使用Langchain生成本地rag知识库并搭载大模型
准备设备: 手机+aidlux2.0个人版
一、下载依赖
pip install langchain langchain-community faiss-cpu pypdf
二、安装ollama并下载模型
curl -fsSL https://ollama.com/install.sh | sh #需要科学上网
ollama serve & #让ollama服务在后台运行
安装完毕可以查看ollama版本进行验证,出现版本号之后就可以使用ollama
ollama -v

考虑性能因素,选择下载较小的模型
ollama pull phi3:mini
ollama pull all-minilm
三、构建rag知识库
- 打开手机上的aidlux应用,打开Cloud_ip查看网络ip,输入ip到浏览器+端口号
:8000访问
输入以下命令:
cd ~
touch build_knowledge_base.py
- 在文件浏览器中/home/aidlux 下找到对应py文件并打开

- 自行准备一个知识库文本(txt或pdf),将文本的路径填入脚本中
- 写入以下脚本内容
from langchain_community.document_loaders import PyPDFLoader, TextLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.embeddings import OllamaEmbeddings
from langchain_community.vectorstores import FAISS
import os# 1. 设置环境变量优化 Ollama 性能
os.environ["OLLAMA_NUM_THREADS"] = "8" # 设置线程数
os.environ["OLLAMA_NUM_CTX"] = "2048" # 设置上下文长度# 2. 配置嵌入模型 - 移除无效参数
embeddings = OllamaEmbeddings(model="all-minilm" # 仅保留必要参数
)# 3. 加载文档
def load_documents(file_path):if file_path.endswith(".pdf"):loader = PyPDFLoader(file_path)print(f"加载 PDF 文档: {file_path}")elif file_path.endswith(".txt"):loader = TextLoader(file_path)print(f"加载文本文档: {file_path}")else:raise ValueError(f"不支持的文档格式: {file_path}")return loader.load()# 4. 文本分割
def split_documents(docs):text_splitter = RecursiveCharacterTextSplitter(chunk_size=500,chunk_overlap=80,separators=["\n\n", "\n", "。", "!", "?", ";"])return text_splitter.split_documents(docs)# 5. 主函数
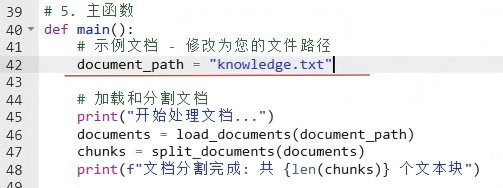
def main():# 示例文档 - 修改为您的文件路径document_path = "knowledge.txt"# 加载和分割文档print("开始处理文档...")documents = load_documents(document_path)chunks = split_documents(documents)print(f"文档分割完成: 共 {len(chunks)} 个文本块")# 创建向量存储print("开始生成嵌入向量...")vector_store = FAISS.from_documents(documents=chunks,embedding=embeddings)# 保存知识库索引save_path = "my_knowledge_base"vector_store.save_local(save_path)print(f"知识库构建完成! 保存到: {save_path}")print(f"向量库大小: {len(vector_store.index_to_docstore_id)} 个向量")if __name__ == "__main__":main()- 运行脚本
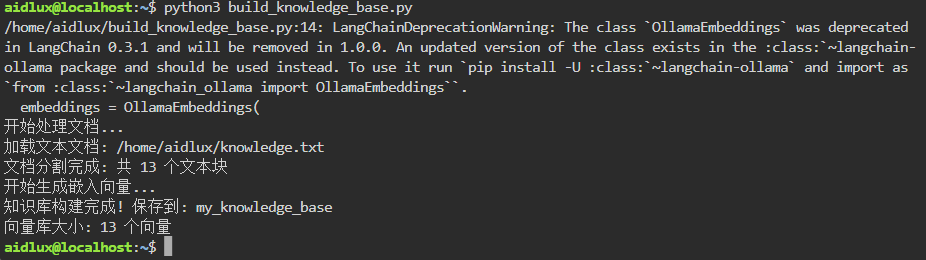
python3 build_knowledge_base.py
四、创建 RAG 问答系统
- 创建一个脚本
touch rag_query.py
- 用文件浏览器的方式写入以下内容
from langchain_community.llms import Ollama
