开始 ComfyUI 的 AI 绘图之旅-ControlNet(六)
文章标题
- 一、LoRA和ControlNet区别
- 1.核心目标与功能
- 1.1 LoRA(低秩适应)
- 1.2 ControlNet
- 2.技术原理
- 2.1 LoRA
- 2.2 ControlNet
- 3.应用场景
- 4.总结:关键区别
- 二、ControlNet
- 1.ControlNet 图片预处理相关说明
- 2.ComfyUI ControlNet 工作流示例讲解
- 2.1 ControlNet 工作流素材
- 2.2 手动模型安装
- 2.3 按步骤完成工作流的运行
- 3.相关节点讲解
- 3.1 Load ControlNet 节点讲解
- 3.2 Apply ControlNet 节点讲解
- 4.开始你的尝试
- 三、Pose ControlNet
- 1.OpenPose 简介
- 2. 2nd Pass Pose ControlNet 使用示例
- 2.1 Pose ControlNet 工作流素材
- 2.2 手动模型安装
- 2.3 按步骤完成工作流的运行
- 3.Pose ControlNet 二次图生图工作流讲解
- 3.1 第一阶段:基础姿态图像生成
- 3.2 第二阶段:风格优化与细节增强
- 4.二次图生图的优势
- 四、Depth ControlNet
- 1.深度图与 Depth ControlNet 介绍
- 2.深度图结合 ControlNet 应用场景
- 3.ComfyUI ControlNet 工作流示例讲解
- 3.1 ControlNet 工作流素材
- 3.2 模型安装
- 3.3 按步骤完成工作流的运行
- 4.混合深度控制与其他技术
- 五、Depth T2I Adapter
- 1.T2I Adapter 介绍
- 1.1 T2I Adapter 与 ControlNet 的对比
- 1.2 T2I Adapter 主要类型
- 1.3 深度 T2I Adapter 应用价值
- 2.ComfyUI Depth T2I Adapter工作流示例讲解
- 2.1 Depth T2I Adapter 工作流素材
- 2.2 模型安装
- 2.3 按步骤完成工作流的运行
- 3.T2I Adapter 通用使用技巧
- 3.1 输入图像质量优化
- 3.2 T2I Adapter 的使用特点
- 六、ControlNet 混合使用示例
- 1.混合 ControlNet 的使用方法
- 2.ComfyUI ControlNet 区域分治混合示例
- 2.1 ControlNet 混合使用工作流素材
- 2.2 手动模型安装(前面都安装过了)
- 2.3 按步骤完成工作流的运行
- 3.工作流讲解
- 3.1 强度平衡
- 3.2 提示词技巧
- 4.同一主体多维控制的混合应用
一、LoRA和ControlNet区别
LoRA(Low-Rank Adaptation)和ControlNet是生成式AI(尤其是图像生成领域,如Stable Diffusion)中两种常用的技术,但它们的核心目标、技术原理和应用场景有显著区别。简单来说:
- LoRA专注于“学习特定特征”(如风格、物体、人物特征等),是一种高效微调技术;
- ControlNet专注于“控制生成结构”(如姿态、轮廓、深度等),是一种条件约束技术。
1.核心目标与功能
1.1 LoRA(低秩适应)
- 核心目标:在不修改预训练模型主体参数的前提下,让模型“记住”特定特征(如某个人的脸、某种艺术风格、某个物体的细节)。
- 功能:通过少量数据微调,让模型生成符合特定风格/特征的内容。例如:
- 训练一个“梵高风格”的LoRA,生成的图像会带有梵高的笔触和色彩;
- 训练一个“特定角色”的LoRA,生成的人物会保持该角色的外貌特征。
1.2 ControlNet
- 核心目标:通过外部控制信号(如线稿、姿态骨架、深度图等),精确控制生成内容的结构或空间布局,同时保留模型原有的风格生成能力。
- 功能:约束生成内容的“形”,而不限制“风格”。例如:
- 输入一张人体姿态骨架图,ControlNet能让生成的人物严格按照这个骨架姿势呈现;
- 输入一张建筑线稿,ControlNet能让生成的建筑遵循线稿的轮廓和结构。
2.技术原理
2.1 LoRA
- 本质是参数高效微调技术:
- 预训练模型(如Stable Diffusion)的参数规模庞大(数十亿级),直接微调全部参数成本高、易过拟合。
- LoRA通过在模型的关键层(如注意力层)插入低秩矩阵(秩远小于原矩阵维度),仅训练这些低秩矩阵,冻结原模型参数。
- 推理时,将低秩矩阵的输出与原模型输出叠加,实现“用少量参数控制模型特征”的效果。
2.2 ControlNet
- 本质是条件约束网络:
- 在原模型(如Stable Diffusion的UNet)中加入一个“控制模块”(ControlNet模块),该模块接收外部控制信号(如边缘图、深度图)。
- 控制模块与原模型共享权重(但初始时权重冻结为0),训练时仅更新控制模块,让它学会将控制信号“映射”到模型的特征空间。
