如何在ONLYOFFICE中使用OCR工具:轻松识别图片和PDF中的文字
OCR 文字识别是一种能够将图像、图片或扫描文档转换为可编辑、可搜索文本的软件。借助该技术,您无需手动输入文档内容,系统会自动将其转换为机器可读的文本格式,这在某些场景下非常便捷,可帮助您节省时间和精力。
本文将会为您介绍 ONLYOFFICE 的OCR 解决方案,帮助您轻松实现图像和PDF中的文本内容识别与转换。

ONLYOFFICE 文档中的 OCR 工具
如果您经常处理文档、电子表格、演示文稿、图表或 PDF 文件,ONLYOFFICE 文档是一个理想的选择,它不仅是一款功能齐全的开源办公套件,还集成了可靠的 OCR 功能。
该套件提供适用于 Linux 与 Windows 服务器的私有化部署解决方案,可轻松集成到任何基于网页的文档管理系统、内容管理系统或文件共享平台,并支持实时协作功能。此外,该套件还提供了基于相同引擎的免费桌面应用程序,兼容任何 Linux 发行版。
ONLYOFFICE 提供两种 OCR 使用方式:传统 OCR 插件和 AI 驱动的 OCR 功能。
- OCR 插件可以通过插件管理器安装,这是一个基于 Tesseract OCR 引擎的 JavaScript 库,支持60多种语言。您可使用该插件识别 PNG 和 JPG 格式的图像与照片中的文本,并将识别出的文本插入文档,以便进一步编辑。
- AI 驱动的 OCR 功能则是通过 AI 插件实现。这个插件可以集成各种 AI 助手和聊天机器人,借助它们的功能执行文档编辑任务,例如文本生成、翻译、语法与样式修正、摘要等。OCR 是其中重要且实用的功能之一。
下面将以 PDF 为主要的使用场景,详细介绍启用 AI 驱动 OCR 功能的完整步骤。
选择合适的 ONLYOFFICE 解决方案
根据您的使用需求,可以选择以下 ONLYOFFICE 解决方案:
