【论文阅读】MEDDINOV3:如何调整视觉基础模型用于医学图像分割?
【论文阅读】MEDDINOV3:如何调整视觉基础模型用于医学图像分割?
文章目录
- 【论文阅读】MEDDINOV3:如何调整视觉基础模型用于医学图像分割?
- 一、介绍
- 二、联系工作
- 三、方法
- 四、实验部分
MEDDINOV3: HOW TO ADAPT VISION FOUNDATION MODELS FOR MEDICAL IMAGE SEGMENTATION?
CT和MRI扫描中器官和肿瘤的准确分割对于诊断、治疗计划和疾病监测至关重要
大多数模型仍然是特定于任务的,缺乏跨模式和机构的通用性
在十亿级自然图像上预训练的视觉基础模型(FM)提供了强大且可转移的表示
适应医学成像面临两个关键挑战:
- 大多数基础模型的ViT主干在医学图像分割方面仍然表现不佳,
- 自然图像和医学图像之间的大域差距限制了可转移性
引入了MedDINOv 3,这是一个简单有效的框架,用于将DINOv3应用于医学分割
首先回顾了普通ViTs,并设计了一个简单有效的多尺度令牌聚合架构
在CT-3M上执行域自适应预训练
CT-3M是3.87M轴向CT切片的精选集合,使用多级DINOv 3配方来学习鲁棒的密集特征
MedDINOv 3在四个分割基准上达到或超过了最先进的性能,证明了视觉基础模型作为医学图像分割统一主干的潜力
一、介绍
计算机断层扫描(CT)和磁共振成像(MRI)等医学成像模式是现代放射学的核心
手动注释是劳动密集型和耗时的[4]。深度学习在自动化这一过程方面表现出很大的潜力
大多数现有的方法依赖于针对单个数据集或器官系统训练的高度专业化的架构
基础模型(FM)提供了一个有前途的解决方案,作为统一的视觉骨干,在大规模未标记数据上进行预训练,并可适应各种下游任务
自监督学习可以直接从原始像素进行训练,而无需手动注释,产生可转移的表示
如DINOv2 [15]和DINOv3 [16],在自然图像中取得了显着的成功,为分类,检测和分割任务提供了强大的全局和局部特征
从零开始获取数十亿规模的数据来训练医学视觉基础模型是不可行的
从网络规模的自然图像中学习到的表示是否可以有效地转移到放射成像中?我们的实验结果表明,DINOv3为医学图像分割提供了有前途的性能
当前的FM骨干是基于视觉变换器(ViTs)
我们提出了MedDINOv3,一个有效的框架,以适应医学图像分割的视觉基础模型
重新审视了2D医学图像分割的普通ViTs
ViT已被证明是可扩展的大规模预训练[19]
它仍然需要量身定制的组件,如ViT-Adapter [20]或Mask 2Former [21],以实现良好的分割性能
基于变换器的设计通常依赖于重卷积组件,并且仍然低于强CNN基线[6,22,23,24,25,26]
提出了一种用于2D医学图像分割的简单有效的Transformer架构。MedDINOv 3利用DINO ViT作为强大的视觉编码器