- 推理时,控制信号通过控制模块引导原模型生成符合结构约束的内容,同时不破坏原模型的风格生成能力。
3.应用场景
| 维度 | LoRA | ControlNet |
|---|---|---|
| 核心作用 | 让模型学习特定特征(风格、物体、人物等) | 控制生成内容的结构(姿态、轮廓、布局等) |
| 输入要求 | 无需额外控制信号,仅需加载LoRA权重 | 必须输入控制信号(如线稿、骨架图等) |
| 典型用途 | 风格迁移(如“赛博朋克”“水墨画”)、特定角色生成、特定物体细节生成(如“二次元眼睛”) | 姿态控制(如人物跳舞姿势)、线稿上色、根据深度图生成3D感图像、语义分割图转真实图像 |
| 灵活性 | 可叠加多个LoRA(如同时用“梵高风格”+“二次元”LoRA) | 可组合多种控制信号(如同时用“姿态”+“深度”控制) |
4.总结:关键区别
- LoRA是“特征注入”:告诉模型“生成什么风格/特征”,不限制结构;
- ControlNet是“结构约束”:告诉模型“生成什么结构/布局”,不限制风格。
两者可以结合使用:例如用LoRA指定“古风风格”,同时用ControlNet根据线稿控制人物姿态,最终生成“符合线稿姿态的古风人物”。
二、ControlNet
本篇将引导了解基础的 ControlNet 概念,并在 ComfyUI 中完成对应的图像生成
在 AI 图像生成过程中,要精确控制图像生成并不是一键容易的事情,通常需要通过许多次的图像生成才可能生成满意的图像,但随着 ControlNet 的出现,这个问题得到了很好的解决。
ControlNet 是一种基于扩散模型(如 Stable Diffusion)的条件控制生成模型,最早由Lvmin Zhang与 Maneesh Agrawala 等人于 2023 年提出Adding Conditional Control to Text-to-Image Diffusion Models
ControlNet 模型通过引入多模态输入条件(如边缘检测图、深度图、姿势关键点等),显著提升了图像生成的可控性和细节还原能力。
使得我们可以进一步开始控制图像的风格、细节、人物姿势、画面结构等等,这些限定条件让图像生成变得更加可控,在绘图过程中也可以同时使用多个 ControlNet 模型,以达到更好的效果。
在没有 ControlNet 之前,我们每次只能让模型生成图像,直到生成我们满意的图像,充满了随机性。

但随着 ControlNet 的出现,我们可以通过引入额外的条件,来控制图像的生成,比如我们可以使用一张简单的涂鸦,来控制图像的生成,就可以生成差不多类似的图片。

在本示例中,我们将引导你完成在 ComfyUI 中 ControlNet 模型的安装与使用, 并完成一个涂鸦控制图像生成的示例。
ControlNet V1.1 其它类型的 ControlNet 模型的工作流也与都与本篇示例相同,你只需要根据需要选择对应的模型和上传对应的参考图即可。1.ControlNet 图片预处理相关说明
不同类型的 ControlNet 模型,通常需要使用不同类型的参考图:

图源:ComfyUI ControlNet aux
由于目前 Comfy Core 节点中,不包含所有类型的 预处理器 类型,但在本文档的实际示例中,我们都将提供已经经过处理后的图片,
但在实际使用过程中,你可能需要借助一些自定义节点来对图片进行预处理,以满足不同 ControlNet 模型的需求,下面是一些相关的插件
- ComfyUI-Advanced-ControlNet
- ComfyUI ControlNet aux
安装aria2快速下载模型,几乎能将我家1000M的宽带跑满,每秒80~90M,接下来的介绍模型都会给出安装命令。
apt install aria2
aria2c https://huggingface.co/stabilityai/sd-vae-ft-mse-original/resolve/main/vae-ft-mse-840000-ema-pruned.safetensors?download=true -o SourceCode/ComfyUI/models/vae/vae-ft-mse-840000-ema-pruned.safetensors auto-file-renaming=false --allow-overwrite=falsearia2c https://huggingface.co/comfyanonymous/ControlNet-v1-1_fp16_safetensors/resolve/main/control_v11p_sd15_scribble_fp16.safetensors?download=true -o SourceCode/ComfyUI/models/controlnet/control_v11p_sd15_scribble_fp16.safetensors auto-file-renaming=false --allow-overwrite=false
小技巧:你要是打不开https://huggingface.co,可以将其换成为https://hf-mirror.com/试一试
