论文阅读:arxiv 2024 Large Language Model Enhanced Recommender Systems: A Survey
https://arxiv.org/pdf/2412.13432
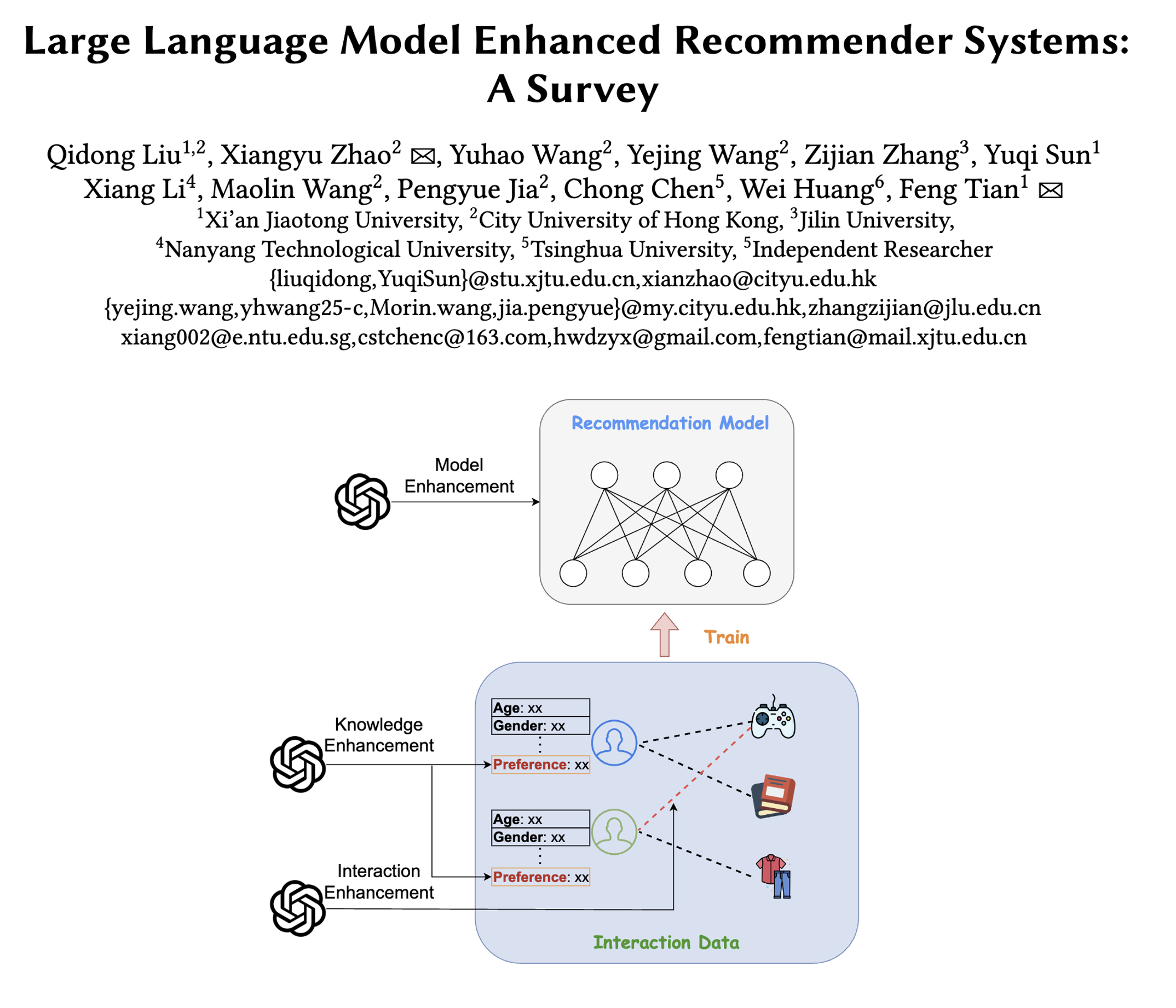
速览
大语言模型赋能推荐系统:综述与展望
该论文题为《Large Language Model Enhanced Recommender Systems: Taxonomy, Trend, Application and Future》,由来自西安交通大学、香港城市大学等多所高校的研究人员共同撰写,对大语言模型(LLM)增强推荐系统(LLMERS)的研究进展进行了全面综述。
随着LLM在自然语言理解与推理方面的强大能力逐渐显现,其在推荐系统领域的应用也备受关注。传统推荐系统主要依赖用户与物品之间的交互数据,而LLM能够为推荐系统补充丰富的语义信息,从而提升推荐效果。然而,早期将LLM直接应用于推荐的尝试面临着推理成本高昂的问题,难以满足实际应用中对低延迟的要求。因此,近年来研究者们开始探索将LLM融入推荐系统的在线系统,避免在推理阶段使用LLM,这一方向被称为LLM增强推荐系统(LLMERS)。
论文首先对LLMERS进行了分类,将其分为知识增强、交互增强和模型增强三大类。知识增强类方法利用LLM的推理能力和世界知识,为用户或物品生成文本描述作为额外特征,以补充传统推荐系统在知识理解方面的不足。例如,通过提示LLM输出用户偏好或物品属性的文本总结,这些总结文本经过编码后可增强推荐模型。交互增强类方法则针对传统推荐系统中数据稀疏性的问题,借助LLM生成新的用户与物品之间的交互数据,用于训练传统推荐模型。模型增强类方法直接将LLM的语义信息注入到传统推荐模型中,通过模型初始化、模型蒸馏、嵌入利用和嵌入引导等方式,提升推荐模型的性能。
论文还对LLMERS的发展趋势进行了分析。从语义角度来看,研究方向正从显式语义向隐式语义转变。显式语义是指通过LLM生成的自然语言文本,虽然可读性强,但在编码过程中可能会丢失信息;而隐式语义则是直接利用LLM的隐藏状态等非文本形式的语义信息,能够更好地保留LLM的语义知识。此外,开源LLM的使用越来越普遍,因为它们不仅可以节省调用API的成本,还可以通过微调来适应推荐任务。微调后的开源LLM能够更好地与推荐任务对齐,从而提高推荐效果。
在应用方面,LLMERS主要集中在那些具有丰富文本信息或特征的应用场景中。例如,在电子商务领域,用户和商品的特征信息可以被LLM理解并提取语义,从而增强推荐效果;在新闻推荐领域,LLM可以对大量新闻文本进行总结,为推荐系统提供语义支持。论文还总结了当前LLMERS研究中使用到的LLM类型,以及相关的应用领域和数据集资源,为后续研究提供了宝贵的参考。
最后,论文提出了未来LLMERS研究的几个方向。一是探索更多推荐任务的应用,如多模态推荐系统,LLM可以用于处理不同模态数据的语义提取和融合。二是加强用户侧的增强研究,目前大多数LLMERS工作集中在物品侧,用户侧的研究相对较少,但用户侧的增强对于提升推荐系统的个性化和准确性具有重要意义。三是提高推荐系统的可解释性,LLM的语义理解能力可以为推荐结果提供更合理的解释。四是建立LLMERS的基准测试,目前该领域尚缺乏统一的基准,建立基准测试有助于推动LLMERS研究的进一步发展。