RDMA和RoCE有损无损
随着互联网, 人工智能等兴起, 跨机通信对带宽和时延都提出了更高的要求, RDMA技术也不断迭代演进, 如: RoCE(RDMA融合以太网)协议, 从RoCEv1 -> RoCEv2, 以及IB协议,Mellanox的RDMA网卡cx4,cx5, cx6/cx6DX, cx7等, 本文主要基于CX5和CX6DX对RoCE技术进行简介, 一文入门RDMA和RoCE有损及无损关键技术
Nvidia Mellanox重于诸多网络细节问题的实现, 把更多的选择留给了用户(用户理解后选择启用或禁用)
RoCE:
RDMA融合以太网, 继承RDMA所有的优势
基于融合以太网的RDMA(英语:RDMA over Converged Ethernet,缩写RoCE)是一个网络协议,允许在一个以太网网络上使用远程直接内存访问(RDMA)。RoCE有RoCE v1和RoCE v2两个版本。RoCE v1是一个以太网链路层协议,因此允许同一个以太网广播域中的任意两台主机间进行通信。RoCE v2是一个网络层协议,因而RoCE v2数据包可以被路由。虽然RoCE协议受益于融合以太网网络的特征,但该协议也可用于传统或非融合的以太网网络。
RoCE v1
RoCE v1协议是一个以太网链路层协议,Ethertype为0x8915。它要符合以太网协议的帧长度限制:常规以太网帧为1500字节,巨型帧为9000字节。
RoCE v2
RoCEv2协议构筑于UDP/IPv4或UDP/IPv6协议之上。UDP目标端口号4791已保留给RoCE v2。[10]因为RoCEv2数据包是可路由的,所以RoCE v2协议有时被称为Routable RoCE[11]或RRoCE。虽然一般不保证UDP数据包的传达顺序,但RoCEv2规范要求,有相同UDP源端口及目标地址的数据包不得改变顺序。除此之外,RoCEv2定义了一种拥塞控制机制,使用IP ECN位用于标记,CNP[12]帧用于送达通知。[13]软件对RoCE v2的支持在不断涌现。Mellanox OFED 2.3或更高版本支持RoCE v2,Linux内核v4.5也提供支持。[14]
RoCE与InfiniBand相比
RoCE定义了如何在以太网上执行RDMA,InfiniBand架构规范则定义了如何在一个InfiniBand网络上执行RDMA。RoCE预期为将主要面向聚类的InfiniBand应用程序带入到一个寻常的以太网融合结构。[15]有人[谁?]认为,InfiniBand将会继续提供比以太网更高的带宽以及更低的延迟。[16]
RoCE与InfiniBand协议之间的技术差异:
- 链路级流量控制:InfiniBand使用一个积分算法来保证无损的HCA到HCA通信。RoCE运行在以太网之上,其实现可能需要“无损以太网”以达到类似于InfiniBand的性能特征,无损以太网一般通过以太网流量控制或优先流量控制(PFC)配置。配置一个数据中心桥接(DCB)以太网网络可能比配置InfiniBand网络更为复杂。[17]