2.ComfyUI ControlNet 工作流示例讲解
2.1 ControlNet 工作流素材
请下载下面的工作流图片,并拖入 ComfyUI 以加载工作流
Metadata 中包含工作流 json 的图片可直接拖入 ComfyUI 或使用菜单 `Workflows` -> `Open(ctrl+o)` 来加载对应的工作流。 该图片已包含对应模型的下载链接,直接拖入 ComfyUI 将会自动提示下载。请下载下面的图片,我们将会将它作为输入

2.2 手动模型安装
如果你网络无法顺利完成对应模型的自动下载,请尝试手动下载下面的模型,并放置到指定目录中- dreamCreationVirtual3DECommerce_v10.safetensors
- vae-ft-mse-840000-ema-pruned.safetensors
- control_v11p_sd15_scribble_fp16.safetensors
ComfyUI/
├── models/
│ ├── checkpoints/
│ │ └── dreamCreationVirtual3DECommerce_v10.safetensors
│ ├── vae/
│ │ └── vae-ft-mse-840000-ema-pruned.safetensors
│ └── controlnet/
│ └── control_v11p_sd15_scribble_fp16.safetensors
2.3 按步骤完成工作流的运行
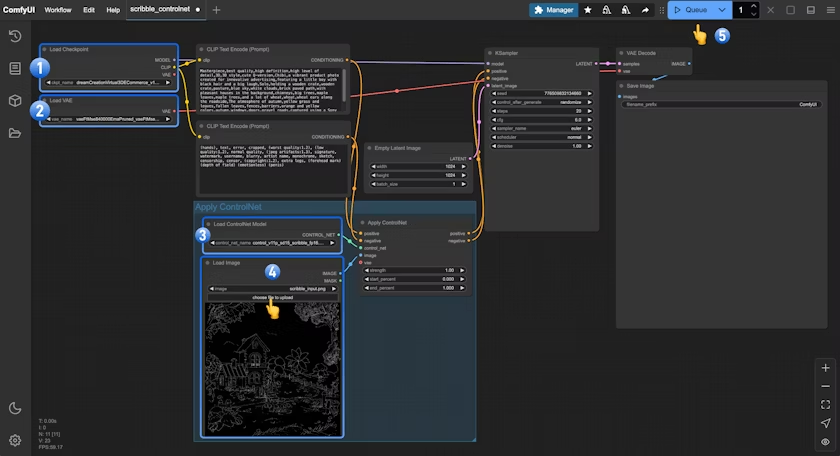
- 确保
Load Checkpoint可以加载 dreamCreationVirtual3DECommerce_v10.safetensors - 确保
Load VAE可以加载 vae-ft-mse-840000-ema-pruned.safetensors - 在
Load Image中点击Upload上传之前提供的输入图片 - 确保
Load ControlNet可以加载 control_v11p_sd15_scribble_fp16.safetensors - 点击
Queue按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来执行图片的生成
3.相关节点讲解
3.1 Load ControlNet 节点讲解
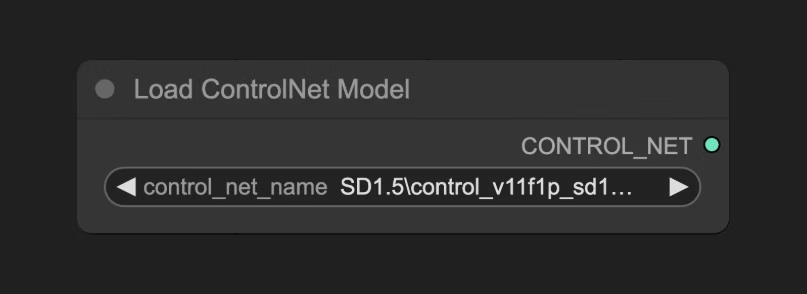
位于ComfyUI\models\controlnet 的模型会被 ComfyUI 检测到,并在这个节点中识别并加载
3.2 Apply ControlNet 节点讲解
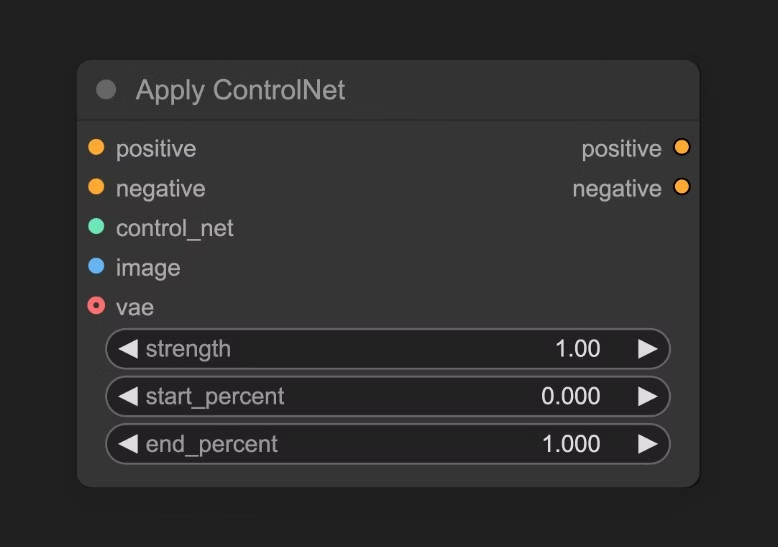
这个节点接受 load controlnet 加载的 ControlNet 模型,并根据输入的图片,生成对应的控制条件。
输入类型
| 参数名称 | 作用 |
|---|---|
positive | 正向条件 |
negative | 负向条件 |
control_net | 要应用的controlNet模型 |
image | 用于 controlNet 应用参考的预处理器处理图片 |
vae | Vae模型输入 |
strength | 应用 ControlNet 的强度,越大则 ControlNet 对生成图像的影响越大 |
start_percent | 确定开始应用controlNet的百分比,比如取值0.2,意味着ControlNet的引导将在扩散过程完成20%时开始影响图像生成 |
end_percent | 确定结束应用controlNet的百分比,比如取值0.8,意味着ControlNet的引导将在扩散过程完成80%时停止影响图像生成 |
输出类型
| 参数名称 | 作用 |
|---|---|
positive | 应用了 ControlNet 处理后的正向条件数据 |
negative | 应用了 ControlNet 处理后的负向条件数据 |
你可以使用链式链接来应用多个 ControlNet 模型,如下图所示,你也可以参考 混合 ControlNet 模型 部分的指南来了解更多关于混合 ControlNet 模型的使用
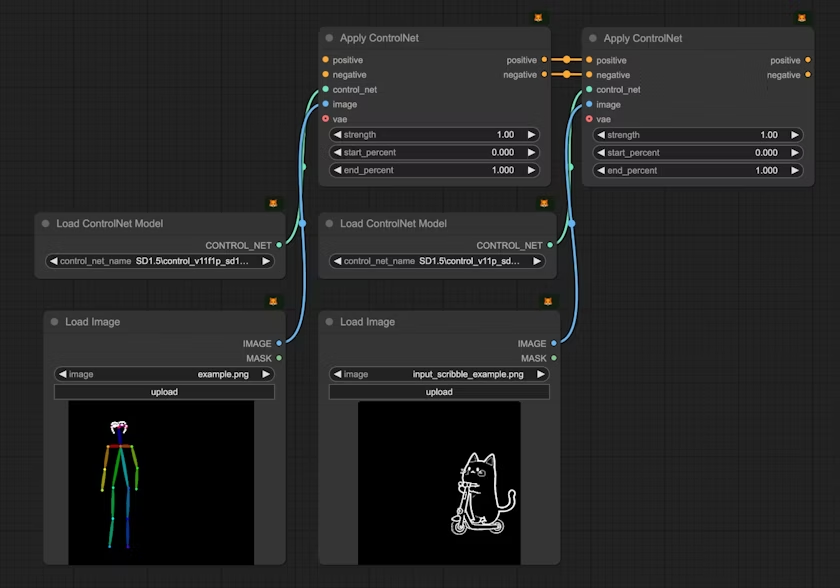
如需启用,请在设置–> comfy --> Node 中,启用Show deprecated nodes in search 选项,推荐使用新节点
4.开始你的尝试
- 试着制作类似的涂鸦图片,甚至自己手绘,并使用 ControlNet 模型生成图像,体验 ControlNet 带来的乐趣
- 调整 Apply ControlNet 节点的
Control Strength参数,来控制 ControlNet 模型对生成图像的影响 - 访问 ControlNet-v1-1_fp16_safetensors 仓库下载其它类型的 ControlNet 模型,并尝试使用它们生成图像

三、Pose ControlNet