- 服务器部署:在 Windows 或 Linux 服务器上部署 ONLYOFFICE 文档,并集成到您选择的平台(如 Nextcloud、ownCloud、Redmine 等)
- 云端版:使用 ONLYOFFICE 协作空间,无需安装配置即可使用
- 桌面应用程序:在 Windows、Linux 或 macOS 电脑上安装 ONLYOFFICE 桌面编辑器,免费享受离线文档编辑
所有方案都包含强大的ONLYOFFICE PDF编辑器,支持编辑现有文本、添加文本框、插入和修改视觉对象等操作。
启用 AI 集成
要在 PDF 中运行 OCR,需通过 AI 插件添加支持 OCR 的 AI 模型。该插件兼容众多主流工具,如 ChatGPT、Google Gemini、Claude Sonnet、Mistral、Groq、DeepSeek、xAI、Stability AI 等。本文我们使用 Mistral 进行演示,您可以选择任何支持 OCR 的模型。
下面是在 ONLYOFFICE PDF 编辑器中安装配置的步骤:
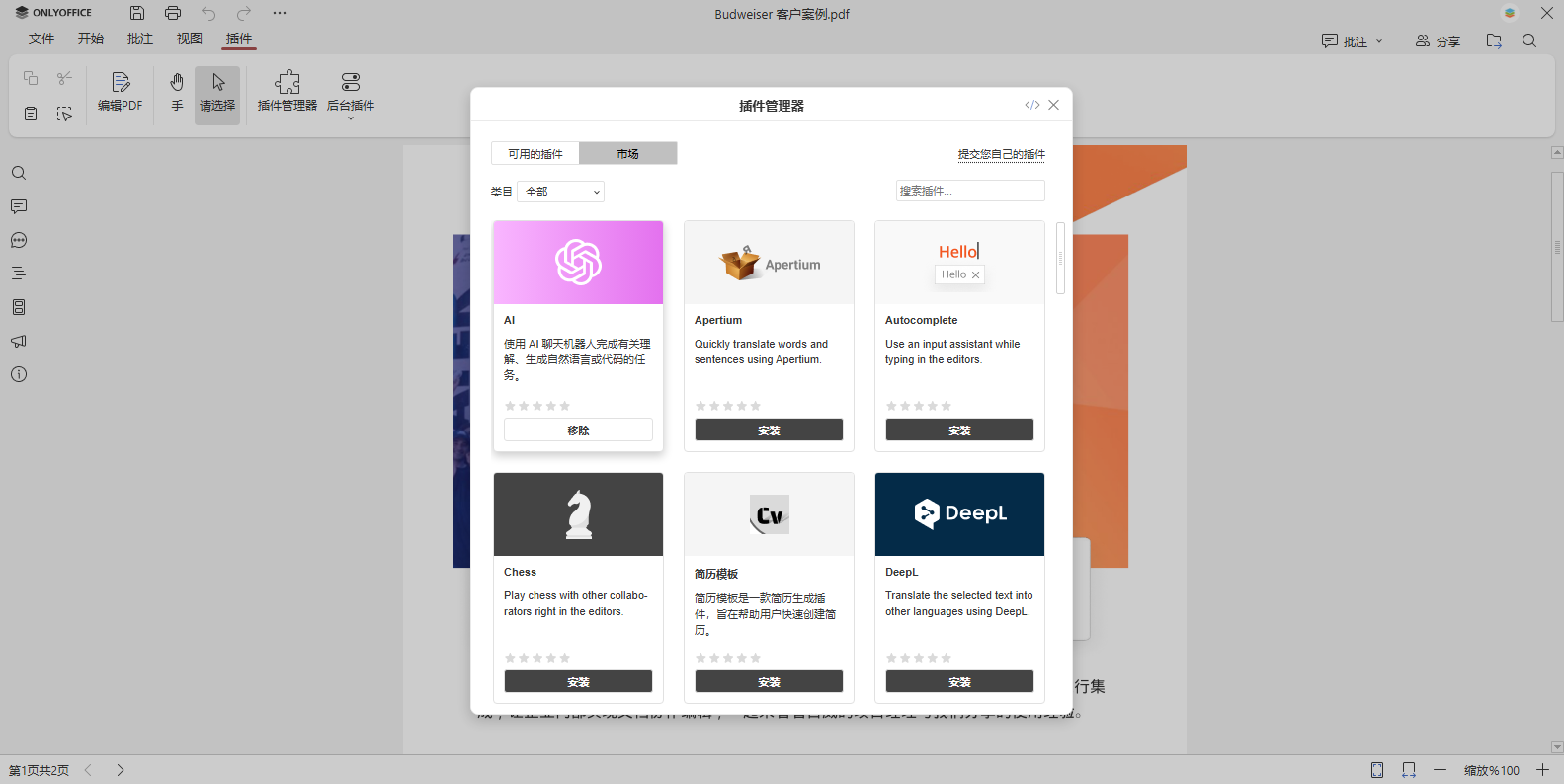
步骤 1. 安装 AI 插件
打开 PDF 文件,通过插件选项卡上的插件管理器访问插件市场。找到 AI 插件并点击相应按钮安装。
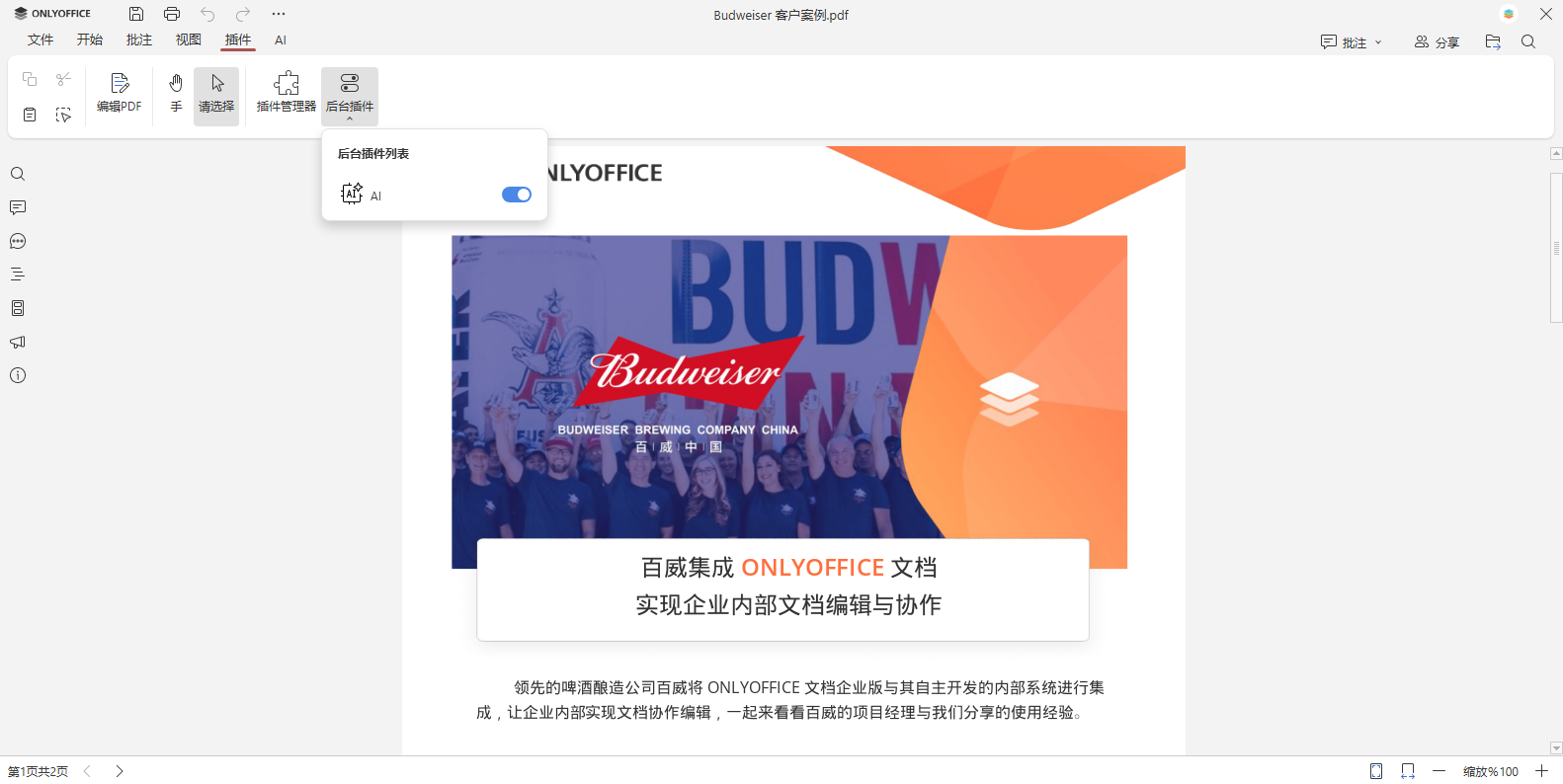
步骤 2. 启用 AI 插件
在插件管理器旁的后台插件区域,点击 AI 插件按钮以激活。顶部工具栏将出现新的 AI 选项卡。
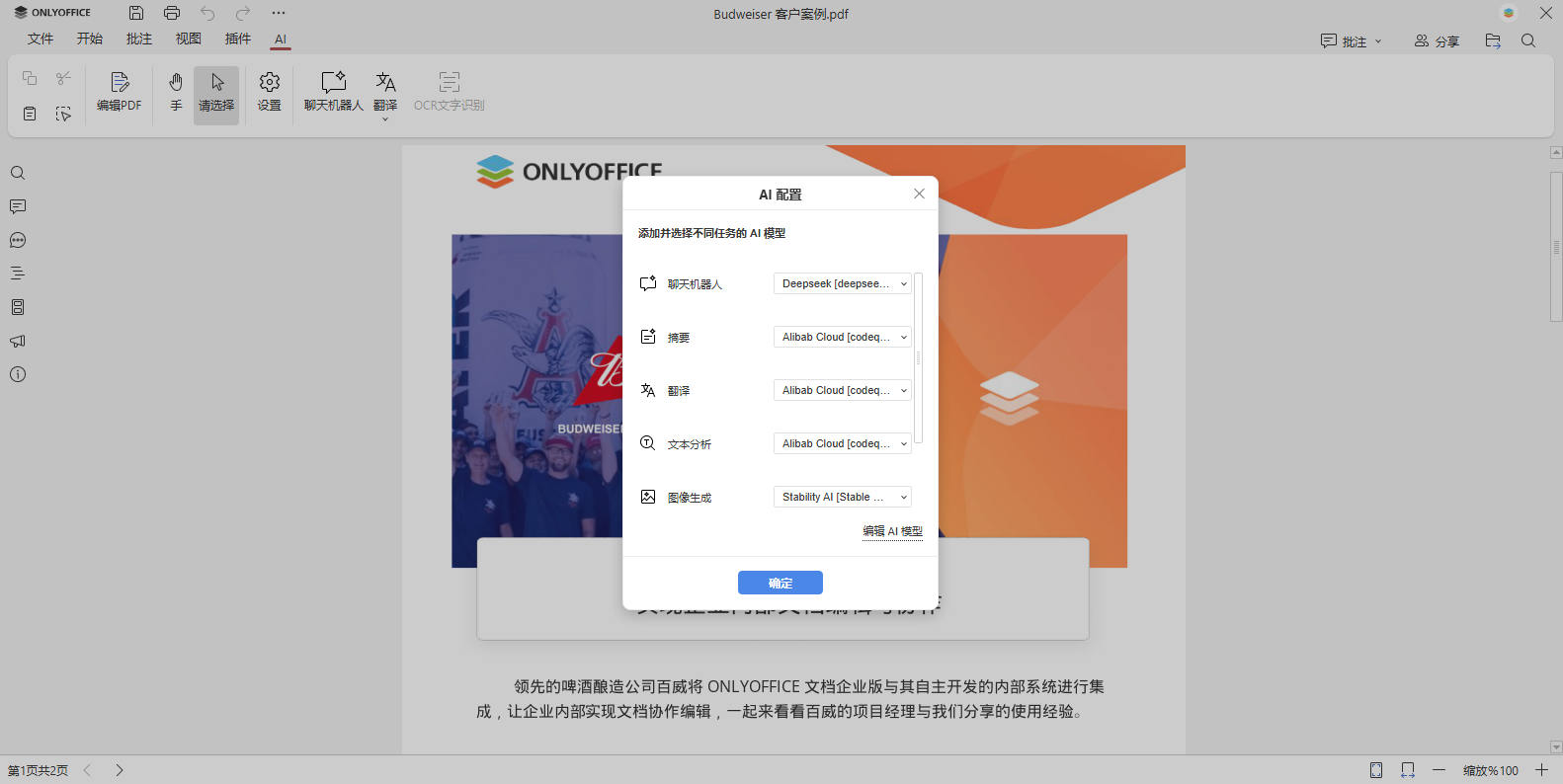
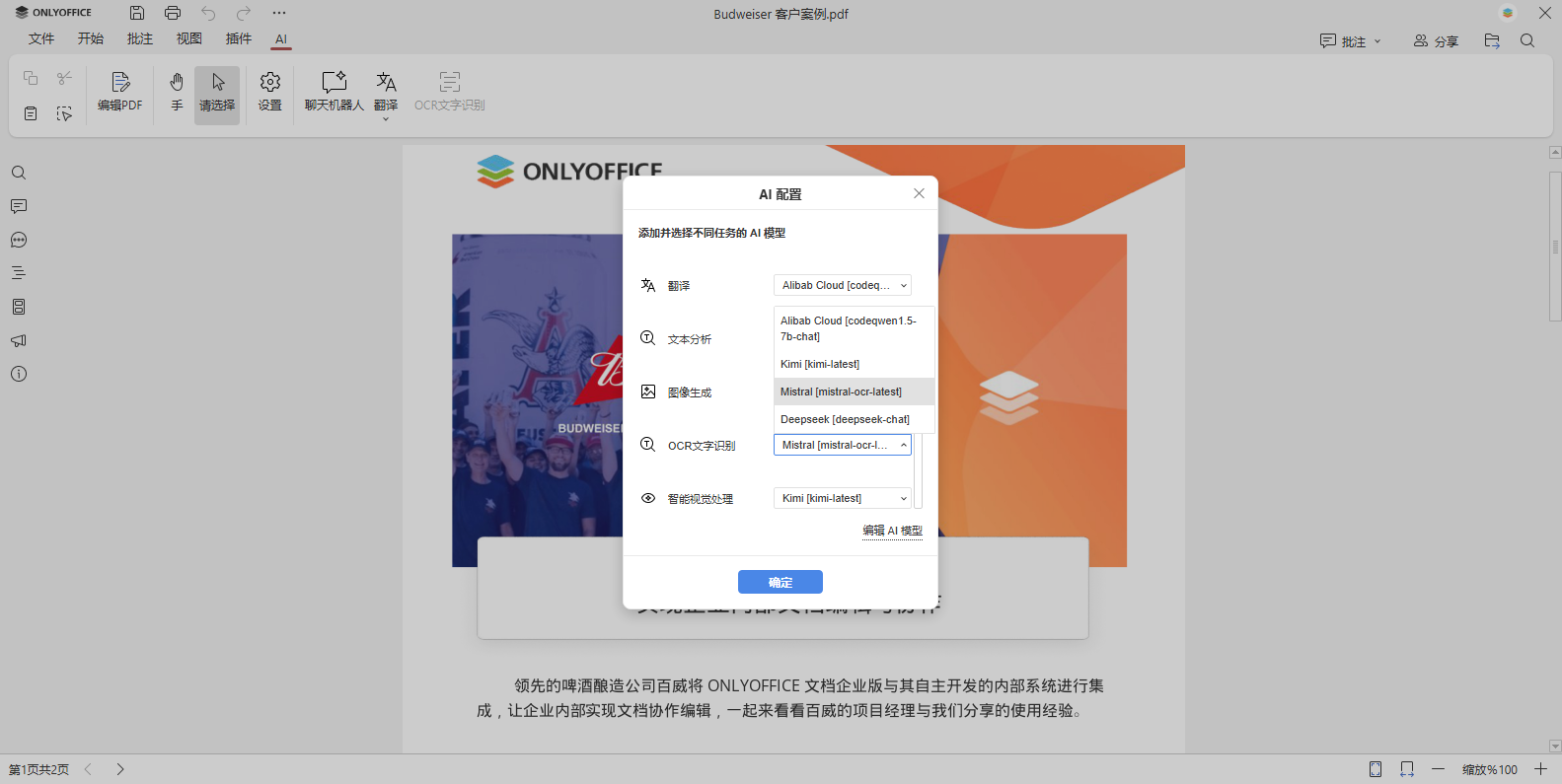
步骤 3. 添加支持 OCR 的 AI 模型
切换到 AI 选项卡,点击设置图标。在 AI 配置菜单中,可为不同任务添加和选择 AI 模型。
