从零实现一个简化版string 类 —— 深入理解std::string的底层设计
从零实现一个简化版 string 类 —— 深入理解 std::string 的底层设计
说明:本文聚焦 string 的实现细节与设计理由,代码使用一个教学用的 mini_string,并配有完整实现与测试用例。不讲 API 用法,而是解释“为什么要这么实现”。
文章目录
- 从零实现一个简化版 `string` 类 —— 深入理解 `std::string` 的底层设计
- 1. 引言
- 2. 基础设计 —— 为什么要有 `size` 和 `capacity`
- 3. 构造与析构 —— RAII 思想的体现
- 4. 拷贝赋值 —— 避免浅拷贝与资源泄漏
- 5. 容量管理 —— `reserve`、`shrink_to_fit` 与扩容策略
- 6. 元素访问 —— 性能与安全的取舍(`[]` vs `at()`)
- 7. 修改操作 —— 为什么 `insert` / `erase` 都是 O(n)
- 8. 查找与子串 —— 朴素实现的理由与复杂度
- 9. 迭代器 —— 直接返回指针的简单而有效
- 10. 小结与思考题
- 11. 完整代码实现
1. 引言
在 C++ 开发中,std::string 就像“空气”一样无处不在:拼接日志、处理配置、解析数据…… 我们随手就能写 s.push_back('a')、s.append("hello"),却很少追问为什么这些操作有特定的性能特征。
本文不讲“如何用 string”,而讲为什么要这样设计 string。我们用教学版 mini_string 来逐步展示 std::string 的核心实现思想:内存布局、扩容策略、拷贝/移动语义、迭代器规则等。读完你应当能回答:为什么 push_back 在大多数情况下是 O(1)?为什么 substr 会拷贝内存?为什么短字符串优化(SSO)能显著提升性能?
2. 基础设计 —— 为什么要有 size 和 capacity
最朴素的字符串只需要一个 char* 指针,并在末尾加 '\0'。但这会带来三个核心问题:
- 获取长度低效:
size()需要遍历到'\0',每次 O(n)。 - 频繁 realloc:每次追加若重新分配内存,会导致大量
new/delete,性能大幅下降。 - 易错且不兼容:忘记
'\0'会导致未定义行为,且不能良好与 C API 交互。
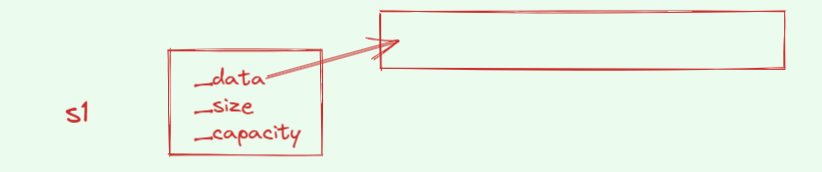
为了解决这些问题,mini_string 采用三个成员:
char* _data; // 指向动态分配的连续内存,末尾有 '\0'
size_t _size; // 当前逻辑长度(不含 '\0')
size_t _capacity; // 分配的容量(通常包含为 '\0' 预留的那 1 字节)
设计思想:
_size:快速得到长度(O(1)),避免频繁遍历。_capacity:记录已分配空间,避免小步扩容。_data保持连续并以'\0'结尾,兼容 C 风格字符串(c_str())。
这个模型是 std::string 的核心:既保证性能(常数时间的 size()、摊还常数的 push_back()),又保证兼容性
3. 构造与析构 —— RAII 思想的体现
C++ 推荐 RAII(Resource Acquisition Is Initialization):对象一旦创建就拥有并管理资源,析构时释放资源。
mini_string 的构造/析构要满足以下目标:
- 默认构造:保证对象是合法的、能调用
c_str()的(哪怕是空串)。 - 从 C 字符串构造:能从
const char*初始化。 - 拷贝构造:保证深拷贝,两个对象不会共享同一内存。
- 析构:释放动态分配的内存,避免泄漏。
示例:
// 默认构造:保证 _data 非空,且 _data[0] == '\0'
mini_string::mini_string(): _data(new char[1]), _size(0), _capacity(1) {_data[0] = '\0';
}// 用 C 字符串构造