分层表示为解码器提供了更丰富的空间上下文,减轻了ViT的弱局部偏差
在CT-3M(一个大规模的CT图像集)上对MedDINOv3进行了域自适应预训练,以更好地将模型与放射学数据分布相匹配
gram锚定,一种防止局部特征崩溃的机制,是我们的预训练框架可选
系统地检查三个-DINOv3的阶段预训练配方,并量化每个阶段对分割性能的贡献
适应CT域后,我们的预训练MedDINOv 3以始终更高的分辨率生成平滑的特征图
贡献:
-
一个简单的2D医学分割的ViT架构
-
在CT-3M上进行域自适应预训练,通过三个阶段的过程来调整DINOv3:
-
全局/局部自蒸馏(DINOv 2风格)
-
稳定块级一致性的gram锚定
-
高分辨率自适应
-
-
四个公共CT/MRI基准测试的最新结果。四个不同的基准测试
二、联系工作
医学视觉基础模型
自监督学习已经成为开发医学视觉基础模型的关键策略,其动机是缺乏注释的医学数据
- 带有SSL预训练的SwinUNETR [4],在3D CT基准测试中显示出了实质性的改进。
- 也被应用于医学领域使自然图像FM(如DINOv2)适应放射学:
- Baharoon等人[18]证明,自然图像SSL特征可以很好地转移到分类中
尽管分割的性能落后于领域预训练的模型。我们的工作通过执行领域预训练来弥合这一性能差距。
自适应SSL预训练规模。
医学图像分割中的视觉变换器
- ransUNet [25]将Transformer层合并到U-Net的瓶颈中
- LeViT-UNet [32]遵循了类似的设计,具有高效的注意力
- UTNet [33]采用多分辨率的Transformer块
- CoTr [23]利用单个Transformer来联合建模跨分辨率的特征
- UNETR [22]直接采用了ViT编码器,代表了向变压器重型设计的转变
- SwinUNETR [6]集成了swin变压器
- Primus [27]等最新作品解构了复杂的解码器,并表明仅编码器架构可以接近CNN性能
我们的工作旨在通过改进架构设计和执行域自适应SSL预训练来充分实现ViTs在医学分割中的潜力
三、方法
虽然在大型数据集上预训练的视觉基础模型在自然图像中表现出了卓越的性能
但由于表示和不同架构设计的巨大差距,直接将其用于医学成像仍然是不可行的
提出了用于医学图像分割的视觉Transformer的迭代改进,使预训练的SSL模型能够集成
我们使用DINOv3对CT图像进行域自适应预训练,DINOv3是一种最先进的SSL方法,以学习上级密集特征而闻名
框架结构

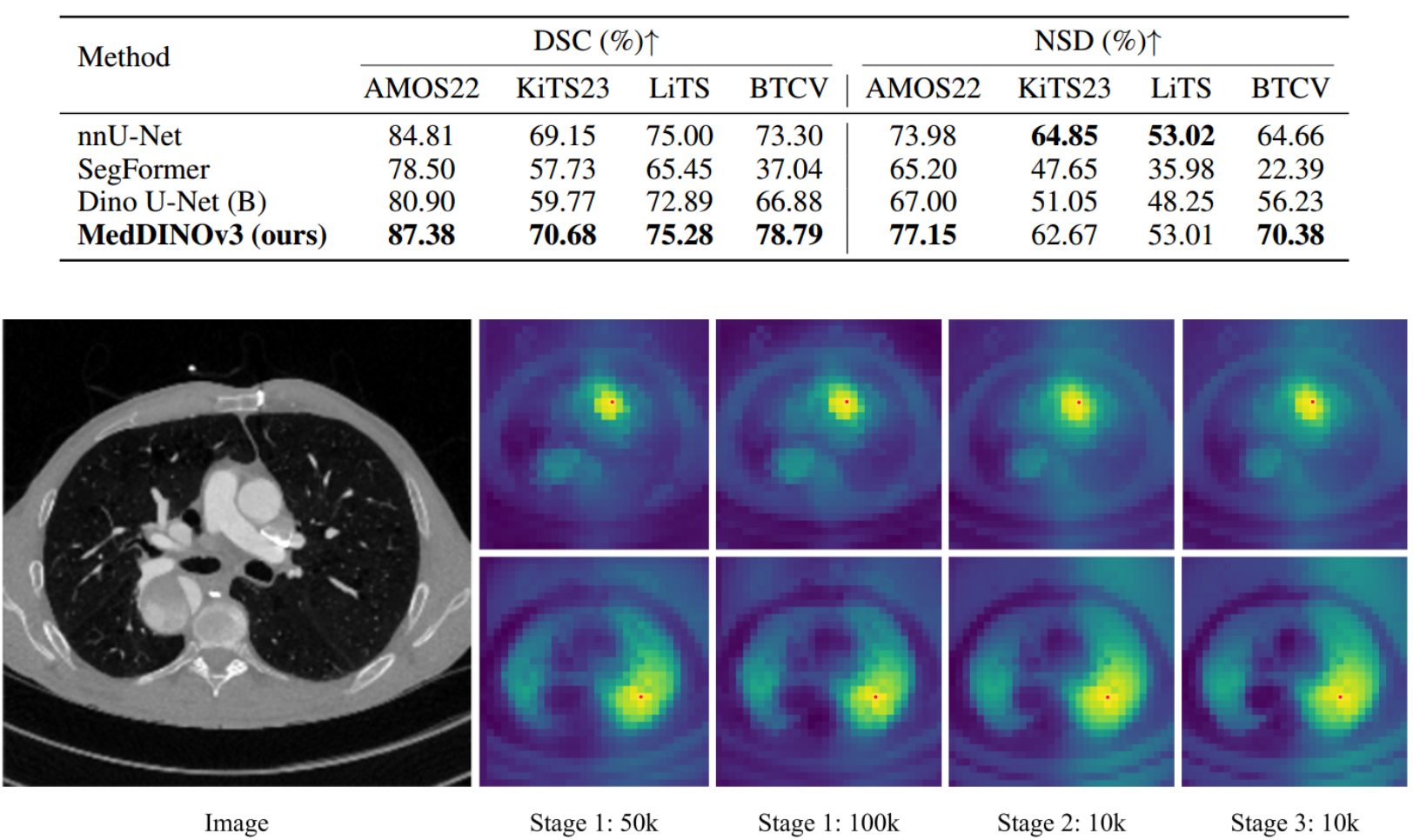
第1阶段:给定一个输入CT,我们将全局crop馈送给教师模型,将局部和Mask crop馈送给学生。自蒸馏损失应用于CLS令牌,Mask损失应用于密集补丁令牌
