OpenTenBase日常操作锦囊(新手上路DML)
OpenTenBase日常操作锦囊(新手上路DML)
- 前情提要
- 系统升级
- 数据库初始化
- 基本操作
- 创建数据表
- 创建shard普通表(分片表)
- 创建shard普通分区表(分片表+分区)
- 创建复制表
- 创建单表
- 适用场景
- DML操作
- INSERT
- UPDATE
- DELETE
- SELECT
- 最后总结
前情提要
在上一篇文章(https://cloud.tencent.com/developer/article/2565410)中,我们提到当前的腾讯云轻量应用服务器是4G 内存,在启动OpenTenBase 数据库时一直启动不成功,更改配置文件也无法成功。在文章结尾,给出了推测,(关于系统的 4G内存要求,个人理解4G内存可能不够,应该8G 内存起步才可以)。那么今天,我们就来尝试升级服务器内存为 8G 内存后再次尝试。
系统升级
腾讯云轻量应用服务器升级服务器内存比较简单,可以直接在轻量应用服务器控制台找到我们的云服务去,点击右上角的…选择【升级套餐】后,在打开的升级套餐页面选择需要升级的套餐即可
这里我已经升级过了,具体的升级操作就不再详细描述,比较简单。
升级系统内存为8G之后,需要将我们的 pgxc_ctl.conf 配置文件中内存设置参数更新为原来的参数,更新参数后再次通过pgxc_ctl 工具 start all 命令启动OpenTenBase 数据库
shared_buffers = 1024MB
max_connections = 1000
可以看到数据库启动成功后的信息,启动成功后输入 monitor all 可以查看服务启动情况

下面我们就可以通过任意一个CN访问数据库集群,在Linux命令行下通过psql访问的具体示例如下。使用公网IP 或者内网IP都可以
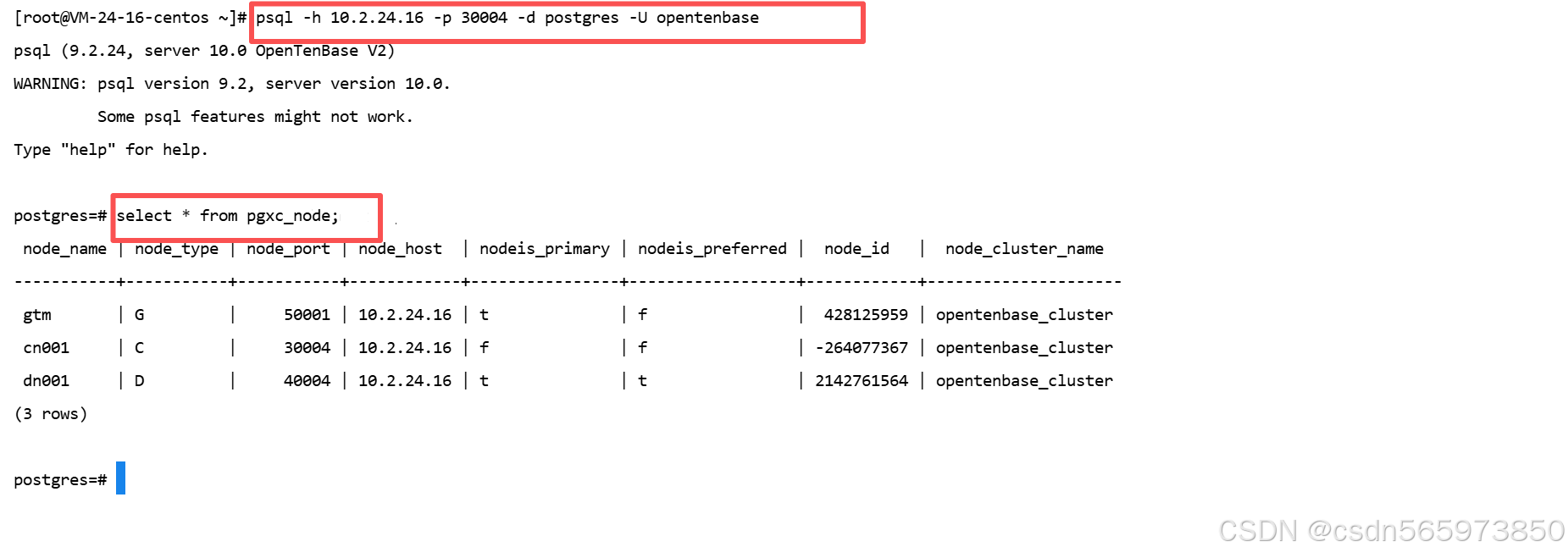
psql -h 10.2.24.16 -p 30004 -d postgres -U opentenbase
psql -h 101.43.245.198 -p 30004 -d postgres -U opentenbase#查询节点信息
select * from pgxc_node;
执行后可以看到具体的节点信息
到这里,我们关于上一篇文章未能完成的任务就全部完成,圆满了。下面我们就开始今天新的内容。安装部署了数据库,后面我们是不是就要来了解一下数据库的一些操作了,下面开始吧!
