深入 Linux 文件系统:从数据存储到万物皆文件
深入 Linux 文件系统:从数据存储到万物皆文件
Linux 文件系统是一个精妙而复杂的工程,它像一座图书馆,不仅存放着书籍(数据),还有一套高效的卡片索引系统(元数据)来管理它们。本文将带你深入探索,从最简模型到现代实现,全面理解 Linux 文件系统的工作机制。
一、 核心思想:最小模型
任何文件系统都可以抽象为两个核心区域:
- 元数据存储区 (Metadata Region):用于管理文件的信息系统。
- 数据存储区 (Data Region):用于存储文件的实际内容。
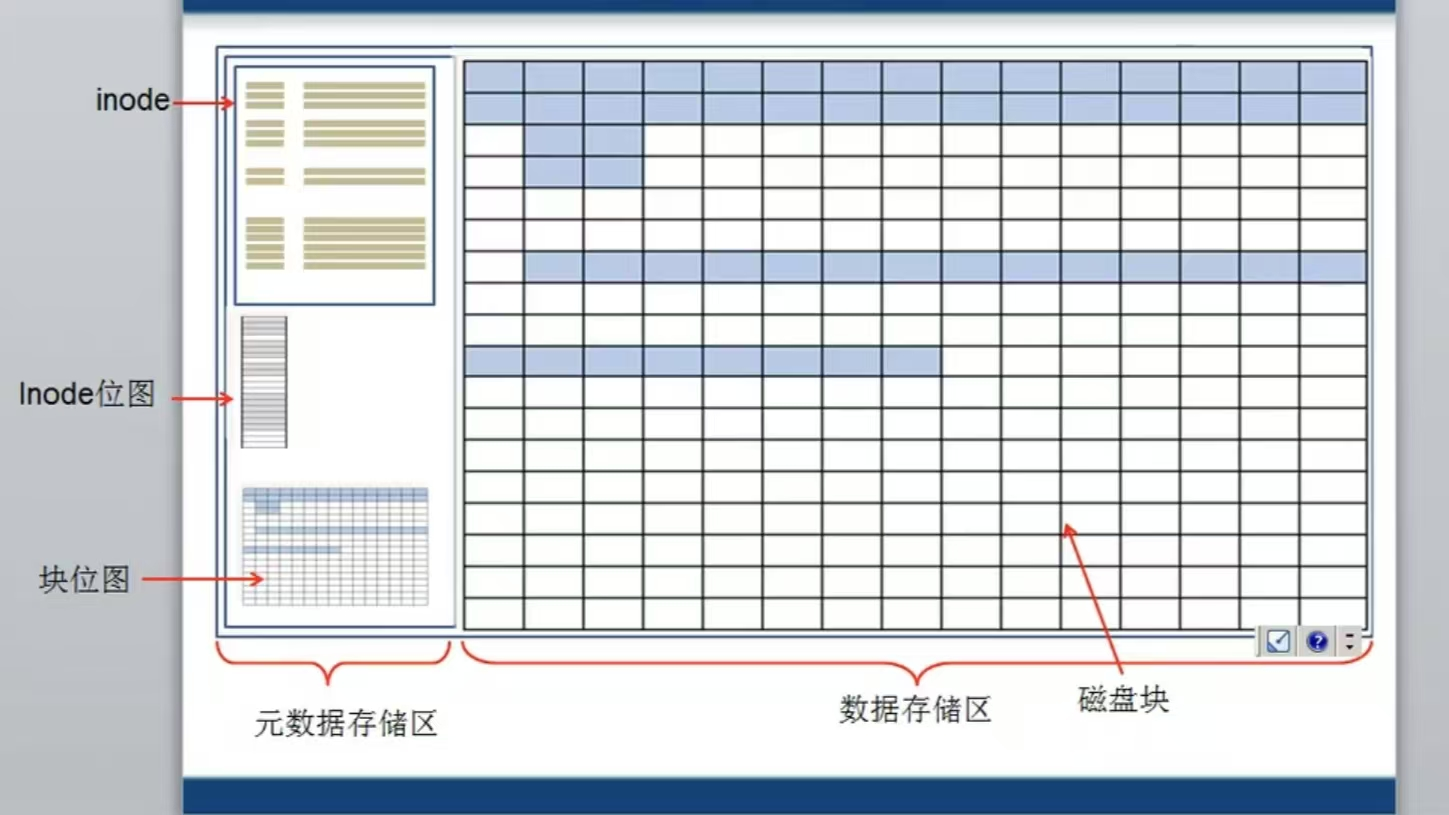
1. 元数据区的三大支柱
- inode 表 (inode Table):