本篇将引导了解基础的 Pose ControlNet,并通过二次图生图的方式,在 ComfyUI 中完成大尺寸的图像生成
1.OpenPose 简介
OpenPose 是由卡耐基梅隆大学(CMU)开发的开源实时多人姿态估计系统,是计算机视觉领域的重要技术突破。该系统能够同时检测图像中多个人的:
- 人体骨架:18个关键点,包括头部、肩膀、手肘、手腕、髋部、膝盖和脚踝等
- 面部表情:70个面部关键点,用于捕捉微表情和面部轮廓
- 手部细节:21个手部关键点,精确表达手指姿势和手势
- 脚部姿态:6个脚部关键点,记录站立姿势和动作细节

在 AI 图像生成领域,OpenPose 生成的骨骼结构图作为 ControlNet 的条件输入,能够精确控制生成人物的姿势、动作和表情,让我们能够按照预期的姿态和动作生成逼真的人物图像,极大提高了 AI 生成内容的可控性和实用价值。
特别针对早期 Stable diffusion 1.5 系列的模型,通过 OpenPose 生成的骨骼图,可以有效避免人物动作、肢体、表情畸变的问题。
2. 2nd Pass Pose ControlNet 使用示例
2.1 Pose ControlNet 工作流素材
请下载下面的工作流图片,并拖入 ComfyUI 以加载工作流
Metadata 中包含工作流 json 的图片可直接拖入 ComfyUI 或使用菜单 `Workflows` -> `Open(ctrl+o)` 来加载对应的工作流。 该图片已包含对应模型的下载链接,直接拖入 ComfyUI 将会自动提示下载。请下载下面的图片,我们将会将它作为输入
2.2 手动模型安装
如果你网络无法顺利完成对应模型的自动下载,请尝试手动下载下面的模型,并放置到指定目录中- control_v11p_sd15_openpose_fp16.safetensors
- majicmixRealistic_v7.safetensors
- japaneseStyleRealistic_v20.safetensors
- vae-ft-mse-840000-ema-pruned.safetensors
安装aria2快速下载模型,几乎能将我家1000M的宽带跑满,每秒80~90M,接下来的介绍模型都会给出安装命令。
apt install aria2
aria2c https://civitai.com/api/download/models/176425?type=Model&format=SafeTensor&size=pruned&fp=fp16 -o SourceCode/ComfyUI/models/checkpoints/majicmixRealistic_v7.safetensors auto-file-renaming=false --allow-overwrite=falsearia2c https://civitai.com/api/download/models/85426?type=Model&format=SafeTensor&size=pruned&fp=fp16 -o SourceCode/ComfyUI/models/checkpoints/japaneseStyleRealistic_v20.safetensors auto-file-renaming=false --allow-overwrite=false
小技巧:你要是打不开https://huggingface.co,可以将其换成为https://hf-mirror.com/试一试
ComfyUI/
├── models/
│ ├── checkpoints/
│ │ └── majicmixRealistic_v7.safetensors
│ │ └── japaneseStyleRealistic_v20.safetensors
│ ├── vae/
│ │ └── vae-ft-mse-840000-ema-pruned.safetensors
│ └── controlnet/
│ └── control_v11p_sd15_openpose_fp16.safetensors
2.3 按步骤完成工作流的运行
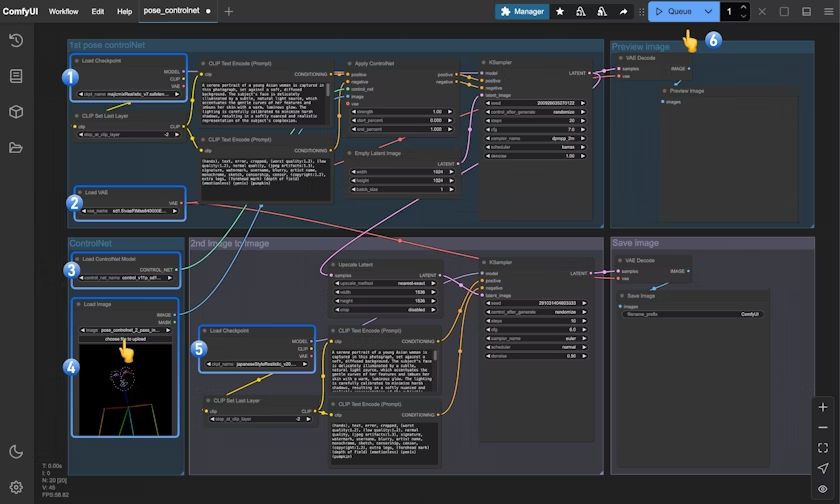
按照图片中的数字标记,执行以下步骤:
- 确保
Load Checkpoint可以加载 majicmixRealistic_v7.safetensors - 确保
Load VAE可以加载 vae-ft-mse-840000-ema-pruned.safetensors - 确保
Load ControlNet Model可以加载 control_v11p_sd15_openpose_fp16.safetensors - 在
Load Image节点中点击选择按钮,上传之前提供的姿态输入图片,或者使用你自己的OpenPose骨骼图 - 确保
Load Checkpoint可以加载 japaneseStyleRealistic_v20.safetensors - 点击
Queue按钮或使用快捷键Ctrl(cmd) + Enter(回车)来执行图片的生成