数据库初始化
OpenTenBase使用datanode group来增加节点的管理灵活度,要求有一个default group才能使用,因此需要预先创建;一般情况下,会将节点的所有datanode节点加入到default group里 另外一方面,OpenTenBase的数据分布为了增加灵活度,加了中间逻辑层来维护数据记录到物理节点的映射,我们叫sharding,所以需要预先创建sharding
postgres=# create default node group default_group with (dn001);
postgres=# create sharding group to group default_group;
创建成功后如图所示

数据库初始化成功之后,我们就可以进行我们后续的创建数据库,用户,创建表,增删查改等操作
postgres=# create database test;CREATE DATABASE
postgres=# create user test with password 'test';
CREATE ROLE
postgres=# alter database test owner to test;
ALTER DATABASE
postgres=# \c test testpsql (9.2.24, server 10.0 OpenTenBase V2)WARNING: psql version 9.2, server version 10.0.Some psql features might not work.
You are now connected to database "test" as user "test".
test=> create table foo(id bigint, str text) distribute by shard(id);
CREATE TABLE
test=> insert into foo values(1, 'tencent'), (2, 'shenzhen');
COPY 2
test=> select * from foo;id | str
----+----------1 | tencent2 | shenzhen
(2 rows)
上述命令截图效果如下展示

基本操作
在通过源码编译安装部署完 OpenTenBase 数据库集群之后,我们也简单测试了一下过去创建数据库、数据库用户、新建表、增删改查的基本操作,使用上和过去的开源数据库 Mysql 基本一致,下面我们来讲述一下 OpenTenBase 的基本使用操作。
创建数据表
创建shard普通表(分片表)
CREATE TABLE public.t1
( f1 int not null,f2 varchar(20),primary key(f1)
) distribute by shard(f1) to group default_group;
创建完成后可以通过以下命令(\d+ 表名)来查看表结构
postgres=# \d+ public.t1

分片表建表语句说明:
-
distribute by shard(x) 用于指定分布键,数据分布于那个节点就是根据这个字段值来计算分片。
-
to group xxx 用于指定存储组(每个存储组可以有多个节点)。
-
分布键字段值不能修改,字段长度不能修改,字段类型不能修改。
分布式数据库中,分片表是使用最多的表类型,合理的分片键设置将会系统的性能提升很多倍,不合理的分片键也会导致SQL性能恶化严重,因此分片键的优化是分布式SQL优化的重点中的重点。