点击编辑 AI 模型添加新模型。在 AI 模型列表菜单中,可随时增删模型。
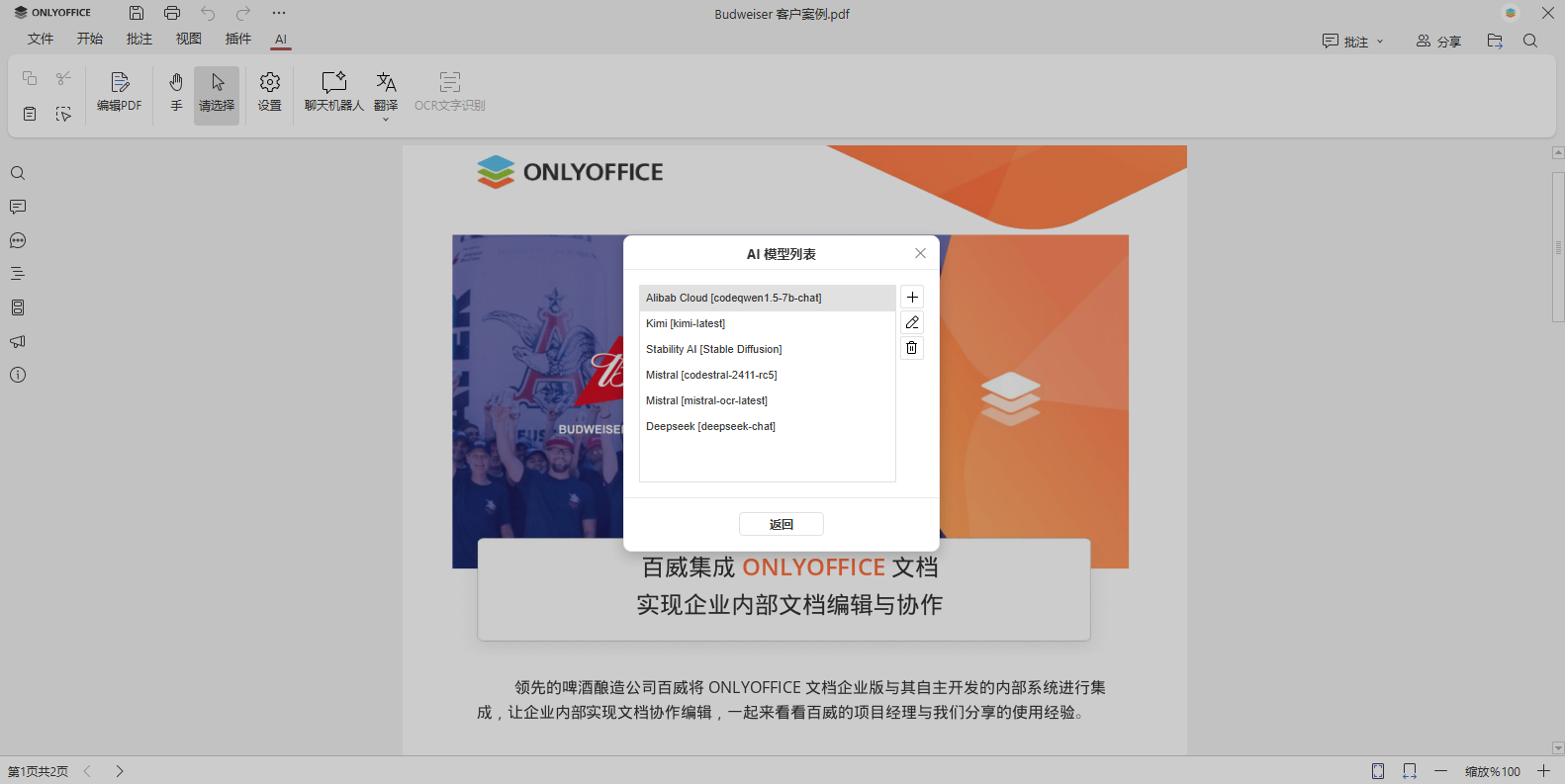
点击 + 按钮,在名称字段的下拉列表中选择一个提供商(如示例中的 Mistral,也可选其他)。
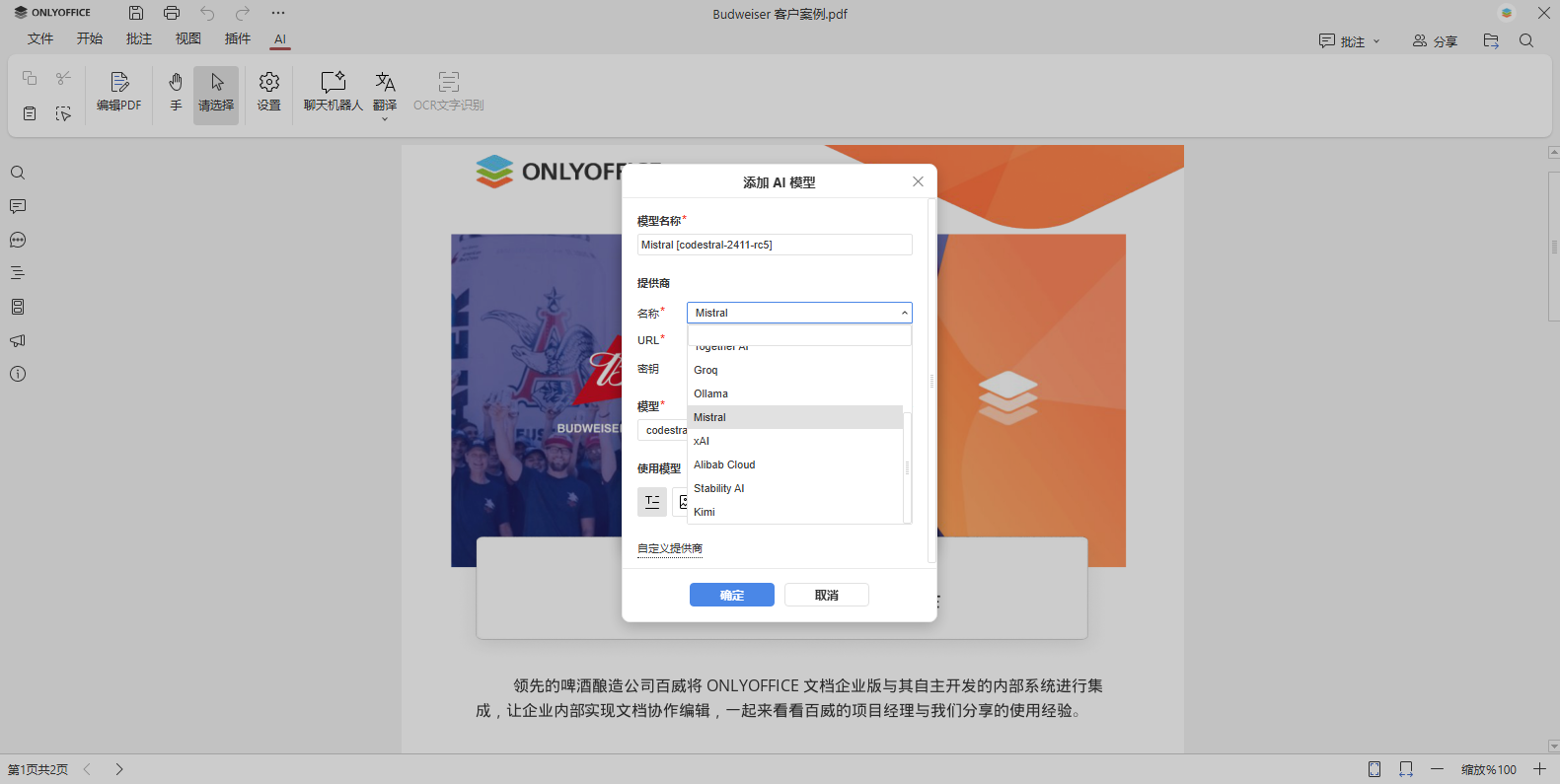
选择提供商后,系统会自动设置对应的 URL 参数。您只需在密钥字段输入有效的 API 密钥(可从提供商官网获取)。
注意: 部分提供商不免费提供 API 密钥,可能需要购买。强烈建议在使用其 AI 模型前查阅其政策和使用条款。
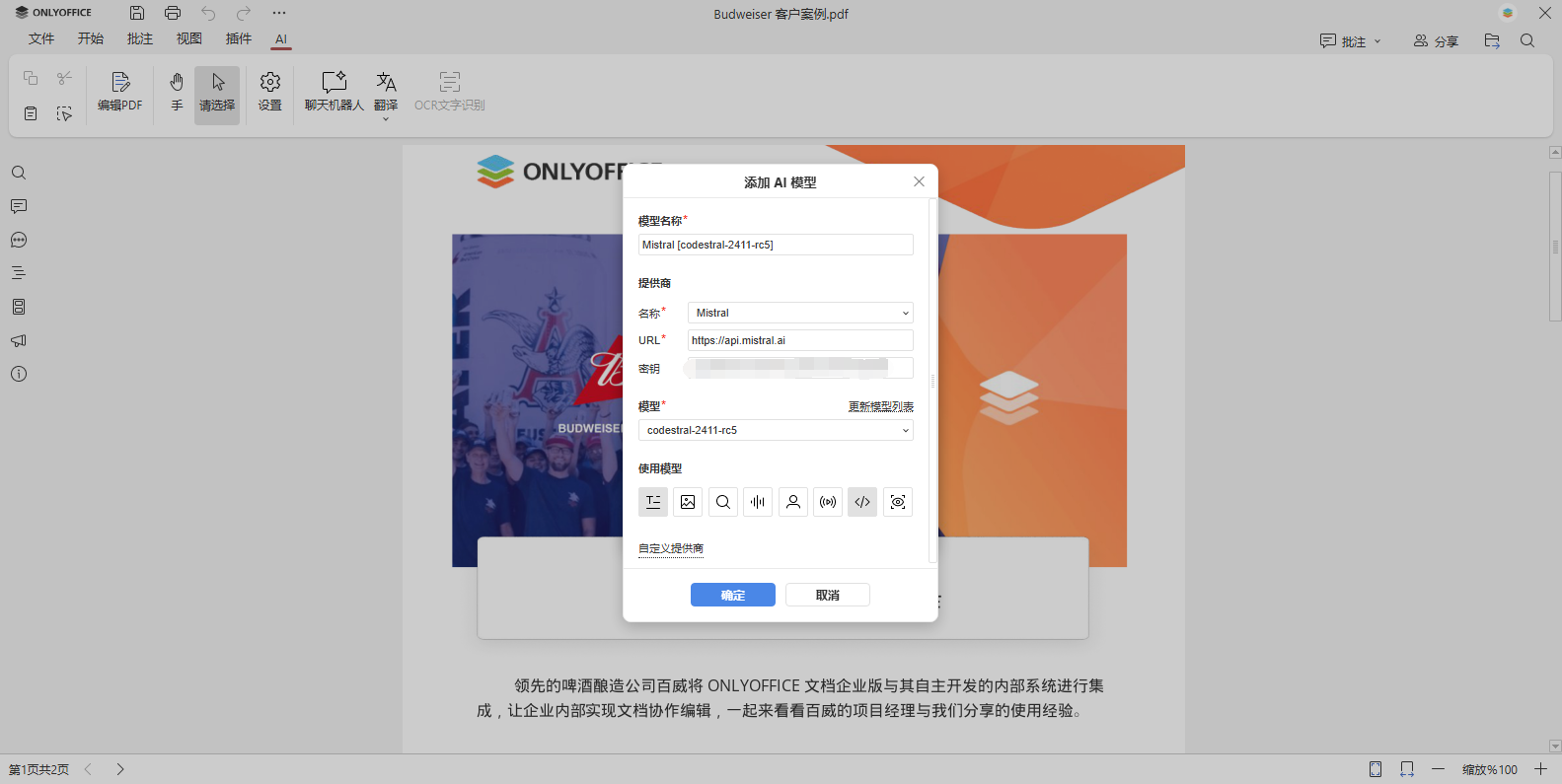
从模型下拉列表中选择一个模型(若无选项可点击更新模型列表)。请注意,不同模型擅长的任务不同(例如,某些擅长文本生成但不支持图像文字识别)。建议选择专为 OCR 设计的模型(具体功能请参考提供商网站说明)。