- 拥塞控制:Infiniband定义了基于FECN/BECN标记的拥塞控制,RoCEv2则定义了一个拥塞控制协议,它使用ECN标记在标准交换机中的实现,以及CNP帧用于送达确认。
- 可用的InfiniBand交换机始终有比以太网交换机更低的延迟。一台特定类型以太网交换机的端口至端口延迟为230纳秒[18],而有相同端口数量的一台InfiniBand交换机为100纳秒[19]。
RoCE与iWARP相比
相比RoCE协议定义了如何使用以太网和UDP/IP帧执行RDMA,iWARP协议定义了如何基于一个面向连接的传输(如传输控制协议,TCP)执行RDMA。RoCE v1受限于单个广播域,RoCE v2和iWARP数据包则可以路由。在大规模数据中心和大规模应用程序(即大型企业、云计算、Web 2.0应用程序等[20])中使用iWARP时,大量连接的内存需求,以及TCP的流量和可靠性控制,将会导致可扩展性和性能问题。此外,RoCE规范中定义了多播,而当前的iWARP规范中没有定义如何执行多播RDMA。[21][22][23]
iWARP中的可靠性由协议本身提供,因为TCP/IP为可靠传输。相比而言,RoCEv2采用UDP/IP,这使它有更小的开销和更好的性能,但不提供固有的可靠性,因此可靠性必须搭配RoCEv2实现。其中一种解决方案是,使用融合以太网交换机使局域网变得可靠。这需要局域网内的所有交换机支持融合以太网,并防止RoCEv2数据包通过诸如互联网等不可靠的广域网传输。另一种解决方案是增加RoCE协议的可靠性(即可靠的RoCE),向RoCE添加握手,通过牺牲性能为代价提供可靠性。
两种协议哪种更好的问题取决于供应商。英特尔和Chelsio建议并独家支持iWARP。Mellanox、Xilinx以及Broadcom推荐并独家支持RoCE/RoCEv2。思科同时支持RoCE[24]与自家的VIC RDMA协议。网络行业中的其他供应商则同时提供两种协议的支持,这些供应商如Marvell、微软、Linux和Kazan。[25]
两种协议都经过了标准化,iWARP是IETF定义的基于以太网的RDMA,RoCE是InfiniBand贸易协会定义的基于以太网的RDMA [26]
术语
WQE: 工作队列元素, 可发音(wuki)
CQE: 完成队列元素, 可发音(cookie)
RDMA Atomic: 原子操作, 主要用于分布式锁, Redis缓存等场景
DCQCN: 数据中心量化拥塞通知
ZTR(Zero Touch RoCE)这是一种简化RoCE配置和部署的技术。它允许网络管理员在不进行手动配置的情况下,自动启用和优化RoCE网络,从而提高部署效率和网络性能。