分片键选择准则:
-
准则1:高频类SQL的业务字段,避免SQL产生分布式事务,避免跨DN节点数据插入、更新、删除(SQL能带上分片键)。
-
准则2:分析类SQL的关联字段,尽量避免SQL产生批量跨DN节点数据交互(关联字段为分片键)。
-
准则3:尽量避免DN节点数据不均衡。
准则1、2和准则3可能有冲突,选择时准则1高于准则2、3 数据库在迁移时,会使用默认的规则指定分片键,大部分情况下是最优的,但仍有部分情景需要调整,下面是默认原则:
-
1)有主键,则选择主键做分片键。如果主键是复合字段组合,则选择第一个字段做分片键。
-
2)有唯一索引,则选择唯一索引列做分片键。如果唯一索引是复合字段组合,则选择第一个字段做分片键。
-
3)使用第一个字段做分片键。
创建shard普通分区表(分片表+分区)
当遇到数据表数据较大时,除了可以通过分片表来分散每个表的数据量,还可以在分片表的基础上进一步分区,从而减小单表的数据量,我们可以通过以下命令来创建分区表
create table public.t1_pt
(
f1 int not null,
f2 timestamp not null,
f3 varchar(20),
primary key(f1)
)
partition by range (f2)
begin (timestamp without time zone '2019-01-01 0:0:0')
step (interval '1 month') partitions (3)
distribute by shard(f1)
to group default_group;
创建分片表+分区 之后我们来查看表结构

关于建表语句的说明:
- partition by range (x)
用于指定分区键,支持timesamp,int类型,数据分布于那个子表就是根据这个字段值来计算分区。 - begin( xxx )指定开始分区的时间点。
- step(xxx)指定分区有周期 。
- partions(xx)初始化时建立分区子表个数。
- 增加分区子表的方法ALTER TABLE public.t1_pt ADD PARTITIONS 2;
创建复制表
对于数据量较少,在查询时又想JOIN,但是又受限于需要跨库查询的情况,可以使用复制表。复制表的建表语句
create table public.t1_rep
(
f1 int not null,
f2 varchar(20),
primary key(f1)
)
distribute by replication
to group default_group;
创建完成之后我们可以来查看一下我们的表结构

关于复制表相关说明:
-
distribute by replication 指定分布方式。
-
经常要跨库JOIN的小数据量表可以考虑使用复制表。
-
复制表是所有节点都有全量数据,对于大数据量的数据表不适合。
-
复制表更新性能较低。
创建单表
个人理解单表的使用场景比较局限,通常情况下,表与表之间数据往往都会有一定关联,不存在完全独立,不与其他表 JOIN 的表,但是从数据库设计上,还是有存在的必要,因此这里也简单创建一个单表
create table public.t1_signal
(
f1 int not null,
f2 varchar(20),
primary key(f1)
)
distribute by replication
to group single_group;
需要注意的点:
单表即表只存在于某一个DN节点,目前还不支持指定任意DN节点进行单表创建。可以通过多group的能力迂回实现:先添加一个DN节点,然后将该节点创建为一个独立的group中,可以命名为single_group。然后创建表时,指定表的group为刚刚创建的single_group。(注意:不能使用default_group中的节点,创建group的时候也会失败的)。
适用场景
根据以上几种表类型的描述及适用场景的整理,下面我们来看一下这几种表类型的适用场景
| 分布式表类型 | 描述 | 适用场景 | 使用约束 |
|---|---|---|---|
| 分片表 | 表记录按分片键值进行hash打散到所有分片中,每个分片都只有一部分数据 | 数据量特别大,并且查询、删除、修改该表的数据时可以指定分片键作为操作条件,大多数语句不涉及跨库分布式事务访问 | 查询、更新、删除数据时需要指定分片键;分片键字段类型、长度不能修改,分片键值不能直接更新;目前不能基于非分片键字段创建主键或者唯一索引 |
| 复制表 | 所有分片中都存储一份相同的全量数据 | 经常要使用非分片键字段JOIN并且更新频率较低的小表推荐使用复制表 | 该表并发更新低、数据量少 |
| 单表 | 存储在一个专门定义的group中,这个group中只有一个分片 | 查询、删除、修改该表的数据时无法利用分片键,更新频繁,但数据量不是特别大 | 更新频繁,数据量不是特别大,不需要与其它分片表或者复制表进行JOIN操作 |
DML操作
INSERT
执行数据表的插入操作
## 创建表
CREATE TABLE public.t1_insert_mul
( f1 int not null,f2 varchar(20),primary key(f1)
) distribute by shard(f1) to group default_group;
## 批量插入数据
postgres=# INSERT INTO t1_insert_mul VALUES(1,'opentenbase'),(2,'pg');
## 插入数据并返回
postgres=# insert into t1_insert_mul values(4,'opentenbase') returning *;f1 | f2
----+-------------4 | opentenbase
(1 row)

UPDATE
更新表数据
## 查询表数据
postgres=# select * from t1_insert_mul;f1 | f2
----+-------------1 | opentenbase2 | pg4 | opentenbase
(3 rows)
## 更新表数据(基于分布键条件更新)
postgres=# UPDATE t1_insert_mul SET f2='opentenbase2' where f1=1;
## 更新后查询结果
postgres=# select * from t1_insert_mul;f1 | f2
----+--------------2 | pg4 | opentenbase1 | opentenbase2
(3 rows)
其中 基于分布键更新 性能最优,扩展性好
基于 非分布键更新 则是更新时指定非 分布键 字段作为更新条件,比如上表除 f1 以外的字段作为条件。更新语句发往所有节点。
对于分区表,还可以通过指定具体分区更新数据
## 创建数据表
create table public.t1_pt_update
(
f1 int not null,
f2 timestamp not null,f3 varchar(20),primary key(f1) )