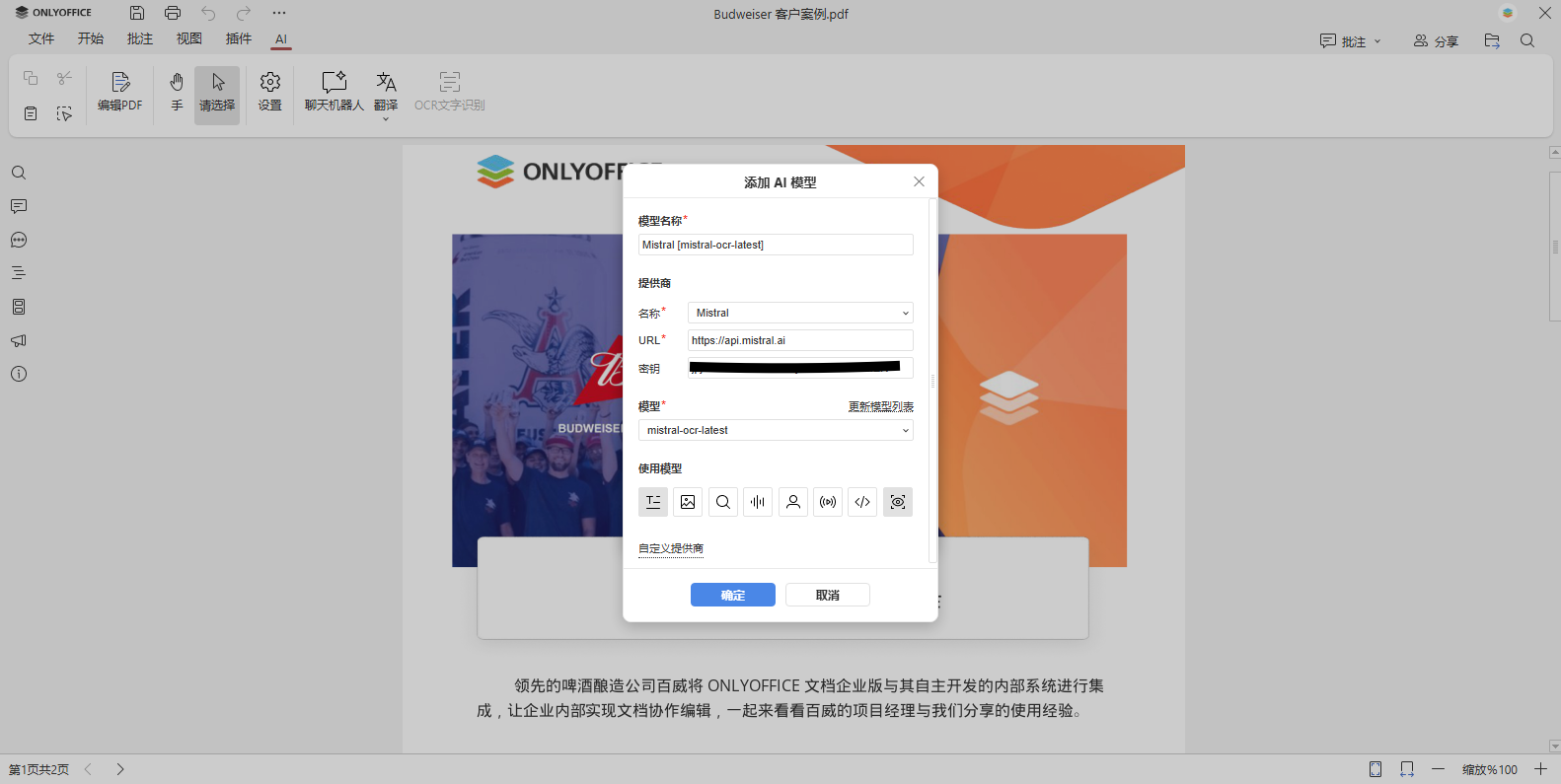
可在模型名称字段重命名添加的模型。关键步骤:在使用模型部分,必须勾选视觉分析选项,否则无法用于 OCR。若您的模型支持 OCR 但未默认勾选,请手动勾选。完成后点击确定。
步骤 4. 分配 OCR 任务
成功添加模型后,返回 AI 模型列表菜单。点击返回按钮进入 AI 配置窗口,将您的模型设为 OCR 任务的默认选项。点击确定完成配置。
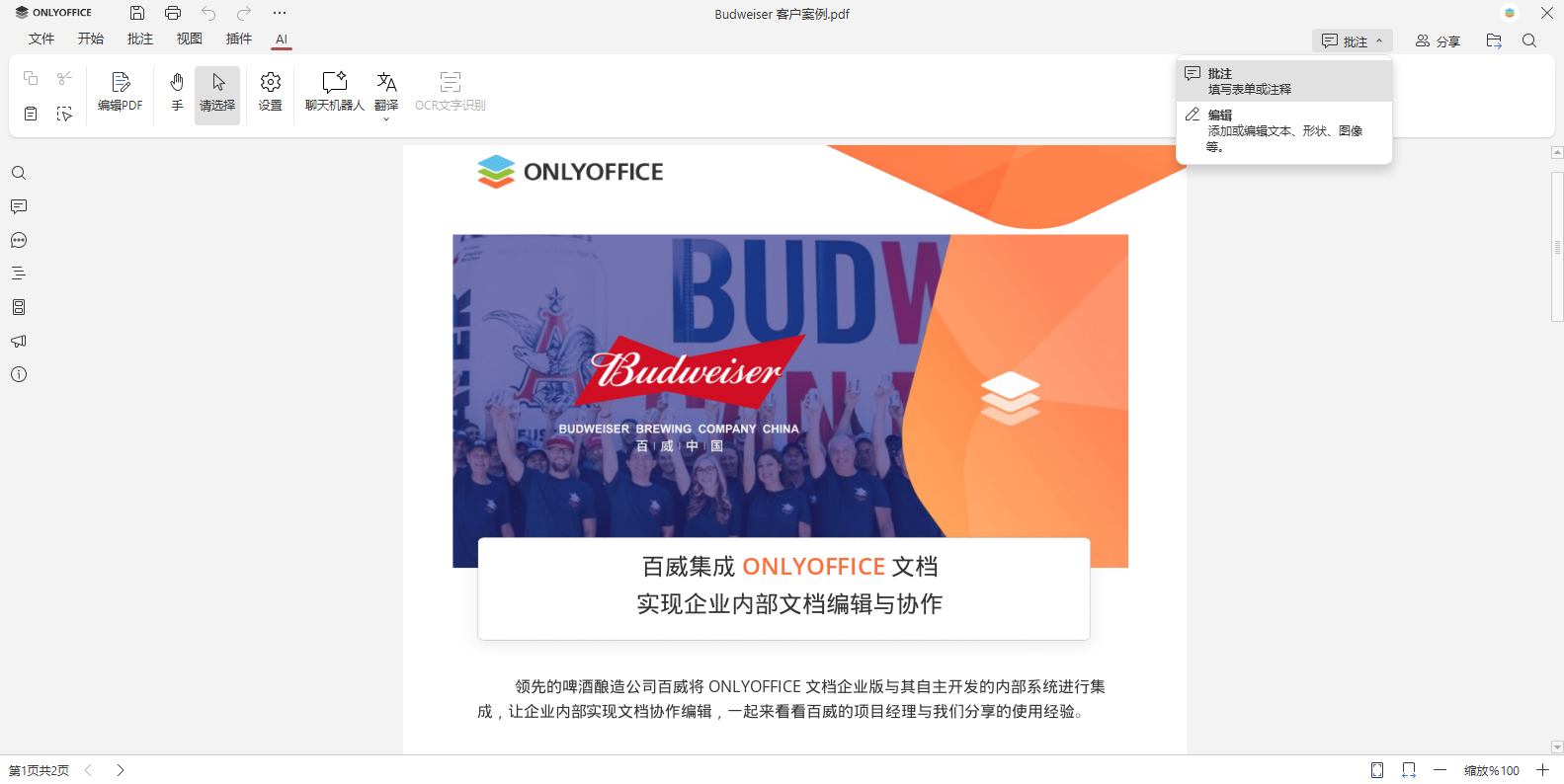
OCR 功能已准备就绪,可在 AI 选项卡访问该功能。若 OCR 图标为灰色,只需从默认的批注模式切换到编辑模式即可(因为批注模式不支持文字识别)。点击 AI 选项卡上的编辑 PDF 按钮,或在界面右上角选择编辑模式均可。