PCP(Priority Code Point): 优先级代码点用于对网络流量进行分类和管理,并在第 2 层以太网中提供 QoS。 它使用 VLAN 标头中的 3 位 PCP 字段对数据包进行分类。 差分服务或DiffServ使用 IP 标头中 8 位 DS 字段中的 6 位 DSCP 进行数据包分类
ECN: 显式拥塞通知 (Explicit Congestion Notification) 是互联网协议和传输控制协议的扩展,在 RFC 3168 (2001) 中定义。 ECN 允许在不丢失数据包的情况下进行网络拥塞的端到端通知。 ECN 是一项可选功能,当底层网络基础设施也支持时,可以在两个启用 ECN 的端点之间使用
DSCP(differentiated services code point): 差分服务代码点, 差分服务或 DiffServ 是一种计算机网络体系结构,它指定了一种在现代 IP 网络上分类和管理网络流量并提供服务质量 (QoS) 的机制。 例如,DiffServ 可用于为语音或流媒体等关键网络流量提供低延迟,同时为 Web 流量或文件传输等非关键服务提供尽力而为的服务。DiffServ 在 IP 标头的 8 位差分服务字段(DS 字段)中使用 6 位差分服务代码点 (DSCP),用于数据包分类。 DS 字段取代了过时的 IPv4 TOS 字段
Cos: class of service 服务分类
CX-6 DX: Datacenter系列
OOS: out of sequence, 出现乱序
PSN: package sequence num, 包序号, 一个包按MTU拆分成多个包, 每个包有个序号PSN
CNP: congestion notification packet 拥塞通知包
RP: reaction point 响应通知的一端(被动方)
NP: notification point 发起通知的一端(主动方)
TO: trade off, 权衡
BDP: bandwidth-delay product 在数据通信中,带宽延迟乘积是数据链路容量(以比特/秒为单位)与其往返延迟时间(以秒为单位)的乘积
PFC:是指Priority-based Flow Control,即基于优先级的流控机制
QPC:数据中心量化拥塞通知(Data Center Quantized Congestion Notification):是一种用于 RDMA(Remote Direct Memory Access)网络的端到端拥塞控制方案,结合了优先级流控制(PFC)和显式拥塞通知(ECN)技术
无损网络和有损网络
无损网络近来越来越多被提到,无损网络似乎是RDMA的必须,为了减轻主机侧的负载(这是 RDMA 的目标之一),网络就要承担复杂,因此,RoCE为 RDMA 承诺了一个无损链路层,这样 RDMA 就不必再实现丢包重传那些东西了。可靠传输是在底层保证的,而不是在传输层保证的。