第2阶段:添加gram锚定。Gram教师可以看到更高分辨率的全局裁剪,并输出密集的特征图,调整大小以匹配学生的分辨率
第3阶段 :学生和教师都用更高分辨率的CT输入进行训练
在自然图像中具有很好的可扩展性,但视觉Transformer尚未实现医学图像分割的一致增益
分割模型中的Transformer块对最终性能的贡献很小,并且仍然低于强大的CNN基线
为了加强注意力的使用,Primus提出了一种简单的Transformer架构,该架构使用轻量级转置卷积解码器
Primus在3D体积分割中取得了令人满意的性能
Primus编码器将其补丁大小从16修改为8,这仍然是计算繁重的,并且不适合DINOv3风格的预训练
重新审视了用于2D医学图像分割的普通ViTs,并提出了逐步改进,以将DINOv3主干调整为有效的分割主干
开发数据集我们选择AMOS22
我们使用DINOv3 ViT编码器(ViT-B)和Primus解码器(由背靠背转置卷积、LayerNorm和GELU激活组成)来形成我们的基线
利用预训练的DINOv3为了提高表示质量,我们使用在LVD-1689M上预训练的DINOv3初始化ViT编码器
多尺度令牌聚合观察到Primus只使用最后一个Transformer块作为解码器的输入,我们假设这种缺乏分层先验的情况阻止了ViTs学习强的局部特征
建议重用来自多个中间层(块2,5,8,11)的补丁令牌,并将它们连接起来作为解码器的输入
更高的分辨率训练为了保留局部信息,Primus建议在标记化过程中将补丁大小从16减少到8
现有的视觉FM很少使用补丁大小8进行预训练,这可能是由于增加了计算开销
基于CT-3M的区域自适应预训练
使用多样化的大规模医学成像数据集CT-3M预训练MedDINOv 3,以更好地将其表示与医学成像对齐
遵循DINOv3开发的3阶段预训练配方
我们策展了一个大规模CT数据集CT-3M,共3,868,833个轴向切片,汇总了16个公开可用的数据集
阶段1 我们使用原始DINOv2损失进行预训练:图像级目标LDINO强制全局-局部裁剪不变性,块级潜在重建目标LiBOT学习局部块对应性,正则化损失LKoleo鼓励批内特征在潜在空间中均匀分布

阶段2 然而,DINOv2训练表明,随着训练的进行,全局损失往往占主导地位,导致补丁级质量的缓慢侵蚀
Gram锚定规则化了Gram矩阵,即图像中块特征的所有成对点积的矩阵
我们鼓励学生的Gram矩阵与早期模型的Gram矩阵对齐,称为Gram老师

这种损失只在所有patch token的全局作物上计算
我们将512 × 512的图像输入Gram老师,然后对生成的特征图进行2倍的下采样,以匹配学
阶段3 最后一阶段调整预训练模型以处理更高分辨率的图像
四、实验部分
评估数据集为了全面评估现有的2D分割方法,我们在四个公开可用的数据集上进行了广泛的实验
- KiTS 23
- LiTS
- BTCV