mini_string::mini_string(const char* s) {_size = strlen(s);_capacity = _size + 1;_data = new char[_capacity];memcpy(_data, s, _capacity); // 包含 '\0'
}// 拷贝构造:深拷贝
mini_string::mini_string(const mini_string& other) {_size = other._size;_capacity = other._capacity;_data = new char[_capacity];memcpy(_data, other._data, _capacity);
}// 析构:释放资源
mini_string::~mini_string() {delete[] _data;_data = nullptr;_size = _capacity = 0;
}
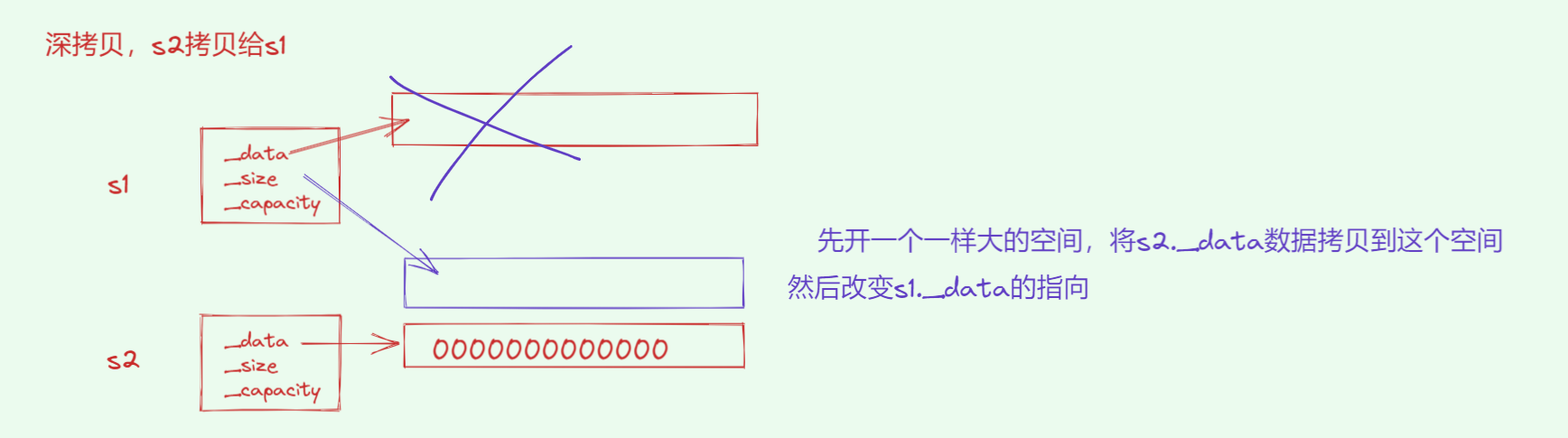
为什么要深拷贝?
如果使用浅拷贝(仅复制指针),两个对象会指向同一内存;其中一对象析构时会释放内存,另一个对象将变成野指针,导致严重错误。

4. 拷贝赋值 —— 避免浅拷贝与资源泄漏
构造函数之外,赋值运算符(operator=)也要注意资源管理。编译器默认生成的是成员逐一复制(浅拷贝),这在管理动态内存时不可接受。
正确做法是:
- 先检测自赋值
if (this != &other)。 - 释放当前对象的旧资源(
delete[] _data)。 - 根据
other的大小分配新内存并拷贝。 - 返回
*this的引用以支持链式赋值。
参考实现:
mini_string& mini_string::operator=(const mini_string& other) {if (this != &other) {delete[] _data;_size = other._size;_capacity = other._capacity;_data = new char[_capacity];memcpy(_data, other._data, _capacity);}return *this;
}
关键点:自我检测避免 a = a 导致释放自身内存后再访问;先释放再分配可以在内存受限时出错(可进一步改进为 copy-and-swap 技法以提高异常安全性),但教学版已足够说明核心问题。
5. 容量管理 —— reserve、shrink_to_fit 与扩容策略
问题:如果每次 push_back 都分配新的内存(按需扩容 1 字节),时间复杂度会非常高(大量 new/delete 与拷贝)。
策略:采用倍增(doubling)策略,使扩容次数降到对数级,从而将 push_back 的摊还复杂度降为 $ O(1)$。
关键操作:
reserve(new_cap):如果new_cap大于当前_capacity,则分配新空间并拷贝数据。通常调用者在已知最终大小时会用reserve预分配,避免多次扩容。shrink_to_fit():将_capacity缩小到_size + 1(保留 ‘\0’)。注意:这会导致内存重分配并使迭代器失效,因此应谨慎使用(通常在内存紧张时使用)。
实现要点(教学版):
void mini_string::reserve(size_t new_cap) {if (new_cap > _capacity) {char* new_data = new char[new_cap];memcpy(new_data, _data, _size + 1); // 含 '\0'delete[] _data;_data = new_data;_capacity = new_cap;}
}void mini_string::shrink_to_fit() {if (_capacity > _size + 1) {char* new_data = new char[_size + 1];memcpy(new_data, _data, _size + 1);delete[] _data;_data = new_data;_capacity = _size + 1;}
}
为什么 clear() 不释放内存?