但物理链路不可能无损,这就好像交通事故一定会发生一样,所有无损网络链路层均需要提供可靠传输,它们本质上就是一个可靠传输承载协议。可靠传输一定要应对并解决丢包,乱序问题,而方法就是ARQ,FEC此类,go-back-n,sack 只是例子。
另一方面,几乎所有可靠传输协议无一例外都避不开TCP的影响,至少任何一个新协议都要保持 TCP 友好,对 TCP 公平。所有可靠传输都要高效且公平,于是大家纷纷学 TCP 的样子来做。可 TCP 的存在正是因为底层链路不可靠的缘故,而不是它必须存在。
如果底层是一个无损网络,谁还会用 TCP。如何做一个可靠传输协议应该关注底层可靠性,而不是学 TCP。
即使底层不是一个完全的无损网络,只要它足够可靠,传输层协议也会大有不同。在目前的数据中心以及广域骨干链路这种足够可靠几乎无损的环境,假设我们忘掉 TCP,类 TCP 的可靠传输协议有多大概率会被重新引入。
在重新引入类 TCP 协议前,不得不重新评估它自身的负担。整个互联网超过一半的流量是 TCP 流量,其中又有几乎 1/4 到 1/3 的流量是pure ACK,而 ACK 仅仅为了提供一个滑动窗口时钟并辅助测量,这已经是非常大的负担。 TCP 才是问题本身,而不是解决方案。
在丢包率不足 0.01% 的网络如何应对丢包和丢包率超过 10% 的网络应对丢包的策略完全不同。为万里挑一的丢包引入源源不断的 pure ACK 时钟仅为指示丢包非常不划算,pure ACK 传递的永远是有效信息,比如拥塞指示,吞吐反馈,以及其它变化量,pure ACK 应边沿触发而非水平触发。
丢包率极低的准可靠网络环境,无论 go-back-n,sack,rto 等 ARQ 还是 FEC 都不划算,都不如应用程序发现问题主动请求重传。传输层将大大简化。目前数据中心网络 transport 都在陆续走上这条路,丢包是 app-aware,而不是 transport-aware。
但 TCP 诞生的 1970 年代,底层信道质量远非可靠,主机资源有限,TCP 就是最优解。TCP 随后的迭代始终保持着该基因,即底层信道是不可靠的,无论 fast retransmit,sack,rack 都在基于此认同上进行优化。因为 TCP 太成功了,以至于几乎成了唯一解,即使链路信道质量已经好到不再需要像 TCP 那般谨慎了,甚至可靠传输本身已经廉价到可由应用程序自己负责了,几乎所有的新传输协议还是无法摆脱 TCP 的影子。
再往底层说,数据中心网络链路信道已经如此可靠,RoCE 却像极了一个链路层的 TCP,go-back-n,ECN...总之还是 TCP 那一套,以至于这些底层协议依然假定,信道是会发生丢包的,丢包需要被应对,这和 TCP 基因里的假设没有任何区别。
首先,可靠传输不仅仅只是 TCP,go-back-n,ECN 也不仅仅属于 TCP,它们是任何可靠传输的选项。其次我们再来看丢包。丢包分误码丢包和拥塞丢包,现如今的误码丢包已经非常罕见,但拥塞丢包大多数还是自找的。
