信息检索2
接上节课 信息检索1 -笔记版

对比学习与监督对比学习:
对比学习是一种自监督方法,它通过将同一数据样本的不同增强版本(如旋转、裁剪后的图像)视为正样本对,而将其他样本视为负样本,从而在无需标签的情况下学习数据的内在结构;其目标是让模型学会区分“相似”与“不相似”的样本。属于无标签场景。
监督对比学习在此基础上引入了真实类别标签,将同一类别内的所有样本,包括增强后的,都视为正样本,不同类别的样本为负样本。这种方法不仅拉近同一样本的不同增强,还增强了同类样本之间的聚类紧凑性,增强鲁棒性。
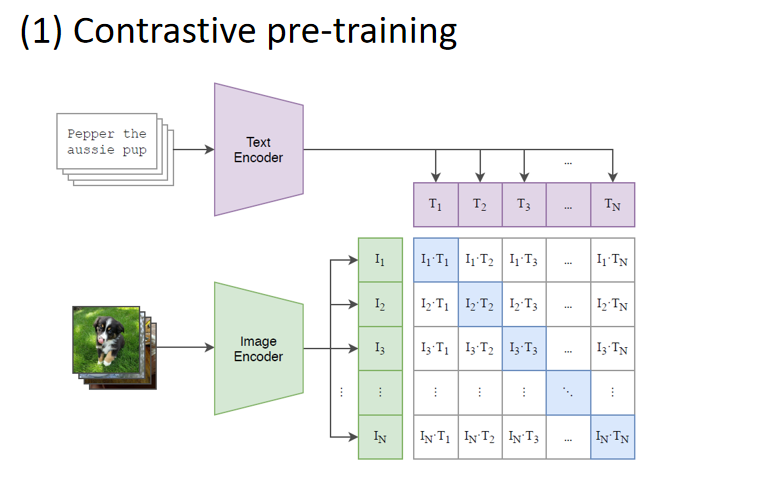
对比预训练(Contrastive Pre-training)
1. 数据输入
- 文本描述:“Pepper the aussie pup”作为文本输入。
- 图像数据:一张狗的照片作为图像输入。
2. 编码器
- Text Encoder:将文本描述转换为文本特征向量 TT。
- Image Encoder:将图像数据转换为图像特征向量 II。
3. 特征对齐
- 对于每一对文本和图像的特征向量 (Ii,Tj),计算它们之间的相似度(如余弦相似度)。
- 目标是让匹配的文本-图像对(例如“Pepper the aussie pup”与对应的狗照片)在特征空间中更接近,而不匹配的对则远离。
4. 损失函数
- 使用对比损失函数(如InfoNCE损失),最大化正样本对之间的相似度,最小化负样本对之间的相似度。
- 正样本对:匹配的文本-图像对
- 负样本对:不匹配的文本-图像对
5. 结果
- 经过对比预训练,模型能够学习到图像和文本之间的语义对应关系,使得同一概念的图像和文本在特征空间中靠近。
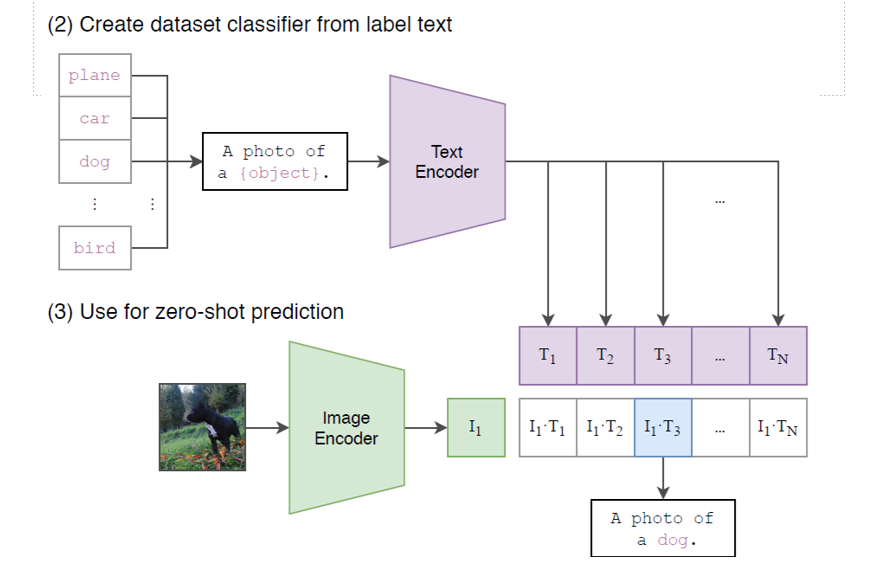
创建数据集分类器并用于零样本预测
1. 创建数据集分类器
- 标签文本:使用一系列类别标签(如“plane”, “car”, “dog”, “bird”等)。
- 文本模板:将每个标签插入到一个通用模板中,生成描述性文本(如“A photo of a {object}.”)。
- Text Encoder:将这些描述性文本编码为特征向量 T1,T2,...,TN。
2. 零样本预测
- 图像输入:给定一张未知类别的图像(如一只狗的照片)。
- Image Encoder:将图像编码为特征向量 I1I1。
- 相似度计算:计算图像特征向量 I1 与所有文本特征向量 T1,T2,...,TN 之间的相似度