clear() 只是把 _size 设为 0 并确保 '\0',不释放缓冲区。这样如果用户随后再次追加,能复用已分配的内存,减少分配次数,提高性能。只有在需要回收内存时才调用 shrink_to_fit()。
6. 元素访问 —— 性能与安全的取舍([] vs at())
字符串应提供两类访问接口:
operator[]:直接返回_data[i],不检查越界,性能最快。适合性能敏感但确信索引正确的场景。at():检查边界,越界抛出std::out_of_range,更安全但略慢。
实现示例:
char& mini_string::at(size_t i) {if (i >= _size) throw std::out_of_range("index out of range");return _data[i];
}
此外提供 front() / back() / c_str() 等便利函数。设计上给使用者“选择权”:性能优先或安全优先由使用者决定。
7. 修改操作 —— 为什么 insert / erase 都是 O(n)
关键约束:字符串必须保持连续内存,以保证 c_str() 和迭代器(指针)有效。因此:
- 插入字符需要把插入点之后的数据整体向后移动(
memmove/ 手写循环),位置越靠前移动长度越大。 - 删除字符需要把删除点之后的数据整体向前移动。
这注定了 insert / erase 的时间复杂度为 O(n)。
实现:
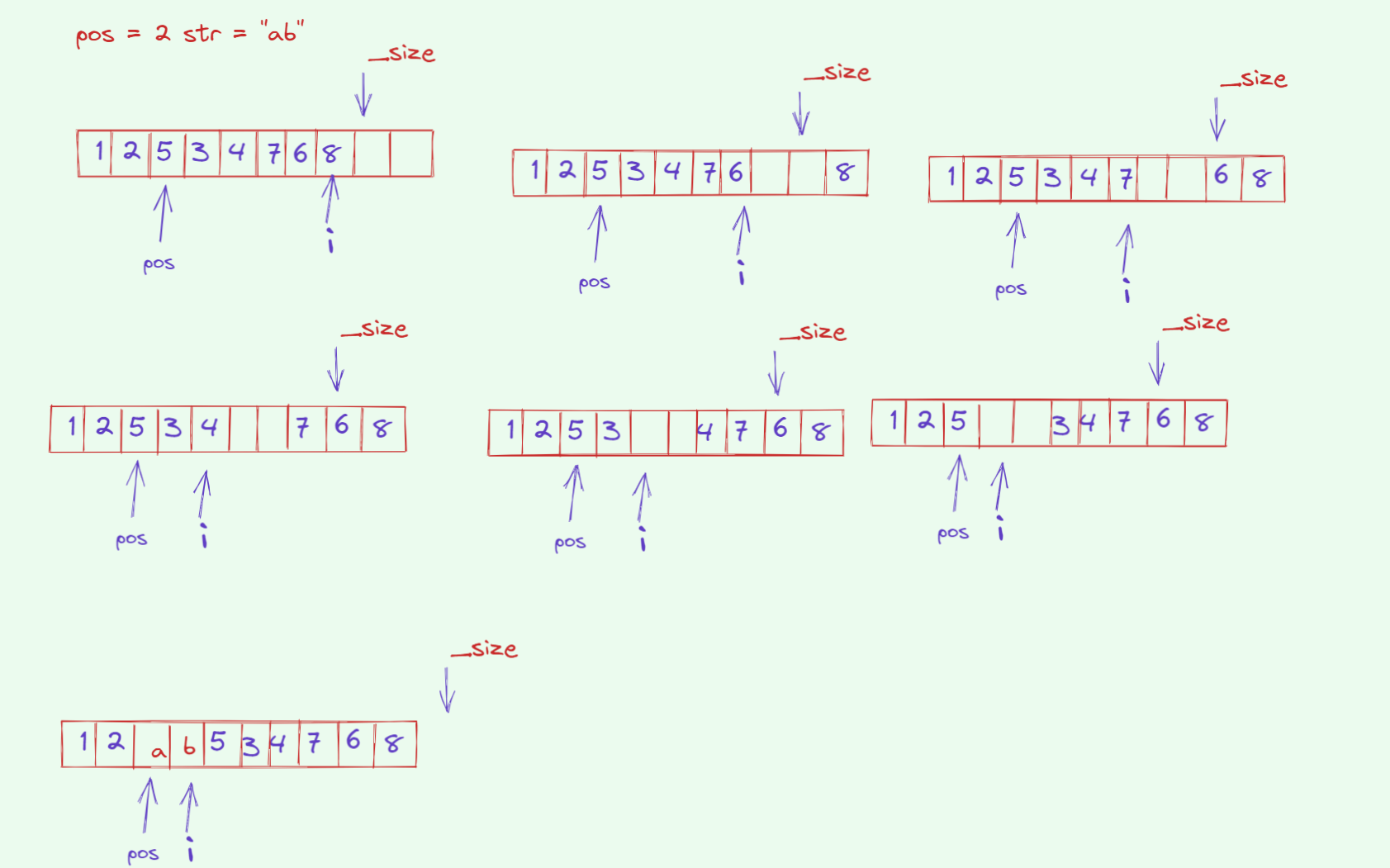
void mini_string::push_back(const char ch) {if (_size + 1 > _capacity) {size_t new_cap = _capacity == 0 ? 4 : 2 * _capacity;reserve(new_cap);}_data[_size] = ch;++_size;_data[_size] = '\0';
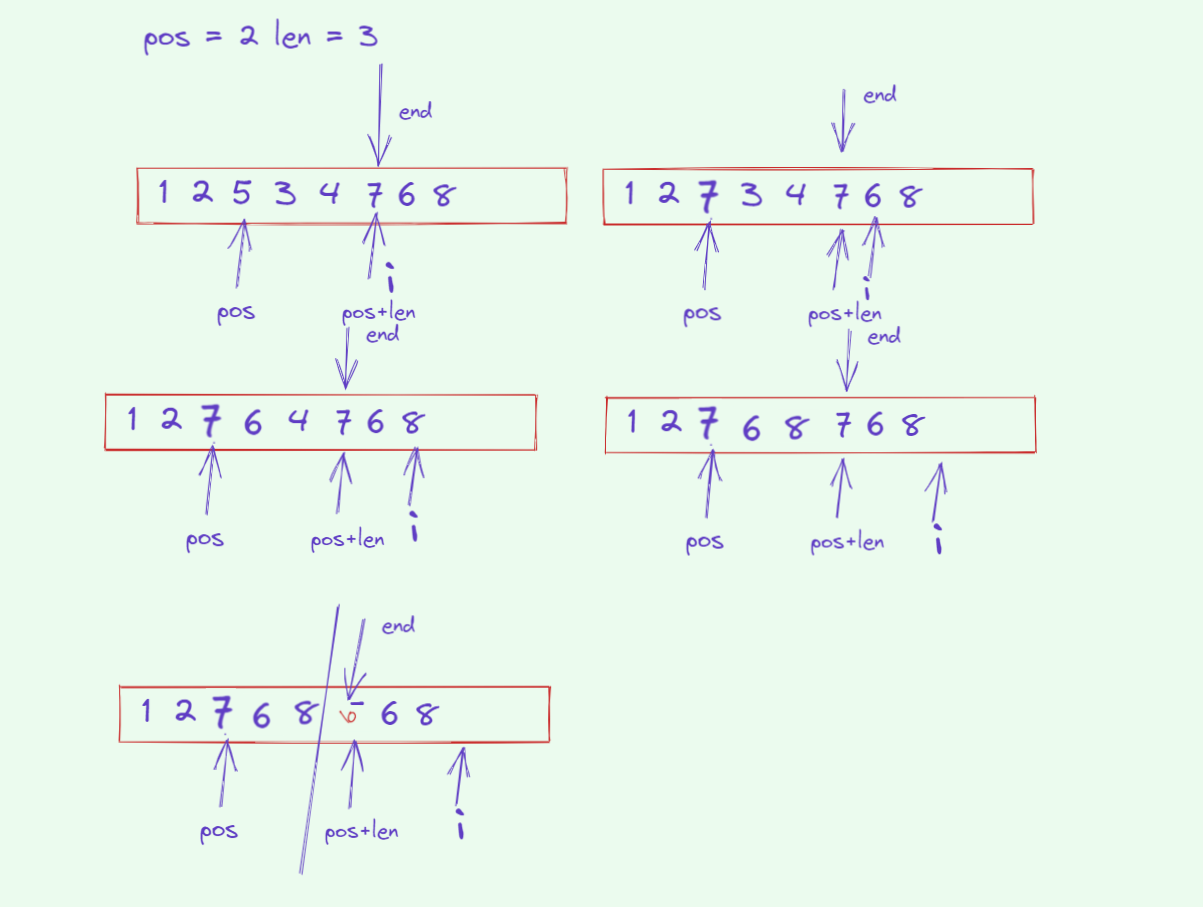
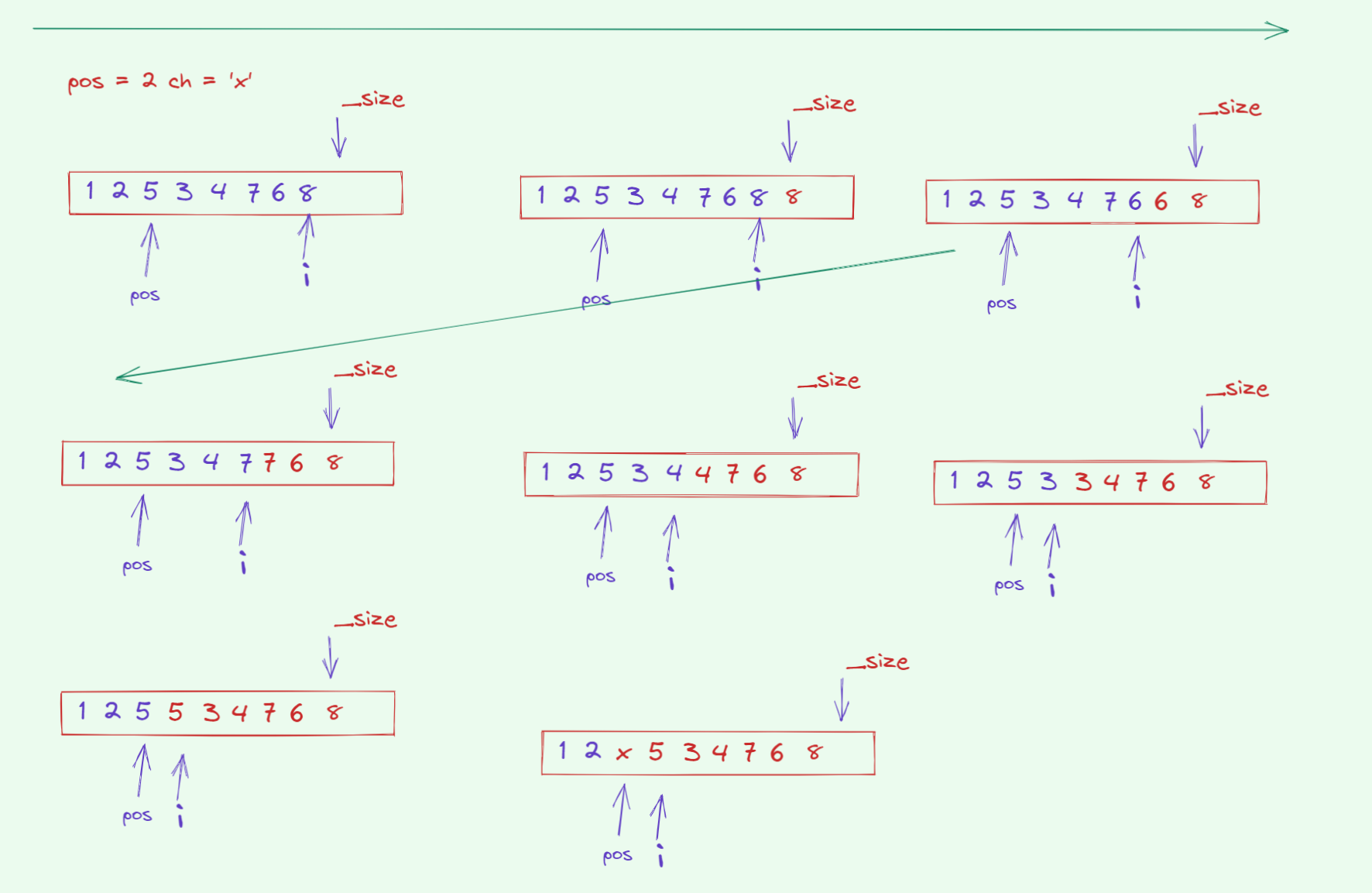
}void mini_string::insert(size_t pos, const char ch) {assert(pos <= _size);if (_size + 1 > _capacity) reserve(_capacity == 0 ? 4 : 2*_capacity);// 从后向前移动一个位置size_t i = _size;while (i > pos) {_data[i] = _data[i - 1];--i;}_data[pos] = ch;++_size;_data[_size] = '\0';
}void mini_string::erase(size_t pos, size_t len) {assert(pos <= _size);if (pos == _size) return;if (len > _size - pos) {_size = pos;} else {size_t i = pos + len;while (i < _size) {_data[i - len] = _data[i];++i;}_size -= len;}_data[_size] = '\0';
}
8. 查找与子串 —— 朴素实现的理由与复杂度
find():教学实现采用朴素子串匹配(strncmp 或逐字符比较),时间复杂度 O(n·m)。虽然理论上 KMP 等算法在某些模式集下更优,但标准库在实现上并不一定统一采用 KMP,因为:
- KMP 在构建部分匹配表时也有成本,且在很多短模式/短文本场景下朴素算法更快。
- 实际应用中查找多是短子串或不频繁调用,朴素足够且实现简单。
substr():返回一个新 mini_string,必须分配新内存并拷贝子串,复杂度 O(len)O(len)O(len)。
实现:
size_t mini_string::find(const char* target_str) const {size_t len = strlen(target_str);if (len == 0) return 0;for (size_t i = 0; i + len <= _size; ++i) {if (strncmp(_data + i, target_str, len) == 0) return i;}return npos;
