大语言模型预训练流程
大语言模型训练流程
Pre-training → SFT → RLHF
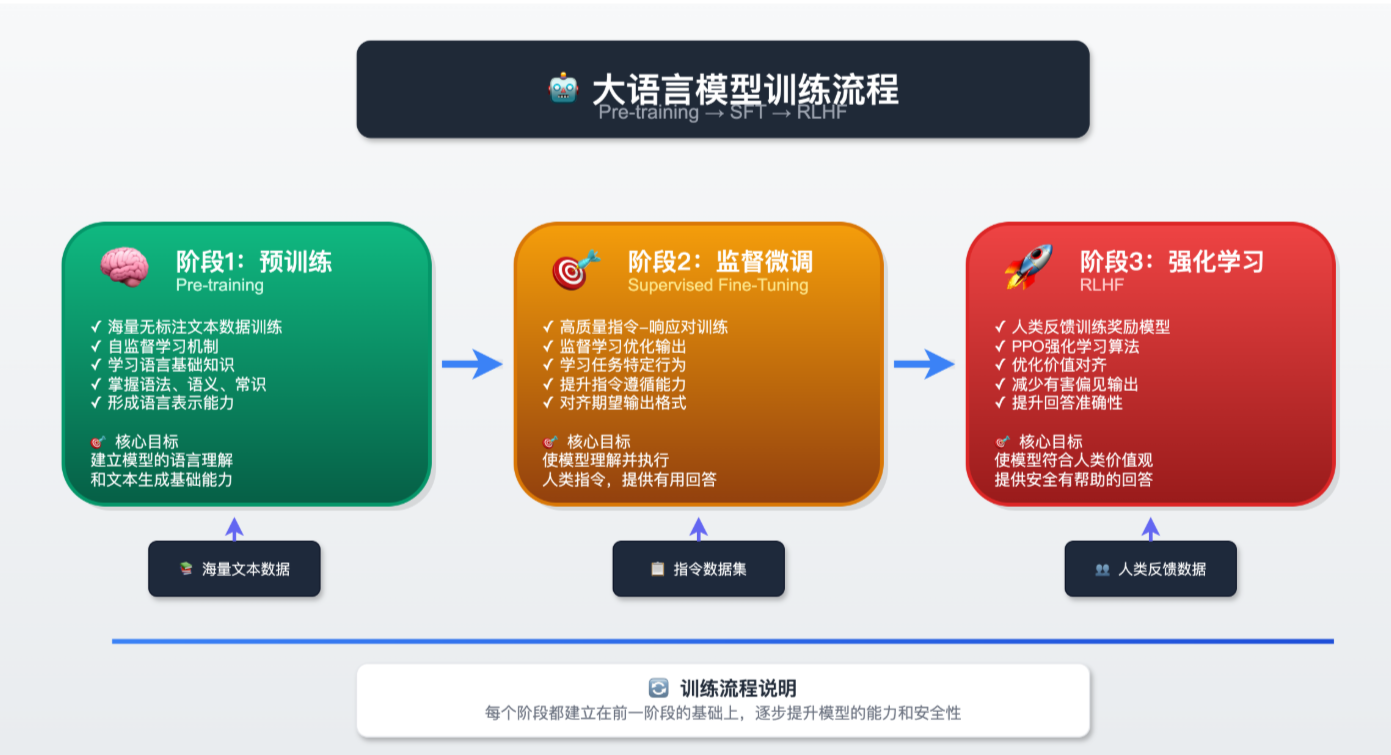
阶段1:预训练Pre-training
- 海量无标注文本数据训练
- 自监督学习机制
- 学习语言基础知识
- 掌握语法、语义、常识
- 形成语言表示能力
核心目标:建立模型的语言理解和文本生成基础能力
阶段2:监督微调Supervised Fine-Tuning
- 高质量指令-响应对训练
- 监督学习优化输出
- 学习任务特定行为
- 提升指令遵循能力
- 对齐期望输出格式
核心目标:使模型理解并执行人类指令,提供有用回答
阶段3:强化学习RLHF
- 人类反馈训练奖励模型
- PPO强化学习算法
- 优化价值对齐
- 减少有害偏见输出
- 提升回答准确性
核心目标:使模型符合人类价值观,提供安全有帮助的回答
训练流程说明
每个阶段都建立在前一阶段的基础上,逐步提升模型的能力和安全性
3.1 大语言模型预训练:从零到一的完整指南
这篇文章介绍下如何从零到一进行 pretrain 工作。

从数据处理到模型评估的完整工程实践
数据准备阶段
- 数据采集:网络爬虫技术、开源数据集整合、API 内容解析、实时流数据接入、多模态数据收集
- 数据清洗:质量评分算法、规则过滤引擎、格式标准化、噪声数据检测
- 数据去重:MinHash 算法、文档级去重、相似段落去重、增量去重策略
- 数据配比:中英文比例 4:4:2、代码数据融合、知识密度聚类、领域数据权重
- 数据排序:课程学习策略、语义相似性聚类、知识难度递进、动态调整算法
- 数据流水线:动态数据加载、Token 预处理优化、数据块智能管理、内存效率优化
- 数据实验:小模型快速验证、Scaling Law 探索、配比效果优化、loss曲线分析、A/B 测试验证
训练准备阶段
- Tokenizer 设计:BPE/BBPE 算法优化、压缩率精细控制、词表覆盖率分析、多语言支持
- 模型架构:LLaMA 类架构、旋转位置编码、GOA 注意力机制、RMS LayerNorm、SwGLU 激活函数
- 超参数配置:模型 Size 科学选择、学习率动态调整、序列长度优化、并行策略设计、内存预算规划
- 训练框架:Megatron-LM 深度集成、Deepspeed 优化整合、3D 并行配置、Flash Attention、混合精度训练
模型训练阶段
- 训练流程管控:Warmup 精细调节、稳定训练期调度、突发错误恢复、Anneal 策略设置、动态学习率调整
