机器学习项目中正确进行超参数优化:Optuna库的使用
本篇文章Why Most People Get Hyperparameter Tuning Wrong (and How to Fix It with Optuna Visualizations)适合数据科学家和机器学习从业者,重点在于通过Optuna的可视化工具优化超参数调优过程。文章强调调优不仅仅是寻找最佳参数,更是理解优化过程,避免无效的计算资源浪费。
文章目录
- 1. 调优到“能用就行”的隐藏成本
- 2. 代码速览
- 3. 输出图表 1:时间线(纵观全局)
- 3.1. 为什么它很重要:
- 3.2. 时间线图的常见错误:
- 4. 输出图表 2:优化历史(是进步还是噪音?)
- 4.1. 为什么它很重要:
- 4.2. 常见误解:
- 5. 输出图表 3:参数重要性(什么才是真正重要的)
- 5.1. 为什么它很重要:
- 5.2. 常见陷阱:
- 6. 输出图表 4:经验分布函数(风险意识)
- 6.1. 为什么它很重要:
- 7. 常见陷阱(以及如何避免它们)
- 8. 展望:超参数调优的未来
- 9. 结论

如果你是一名数据科学家、机器学习工程师或分析专业人士,你可能经历过:无休止的网格搜索循环、令人困惑的图表,以及对真正重要的东西缺乏清晰的认识。
大多数人犯的错误是:他们认为调优仅仅是“找到最佳参数”。实际上,它是关于理解优化过程。如果你不理解,你将浪费计算资源,并错过隐藏在搜索中的洞察。
在这篇文章中,我将向你展示如何利用 Optuna 内置的可视化功能,将超参数调优从一个黑盒转变为一个洞察金矿。我将通过真实的案例、我犯过的错误,以及你如何将相同的方法应用到你的项目中——无论是训练 XGBoost、LightGBM 还是深度学习模型。
1. 调优到“能用就行”的隐藏成本
当我第一次为一个金融数据预测项目工作时,我以为超参数调优很简单:
- 定义搜索空间
- 运行数百次试验
- 选择最佳结果
但现实给了我沉重一击。我通宵运行了 500 次 XGBoost 试验。第二天早上,我的最佳分数与基本基线相比几乎没有改善。我浪费了计算时间和云积分,我的经理也并不满意。
这个错误比人们承认的更常见。事实上,一项 Kaggle 研究估计,超过 60% 的调优工作浪费在选择不当的搜索策略上。人们普遍认为“更多试验 = 更好的结果”。但如果没有可视化,你不知道自己是在学习还是在原地踏步。
这就是 Optuna 可视化为我扭转局面之处。我不再盲目地希望第 499 次试验会是神奇的一次,而是开始看到搜索背后的故事。哪些试验有效,哪些无效,最重要的是——为什么。
👉 经验教训: 超参数调优不仅仅是追求最佳分数。它是关于从过程中提取洞察。
2. 代码速览
在深入探讨之前,让我们先看看驱动这一切的代码片段:
fig = optuna.visualization.plot_timeline(study)