}mini_string mini_string::substr(size_t pos, size_t len) const {assert(pos < _size);if (pos + len > _size) len = _size - pos;mini_string result;result.reserve(len);for (size_t i = 0; i < len; ++i) result.push_back(_data[pos + i]);return result;
}
9. 迭代器 —— 直接返回指针的简单而有效
因为内部存储就是连续的 char 数组,char* 自然满足随机访问迭代器的要求,所以直接返回 begin()/end() 为 _data 和 _data + _size 是最简洁高效的选择:
char* begin() { return _data; }
char* end() { return _data + _size; }
这样既能与 <algorithm> 无缝配合,也避免了额外的迭代器类型实现成本。
10. 小结与思考题
通过实现 mini_string,我们会更清晰地理解:
-
为什么
std::string要同时维护_size和_capacity(性能与可用性权衡)。 -
为什么
push_back能做到摊还$ O(1)$:倍增策略减少realloc。 -
为什么插入/删除要搬移大量数据(连续内存带来的代价)。
思考题(练手):
- 把
append(const char*)中的reserve改为reserve(_size + len + 1)(为'\0'留位),你能解释差别吗? - 尝试把
substr的实现改为使用memcpy(直接分配并拷贝一次),与push_back循环版在性能上有什么差别?为什么? - 如果你要为
mini_string添加移动构造与移动赋值,如何实现以保证noexcept?为什么noexcept很重要(特别是容器在移动元素时)?
11. 完整代码实现
// ======== mini_string.h ========
#include <iostream>
#include <cassert>
using namespace std;// 基本定义
class mini_string {
private:char* _data; // 字符数据size_t _size;// 实际字符数size_t _capacity; // 容量 不含'\0'static const size_t npos;
public:// ======= 构造&析构 ========mini_string(); // 默认构造mini_string(const char* str); // 用C格式字符串构造mini_string(const mini_string& str); // 拷贝构造~mini_string(); // 析构// ======= 赋值操作 ========mini_string& operator=(const mini_string& str);// ======= 元素访问 ========char& operator[](size_t i) { return _data[i]; } // 可以修改const char& operator[](size_t i) const { return _data[i]; } // 不能修改char& at(size_t i);char& front() { return _data[0]; } // 字符串首位索引char& back() { return _data[_size - 1]; } // 字符串末尾索引const char* c_str() const { return _data; } // 返回C格式字符串// ======= 容量操作 ========size_t size() const { return _size; }size_t capacity() const { return _capacity; }size_t clear() { _size = 0,_data[0] = '\0'; }bool empty() const { return _size == 0; }void reserve(size_t new_cap);void shrink_to_fit();// ======= 查找操作 ========size_t find(const char target_char) const; // 查找字符串中有无目标字符size_t find(const char* target_str) const; // 查找字符串中有无目标字符串mini_string substr(size_t pos, size_t len) const; // 截取子串// ======= 修改操作 ========void push_back(const char ch); // 尾插mini_string& append(const char* str); // 结尾追加一个C格式字符串mini_string& append(const mini_string& str); // 结尾追加一个mini_string类字符串void erase(size_t pos, size_t len); //从pos位置开始删除len个长度字符void insert(size_t pos, const char ch);// 在pos位置之后插入一个字符void insert(size_t pos, const char* str);// 在pos位置之后插入一个字符串mini_string& operator+=(const char ch);mini_string& operator+=(const char* str);mini_string& operator+=(const mini_string& str);// ======= 迭代器 ========typedef char* iterator;typedef char* const_iterator;iterator begin() { return _data; }iterator end() { return _data + _size; }/*const_iterator begin(){ return _data; }const_iterator end() { return _data + _size; }*/
};// ======= 流操作 =========
istream& operator>>(istream& is, const mini_string& str);
ostream& operator<<(ostream& os, mini_string& str);// ======== mini_string.cpp ========
#include "mini_string.h"
const size_t mini_string::npos = -1;
// ======= 构造&析构 ========
// 默认构造:分配 1 字节,存放 '\0'
mini_string::mini_string(): _data(new char[1]), _size(0), _capacity(1)
{_data[0] = '\0';
}// 用 C 字符串构造
mini_string::mini_string(const char* s) {_size = strlen(s);_capacity = _size + 1;_data = new char[_capacity];// 拷贝s到_datamemcpy(_data, s, _capacity);
}// 拷贝构造:深拷贝
mini_string::mini_string(const mini_string& str) {_size = str._size;_capacity = str._capacity;_data = new char[_capacity];memcpy(_data, str._data, _capacity);
}// 析构函数:统一释放
mini_string::~mini_string() {delete[] _data;_data = nullptr;_size = _capacity = 0;
}// ======= 元素访问 ========