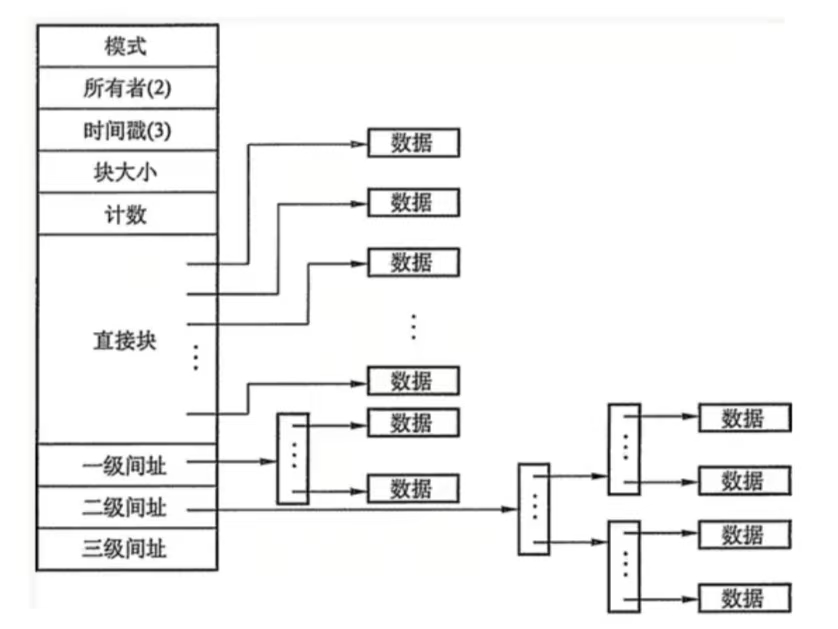
- 每个文件或目录都对应一个 inode(索引节点),它是文件的“身份证”。
- inode 记录了文件的元信息:权限、所有者、大小、时间戳,以及最关键的——指向文件数据块的指针。
- 文件名不存储在 inode 中。
- inode 位图 (inode Bitmap):
- 一个简单的二进制位图,用于快速追踪哪些 inode 已被使用,哪些是空闲的。
- 系统创建新文件时,通过扫描此位图来快速分配空闲 inode。
- 块位图 (Block Bitmap):
- 与 inode 位图类似,用于追踪数据存储区中哪些数据块已被使用,哪些是空闲的。
2. 目录是什么?