show(fig)try:fig = optuna.visualization.plot_optimization_history(study)show(fig)
except:passfig = optuna.visualization.plot_param_importances(study)
show(fig)fig = optuna.visualization.plot_edf(study)
show(fig)
这不到 15 行代码,但其洞察深度是巨大的。每个图表都告诉你不同的信息:
- 时间线(Timeline) → 你的试验运行效率如何
- 优化历史(Optimization history) → 你是在收敛还是在浪费时间
- 参数重要性(Parameter importances) → 哪些参数最重要
- EDF (Empirical Distribution Function) → 你最佳解决方案的稳定性如何
我将详细解读每一个图表,包括故事、陷阱和技巧。
3. 输出图表 1:时间线(纵观全局)
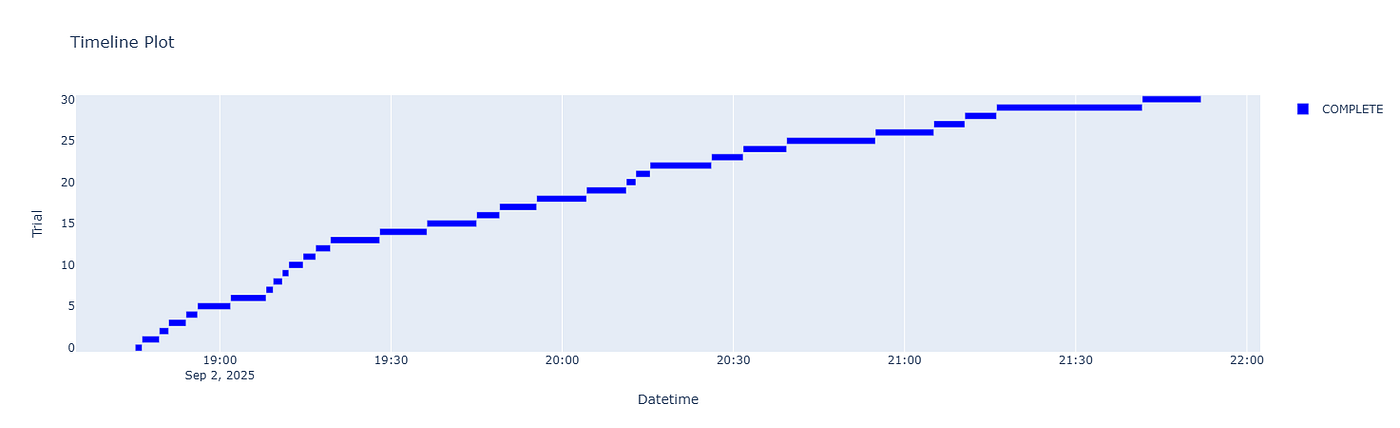
将时间线图(timeline plot)想象成你调优实验的航班追踪器。每个试验都是一个点。你可以看到它何时开始、花费了多长时间以及是否成功完成。
当我第一次运行时间线图时,我发现了一些令人担忧的事情:大约 30% 的试验过早失败。我允许了无效的参数组合(例如 LightGBM 中荒谬的学习率或最大深度值)。如果没有这个图表,我就不会发现这种低效率。
3.1. 为什么它很重要:
- 检测瓶颈:有些试验需要 5 秒,另一些则需要 5 分钟。也许你的数据集太大,或者搜索空间太宽。
- 发现失败的试验:如果许多试验在同一点停止,说明你的搜索空间包含了无效的范围。
- 优化资源:云积分很昂贵。了解哪些试验浪费时间有助于你更好地进行剪枝。
3.2. 时间线图的常见错误:
- 忽略试验持续时间:如果你可以接受 30 分钟的试验,那没问题。但如果你要运行 1000 次,你就负担不起了。
- 不进行剪枝:Optuna 内置了剪枝功能(例如 MedianPruner)。不使用它就像让糟糕的投资耗尽你的资金一样。
👉 行动步骤: 在你的前 20-30 次试验后使用时间线图。这足以在扩大规模之前发现效率低下的地方。
4. 输出图表 2:优化历史(是进步还是噪音?)
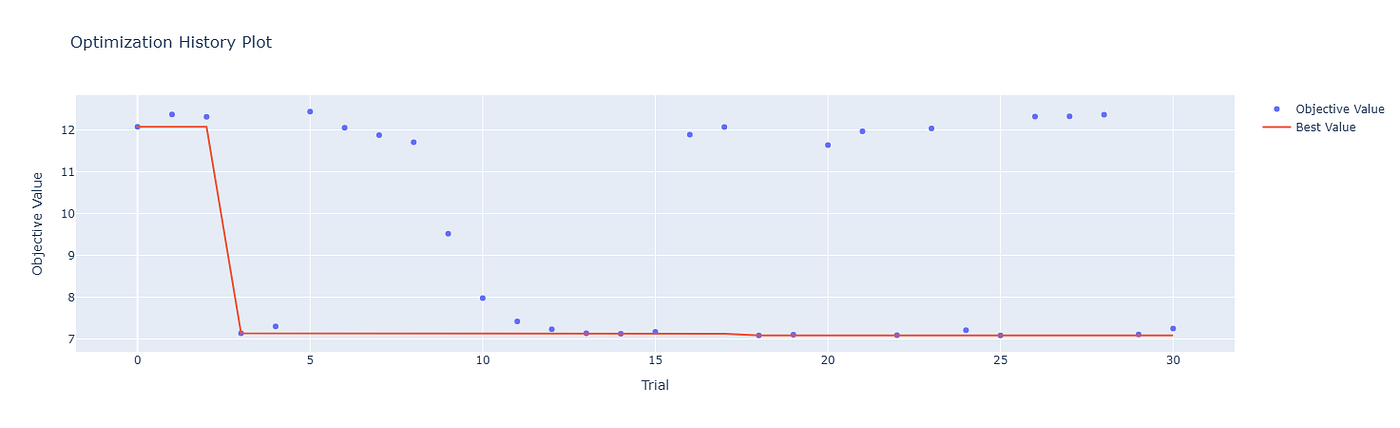
优化历史图就像实时观察你的模型学习过程。它显示了每次试验后达到的最佳分数。
在我一个项目中,我为客户流失预测调整了一个 CatBoost 模型。起初,我以为我需要 500 多次试验。但当我绘制优化历史图时,我看到在 70 次试验后,曲线趋于平稳。之后没有明显的改进。
这个单一的可视化为我节省了数小时的计算时间,并让我有信心提前停止。
4.1. 为什么它很重要:
- 收敛检测:你的模型还在改进吗,还是已经达到了上限?