// 访问指定位置的字符
char& mini_string::at(size_t i) {if (i >= _size) throw std::out_of_range("index out of range");return _data[i];
}// ======= 赋值操作 ========
mini_string& mini_string::operator=(const mini_string& str) {// 防止自赋值if (this != &str) {delete[] _data;_size = str._size;_capacity = str._capacity;_data = new char[_capacity];memcpy(_data, str._data, _capacity);}return *this;
}// ======= 容量操作 ========
void mini_string::reserve(size_t new_cap) {// 只有传递的新容量够大才扩容if (new_cap > _capacity) {// 开一个新容量的空间 释放旧空间 指向新空间char* tmp = new char[new_cap];memcpy(tmp, _data, _size + 1);delete[] _data;_data = tmp;_capacity = new_cap;}
}
// 缩小容量
void mini_string::shrink_to_fit() {// 这个1是为了多存'\0'if (_size + 1 > _capacity) {// 开一个新容量的空间 释放旧空间 指向新空间char* tmp = new char[_size + 1];memcpy(tmp, _data, _size + 1);delete[] _data;_data = tmp;_capacity = _size + 1;}
}// ======= 修改操作 ========void mini_string::push_back(const char ch) {// 先扩容if (_size + 1 > _capacity) {size_t new_cap = _capacity == 0 ? 4 : 2 * _capacity;reserve(new_cap);}_data[_size] = ch; // 插入新字符++_size; // 先更新长度_data[_size] = '\0';// 此时_size已+1,结尾符位置正确
}mini_string& mini_string::append(const char* str) {size_t len = strlen(str);if (_size + len > _capacity) reserve(_size + len);memcpy(_data + _size, str, len);_size += len;_data[_size] = '\0';return *this; // 返回当前对象的引用,无拷贝
}mini_string& mini_string::append(const mini_string& str) {size_t len = str.size();if (_size + len > _capacity) reserve(_size + len);memcpy(_data + _size, str.c_str(), len);_size += len;_data[_size] = '\0';return *this; // 返回当前对象的引用,而非拷贝
}void mini_string::erase(size_t pos, size_t len) {// 边界检查assert(pos <= _size);// 如果pos在末尾,不用操作if (pos == _size) return;// 如果len足够长 有多少删多少if (len > _size - pos) {_data[pos] = '\0';_size = pos;}else {// 老老实实挪动size_t i = pos + len; while (i < _size) {_data[i - len] = _data[i];++i;}_size -= len;}_data[_size] = '\0';// 一定不要忘了字符串结尾