拥塞丢包,简单说就是发的太多了,为了应对这种情况,需要拥塞控制。拥塞控制分分布式和集中式两类。早期关于互联网设计哲学的辩论,倾向于将互联网设计成了胖端瘦网的分布式结构,几乎于此同时,以太网成功占领了互联网的枝端,而以太网本身也是分布式控制网络,它和互联网基本是一回事。
和互联网交换机 buffer 溢出丢包一样,以太网在重试次数超过一定阈值后会放弃重试而丢包,而最大重试次数表示的就是一个有最大值限制的最大等待时间,以太网丢包策略几乎就是一个完备的 RED。无论交换机还是以太网,都没有中心控制器对拥塞源进行抑制,需要指示拥塞并付出了丢包代价时,拥塞肯定已经发生了,这是互联网和以太网的基因,它们都是有损网络。
将传输协议和网络结合,要么像 RoCE 在有损网络上提供无损链路层,要么像 TCP 在有损网络上提供无损传输层,二者是一回事,区别在于 RoCE 卸载了 CPU 的负担,而 TCP 必须由 CPU 处理。
整体回顾,我们发现 TCP 也好,RoCE 也好,它们与互联网以及以太网是契合的。互联网和以太网提供了一个有损网络,这也是上层协议的唯一假设。
真正的无损网络必须引入中心控制,彻底摆脱由于拥塞导致的丢包,可参考infiniband,ATM等实现,而不是在以太网上打 patch,以太网再打 1000 个 patch 也还是修修补补,改变不了基因,就像打地鼠一样,这边打下去那边冒头,PFC用延时换溢出,总之还是拥塞不顺畅,这其实可以看成是 pause 帧的细化,还要解决死锁问题,越来越复杂。这是由于以太网分布式本质造成的。就算你想出再新式的 “算法”,无一例外都很以太网,INT,带内逆向捎带 ECN,都改变不了。
本文两个层面说问题,丢包分两类,信道误码丢包和拥塞丢包。第一种情况,信道质量越好,应用程序自行检测的成本越低,越倾向于传输协议不实现可靠传输,第二种情况,分布式端到端拥塞控制本质上只是转移等待时间(重传延时,排队延时等),无法彻底避免拥塞,丢包一定会发生,因此拥塞丢包必须处理。愿景是,当带宽足够大,大到分布式网络上跑满了 application-limited 自限性流量依然跑不满带宽时,分布式拥塞就彻底避免了,否则,引入一套中心控制机制终究还是不雅。
今天想到一个例子,打电话不会拥塞,没有排队延时,但会造成主叫长时间等待,打电话和互联网通信是两个极端,但改变不了的是总等待时间,不同的只是这段总时间的分布。很多人并不明白这一点,总以为用 buffer 兜住数据而不丢包就是无损网络的一切,实际上该损还得损,问题不在这里就在那里,最终都是时间,等待时间,CPU 时间,这一切都是守恒的。
浙江温州皮鞋湿,下雨进水不会胖。
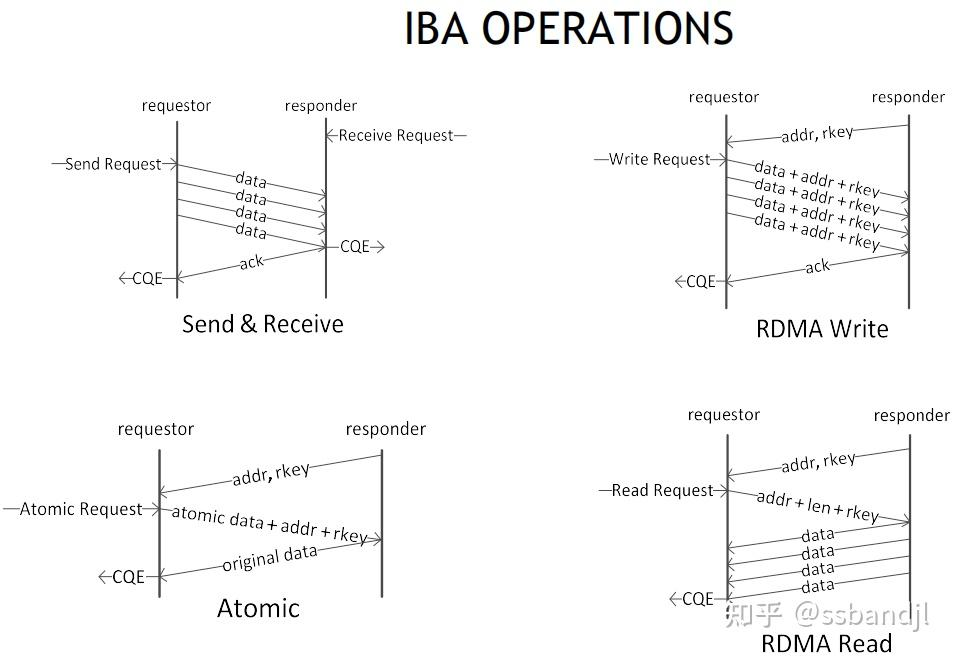
RDMA常见操作