from langchain_community.embeddings import OllamaEmbeddings
from langchain_community.vectorstores import FAISS
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
import os
import time
import sys
import select# 1. 通过环境变量设置优化参数
os.environ["OLLAMA_NUM_THREADS"] = "8" # 设置线程数
os.environ["OLLAMA_NUM_CTX"] = "2048" # 设置上下文长度# 2. 初始化模型
llm = Ollama(model="phi3:mini", # 轻量级语言模型temperature=0.3, # 平衡创造性和准确性timeout=120.0 # 设置超时时间)embeddings = OllamaEmbeddings(model="all-minilm")# 3. 加载知识库
try:vector_store = FAISS.load_local("my_knowledge_base", embeddings, allow_dangerous_deserialization=True)retriever = vector_store.as_retriever(search_kwargs={"k": 3})print("知识库加载成功")
except Exception as e:print(f"加载知识库失败: {str(e)}")print("请确保已运行 build_knowledge_base.py 构建知识库")exit(1)# 4. 定义提示模板
template = """你是一个专业的知识库助手,请基于以下上下文回答问题。
如果不知道答案,请说"我不知道",不要编造答案。上下文:
{context}问题:{question}请用中文给出详细回答:"""
prompt = ChatPromptTemplate.from_template(template)# 5. 构建 RAG 链
rag_chain = ({"context": retriever, "question": RunnablePassthrough()}| prompt| llm| StrOutputParser()
)# 6. 格式化文档显示
def format_docs(docs):return "\n\n".join(doc.page_content for doc in docs)# 7. 改进的输入函数(解决输入卡住问题)
def get_user_input(prompt, timeout=60):print(prompt, end='', flush=True)# 使用 select 检测输入可用性if select.select([sys.stdin], [], [], timeout)[0]:return sys.stdin.readline().strip()return None# 8. 交互式问答
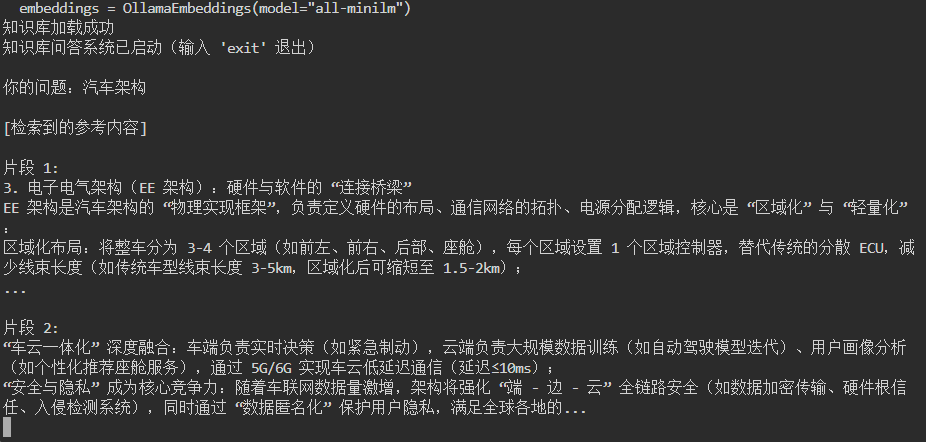
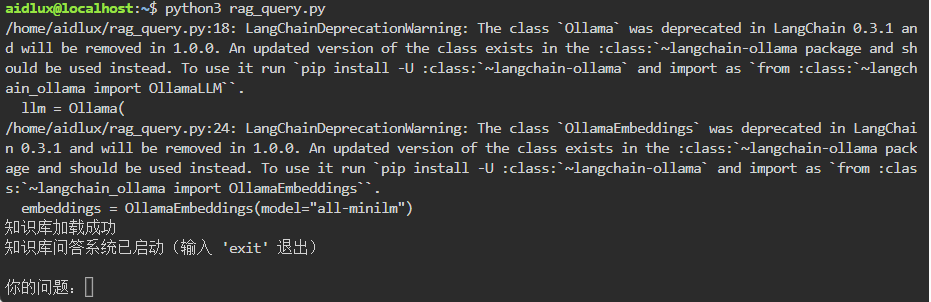
print("知识库问答系统已启动(输入 'exit' 退出)")
while True:try:# 使用改进的输入函数query = get_user_input("\n你的问题:")if query is None:print("\n输入超时,请重新输入...")continueif query.lower() == "exit":breakstart_time = time.time()# 显示检索到的参考内容relevant_docs = retriever.invoke(query)print("\n[检索到的参考内容]")for i, doc in enumerate(relevant_docs[:2]): # 显示前2个相关片段print(f"\n片段 {i+1}:\n{doc.page_content[:200]}...")# 生成答案response = rag_chain.invoke(query)end_time = time.time()print(f"\n[答案] (耗时:{end_time - start_time:.2f}秒)")print(response)# 确保输出缓冲区刷新sys.stdout.flush()except KeyboardInterrupt:print("\n退出系统...")breakexcept Exception as e:print(f"处理问题时出错: {str(e)}")print("请尝试简化问题或稍后重试")# 清除可能的输入缓冲区残留sys.stdin.readline()五、测试验证
python3 rag_query.py
根据提示词输入