}
void mini_string::insert(size_t pos, const char ch) {// 边界检查assert(pos <= _size);// 先扩容if (_size + 1 > _capacity) {size_t new_cap = _capacity == 0 ? 4 : 2 * _capacity;reserve(new_cap);}size_t i = _size; while (i > pos) {_data[i] = _data[i - 1];--i;}_data[pos] = ch;++_size; // 先更新长度_data[_size] = '\0';// 结尾符位置为新的_size
}void mini_string::insert(size_t pos, const char* str) {// 边界检查assert(pos <= _size);size_t len = strlen(str);if (_size + len > _capacity) reserve(_size + len); // 扩容// 将 [pos, _size) 区间的字符向后移动 len 位size_t i = _size;while (i > pos) {_data[i + len - 1] = _data[i -1];--i;}// 把目标字符串拷贝从pos位置开始拷贝memcpy(_data + pos, str, len);_data[_size + len] = '\0';_size += len;
}
mini_string& mini_string::operator+=(const char ch) {push_back(ch);return *this;
}
mini_string& mini_string::operator+=(const char* str) {append(str);return *this;
}
mini_string& mini_string::operator+=(const mini_string& str) {append(str);return *this;
}
// ======= 查找操作 ========
size_t mini_string::find(const char target_char) const {for (size_t i = 0; i < _size; i++){if (_data[i] == target_char) return i;}return npos;
}
size_t mini_string::find(const char* target_str) const {size_t len = strlen(target_str);if (len == 0) return 0;for (size_t i = 0; i + len <= _size; ++i) {if (strncmp(_data + i, target_str, len) == 0) return i;}return npos;
}mini_string mini_string::substr(size_t pos, size_t len) const {// 越界判断assert(pos < _size);// 计算实际长度:不能超过剩余字符数if (pos + len > _size) {len = _size - pos;}// 用已有的构造函数来完成拷贝mini_string result;result.reserve(len); // 提前分配内存,避免多次扩容for (size_t i = 0; i < len; ++i) {result.push_back(_data[pos + i]);}return result;
}// ========test_mini_string.cpp========
#include <iostream>
#include "mini_string.h"