目录本身也是一种特殊的文件。它的内容不是普通数据,而是一张“表格”,记录了其包含的文件和子目录的名字到 inode 的映射关系。
- 例如:访问 /test/123.mp3
| 文件名 | inode 号 |
|---|---|
| a.txt | 1001 |
| b.log | 1002 |
| test | 1003 |
| 文件名 | inode 号 |
|---|---|
| 123.mp3 | 5555 |
| music | 5556 |
结论:文件名是目录的内容,而文件的实际信息由 inode 管理。这使得“重命名”文件在同一个目录下几乎瞬间完成,只需修改目录文件中的一个条目即可。
3. 文件操作揭秘
- 新建文件:
- 在目录文件中添加一个新条目(文件名 -> inode号)。
- 在 inode 位图中找到一个空闲 inode 并标记为已用。
- 将文件元信息写入该 inode。
- 在块位图中找到空闲数据块并标记为已用。
- 将文件数据写入数据块,并将数据块地址记录在 inode 的指针中。
- 删除文件:
- 在目录中删除文件名到 inode 的映射条目。
- 在 inode 位图中将该文件对应的 inode 标记为空闲。
- 在块位图中将该文件占用的所有数据块标记为空闲。
- 注意:数据并没有被立即擦除,只是被“遗忘”了,直到被新数据覆盖。这就是数据恢复的原理。
- 移动/重命名文件:
- 同一分区内:仅在原始目录中删除条目,并在目标目录中创建一个新条目(指向同一个 inode)。速度快,因为数据无需移动。
- 跨分区:相当于在新位置“创建”一个新文件,然后删除旧文件。速度慢,因为数据需要被复制。
4. 软连接 vs. 硬链接
| 特性 | 硬链接 (Hard Link) | 软连接 (Symbolic Link) |
|---|---|---|
| 本质 | 是同一个文件的多个目录入口(别名) | 是一个独立文件,内容存储目标文件的路径 |
| inode | 共享目标文件的 inode | 拥有自己的 inode |
| 跨分区/FS | 不支持 | 支持 |
| 删除原文件 | 不影响硬链接访问 | 软连接失效(“悬空链接”) |
ln 命令 | ln <源文件> <链接名> | ln -s <源文件> <链接名> |
二、 日志文件系统 (Journaling FS)
1. 非日志文件系统的问题
在传统文件系统(如 ext2)中,如果发生意外断电或系统崩溃,一个正在进行的写操作可能只完成了一半(例如,数据块已写入,但 inode 未更新)。这会导致文件系统处于不一致状态,需要运行漫长的 fsck 工具来检查和修复,耗时极长。
2. 日志的解决方案
日志文件系统(如 ext3, ext4, XFS, Btrfs)引入了“预写日志 (Write-Ahead Logging)”机制。
- 记录日志:在真正修改元数据之前,先将即将要执行的操作概要写入磁盘的一个特定区域(日志)。
- 提交操作:只有日志成功写入后,才真正执行文件系统的元数据和数据写入。
- 检查点:操作完成后,在日志中标记该事务已完成。
好处:如果系统崩溃,恢复时只需读取日志,重做(Redo)或撤销(Undo)未完成的操作即可, recovery 速度极快,保证了数据一致性。
三、 实际文件系统模型:Ext4 的块组
现代文件系统(如 ext4)将整个分区划分为多个块组 (Block Groups),每个块组都拥有自己的元数据区和数据区,这是一种卓越的优化设计。