- 智能监控系统:实时 Loss 曲线、Channel 损失分析、梯度分布监控、训练健康度监控、性能瓶颈识别
- 效率优化策略:通信拓扑优化、智能内存管理、梯度累积优化、重计算权衡策略、硬件利用率最大化
- 容错与恢复:检查点智能保存、故障自动检测、快速恢复机制、数据完整性验证、训练状态追踪
- 实时调优:超参数动态调整、数据配比实时优化、模型收敛监控、学习率自适应、训练策略自适应
评估验证阶段
- 强度评估:测试集 loss 精确测量、收敛趋势分析、泛化能力评估、泛化能力评估、基座模型对比
- 标准测试:改进式评估设计、生成式任务测试、多维度能力评估、多维度能力评估、多维度能力评估
- 深度探针:知识概率分布、价值类属性判断、思维链分析、推理路径分析、偏见风险评估
- 能力检测:多模态理解测试、代码生成能力、代数推理能力、创意写作评估、专业领域知识
- 性能报告:训练效率分析、成本效益评估、稳定性总结、改进方向规划、下一版本路线图
数据准备篇
一、原始数据获取:不只是“爬”那么简单
做大模型预训练,第一步就是搞数据。别急着写模型,先准备个10T级别的语料库再说。当然,初期没那么多也没关系,可以边训边收集,像 Spark、Flink、Hadoop 这些工具都能帮你持续补充数据流。
数据来源五花八门,网页抓取、第三方采购、甚至找“数据中间商”都行。但注意,爬虫不是算法工程师的强项,IP被封、被起诉都不是闹着玩的,专业的事交给专业的数据团队去做。
像论文、书籍这类高质量内容,很多是PDF格式,解析起来相当头疼。别指望用Python库搞定复杂排版,公式、表格一多就崩。用GPT4解析?贵得离谱。自己训OCR模型?可以,但得有大量PDF-文本对齐数据。
好消息是,现在开源数据集遍地都是,FineWeb、The Pile、SkyPile、RedPajama 都能拿来当“启动资金”。但别高兴太早,开源的中文数据往往是“别人挑剩下的”,质量参差不齐,得自己再洗一遍。
哪怕是从 Hugging Face 下载数据,也不是点几下就完事。服务器没外网?得换镜像。下载太慢?得多进程、多机器并行。文件太多?ls都能卡死,得上大数据平台处理。
还得明白一点:数据的知识密度差异巨大。三百首唐诗的信息密度远高于三百篇新闻。高价值数据往往要花钱买。现在流行“合成高密度数据”——把几千字的新闻压缩成几百字,训练效率直接起飞。
结论:真想干预训练,数据团队是必须的,爬虫、采购、清洗、合成,一个都不能少。
二、数据清洗:别小看“脏活累活”
清洗是数据准备中最关键的一步,没有之一!