using namespace std;int main() {cout << "===== 构造 & 输出 =====" << endl;mini_string s1("Hello");mini_string s2("World");mini_string s3; // 默认构造cout << "s1: " << s1 << endl;cout << "s2: " << s2 << endl;cout << "s3 (empty): " << s3 << endl;cout << "\n===== 拷贝 & 赋值 =====" << endl;mini_string s4 = s1; // 拷贝构造mini_string s5;s5 = s2; // 赋值cout << "s4 (copy of s1): " << s4 << endl;cout << "s5 (assigned from s2): " << s5 << endl;cout << "\n===== 拼接 operator+= =====" << endl;s1 += ' ';s1 += s2;cout << "s1 after += : " << s1 << endl;cout << "\n===== append & push_back =====" << endl;s5.append("!!!");s5.push_back('?');cout << "s5 after append/push_back: " << s5 << endl;cout << "\n===== insert & erase =====" << endl;mini_string s6("abcdef");s6.insert(3, "XYZ"); // 在 d 之前插入 "XYZ"cout << "s6 after insert: " << s6 << endl;s6.erase(2, 4); // 删除从下标2开始的4个字符cout << "s6 after erase: " << s6 << endl;cout << "\n===== substr =====" << endl;mini_string s7("substring_test");mini_string sub = s7.substr(3, 6);cout << "s7: " << s7 << endl;cout << "s7.substr(3,6): " << sub << endl;cout << "\n===== 比较运算 =====" << endl;cout << boolalpha;cout << "\"abc\" == \"abc\" ? " << (mini_string("abc") == mini_string("abc")) << endl;cout << "\"abc\" < \"abd\" ? " << (mini_string("abc") < mini_string("abd")) << endl;cout << "\"zzz\" > \"aaa\" ? " << (mini_string("zzz") > mini_string("aaa")) << endl;cout << "\n===== clear & empty =====" << endl;s4.clear();cout << "s4 cleared, empty? " << s4.empty() << endl;cout << "\n===== reserve & shrink_to_fit =====" << endl;mini_string s8("capacity");cout << "before reserve, capacity: " << s8.capacity() << endl;s8.reserve(50);cout << "after reserve(50), capacity: " << s8.capacity() << endl;s8.shrink_to_fit();cout << "after shrink_to_fit(), capacity: " << s8.capacity() << endl;cout << "\n===== 运算符+ (拼接返回新对象) =====" << endl;mini_string s9 = mini_string("Hi") + mini_string(", ") + mini_string("GPT!");cout << "s9: " << s9 << endl;return 0;
}