- 超级块 (Superblock):存储整个文件系统的全局信息(如大小、块数量、空闲 inode 计数等)。通常会在多个块组中进行备份,防止单点故障。
- 块组描述符表 (Group Descriptor Table):描述每个块组的详细信息(如块位图和 inode 位图的位置、空闲 inode 数等)。
- 每个块组包含:
- 一份备份的超级块和块组描述符(可选)。
- 该块组专用的 inode 位图 和 块位图。
- 该块组专用的 inode 表。
- 该块组专用的数据块。
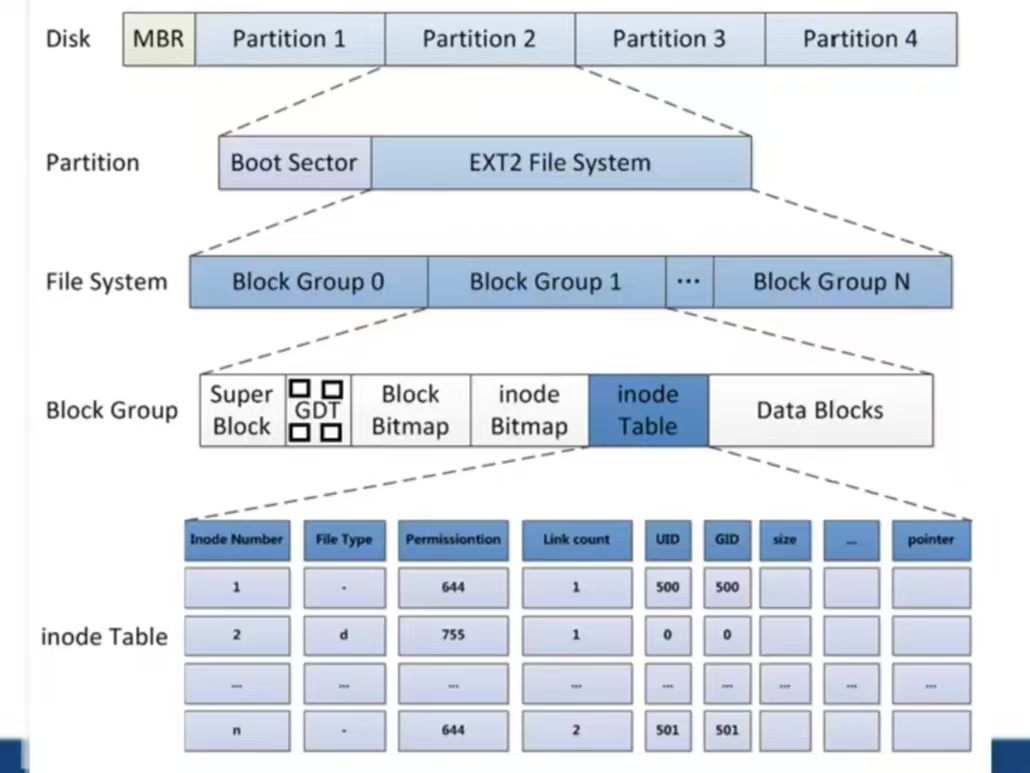
现代文件系统的优势:
- 性能:将 inode 和数据块靠近存放,减少磁头寻道时间(磁盘 fragmentation 的影响降低)。
- 可靠性:元数据分散备份,部分损坏不会导致整个文件系统瘫痪。
- 并行性:内核可以同时处理多个块组,提高吞吐量。
四、 虚拟文件系统 (VFS):一切皆文件
Linux 支持数十种文件系统(ext4, XFS, NTFS, FAT32…),应用程序如何用统一的 open(), read(), write() 接口与它们交互?答案是 VFS。
- VFS 是什么?:它是内核中的一个抽象层,为上层的应用程序提供一套统一的文件操作接口。
- 如何工作?:当应用程序调用
read()时,VFS 会根据文件路径找到其所在的具体文件系统(如 ext4),然后调用该文件系统驱动提供的read()方法。对应用程序来说,这个过程是透明的。 - 一切皆文件:VFS 的强大之处在于它将许多资源都抽象成了文件。
- 普通文件、目录 -> 文件
- 块设备 (
/dev/sda1) -> 文件 - 字符设备 (
/dev/tty,/dev/null) -> 文件 - 网络套接字 (Sockets) -> 文件
- 管道 (Pipes) -> 文件
这使得我们可以使用相同的read/write命令与各种资源交互。
- 挂载 (Mount):将某个设备(如
/dev/sda1)关联到当前目录树中的一个目录(如/home)。这个目录称为挂载点 (Mount Point)。通过mount命令,VFS 将不同的文件系统整合成一棵单一的、统一的目录树。
五、 文件系统的运行机制:从系统调用到硬件写入
当你在应用程序中调用 write(fd, buf, count) 这样一行简单的代码时,Linux 内核中会触发一场精妙的协作。数据需要穿越多个软件层次,最终才能安全地抵达磁盘。这个过程体现了 Linux 系统设计的模块化和层次化思想。
其核心层次结构如下图所示,数据请求自上而下流动:
1. 虚拟文件系统 (VFS - Virtual File System)
VFS 是所有文件系统操作的总入口和调度中心。它的主要职责是:
- 抽象与统一:为上层应用程序提供统一的系统调用接口(如
open,read,write,close),无论底层是哪种文件系统。 - 查找与路由:当应用程序请求操作某个路径(如
/home/user/file.txt)的文件时,VFS 负责解析路径,找到目标文件对应的 inode。 - 多文件系统支持:VFS 定义了一套所有文件系统驱动都必须实现的通用操作接口(
file_operations,inode_operations等)。找到文件后,VFS 会根据该文件所在的具体文件系统类型(如 ext4),调用该文件系统驱动提供的具体方法。这就是为什么 Linux 可以同时挂载和使用多种文件系统的原因。
简单来说,VFS 是一个“经理”,它接收客户(应用程序)的请求,然后派发给对应的“专员”(具体文件系统)去处理。