现在主流做法是用模型打分筛选数据,Llama3、Qwen2 都这么干。建议用 BERT 系列模型做打分器,结构轻、效果好、速度快。训练数据可以用 GPT4 标注,或者按来源设定规则(比如某些网站=高质量,某些=低质量)。
注意:打分器对代码、Markdown、LaTeX 不友好,容易误杀,得单独处理。比如 FineWeb 就几乎把代码洗没了。
别太纠结打分器的准确率,能用就行。花一个月优化打分器,不如早点进入训练阶段。还有,训练数据不需要全量,4K条就能训个差不多,别钻牛角尖。
打分只是参考,规则清洗才是大杀器:
- 文本长度、token比例、语言占比(zh/en/num)
- 是否含网址、敏感词(如“新冠”、“疫情”)、反动/色情内容
- 是否含“转载自”等版权信息
规则不丢人,洗不干净才丢人。但注意:别洗出“偏见数据”。比如英文占比高就去掉,结果模型只会中文,成了“单语模型”。
脱敏也得做:人名、电话、邮箱、版权信息、黄色/反动内容,统统清理干净。别等模型生成隐私信息被罚款,那成本更高。正则匹配虽笨,但最稳妥。
三、去重:T级数据的“瘦身”工程
数据去重是工程能力的大考,TB级数据不能靠Python for循环,得上 Spark/Hadoop 这类分布式框架。
先用 MinHash 做相似度计算,ChatGPT 都能帮你写。关键是:先定目标数据量,再定去重粒度。
- 想要10T?相似度阈值设80%
- 想要5T?设90%
去重不是越干净越好,而是“够用就行”。目前没人知道一条数据训几遍最优,所以别怕重复,只要相似文档之间隔得够远,影响就小。
还有,sentence级去重比 document级更难,但效果更好。量力而行,别硬上。
四、数据分类与配比:让模型“营养均衡”
怎么把代码、百科、新闻分开?训个分类器,BERT 就行,不用太准,大致分类即可。
不同类别,清洗和去重策略也不同:
- 代码类:清洗阈值高,去重阈值低
- 知识类:清洗阈值低,去重阈值高
- 优先保留打分高的文档
主流配比是:中文 : 英文 : 代码 = 4 : 4 : 2(逻辑类数据如 math、cot 视情况而定)
英文数据不能太少,中文语料质量和数量普遍不如英文,这是共识。原因可能是:
- 中文语言复杂度更高
- 中文互联网内容质量偏低
五、数据顺序:课程学习不是玄学
预训练不是乱序灌输,而是“有节奏的教学”。课程学习(Curriculum Learning) 已被多次验证有效。
同样1T数据,顺序不同,模型能力不同。比如先学“加减法”再学“微积分”,比反过来效果好。
灾难性遗忘始终存在,顺序影响遗忘程度。比如先A后B,A忘30%;先B后A,B忘20%。显然后者更优。
推荐做法:In-Context Pretraining(Llama 提出),按语义相似度拼接文档,构建连贯上下文。
注意:Llama 强调文档间不能“相互看见”,即用 attention_mask 隔离。但实践中,大多数团队不做 mask,效果差异不大。是否采用,建议自己实验。
六、数据流水线:让GPU永远“有饭吃”
预训练必须是动态数据加载,不可能一次性读几T数据。流程是:
读1B → 训1B → 读1B → 训1B → …
注意:模型输入的是 token id,不是原始文本。tokenization、concatenation、padding 必须提前完成,别让GPU等你。
因此,数据处理进程和模型训练进程必须解耦:
- 数据处理持续生成 part-00000.jsonl
- 训练进程始终有新数据可吃
- 每条数据记录使用次数,高频数据后续降权