- 搜索空间反馈:如果改进停止得太早,你的参数范围可能太窄。
- 基准测试:比较不同的采样器(TPE、CMA-ES、Random)如何影响曲线。
4.2. 常见误解:
- “更多试验总是有帮助。” 错误。收敛后,更多试验 = 浪费时间。
- “最佳分数才是最重要的。” 不对。达到该分数的_路径_显示了你的过程有多稳定。
👉 行动步骤: 如果你的曲线变平,暂停并重新考虑你的搜索空间,然后再进行更多试验。
5. 输出图表 3:参数重要性(什么才是真正重要的)
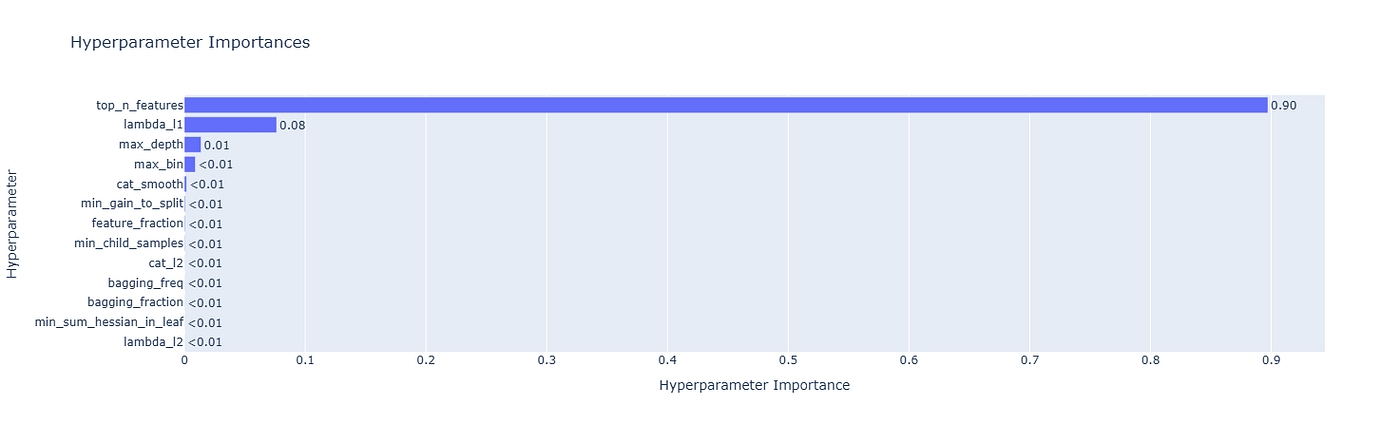
这是一个改变游戏规则的图表。参数重要性图告诉你哪些超参数真正驱动结果。
当我调整 LightGBM 时,我以为 learning_rate 和 num_leaves 是最重要的。但图表显示 min_child_samples 影响最大。我以前从未认为这个参数是关键。
5.1. 为什么它很重要:
- 优先级排序:专注于调整有影响力的参数。缩小不重要参数的范围。
- 调试:如果你认为重要的参数重要性接近于零,也许你的数据集不需要它。
- 研究洞察:这对于讲故事很有用。你可以解释你的模型_为什么_会改进。
5.2. 常见陷阱:
- 过度拟合“重要性”。 仅仅因为一个参数占主导地位,并不意味着其他参数在组合中不重要。
- 误解全局与局部效应。 重要性显示的是整体效应,而不是逐个试验的交互。
👉 行动步骤: 在大约 50 次试验后使用此图表来缩小你的搜索空间。这将大大加快后续搜索的速度。
6. 输出图表 4:经验分布函数(风险意识)
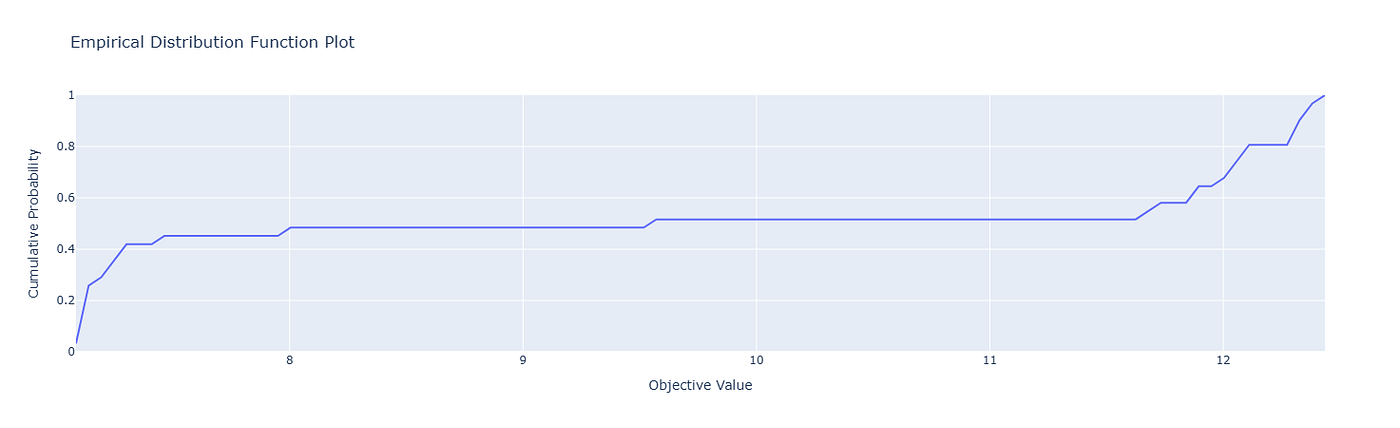
EDF 图表可能是最被低估的一个。它不仅仅关注最佳分数,还显示了试验结果的分布。
这很重要,因为在生产环境中,你不在乎“一次幸运的运行”。你在乎的是稳定性。
例如,我调整了一个用于应收账款(AR)预测的 XGBoost 模型。两组参数给出了几乎相同的最佳 RMSE。但 EDF 显示其中一组在试验中更加一致。你猜我部署了哪一个?