partition by range (f2) begin (timestamp without time zone '2019-01-01 0:0:0')
step (interval '1 month') partitions (2)
distribute by shard(f1)
to group default_group;
## 插入数据
postgres=# insert into t1_pt_update values(1,'2019-01-01 00:00:00','pg');
为了可以看到更新执行的过程,我们可以加上 explain 关键词来查看
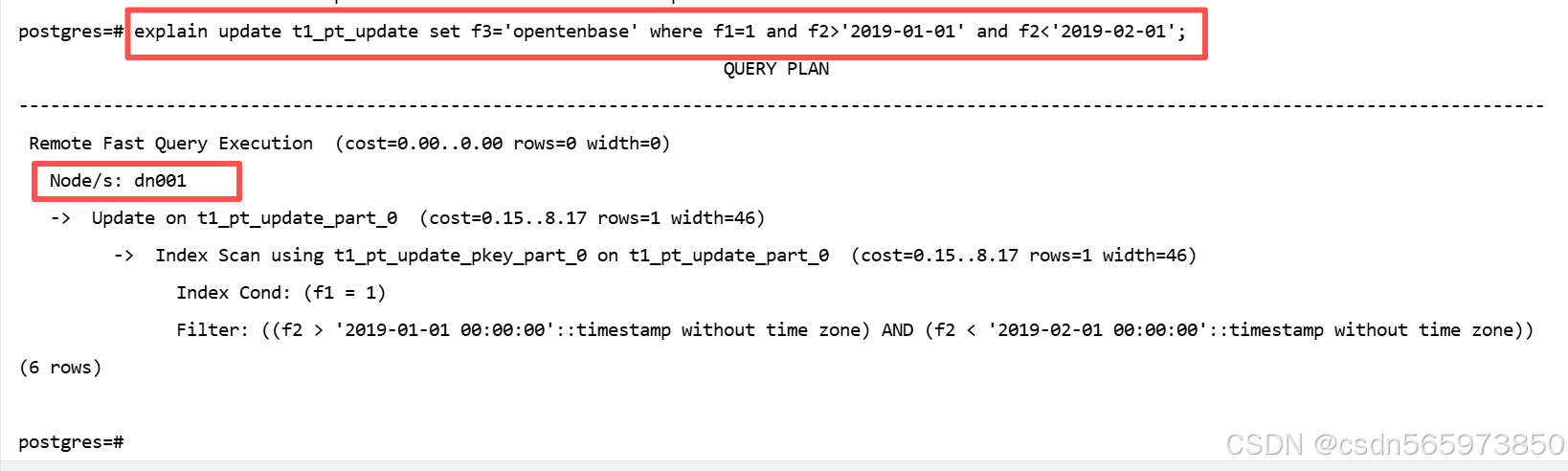
postgres=# explain update t1_pt_update set f3='opentenbase' where f1=1 and f2>'2019-01-01' and f2<'2019-02-01';
执行结果如图,带分区条件更新,性能最优,扩展性好
这里需要注意的是,分区键不能更新,对于上面我们的表 t1_pt_update 分区键是 f2 ,那么如果更新分区键 f2 的话则会报错
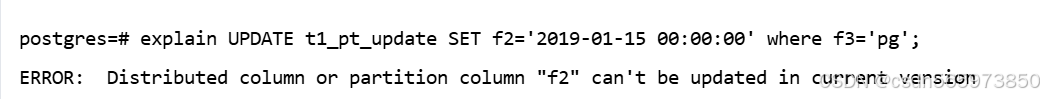
DELETE
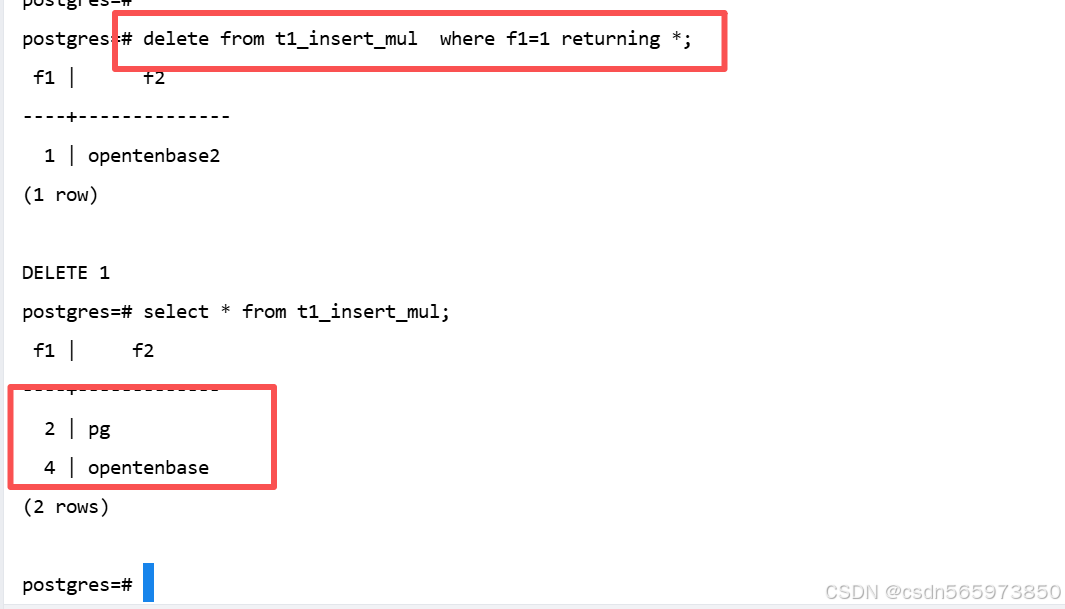
删除表记录,同样比较简单,比如这里我们删除表数据
postgres=# delete from t1_insert_mul where f1=1 returning *;
删除返回记录
SELECT
对于查询,和更新操作相似,对于分布键和非分布键有所不同,对于分布键查询性能最优,扩展性好,对于非分布键查询,查询语句发往所有节点,然后在CN汇总
## 分布键查询
postgres=# explain select * from t1_insert_mul where f1=2;
## 非分布键查询
postgres=# explain select * from t1_pt_update where f3='pg';


当然,对于sql 查询的操作远不是单表查询这么简单,这里只是简单举例。查询往往还有涉及到关联查询,同样的道理,比如
基于分布键的JOIN查询,性能最优,扩展性好。基于非分布键的JOIN查询,则需要在DN做数据重分布。
更多关于 OpenTenBase 的查询操作以及函数适用可以参考文档:https://docs.opentenbase.org/guide/04-advanced-use/
最后总结
这里我们成功将腾讯云服务器升级至8G内存并部署OpenTenBase数据库后,随后重点介绍了该分布式数据库的核心操作与表类型。文章详细阐述了如何初始化数据库集群(创建默认节点组和分片),并深入讲解了四种关键表类型:分片表(适用于海量数据,需谨慎选择分片键)、分区表(在分片基础上进一步细分)、复制表(存储全量数据,适用于频繁关联的小表)和单表(存储于单一节点)。最后,文章演示了基本的DML操作(增删改查),并特别强调了基于分布键进行操作能获得最优性能,为后续高效使用OpenTenBase提供了清晰的实践指南。
对于OpenTenBase 数据库 sql 语句的操作,基础的增删改查sql 和我日常用的开源的 Mysql 数据库差异性较小,而关于数据库函数这方面,OpenTenBase 可以完全兼容 PostgreSQL,相信用过 PostgreSQL 的小伙伴会更容易上手操作。