RoCE与RoCEv2对比
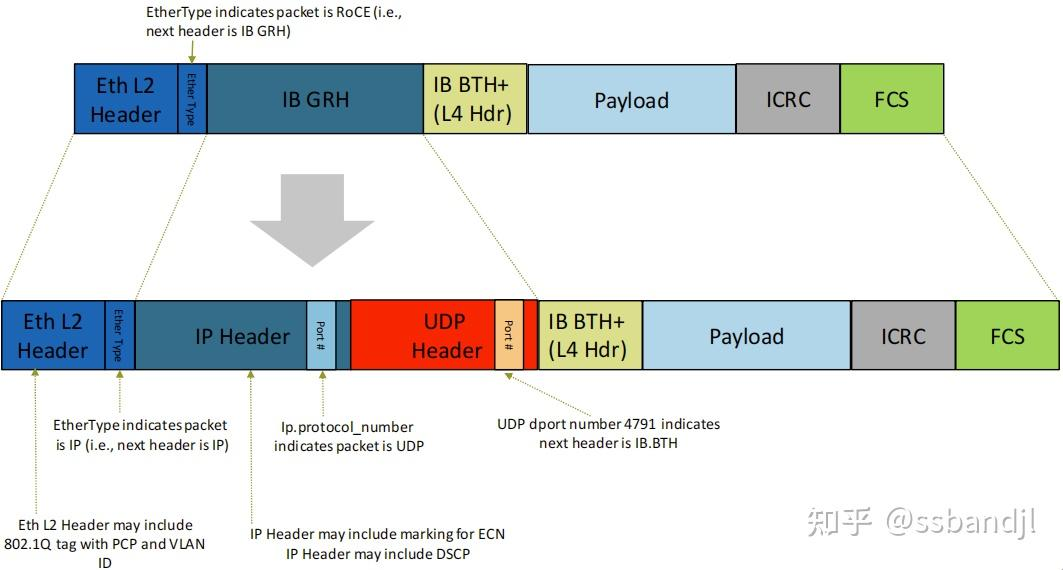
- RoCEv2没有RoCE的GRH(全局路由头)
- L2二层以太头中可能包含了802.1Q标签(PCP或VLAN_ID)
- RoCEv2的IP头可能包含ECN标记, 和DSCP
- IP协议端口号表明该包是UDP报文
- UDP目的端口4791(保留端口)表明, 下一个头是IB的BTH(BasicTranspotHeader 基本传输头占用12字节)
- 可通过抓包对比两者差异(注意IPv6与IPv4的差异)
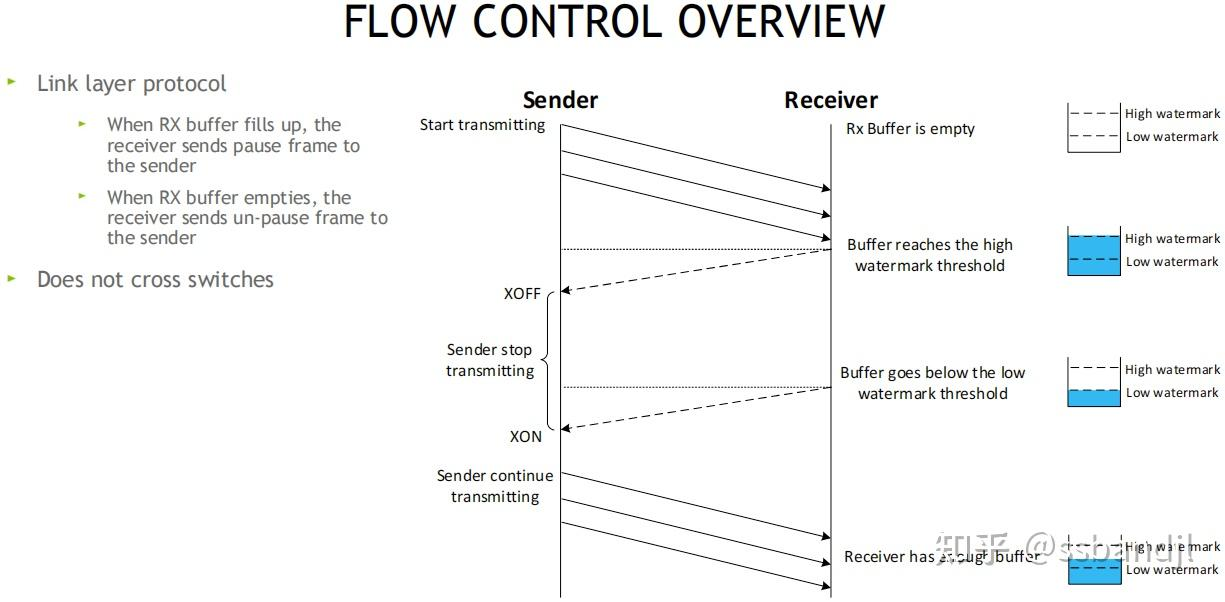
如何让RoCE工作的更好
Sender发送方 -> Receiver接收方
流控为链路层协议, 在接收方的RX Buffer接收缓存区设置高和低水位, 接收方Buffer填满时, 发送暂停帧Pause给发送方, 发送方XOFF, 并暂停发包, 等接收方释放出接收Buffer后, 给发送方发送一个UN-Pause帧, 发送方XON, 重新开始发送, 该方案不会跨越交换机
多流问题: 暂停帧不区分流, 会影响其他流
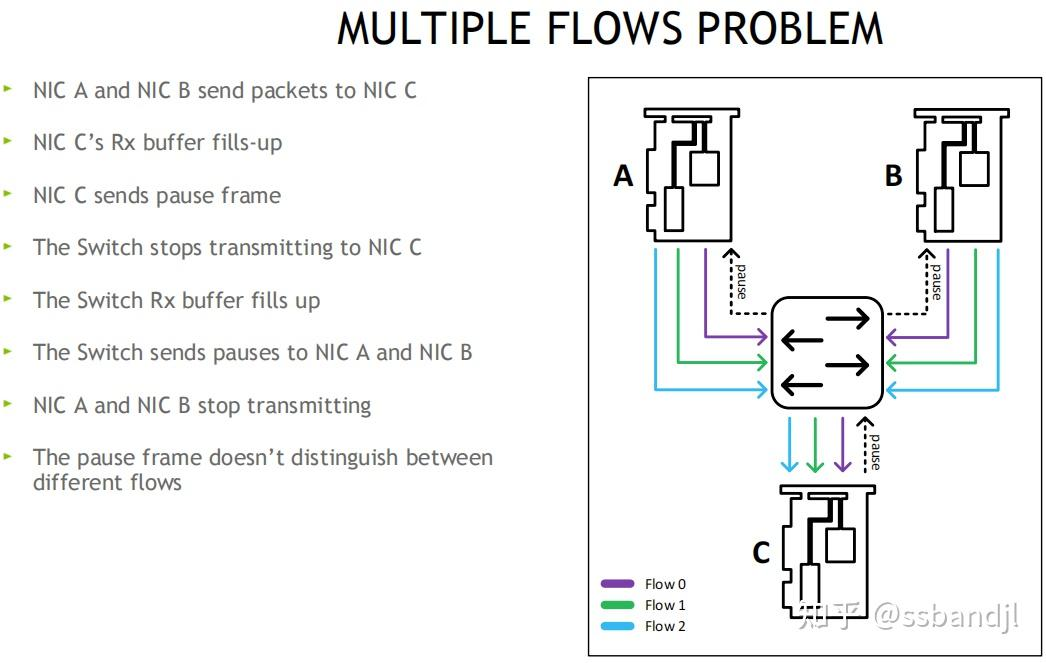
解决: 无损方案,PFC优先级流控, 用8个优先级(0-7), 独立控制每个流分类服务CoS, 网卡可将Buffer切分, 比如一半启动无损, 一半保持有损
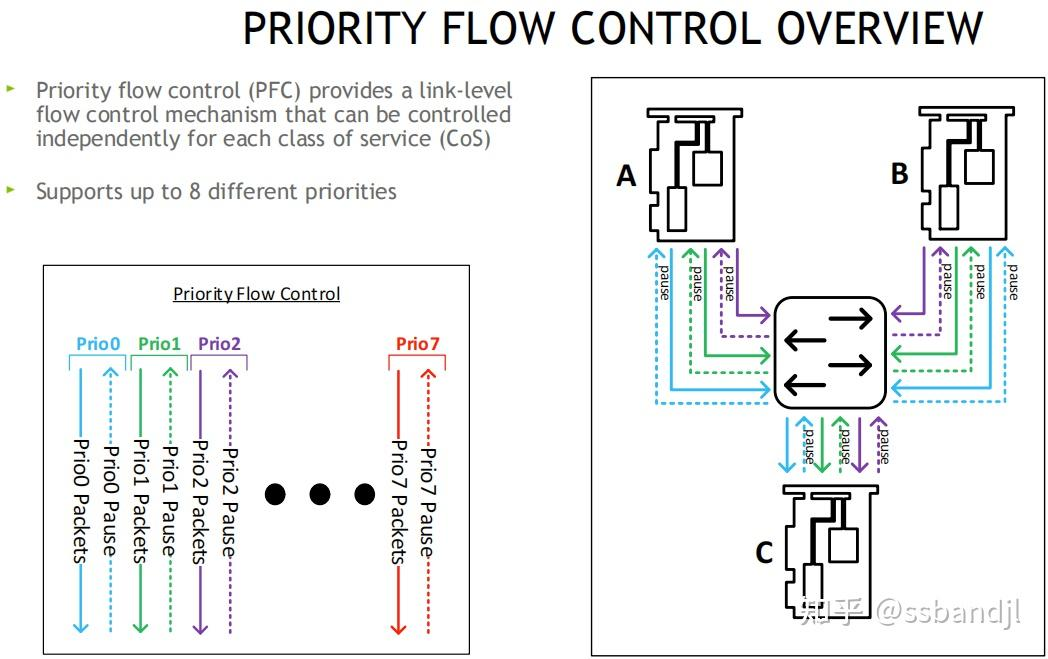
主机侧: 可通过ethtool, mlnx_qos工具查看和配置PFC流控, 交换机侧也需要做对应的配置, 如果是跨机房,也需要保持类似的配置(无损痛点之一, 有时候交换机不在咱们得控制范围, 所以这种规模的网络, 限制了无损的配置)
拥塞管理/算法(DCQCN, ZTR_RTTCC,自定义PCC算法)
拥塞问题:
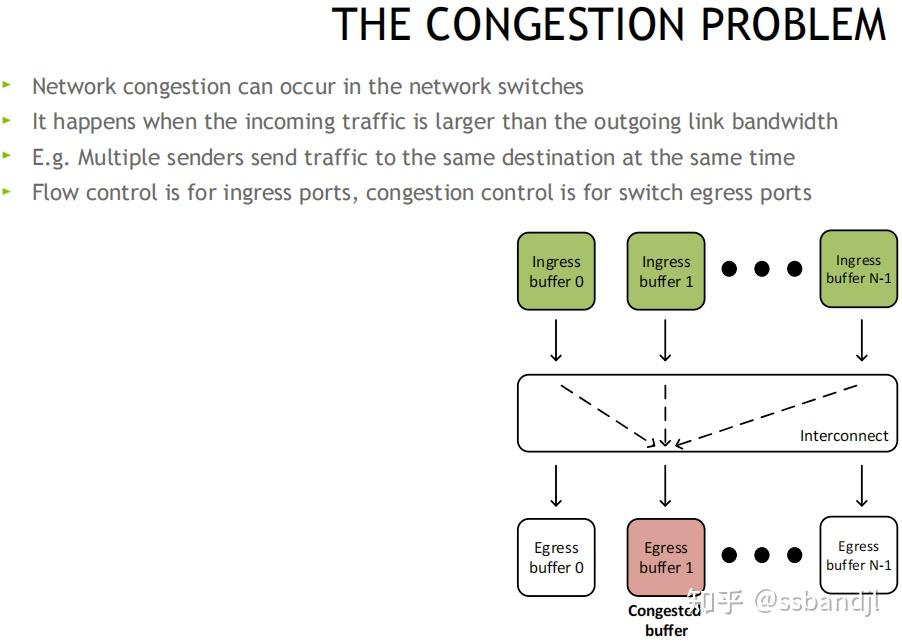
ReactionPoint 响应端(发送方网卡) --------------- Congestion Point 拥塞点交换机 -------------------- NotificationPoint 通知发起方(接收方网卡)
原理: 当交换机检测到拥塞时, 将出口包打上ECN标记, 接收端收到ECN包后, 因为有发送端的QP信息, 发送拥塞通知包CNP给发送端, 这时候假如发送端收到多个接收端发来的ECN包, 发送方需要有一个分布式拥塞控制算法(DCQCN, 由Mellanox和微软共同开发), 来降速和调度发送, 一段时间发端没有收到CNP时, 这个时候需要恢复流量, 目前是按照三个阶段来恢复, 快速恢复FR(fast recovery) -> 二分递增AI(additive increase) -> 更快增加HAI(hyper increase)