使用 AI 驱动的 OCR 功能
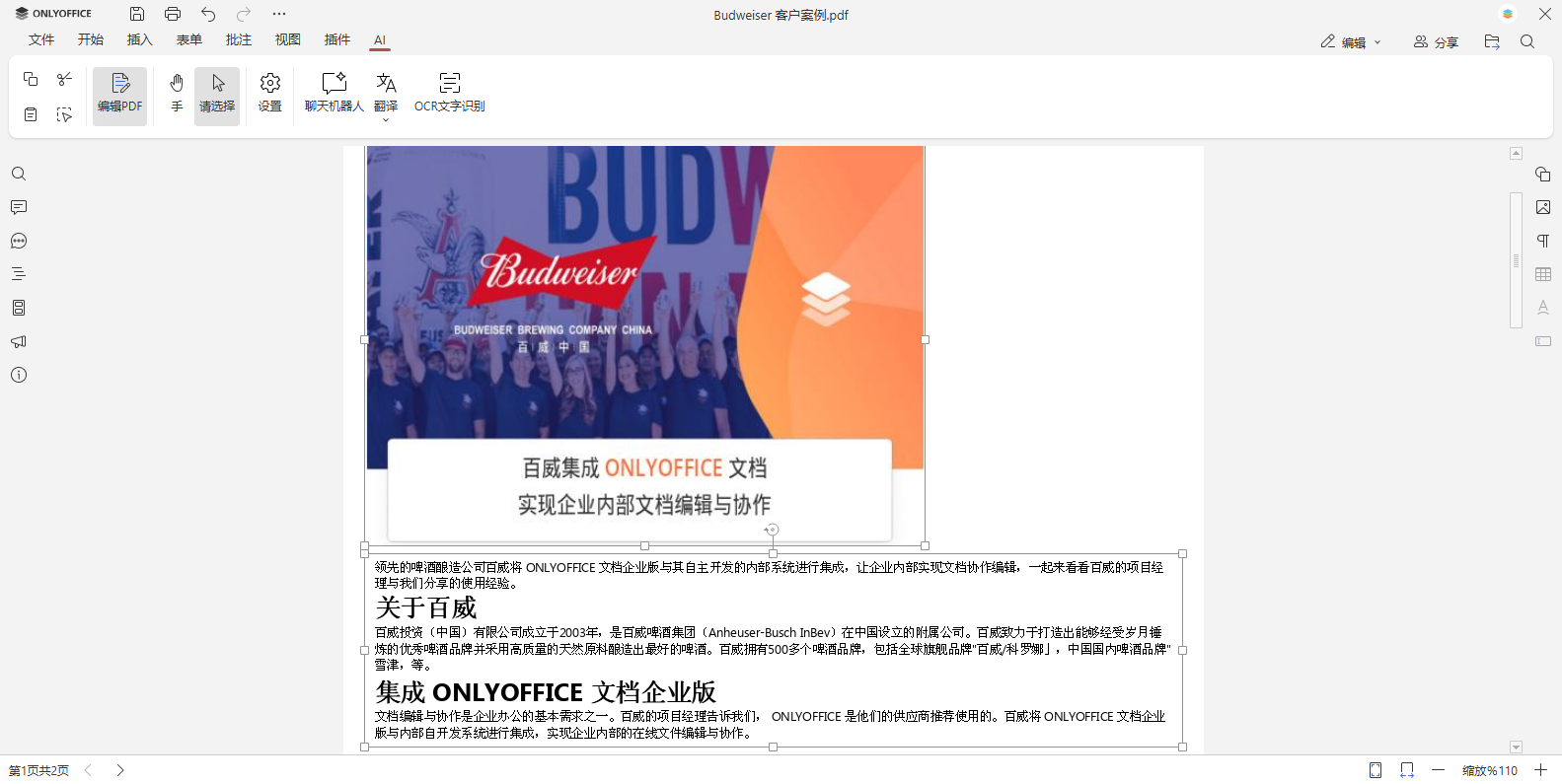
配置好 AI 模型后,点击 AI 选项卡上的 OCR 按钮,即可轻松将 PDF 中的图像转为可编辑文本。AI 助手会识别图像文字并插入同一页面。随后,您可使用 ONLYOFFICE PDF 编辑器丰富的工具进行编辑:选择多样字体、调整大小颜色、创建列表、对齐文本、插入修改对象等。
这种 AI 驱动的 OCR 集成最大优势在于,您不必局限于默认的 OCR 工具,可直接在文档、PDF、幻灯片等编辑器中,直接将图像转换为可编辑文本。您可以自由选择平台提供的多种 AI 模型,例如 Mistral、Ollama、LocalAI 等,也支持使用自定义模型。
常见问题解答
以下是关于 ONLYOFFICE 中 AI 驱动的 OCR 常见问题解答:
问:不信任 AI 工具,能否不用 AI 插件运行 OCR?