- 预测结果:选择相似度最高的文本特征向量对应的标签作为预测结果(如“A photo of a dog.”)。
CLIP
通过对比学习的方式将图像和文本嵌入到同一个高维空间中, 使得语义相似的图像和文本在空间中靠近, 从而实现跨模态检索和生成任务。
使用CLIP模型进行跨模态检索的基本步骤:
1.加载CLIP模型,包括图像编码器和文本编码器
2.数据预处理,图像文本数据向量化,投射到新空间
图像预处理技术(如缩放、裁剪、归一化等)
文本预处理可能包括分词、去除停用词、词嵌入等步骤
把整个数据集进行编码,存储向量
3.计算相似度
使用余弦相似度或其他相似度度量方法,计算查询文本向量与图像库中所有图像向量的相似度
query文本图片都行
4.检索
5.改进:微调,百度百科等已有的数据既有文本又有图片;引入其他技术,重排列等
重排列:在初步检索或排序之后,对候选结果进行精细化排序
4.4 行为分析、舆论监控
社会媒体信息检索:信息内容、发布时间,地点,设备 个人历史记录 社会关系图谱
数据挖掘,信息分析:社交网络分析(虚拟世界中用户之间的关系网络及社区划分;虚拟世界中的领袖,利用虚拟世界的信息,发现现实世界的突发事件),事件发现(地震、疾病的传播、 突发事件的发现、追踪和分析)
舆情信息
4.5 个性化信息检索
个性化搜索引擎
搜索引擎重复 常点的网页,类似书签功能
4.6 移动搜索 手机
问题:小屏 语音
手机更方便输入图像和语音
排序精度高 因为显示内容少
4.7 自动问答QA
用户用自然语言方式的询问,系统从文档返回确切答案
(允许用户以自然语言方式询问,系统从单语或多语文档集中查找并返回确切答案或者蕴含答案文本片段的新型信息检索方式。)
并非指令(打开灯)
从应用场景的角度来看,可以分为在线客服、娱乐、 教育、个人助理和智能问答五个种类
几种QA:
1.IR-based QA:基于关键词匹配+信息抽取,仍然是基于浅层语义分析
2.Community QA:依赖于网民贡献,回答过程依然依赖于关键词检索技术
3.KB-based QA(基于知识检索的问答系统):
过程
(这个过程不确定是哪一种QA,先放一放)
问题分析
信息检索阶段: 该阶段目标是如何根据问题的分析结果去缩小答案 可能存在的范围,其中存在两个关键问题:(1)检索模型(找到和问题类似的问题) (2)两个问题相似性判断(返回答案或返回相似问题列表)
答案抽取部分: 判断答案的质量.研究怎么从问题的众多答案中选择一个最好的答案.