在cx6 DX网卡上可自定义拥塞控制算法, 比如阿里和google都有自己的拥塞管理算法, 算法参考:
可编程的拥塞控制算法
1. 可用算法调整硬件,微核等, 可不用配置交换机就做到拥塞控制
2. 专门的团队也在做算法
QoS保证质量
主要是二层的PCP和三层的DSCP, 进行流分类, 保证服务质量
网卡接收缓冲区的细粒度控制
将RX Buffer切片, 比如8片, 进行更细粒度的优先级队列控制
其他
一键配置: 可通过脚本检测和配置, 用于管理 RoCE 部署的系统高性能网络接口配置的命令行实用程序, 参考:https://github.com/NVIDIA/doroce-linux
RoCEv2 流分类(TC/TOS/优先级)
无损带来的挑战

配置复杂
拥塞严重时会带来暂停发送的问题
- 延迟增加
- 暂停帧风暴PauseStorm
- 配置复杂, 每个Fabric节点需要保持一致的无损配置
- 受限制, 比如大型网络, 或客户的网络中, 没有权限去配置无损
为了更好的推广和使用RoCE, 有损配置解决了部分无损的配置难题
有损RoCE(CONNECTX-5/6 DX系列网卡)功能支持表(6大功能)
慢重启(SlowRestart, 丢包后的快速处理(响应) 默认打开)
1. 接收方收到乱序包(PSN2丢失)后, OOS计数器加1, 并在回复给发送端的oos_nack中带psn编号(psn2), 并发送CNP
2. 发送端收到消息后, 增加错误计数, 后面的包以较低的速率发送(防止继续丢包)
3. 硬件计数器中可查看相关错误计数
4. 其他: ecn_mark, mst status -v, ls /sys/class/net/ens3f0/roce_rp/enable/, 8个优先级(0~7), rp: reaction_point 这里只发送端
新建QP连接时的慢重启(默认关闭)及计数器详解
1. 丢包时, 新建QP也需要被控制在较低的速率去发包
2. 新启动的流量的计数器都在发送端(如下), 收到几次慢重启控制, 自己给自己的拥塞通知包, QP从挂起到发送状态(suspend resume 暂停恢复),
3. QP超时由IB协议规定(闲置QP需要应用程序控制, 以提高QP利用率)
丢包重传, 还是新建QP或暂停重启QP, 查看固件信息(FW)
慢重启, 适用于长流量, 不适合发送紧急控制命令类的短流量QP, 相比tcp的控制, 要做的简单一些, 为了权衡, 受到慢重启控制的QP, 会在后续的DCQCN(动态拥塞控制算法中)得到限速上均衡
慢启动(默认关闭)
发生慢重启后, 其他QP启动后, 以受限速率发包, 直到拥塞解除
传输窗口(默认2的7次方=128PSN)
网络拥塞时, 原来的Go-BackN可能需要重传大量已经到达接收端但是被忽略的包
现在以一个窗口大小, 降低重传代价