答: 对于 PDF 文件,目前仅支持 AI 驱动的 OCR。但处理文本文档时,可使用无需 AI 集成的 OCR 插件转换图像文本。
问:只能在 PDF 中使用 OCR 吗?
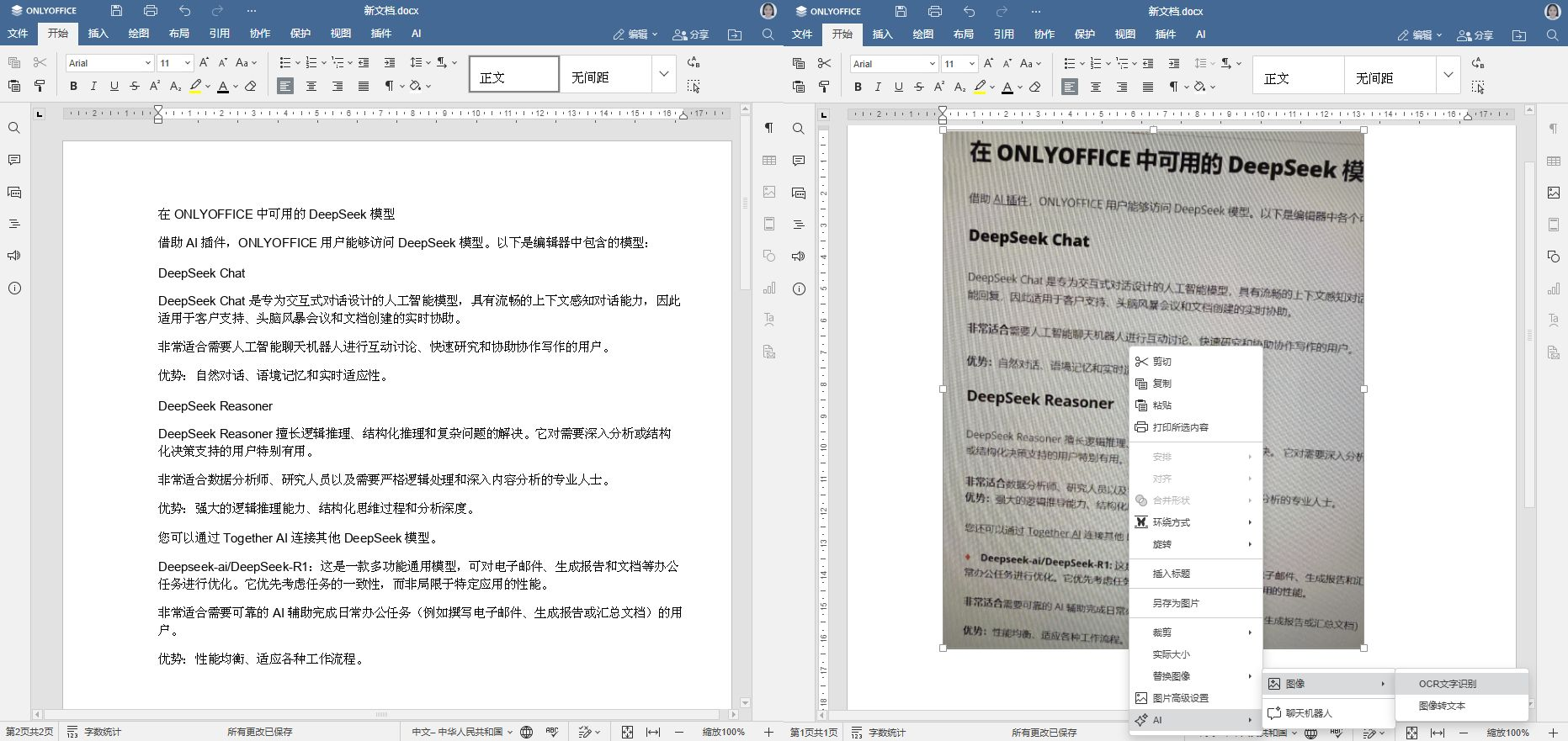
答: AI 驱动的 OCR 同样适用于文本文档、电子表格和演示文稿。使用方法:选中图像 > 右键菜单 > AI > 图像 > OCR。
问:任何 AI 模型都适合 OCR 吗?
答: 并非所有模型都能处理此任务。使用前,请在其提供商官网确认模型规格。
问:AI 驱动的 OCR 是付费功能吗?
答: ONLYOFFICE AI 插件及其功能(包括 OCR)免费提供。但您的 AI 提供商可能会收取模型使用费,具体定价请参考其官网。
相关链接
ONLYOFFICE AI 智能体
集成 ONLYOFFICE 与 AI 插件