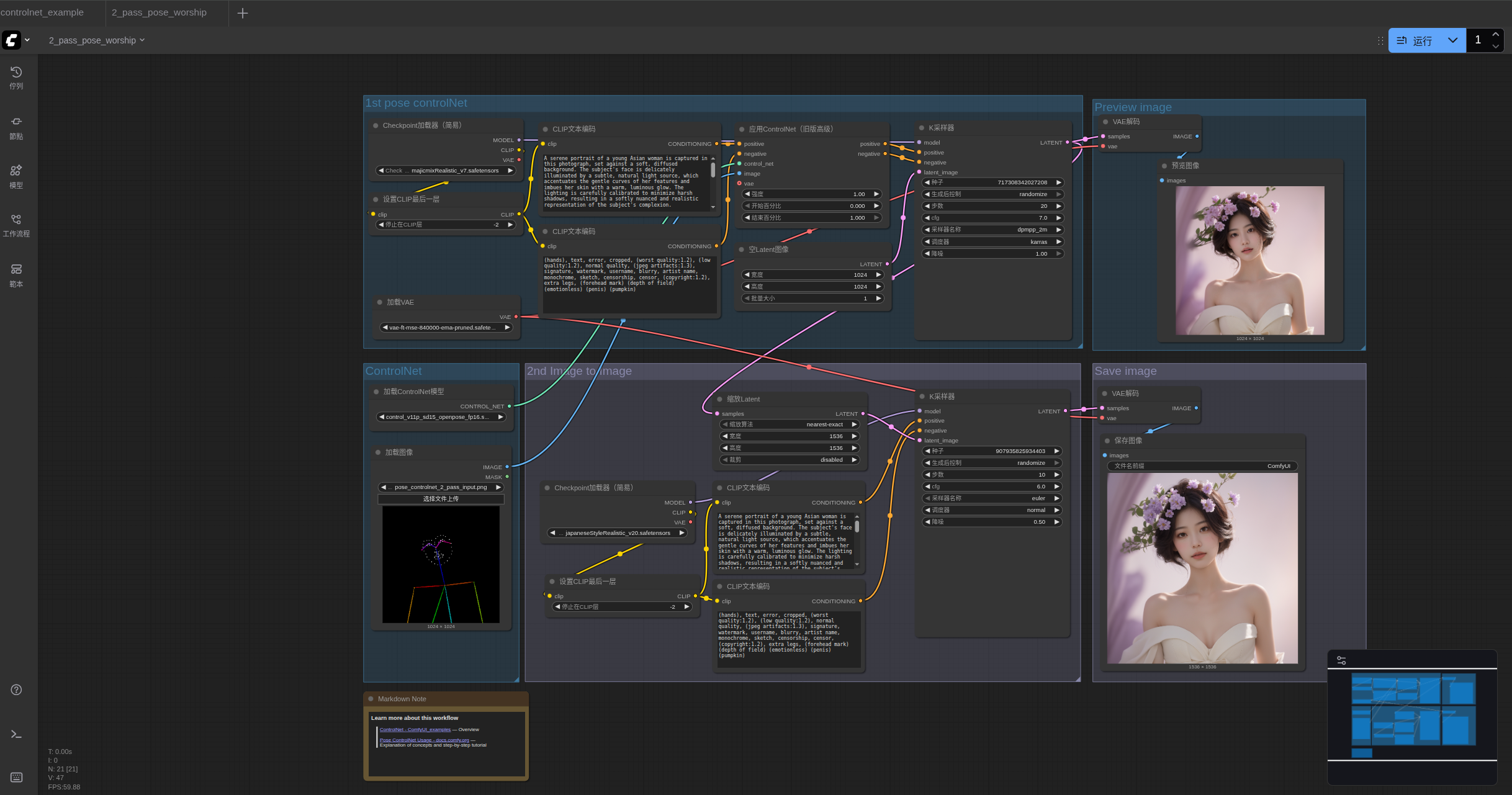
3.Pose ControlNet 二次图生图工作流讲解
本工作流采用二次图生图(2-pass)的方式,将图像生成分为两个阶段:
3.1 第一阶段:基础姿态图像生成
在第一阶段,使用majicmixRealistic_v7模型结合Pose ControlNet生成初步的人物姿态图像:
- 首先通过
Load Checkpoint加载majicmixRealistic_v7模型 - 通过
Load ControlNet Model加载姿态控制模型 - 输入的姿态图被送入
Apply ControlNet节点与正向和负向提示词条件结合 - 第一个
KSampler节点(通常使用20-30步)生成基础的人物姿态图像 - 通过
VAE Decode解码得到第一阶段的像素空间图像
这个阶段主要关注正确的人物姿态、姿势和基本结构,确保生成的人物符合输入的骨骼姿态。
3.2 第二阶段:风格优化与细节增强
在第二阶段,将第一阶段的输出图像作为参考,使用japaneseStyleRealistic_v20模型进行风格化和细节增强:
- 第一阶段生成的图像通过
Upscale latent节点创建的更大分辨率的潜在空间 - 第二个
Load Checkpoint加载japaneseStyleRealistic_v20模型,这个模型专注于细节和风格 - 第二个
KSampler节点使用较低的denoise强度(通常0.4-0.6)进行细化,保留第一阶段的基础结构 - 最终通过第二个
VAE Decode和Save Image节点输出更高质量、更大分辨率的图像
这个阶段主要关注风格统一性、细节丰富度和提升整体画面质量。
4.二次图生图的优势
与单次生成相比,二次图生图方法具有以下优势:
- 更高分辨率:通过二次处理可以生成超出单次生成能力的高分辨率图像
- 风格混合:可以结合不同模型的优势,如第一阶段使用写实模型,第二阶段使用风格化模型
- 更好的细节:第二阶段可以专注于优化细节,而不必担心整体结构
- 精确控制:姿态控制在第一阶段完成后,第二阶段可以专注于风格和细节的完善
- 降低GPU负担:分两次生成可以在有限的GPU资源下生成高质量大图
四、Depth ControlNet
本篇将引导了解基础的 Depth ControlNet 概念,并在 ComfyUI 中完成对应的图像生成
1.深度图与 Depth ControlNet 介绍
深度图(Depth Map)是一种特殊的图像,它通过灰度值表示场景中各个物体与观察者或相机的距离。在深度图中,灰度值与距离成反比:越亮的区域(接近白色)表示距离越近,越暗的区域(接近黑色)表示距离越远。

Depth ControlNet 是专门训练用于理解和利用深度图信息的 ControlNet 模型。它能够帮助 AI 正确解读空间关系,使生成的图像符合深度图指定的空间结构,从而实现对三维空间布局的精确控制。
2.深度图结合 ControlNet 应用场景
深度图在多种场景中都有比较多的应用:
- 人像场景:控制人物与背景的空间关系,避免面部等关键部位畸变
- 风景场景:控制近景、中景、远景的层次关系
- 建筑场景:控制建筑物的空间结构和透视关系
- 产品展示:控制产品与背景的分离度和空间位置
本篇示例中,我们将使用深度图生成建筑可视化的场景生成。
3.ComfyUI ControlNet 工作流示例讲解
3.1 ControlNet 工作流素材
请下载下面的工作流图片,并拖入 ComfyUI 以加载工作流
Metadata 中包含工作流 json 的图片可直接拖入 ComfyUI 或使用菜单 Workflows -> Open(ctrl+o) 来加载对应的工作流。
该图片已包含对应模型的下载链接,直接拖入 ComfyUI 将会自动提示下载。
请下载下面的图片,我们将会将它作为输入。
3.2 模型安装
如果你网络无法顺利完成对应模型的自动下载,请尝试手动下载下面的模型,并放置到指定目录中- architecturerealmix_v11.safetensors
- control_v11f1p_sd15_depth_fp16.safetensors
安装aria2快速下载模型,几乎能将我家1000M的宽带跑满,每秒80~90M,接下来的介绍模型都会给出安装命令。
apt install aria2
使用浏览器的 cookies:对于需要登录会话的情况,可以导出浏览器的 cookies 并供 aria2c 使用:
- 用浏览器插件(如 Get cookies.txt)导出 cookies
- 使用 --load-cookies 参数 指定 指定 cookies 文件路径
aria2c https://civitai.com/api/download/models/431755?type=Model&format=SafeTensor&size=full&fp=fp16 -o SourceCode/ComfyUI/models/checkpoints/architecturerealmix_v11.safetensors