6.1. 为什么它很重要:
- 风险管理:选择稳定的参数而不是脆弱的参数。
- 比较:如果两个模型的得分相似,EDF 会告诉你哪个更健壮。
- 生产就绪:稳定的模型泛化能力更好。
👉 行动步骤: 在最终确定参数之前使用 EDF。选择稳定性而不是稍微更高的峰值。
7. 常见陷阱(以及如何避免它们)
超参数调优并非万无一失。以下是我看到的最大错误:
- 运行的试验太少
试验次数少于 20 次,你的图表会误导你。至少从 50-100 次开始。 - 忽略剪枝
Optuna 可以自动剪枝不良试验。不使用它就像让不良投资耗尽你的投资组合一样。 - 追逐单一的最佳试验
单一的最佳分数可能只是侥幸。始终检查 EDF 和优化历史。 - 不记录种子
可复现性至关重要。没有固定的种子,你无法可靠地比较运行结果。
👉 黄金法则: 及早可视化,经常解释,持续改进。
8. 展望:超参数调优的未来
超参数调优正在从暴力破解转向智能探索 + 可解释性。
以下是我看到的一些趋势:
- 元可视化: 不仅仅是单一研究图表,而是比较多个项目的仪表板。
- 协作调优: 团队共享搜索洞察(例如,跨数据集的参数重要性)。
- 风险优先调优: 稳定性将比原始准确性更重要,尤其是在金融、医疗保健和关键基础设施领域。
- 与 AutoML 集成: Optuna 等工具将作为 AutoML 平台的核心,使可解释性对非专业人士也易于访问。
如果你是今天的实践者,学习解释这些图表将为你提供一项面向未来的技能。
9. 结论
让我们回顾一下:
- 时间线(Timeline) 帮助你发现效率低下的地方。
- 优化历史(Optimization history) 显示收敛模式。
- 参数重要性(Parameter importances) 揭示性能的真正驱动因素。
- EDF 确保部署前的稳定性。
如果你认真对待机器学习,不要只追求最佳试验。可视化你的搜索,解读其中的故事,并做出更明智的决策。
👉 我给你的挑战:下次你运行 Optuna 时,不要只停留在 study.best_trial。运行这四个图表。看看会发生什么故事。