经典的知识图谱问答系统的流程
- 问题理解:识别问题中的实体(如“爱因斯坦”)和关系(如“获得诺贝尔奖的年份”)。
- 图谱查询:将问题转化为结构化查询语言(如 SPARQL 或 Cypher),在知识图谱中查找匹配的三元组。
- 返回答案:直接返回查到的结果,比如一个实体或数值
4.8 检索增强生成 RAG
1.大模型
大模型:多参数,多任务学习,强大计算资源,丰富的数据
2.大语言模型LLM
llm能实现QA,生成式QA(直接根据上下文生成自由文本)
根据少量数据泛化到不同领域,通过数据找到概率分布
问题找到的相关的表达形式,接近真实文本,大模型经过计算,可能错误,这是对问题的泛化

幻觉根本原因:数据量不够,需要增加领域知识
需要专业知识:知识图谱
生成模型局限性:幻觉,数学弱,缺乏可解释性
所以用检索增强生成RAG,用信息检索提高大模型能力
训练大语言模型方法:微调/RAG
RAG
为llm提供额外数据集,对于用户query,检索相关文档,作为提示给llm
(给 LLM 提供外部数据库, 对于用户问题 ( Query ),通过一些信息检索 ( Information Retrieval, IR ) 的技术, 先从外部数据库中检索出和用户问题相关的信息, 然后让 LLM 结合这些相关信息来生成结果。)
实现过程:
1.数据准备
数据提取:过滤压缩格式化,格式统一
分块:把大文档切成块 长度限制
向量化
数据入库:将向量化后的数据构建索引,并写入向量数据库(如Facebook Research的FAISS、Elasticsearch、Milvus等),以便快速检索
2.检索模块
问题向量化:用与数据准备阶段相同的嵌入模型,将用户的提问转化为向量
数据检索:计算相似度
3.生成模块
注入Prompt: 将用户查询和检索到的相关知识整合成一个提示模板(Prompt)。 Prompt中通常包括任务描述、背景知识(即检索得到的相关内容)和任务指令(一般为用户提问)等。
LLM生成答案: 将增强后的提示输入到大型语言模型(LLM)中,让模型生成相应的答案。 LLM会根据提供的背景知识生成更加丰富、准确和连贯的回答
解决的问题:
长尾知识,不常见的知识 作为上下文给出
私有数据,构建自己的对话系统
数据新鲜度 llm更新周期不快
来源验证和可解释性
区分IR-QA与RAG:
| 特性 | IRQA (基于信息检索的问答) | RAG (检索增强生成) |
|---|---|---|
| 核心范式 | 检索-抽取 | 检索-生成 |
| 答案来源 | 直接从检索到的文档中提取原文片段 | 由模型综合检索到的信息后生成 |
| 输出答案 | 一个确切的、已有的文本片段(字符串) | 一段新生成的、流畅的自然文本 |
| 关键技术 | 关键词检索(BM25)、模式匹配、浅层语义分析 | 密集向量检索 + 大型生成式语言模型(LLM) |
| 灵活性 | 差。只能回答答案明确写在文档中的问题。 | 强。可以总结、推理、重组信息,回答复杂问题。 |
| 答案质量 | 答案准确但生硬,可能缺乏上下文,可能是碎片化的。 | 答案连贯、完整、易于阅读,但可能包含模型幻觉(编造)。 |
| 处理未知 | 如果答案不在文档中,系统会失败。 | 即使检索到的文档不包含直接答案,LLM也可能根据知识进行推理(但需谨慎对待可靠性)。 |
| 可解释性 | 高。可以轻松追溯到答案所在的源文档。 | 中等。可以提供引用的源文档,但答案本身是生成的,可能与原文措辞不同。 |
第二章 词项词典
1.文档解析
文档格式:需要变成纯文本 Apache从office中读取
文档语言:若有其他语言,保留或是删除
文档编码方式:不同编码,解码统一
2.词条化
序列拆分为token(可能是两个单词)
英文有空白符分割
中文要分词
可能有专有名词表
连字符,空格,句号IEEE.802,数字,通过正则表达式
3.词项归一化
归一化:把不同表达归一为同一表达(token的压缩)
同义词
大小写
建立同义词扩展表,手工构造,把同义词合到一个词中
4.词干还原
去掉单词两端词缀的启发式过程(西方语系都很有用)
能提高召回率(查全率),可能降低准确率
中文:去掉重叠词,可能用不上
启发式规则
去后缀,去掉后缀后剩下的少,不能去掉
porter算法
5.词形归并
用词汇表分析,转化为一般形式
(利用词汇表和词形分析来减少曲折变化的形式,将其转变为基本形式)
如:is,am,are转为be
按照规律变化,减少词项数量
如:复数boys去掉s,tries变try
词干还原和词形合并从不同角度,降低词项数,可通过在索引过程中增加插件程序实现
掌握4.5.定义,区别
1.代表意义不同
stemming去掉单词两端词缀的启发式过程
利用词汇表和词形分析来减少屈折变化的形式,将其转变为基本形式
2.词干还原在一般情况下会将多个派生相关词合并在一起
词形归并通常只将同一词元的不同屈折形式进行合并
6.停用词
变为term
去掉没有意义的(停用词),对搜索引擎没有帮助的词,an,the,to
构造停用词表:语法,词频高,公开词表
缺点:有些停用词有意义
优点:减少terms,缩小范围,提高效率,用在文本分类算法