1. TCP是可动态控制, 这里以QP为单位, 固定窗口大小
2. outstanding打满窗口大小: 没有到ACK或NACK的包
3. 收到ACK后,PSN窗口往下滑
4. 请求方下发3个1K的RDMA write, 收到ACK后, 下滑窗口(假如窗口为6个PSN), 产生CQE
5. 图中间距越大表示等待时间越长
6. IB规定ACK回复规范, 收到1个就需要回复1个(最后1个PSN), 为了防止死锁, 每8个PSN会回复1个ACK, 可参考BDP流控(Bandwidth Delay Product 带宽延迟积的影响)
自适应重传超时(建议打开, Nvidia Mellanox私有实现,可对比博通或其他实现)
RDMA有损网络(Lossy)和选择性重传
作用:
- 可以节省大量sram,从而存放更多的QPC,进而大幅度提高连接扩展性,即大规模连接下不会损失性能。
- 通过扩展IB协议可能很好的应对无损和有损网络,大幅度降低对PFC需求,甚至可以摒弃PFC。
导致重传的Error主要有四类

goback-N
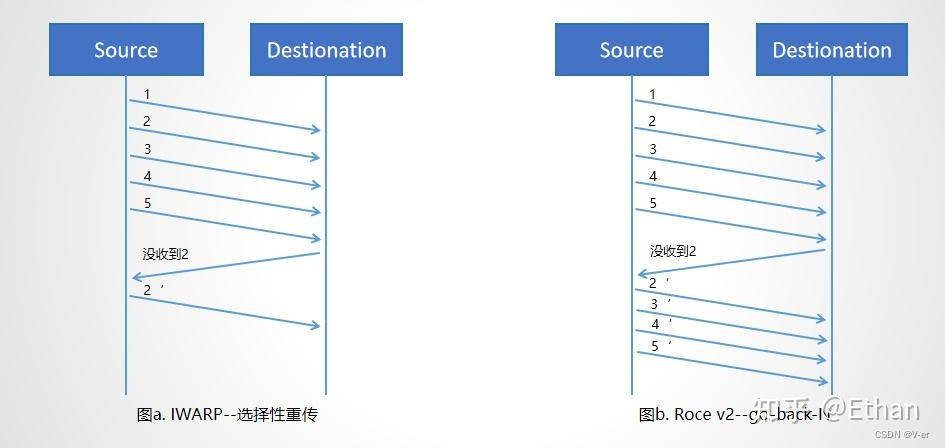

传统的RDMA跑在InfiniBand(IB)网络上,IB链路层使用逐跳的、基于credit的流控,丢包非常罕见。而在数据中心中,RDMA则需要跑在三层IP网络之上,即RoCEv2。RoCEv2保留了IB传输层,但是使用IP和UDP封装替换了IB的网络层,其中IP层用来路由,UDP层用来进行ECMP。由于历史性的RDMA网卡(e.g., CX-3, CX-4, CX-5)的传输层处理丢包很不高效,如接收端会丢弃所有的out-of-order packets、发送端需要重传上一个acked packet后的所有packets(go-back-N机制),RoCEv2需要无损网络(Lossless)来保证高性能。无损网络的核心是在交换机和网卡上使能Priority Flow Control (PFC)。PFC允许以太网交换机通过强制直接上游实体(另一个交换机或主机网卡)暂停数据传输来避免缓冲区溢出。然而,PFC是一种粗粒度机制。它以端口(或端口加优先级)级别运行,不区分流。这可能会导致拥堵蔓延现象(congestion-spreading),进而有不公平现象、受害者流、PFC deadlock、PFC storm等一系列性能问题。尽管有一系列拥塞控制算法来缓解PFC带来的问题,但是PFC并不能从根本上消除。这是因为在一个端到端路径中,拥塞标记信号需要先经过数跳交换机到达接受者,再被CNP携带着穿越数跳交换机回到发送者,发送者才能降低自己的发送速率,这中间需要至少一个端到端往返时间(RTT)。而在这个往返时间内,发送者可能仍然在提高发送速率,PFC仍然可能会被触发。尤其在规模更大、跳数较多的网络中,PFC的问题仍然会出现,给网络运营带来了较大的稳定性风险。