--load-cookies /home/d/Downloads/civitai.com_cookies.txt auto-file-renaming=false --allow-overwrite=falsearia2c https://huggingface.co/comfyanonymous/ControlNet-v1-1_fp16_safetensors/resolve/main/control_v11f1p_sd15_depth_fp16.safetensors?download=true -o SourceCode/ComfyUI/models/controlnet/control_v11f1p_sd15_depth_fp16.safetensors auto-file-renaming=false --allow-overwrite=false
小技巧:你要是打不开https://huggingface.co,可以将其换成为https://hf-mirror.com/试一试
ComfyUI/
├── models/
│ ├── checkpoints/
│ │ └── architecturerealmix_v11.safetensors
│ └── controlnet/
│ └── control_v11f1p_sd15_depth_fp16.safetensors
3.3 按步骤完成工作流的运行
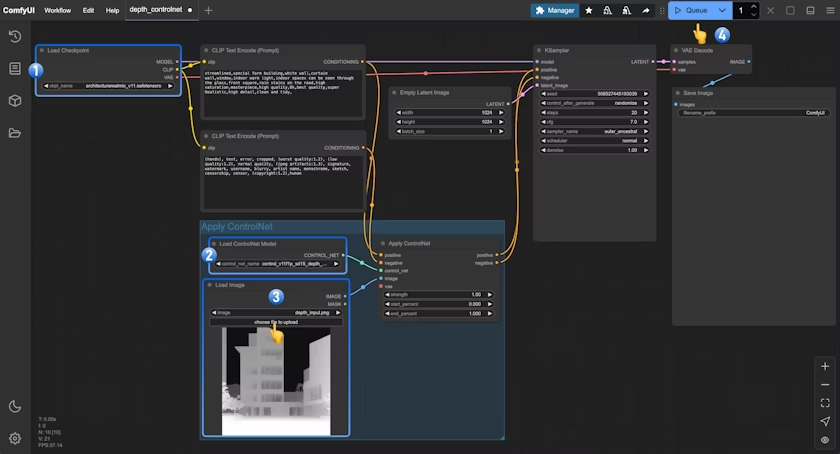
- 确保
Load Checkpoint可以加载 architecturerealmix_v11.safetensors - 确保
Load ControlNet可以加载 control_v11f1p_sd15_depth_fp16.safetensors - 在
Load Image中点击Upload上传之前提供的 Depth 图像 - 点击
Queue按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来执行图片的生成

4.混合深度控制与其他技术
根据不同创作需求,可以将深度图 ControlNet 与其它类型的 ControlNet 混合使用来达到更好的效果:
- Depth + Lineart:保持空间关系的同时强化轮廓,适用于建筑、产品、角色设计
- Depth + Pose:控制人物姿态的同时维持正确的空间关系,适用于人物场景
关于多个 ControlNet 混合使用,可以参考 混合 ControlNet 示例。
五、Depth T2I Adapter
本篇将引导了解基础的 Depth T2I Adapter ,并在 ComfyUI 中完成对应的图像生成
1.T2I Adapter 介绍
T2I-Adapter 是由 腾讯ARC实验室 开发的轻量级适配器,用于增强文本到图像生成模型(如Stable Diffusion)的结构、颜色和风格控制能力。
它通过外部条件(如边缘检测图、深度图、草图或颜色参考图)与模型内部特征对齐,实现高精度控制,无需修改原模型结构。其参数仅约77M(体积约300MB),推理速度比 ControlNet 快约3倍,支持多条件组合(如草图+颜色网格)。应用场景包括线稿转图像、色彩风格迁移、多元素场景生成等。
1.1 T2I Adapter 与 ControlNet 的对比
虽然功能相似,但两者在实现和应用上有明显区别:
- 轻量级设计:T2I Adapter 参数量更少,占用内存更小
- 推理速度:T2I Adapter 通常比 ControlNet 快约3倍
- 控制精度:ControlNet 在某些场景下控制更精确,而 T2I Adapter 更适合轻量级控制
- 多条件组合:T2I Adapter 在多条件组合时资源占用优势更明显
1.2 T2I Adapter 主要类型
T2I Adapter 提供多种类型以控制不同方面:
- 深度 (Depth):控制图像的空间结构和深度关系
- 线稿 (Canny/Sketch):控制图像的边缘和线条
- 关键点 (Keypose):控制人物姿态和动作
- 分割 (Seg):通过语义分割控制场景布局
- 颜色 (Color):控制图像的整体配色方案
在 ComfyUI 中,使用 T2I Adapter 与 ControlNet 的界面和工作流相似。在本篇示例中,我们将以深度 T2I Adapter 控制室内场景为例,展示其使用方法。

1.3 深度 T2I Adapter 应用价值
深度图(Depth Map)在图像生成中有多种重要应用:
- 空间布局控制:准确描述三维空间结构,适用于室内设计、建筑可视化
- 物体定位:控制场景中物体的相对位置和大小,适用于产品展示、场景构建
- 透视关系:维持合理的透视和比例,适用于风景、城市场景生成
- 光影布局:基于深度信息的自然光影分布,增强真实感
我们将以室内设计为例,展示深度 T2I Adapter 的使用方法,但这些技巧也适用于其他应用场景。
2.ComfyUI Depth T2I Adapter工作流示例讲解
2.1 Depth T2I Adapter 工作流素材
请下载下面的工作流图片,并拖入 ComfyUI 以加载工作流