数据块别太大,建议以B为单位(1B、2B、4B)。训练回退时损失小,checkpoint 更灵活。
小技巧:动态保存机制——训练代码检测某个文件夹下是否有名为“save”的文件,有则立即保存checkpoint,避免“看loss美丽却无法保存”的悲剧。
七、数据实验:别急着上主模型
别一上来就训大模型,先在小模型上做实验,把 scaling law 搞明白。
分三个阶段:
- 粗糙实验:小模型上跑不同配比、顺序,训500B数据,看loss曲线选最优
- 专业实验:多size小模型跑loss,结合scaling law推算大模型最优参数
- 创新实验:像Llama/DeepSeek那样,画“loss → benchmark”曲线,预测模型能力
scaling law 没死,只是放缓了。不信它,你就只能靠“玄学”训模型。
预训练没有回头路,实验阶段必须扎实。
训练阶段
分词器(Tokenizer)
扩展词表时很容易出错,尤其是涉及到字典树(Trie)结构时。比如,你新增了一个词“中华人民”,并配套了合并规则,结果可能导致“中华人民共和国”这个已有词无法被正确编码,从而丢失了它原本承载的语义信息。
因此,提前设计好一个高质量的 tokenizer 至关重要。这就像盖房子打地基,不能等房子歪了再临时加柱子。很多人尝试在 LLaMA 基础上扩展中文词表并继续预训练,但真的训出过效果惊艳的中文模型吗?
训练 tokenizer 的方法并不复杂:找一台大内存的 CPU 机器,准备一份大规模通用语料,然后用 BPE 或 BBPE 算法训练即可(代码 ChatGPT 能写)。不过有几个细节值得注意:
- 数字处理建议拆分:虽然 OpenAI 没这么做,但我们建议保留数字拆分逻辑,以避免模型在比较“9.9 和 9.11”这类问题时出错。
- 控制压缩比例:每个 token 对应多少个汉字需要权衡。压缩率太低,解码效率差;压缩率太高,词表过大,影响模型泛化能力。通常中文模型中,1 个 token 大约对应 1.5 个汉字是比较合理的。
- 清理脏数据:此前 GPT-4o 的词表泄露事件中,就发现了不少中文低俗、违法词汇,手动清洗是必要的。
- 业务导向优化:如果明确知道模型将用于某个垂直领域,比如医疗,可以提前将“阿莫西林”“青霉素”等高频词设为独立 token,提高压缩效率。
- 语言覆盖:中英文覆盖率要尽量高,小语种是否加入视具体业务需求而定。
- 词表与嵌入层预留空间:tokenizer 的 vocab_size 应比模型的 embedding_size 多出约 1000 个位置,以便后续对齐(alignment)阶段引入新 token。
顺便说一句,我不太理解“strawberry 有几个 r”这种问题为何总被拿出来讨论。这本质上是 tokenizer 无法处理的问题,模型答对了只能说明它背过,答不出来才是正常的。希望这类“噱头题”别再被拿来炒作,误导大众对 LLM 的理解。
网络结构选型
一句话总结:能抄 LLaMA 就别乱改。推荐使用 Rope + GQA + RMSNorm + SwiGLU 这套组合,稳定、成熟、坑少。小模型(如 1B)建议共享 embedding 和 lm_head 参数,以提升 layer 参数占比;大模型则无需共享。
预训练阶段成本极高,任何结构上的“创新”都必须慎之又慎。别为了发论文或宣传“超越 LLaMA”,就在小模型上跑几天实验,发现 loss 下降快就贸然改动结构。等真正上规模训练一个月后才发现问题,几千万的预算已经打水漂。老板问起来,你说“小模型上没出问题”——这不是找骂吗?