2. 具体文件系统 (如 ext4, XFS, Btrfs)
这一层是处理文件系统特定逻辑的“专员”。它接收来自 VFS 的请求,并转换为对磁盘布局的具体操作:
- 逻辑到物理的映射:它的核心任务是管理 inode、目录、数据块等结构。当收到写请求时,它需要:
- 为数据分配空闲的数据块(通过查询块位图)。
- 更新文件的 inode,将新的数据块地址添加到指针列表中。
- 可能还需要更新目录文件(如文件大小改变)、日志等。
- 事务管理:对于日志文件系统,它会将此次写操作作为一个事务(Transaction)写入日志区域,确保一致性。
- 提交 IO 请求:处理完元数据后,它将本次写请求转换为一个或多个IO请求。每个请求描述了要写入的逻辑块号 (Logical Block Number) 和数据。这些请求被提交到下一层:通用块层。
3. 通用块层 (Generic Block Layer)
通用块层是 Linux 存储子系统中的交通指挥官,负责所有块设备(硬盘、SSD)的IO管理。它的核心任务是优化和调度IO请求:
- IO调度 (IO Scheduler):
- 合并 (Merging):将多个连续的、小的IO请求合并成一个大的请求,减少IO次数。
- 排序 (Sorting):对请求按磁盘扇区号进行排序(类似于电梯算法),将无序的请求变为顺序请求,极大减少机械硬盘的磁头寻道时间,提升吞吐量。
- 公平性调度:在多个进程竞争IO资源时,保证系统的响应性。
- 创建
bio结构:调度完成后,通用块层会创建一个或多个bio(Block IO)结构,这是内核中描述块IO请求的通用数据结构。bio包含了要写入的物理设备、起始扇区、数据在内存中的位置等信息。
4. 设备驱动层 (Device Driver Layer)
这是最后一步,bio 请求被发送到具体的块设备驱动(如 SATA, NVMe, Virtio-BLK 驱动)。
- 驱动将
bio请求转换为硬件控制器能够理解的指令(如 NVMe 的 SQ/CQ 命令)。 - 它通常会配置 DMA (Direct Memory Access),让设备控制器直接从内存中取数据并写入磁盘,无需CPU参与,解放了CPU。
- 写入完成后,设备会发出一个中断,通知CPU写入操作已经完成。然后这个完成信号会自底向上地一层层返回,最终告知应用程序写入操作成功。
六、 绕过文件系统:设备访问
在 /dev/ 目录下的文件是设备文件,是应用程序与硬件设备驱动的接口。
- 块设备 (Block Devices):
- 特性:数据存储在以固定大小(如 4KiB)的“块”中,支持随机访问(如硬盘、SSD)。
- 读写:通常涉及缓存,读写操作先经过内核的页缓存 (Page Cache),然后由内核择时写入设备,以提高性能。
- 示例:
/dev/sda(硬盘),/dev/vda1(虚拟磁盘分区)。
- 字符设备 (Character Devices):
- 特性:数据以字节流的形式处理,不支持随机寻址(如键盘、鼠标、打印机)。
- 读写:通常没有缓存,数据直接与驱动交互。
- 示例:
/dev/tty(终端),/dev/random(随机数生成器)。
设备访问只需要经过虚拟文件系统,不需要经过文件系统。
总结
Linux 文件系统是一个层次化的杰作:
- 底层:
数据块 + inode的最小模型保证基础功能。 - 中层:
日志 + 块组的设计保证了性能、可靠性和可扩展性。 - 顶层:
VFS抽象统一了所有差异,实现了“一切皆文件”的哲学,并通过挂载将其组织成统一的视图。