Metadata 中包含工作流 json 的图片可直接拖入 ComfyUI 或使用菜单 `Workflows` -> `Open(ctrl+o)` 来加载对应的工作流。 该图片已包含对应模型的下载链接,直接拖入 ComfyUI 将会自动提示下载。请下载下面的图片,我们将会将它作为输入

2.2 模型安装
如果你网络无法顺利完成对应模型的自动下载,请尝试手动下载下面的模型,并放置到指定目录中- interiordesignsuperm_v2.safetensors
- t2iadapter_depth_sd15v2.pth
安装aria2快速下载模型,几乎能将我家1000M的宽带跑满,每秒80~90M,接下来的介绍模型都会给出安装命令。
apt install aria2
aria2c https://civitai.com/api/download/models/20335?type=Model&format=SafeTensor&size=full&fp=fp16 -o SourceCode/ComfyUI/models/controlnet/controlnetT2IAdapter_t2iAdapterDepth.safetensors --load-cookies /home/d/Downloads/civitai.com_cookies.txt auto-file-renaming=false --allow-overwrite=falsearia2c https://civitai.com/api/download/models/93152?type=Model&format=SafeTensor&size=full&fp=fp16 -o SourceCode/ComfyUI/models/checkpoints/interiordesignsuperm_v2.safetensors --load-cookies /home/d/Downloads/civitai.com_cookies.txt auto-file-renaming=false --allow-overwrite=false
小技巧:你要是打不开https://huggingface.co,可以将其换成为https://hf-mirror.com/试一试
ComfyUI/
├── models/
│ ├── checkpoints/
│ │ └── interiordesignsuperm_v2.safetensors
│ └── controlnet/
│ └── t2iadapter_depth_sd15v2.pth
2.3 按步骤完成工作流的运行
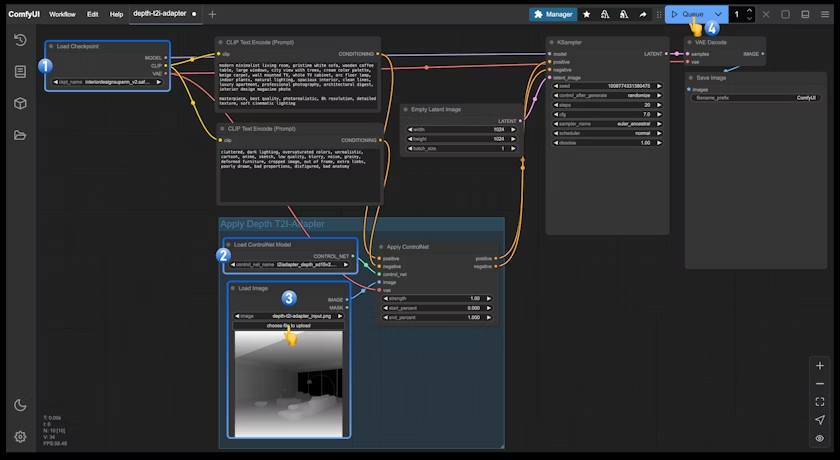
- 确保
Load Checkpoint可以加载 interiordesignsuperm_v2.safetensors - 确保
Load ControlNet可以加载 t2iadapter_depth_sd15v2.pth - 在
Load Image中点击Upload上传之前提供的输入图片 - 点击
Queue按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来执行图片的生成

3.T2I Adapter 通用使用技巧
3.1 输入图像质量优化
无论应用场景如何,高质量的输入图像都是成功使用 T2I Adapter 的关键:
- 对比度适中:控制图像(如深度图、线稿)应有明确的对比,但不要过度极端
- 清晰的边界:确保主要结构和元素边界在控制图像中清晰可辨
- 噪点控制:尽量避免控制图像中有过多噪点,特别是深度图和线稿
- 合理的布局:控制图像应当具有合理的空间布局和元素分布
3.2 T2I Adapter 的使用特点
T2I Adapter 的一大优势是可以轻松组合多个条件,实现复杂的控制效果:
- 深度 + 边缘:控制空间布局的同时保持结构边缘清晰,适用于建筑、室内设计
- 线稿 + 颜色:控制形状的同时指定配色方案,适用于角色设计、插画
- 姿态 + 分割:控制人物动作的同时定义场景区域,适用于复杂叙事场景
T2I Adapter 之间的混合,或与其他控制方法(如ControlNet、区域提示词等)的组合,可以进一步扩展创作可能性。要实现混合,只需按照与 混合 ControlNet 相同的方式,通过链式连接多个 Apply ControlNet 节点即可。
六、ControlNet 混合使用示例
我们将在本篇示例中,完成多个 ControlNet 混合使用,学会使用多个 ControlNet 模型来控制图像生成
在 AI 图像生成中,单一的控制条件往往难以满足复杂场景的需求。混合使用多个 ControlNet 可以同时控制图像的不同区域或不同方面,实现更精确的图像生成控制。
在一些场景下,混合使用 ControlNet 可以利用不同控制条件的特性,来达到更精细的条件控制:
- 场景复杂性:复杂场景需要多种控制条件共同作用
- 精细控制:通过调整每个 ControlNet 的强度参数,可以精确控制各部分的影响程度
- 互补效果:不同类型的 ControlNet 可以互相补充,弥补单一控制的局限性