说实话,国内大多数大模型岗位并不鼓励“试错式创新”,老板们更看重的是快速复现、低成本追赶。除非你真的在一个鼓励探索的团队,否则盲目搞结构创新,风险极高。
模型参数设定
OpenAI、Google、Meta 等早期论文中提到的 7B、13B、33B、70B 等模型尺寸,确实有其道理,但也不能全信。这里从工程实践角度,聊聊如何选定模型规模。
核心依据:Scaling Laws(缩放定律)
-
OpenAI 的幂律关系(2020):
- 性能 ∝ 参数量^(-0.076)
- 性能 ∝ 数据量^(-0.095)
- 性能 ∝ 计算量^(-0.050)
-
Chinchilla 定律(DeepMind):
- 提出“参数与数据等比例增长”原则
- 模型参数翻倍,训练数据也应翻倍
为什么选 7B、13B、33B、70B?
-
成本与性能的平衡点:
- 训练成本 vs 推理成本
- 模型能力 vs 部署难度
- 内存占用 vs 计算效率
-
硬件适配性:
- 7B:单张 A100 可跑,适合研究
- 13B:需多卡,但仍可控
- 33B/70B:需分布式部署,性能更强
-
数学优化结果(Chinchilla):
- 最优参数 ≈ G × (预算/6)^(β/(α+β))
- 最优数据 ≈ G^(-1) × (预算/6)^(α/(α+β))
- 其中 α≈0.32,β≈0.28
实际趋势:超越 Chinchilla
为降低推理成本,越来越多模型选择“小参数 + 大数据”策略:
- LLaMA-2 70B:训练了 2T tokens
- LLaMA-3 70B:训练了 1.5T tokens(远超 Chinchilla 建议)
这些数字并非玄学,而是在理论最优与现实可行之间反复权衡后的结果。
模型尺寸选择建议
别一上来就按业务场景定模型大小(除非是数学、法律这类复杂任务)。小模型的潜力远未被挖尽,Qwen2.5 的 benchmark 也显示,更小的模型也能达到更高分数。很多时候,模型小了点,alignment 阶段也能通过过拟合业务数据“救回来”。
真正决定模型尺寸的,是以下两个现实因素:
-
训练资源:
- 你有多少卡?能跑多久?训练框架一天能处理多少 token?这些都能提前算出来。
- 比如目标是在 2 个月内训完 2T tokens,那就能反推出适合的模型规模。
- 建议跟大厂保持一致(如 7B、13B、33B、70B),别自己乱创尺寸,方便对比效果。
-
推理资源:
- 33B 模型刚好能塞进一张 80G 卡,72B 需要两张卡,稍微加长序列就 OOM。
- 如果你训了个 40B 模型,效果跟 72B 差不多,但部署成本一样,那还不如直接用 72B。
- 所以,模型尺寸得根据实际部署环境来定,别出现“一张卡装不下,两张卡浪费”的尴尬。
这也解释了为什么市面上有 65B、70B、72B、75B 等各种“奇怪”尺寸——它们都是为了适配实际部署资源而微调的结果。
关于模型 size 的设置建议
当前主流研究普遍认为:优秀的模型结构应具备“均衡”特性。也就是说,像 LLaMA 这类标准架构,在扩展模型规模时,层数(layer_num)与隐藏层维度(hidden_size)应同步增长,而非单独放大某一维度。LLaMA 论文中对此有明确的设计原则。
我的建议是:普通开发者无需在此过度创新,直接参考 LLaMA 的配比即可,减少试错成本,避免踩坑。
| 模型规模 | 隐藏维度 | 注意力头数 | 层数 | 学习率 | 批大小 | 训练 token 数 |
|---|---|---|---|---|---|---|
| 6.7B | 4096 | 32 | 32 | 3.0e-4 | 4M | 1.0T |
| 13.0B | 5120 | 40 | 40 | 3.0e-4 | 4M | 1.0T |
| 32.5B | 6656 | 52 | 60 | 1.5e-4 | 4M | 1.4T |
| 65.2B | 8192 | 64 | 80 | 1.5e-4 | 4M | 1.4T |
不过,具体数值的选择也有讲究:尽量选取能被 2、4、8、64、128 整除的数。这不是出于理论,而是训练框架的底层优化要求:
- layer_num:建议具备较多质因数,便于支持 pipeline 并行。比如 layer_num=30 就无法被 4 整除,导致无法使用 pipeline_size=4,除非手动调整代码,增加开发负担;
- num_head:最好是 8 的倍数,利于 tensor 并行。tensor_parallel 的上限通常为 8,超过后涉及跨机通信,效率骤降;
- hidden_size:建议为 128 的倍数,虽然目前无明确原因,但未来框架可能对此有优化;
- vocab_size:同样建议为 128 的倍数,预留兼容性。
此外,seq_len 的设定也需谨慎。即使业务需要长文本支持,也不建议一上来就用 32K 或 200K 的序列长度,attention 的计算复杂度是平方级的,成本极高。推荐方案是:
初期使用 4K 或 8K 长度,结合 RoPE 的小 base 训练大部分数据,再切换至 32K/64K 长度,使用大 base 微调剩余 10% 数据。NTK 外推已是业界通用做法。
训练框架选择:Megatron vs DeepSpeed
直接给出结论:
- 从零开始预训练(T 级 token):选 Megatron;
- 继续预训练或微调(B 级 token):可考虑 DeepSpeed。
Megatron(NVIDIA 出品)
优点:
- 训练效率高:tensor_parallel 与 pipeline_parallel 优化极致,RoPE 已集成 apex 算子,MLP 层也在开发中;
- 配置细致:argument.py 中参数丰富,能精细控制每一层是否使用 dropout 等;
- 加载速度快:千亿级模型也能在 1 分钟内加载完成,调试体验极佳。
缺点:
- 上手门槛高:需理解 torch 分布式通信,基建工作繁重(如格式转换脚本);
- 官方代码 bug 多:不预留一周调试时间,基本跑不起来。频繁 pull 最新代码反而容易引入新问题。
DeepSpeed(微软出品)
优点:
- 代码简洁:极易上手,model.trainer 封装强大;
- 社区活跃:alignment 阶段 90% 开源项目基于 DeepSpeed。
缺点:
- 训练效率低:相比 Megatron 有 10%~30% 的性能损耗;
- 加载极慢:小模型启动需十几分钟,大模型甚至半小时,调试效率极低;
- 可定制性差:封装过度,几乎无法修改核心逻辑;
- 隐性 bug 多:不像 Megatron 直接报错,DeepSpeed 的问题往往藏在训练现象中,排查困难。
同事名言:“遇到解释不了的问题,先别怀疑自己,先怀疑 DeepSpeed。”
Megatron-DeepSpeed(微软 & 英伟达联合)
这是两者的官方整合版,兼顾模型并行与内存优化,适合超大规模训练任务。
核心优势:
- 结合 DeepSpeed 的 ZeRO、数据并行、CPU Offload;
- 融合 Megatron 的 Tensor/Pipeline Parallelism;
- 支持训练万亿级参数模型(如 BLOOM)。
典型应用场景:
训练千亿参数模型时,可同时启用 Tensor Parallelism(模型分片)、Pipeline Parallelism(流水并行)与 ZeRO(显存优化),实现极致扩展。
三者的关系总结如下:
| 工具名称 | 核心能力 | 依赖关系说明 |
|---|---|---|
| DeepSpeed | ZeRO、数据并行、通用优化 | 可独立使用 |
| Megatron-LM | Tensor/Pipeline 模型并行 | 通常需配合数据并行框架使用 |
| Megatron-DeepSpeed | 整合上述两者,提供端到端方案 | 依赖 Megatron 与 DeepSpeed 两者 |
最后提醒一句:
无论选哪个框架,务必把 attention 实现换成 flash_attention,能显著提升训练速度与显存利用率,别用默认实现。
训练技巧
大模型训练侧必须掌握的工程要点
让 GPU 时间花在刀刃上
训练时把“通信距离”刻进脑子里:同卡 > 同机多卡 > 跨机。
显存够就尽量别拆模型:
- 先别上 tensor/pipeline/sequence parallel,也别把参数踢到 CPU offload;
- 能存就别重算,显存↔内存来回倒腾同样烧时间;
- 真要用并行,优先 data_parallel,它几乎不浪费 FLOPS。
盯紧那条 loss 曲线
pretrain 期间唯一要天天盯的就是 tensorboard 里的 loss。
- 必须拆 channel_loss:中文、英文、代码三条线各看各的,方便定位哪路数据掉链子。
- 任何 spike——暴涨或暴跌——都先当脏数据报警处理:
- 乱码会让 loss 飞天,全换行符会让 loss 贴地;
- 确认脏就回滚到上一个 ckpt,别硬洗。
- 数据没问题仍 spike?八成是优化器梯度爆炸,把 adamw 的 β1、β2、weight_decay 按 Llama 报告再调一遍,熬过前期 2~3 区间后基本就稳了。
四步曲跑完 pretrain
代码+数据就位后,按固定脚本走:
- warmup:lr 从 0 慢慢爬到峰值;
- 主阶段:cos/decay/constant 随你挑,先在小模型上试;
- 拉长上下文:把 rope base 加大、seq_len 拉长,让模型见识长文;
- anneal:喂高质量、IFT 数据做“考前冲刺”,完了直接拉去 benchmark 报道。
训练一旦点火就放手,卡没炸、loss 没蹦极就不用管;真炸 or 陡降(大概率数据重复)→回退 ckpt 重跑。
评估环节
为什么 pretrain 评估“看起来”最轻松
在整个 LLM 生命周期里,pretrain 阶段的评估是最“单纯”的:不需要测指令跟随、不管安全红线、也不查幻觉,只回答一个问题——“肚子里到底装了多少知识”。
1. 先盯 Loss(PPL)
- 老办法:拿百科、逻辑、代码各切一小块当 daily probe,每天记录测试 loss。
- 曲线允许小抖动,但大趋势必须一路向下,最后收敛。只要这些语料没进训练集,测试 loss 就该和训练 loss 同步下降。
- 注意:PPL 只能“自己跟自己比”。不同 tokenizer 的压缩率天差地别,全字符 tokenizer 天然 loss 更低。无论压缩率如何,通用知识集上的 loss 应压到 2 以下,否则就是训得不够。
2. 再聊 Benchmark——“刷榜原罪”
- 全程自己训的 checkpoint,benchmark 才勉强可信;一旦接手别人的权重(同事交接、开源下载),默认对方已刷过榜。
- 有宣发需求的团队必刷,不刷就躺平被碾压。此时 benchmark 考的不是“谁学得多”,而是“谁忘得少”——训得越久,分反而越低。
- 题型缺陷:主流 benchmark 全是“无 CoT 选择题”。人做题还得草稿纸,模型直接猜 ABCD,能力评估必然失真。
- 既然题库本身含金量高,就别浪费,改成生成式玩法:
- 把“Question + 选项”拆成四段文本,让模型综合后自由回答;
- 把正确答案替换成“其他选项全错”,看模型能否依旧揪出它;
- 把 ABCD 换成一二三四,打乱符号记忆;
- 多选变单选,或者反过来;
- 先拿题干当训练语料“洗”一遍,再让模型回答,检验是否死记硬背;
- ……玩法随意,核心目标只有一个:让背答案失效——考纲不变,换卷子。
- 格式不听话就给 few-shot 示例;停不下来就卡 max_new_token 或加 StoppingCriteria(遇到换行就停)。
- 评估指标只用 ACC,BLEU / ROUGE 太抽象,难做 case 分析。
3. 概率探针——盯“知识漂移”
- 想监测某项具体知识是否被遗忘,就建一个小探针集,看目标 token 或句子的概率涨跌。
- 探针得人工逐条打磨,无法批量生成;指标只看趋势,不看绝对值。
比较抽象,我举几个例子:

一句话总结
pretrain 评估=盯 Loss + 花式折腾 Benchmark + 概率探针看细节;自洽比绝对分更重要,趋势比数值更有说服力。