- 创意表达:组合不同控制可以产生独特的创意效果
1.混合 ControlNet 的使用方法
当我们混合使用多个 ControlNet 时,每个 ControlNet 会根据其应用的区域对图像生成过程施加影响。ComfyUI 通过 Apply ControlNet 节点的链式连接方式,允许多个 ControlNet 条件按顺序叠加应用混合控制条件:
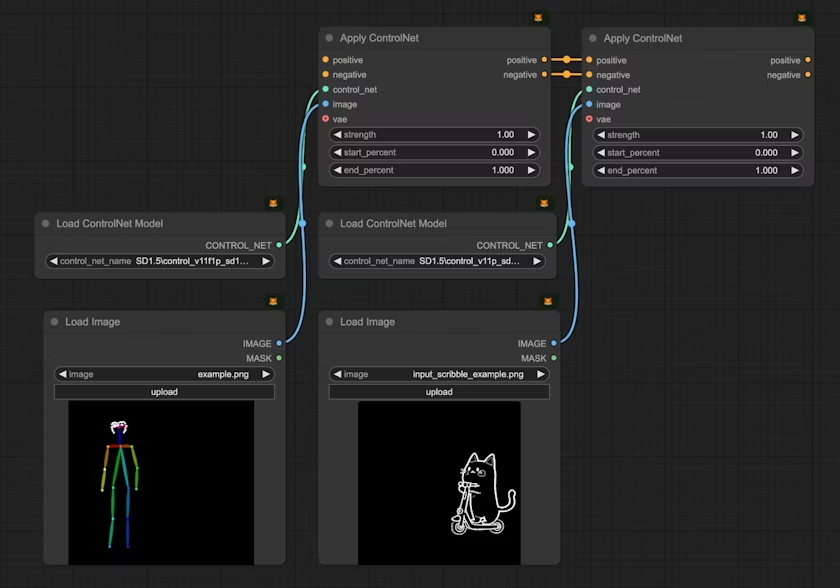
2.ComfyUI ControlNet 区域分治混合示例
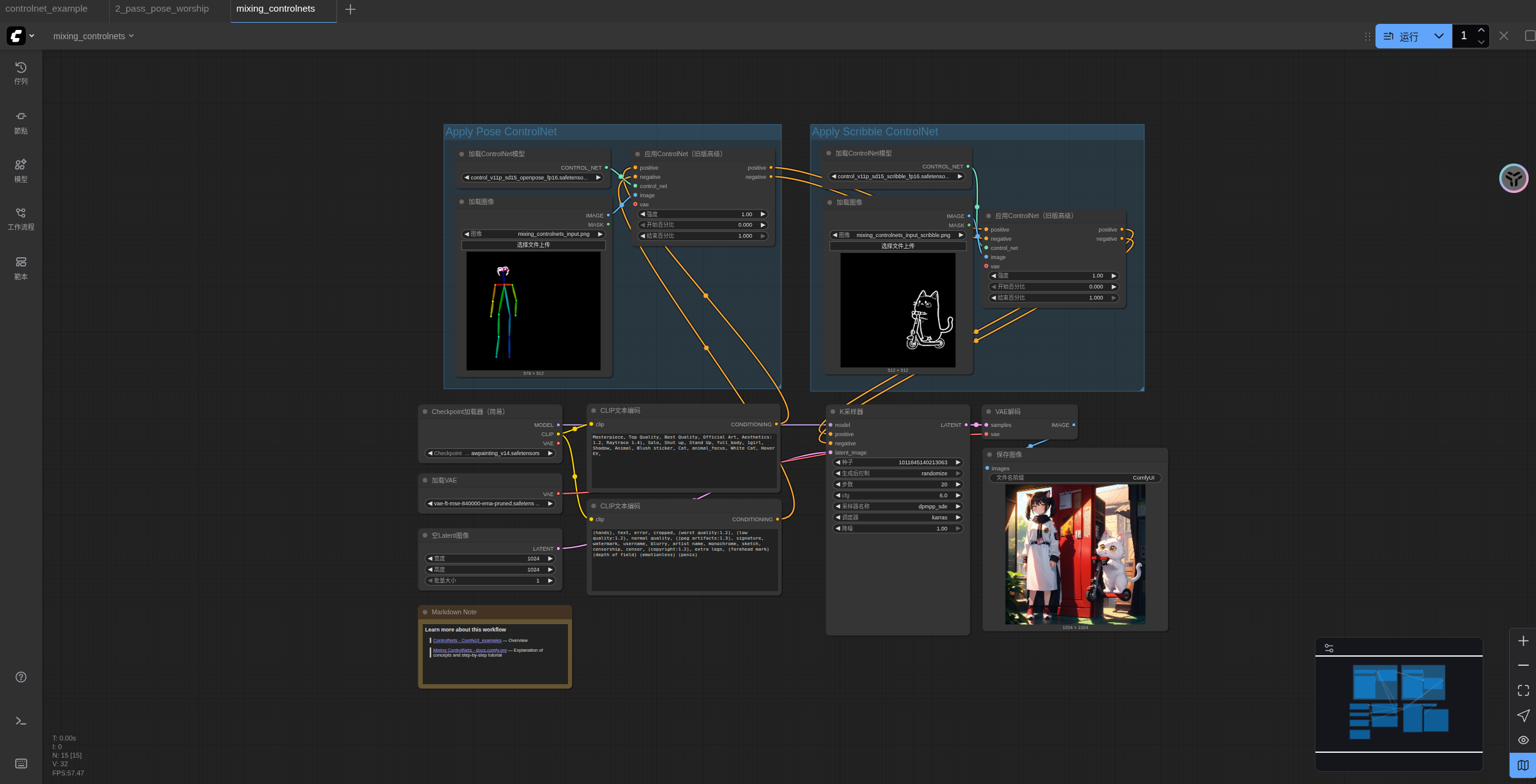
在本示例中,我们将使用 Pose ControlNet 和 Scribble ControlNet 的组合来生成一张包含多个元素的场景:左侧由 Pose ControlNet 控制的人物和右侧由 Scribble ControlNet 控制的猫咪滑板车。
2.1 ControlNet 混合使用工作流素材
请下载下面的工作流图片,并拖入 ComfyUI 以加载工作流
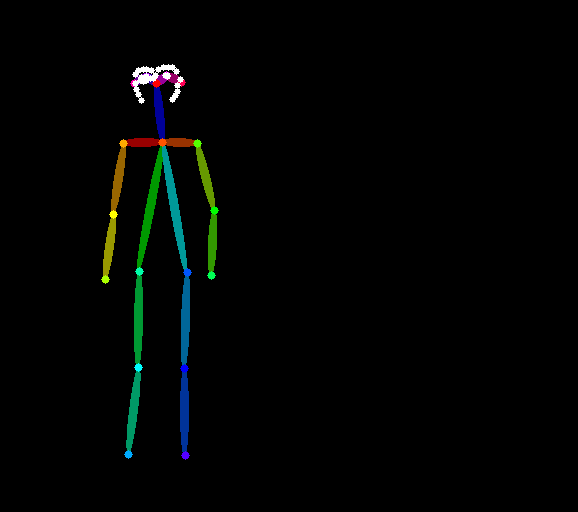
该工作流图片包含 Metadata 数据,可直接拖入 ComfyUI 或使用菜单 `Workflows` -> `Open(ctrl+o)` 加载。系统会自动检测并提示下载所需模型。用于输入的 pose 图片(控制左侧人物姿态):
用于输入的 scribble 图片(控制右侧猫咪和滑板车):

2.2 手动模型安装(前面都安装过了)
如果你网络无法顺利完成对应模型的自动下载,请尝试手动下载下面的模型,并放置到指定目录中- awpainting_v14.safetensors
- control_v11p_sd15_scribble_fp16.safetensors
- control_v11p_sd15_openpose_fp16.safetensors
- vae-ft-mse-840000-ema-pruned.safetensors
ComfyUI/
├── models/
│ ├── checkpoints/
│ │ └── awpainting_v14.safetensors
│ ├── controlnet/
│ │ └── control_v11p_sd15_scribble_fp16.safetensors
│ │ └── control_v11p_sd15_openpose_fp16.safetensors
│ ├── vae/
│ │ └── vae-ft-mse-840000-ema-pruned.safetensors
2.3 按步骤完成工作流的运行
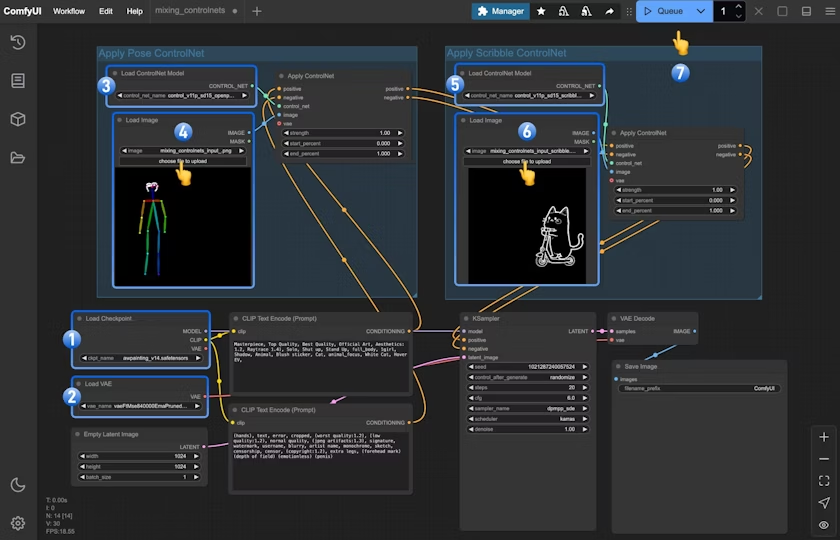
按照图片中的数字标记,执行以下步骤:
- 确保
Load Checkpoint可以加载 awpainting_v14.safetensors - 确保
Load VAE可以加载 vae-ft-mse-840000-ema-pruned.safetensors
第一组 ControlNet 使用 Openpose 模型:
3. 确保Load ControlNet Model加载 control_v11p_sd15_openpose_fp16.safetensors
4. 在Load Image中点击Upload 上传之前提供的 pose 图片
第二组 ControlNet 使用 Scribble 模型:
5. 确保Load ControlNet Model加载 control_v11p_sd15_scribble_fp16.safetensors
6. 在Load Image中点击Upload 上传之前提供的 scribble 图片
7. 点击 Queue 按钮,或者使用快捷键 Ctrl(cmd) + Enter(回车) 来执行图片的生成
3.工作流讲解
3.1 强度平衡
当控制图像不同区域时,强度参数的平衡尤为重要:
- 如果一个区域的 ControlNet 强度明显高于另一个,可能导致该区域的控制效果过强而抑制另一区域
- 推荐为不同区域的 ControlNet 设置相似的强度值,例如都设为 1.0
3.2 提示词技巧
在区域分治混合中,提示词需要同时包含两个区域的描述:
"A woman in red dress, a cat riding a scooter, detailed background, high quality"
这样的提示词同时涵盖了人物和猫咪滑板车,确保模型能够同时关注两个控制区域。
4.同一主体多维控制的混合应用
除了本例展示的区域分治混合外,另一种常见的混合方式是对同一主体进行多维控制。例如:
- Pose + Depth:控制人物姿势及空间感
- Pose + Canny:控制人物姿势及边缘细节
- Pose + Reference:控制人物姿势但参考特定风格
在这种应用中,多个 ControlNet 的参考图应该对准同一主体,并调整各自的强度确保适当平衡。
通过组合不同类型的 ControlNet 并指定其控制区域,你可以对画面元素进行精确控制。