Gradio全解11——Streaming:流式传输的视频应用(3)——YOLO系列模型技术架构与实战
Gradio全解11——Streaming:流式传输的视频应用(3)——YOLO系列模型技术架构与实战
- 11.3 YOLO系列模型技术架构与实战
- 11.3.1 YOLOv10:优化后处理和模型架构
- 1. 模型技术特点
- 2. 模型性能与子模型比较
- 3. 安装与运行Demo
- 4. 加载模型并验证、训练、预测和推送hub
- 11.3.2 YOLOE:实时高效感知任何物体
- 1. 模型技术架构
- 2. 性能表现
- 3. 安装与运行Demo
- 4. 下载与导入模型
本章目录如下:
- 《Gradio全解11——Streaming:流式传输的视频应用(1)——FastRTC:Python实时通信库》
- 《Gradio全解11——Streaming:流式传输的视频应用(2)——Twilio:网络服务提供商》
- 《Gradio全解11——Streaming:流式传输的视频应用(3)——YOLO系列模型技术架构与实战》
- 《Gradio全解11——Streaming:流式传输的视频应用(4)——基于Gradio WebRTC的实时目标检测》
- 《Gradio全解11——Streaming:流式传输的视频应用(5)——RT-DETR:实时端到端检测模型》
- 《Gradio全解10——Streaming:流式传输的视频应用(6)——基于RT-DETR模型构建视频流目标检测系统》
- 《Gradio全解11——Streaming:流式传输的视频应用(7)——多模态Gemini模型及其思考模式》
- 《Gradio全解11——Streaming:流式传输的视频应用(8)——Gemini Live API:实时音视频连接》
- 《Gradio全解11——Streaming:流式传输的视频应用(9)——使用FastRTC+Gemini创建沉浸式音频+视频的艺术评论家》
11.3 YOLO系列模型技术架构与实战
近年来,YOLO系列因其在计算成本与检测性能之间的有效平衡,已成为实时目标检测领域的主导技术。本节将介绍YOLO系列最流行的两个模型:YOLOv10和YOLOE,讲解技术架构并进行实战,方便读者了解著名的YOLO系列模型较新版本的区别和优势。
11.3.1 YOLOv10:优化后处理和模型架构
本节首先介绍YOLOv10模型的技术特点,然后介绍性能优势及子模型区别,最后进行实战,包括安装与运行Demo,下载模型并验证、训练和预测。
1. 模型技术特点
近年来,YOLO系列因其在计算成本与检测性能之间的有效平衡,已成为实时目标检测领域的主导技术。研究者们针对YOLO的架构设计、优化目标、数据增强策略等方面进行了深入探索,取得了显著进展。然而,依赖非极大值抑制(NMS)的后处理方式阻碍了YOLO的端到端部署,并对推理延迟产生负面影响。此外,YOLO各组件设计缺乏全面深入的考量,导致明显的计算冗余并限制了模型能力,使得其效率欠佳而存在较大性能提升空间。
在2024年3月提出的YOLOv10中,旨在从后处理和模型架构两方面共同推进YOLO系列的性能-效率边界,其主要改进有两个方面:
- YOLOv10首先提出用于NMS-free训练的一致性双重分配策略,在保持高性能同时显著降低推理延迟。
- 其次,引入面向YOLO效率-精度的全方位驱动模型的设计策略,从效率与精度两个维度系统优化YOLO的各个组件,大幅降低计算开销并提升模型能力。
这些技术共同构建了新一代实时端到端目标检测YOLO系列——YOLOv10。关于YOLOv10的论文和详细代码请参阅其Github:YOLOv10: Real-Time End-to-End Object Detection🖇️链接11-23。
2. 模型性能与子模型比较
大量实验表明,YOLOv10在不同模型规模下均实现了近乎最优的性能与效率表现,例如:
- 在COCO数据集的相似指标AP(Accurate Performance,精准度)下,YOLOv10-S比RT-DETR-R18快1.8倍,且参数量与FLOP减小2.8倍。
- 与YOLOv9-C相比,YOLOv10-B在同等性能下延迟降低46%,参数量减少25%。
在延迟-精度(左)和参数量-精度(右)权衡方面,YOLOv10与其他模型进行比较的结果如图11-3所示:

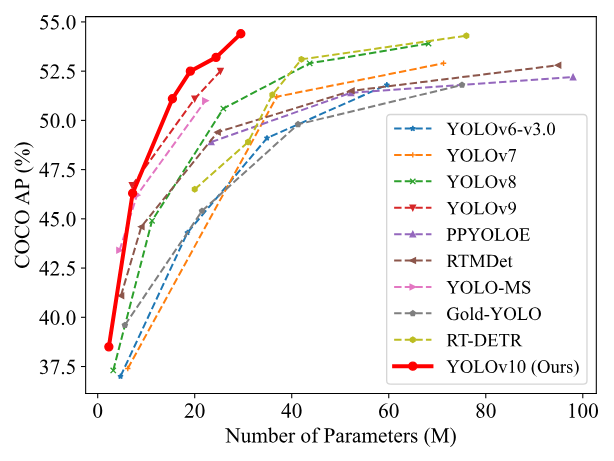
以COCO数据集为例,YOLOv10系列子模型的数据量测试大小、参数量、浮点操作数(FLOP)、精度值及延迟等的比较如表11-2所示:
| 模型 | 测试大小 | 参数量 | 浮点操作数 | 精度值 | 延迟 |
|---|---|---|---|---|---|
| YOLOv10-N | 640 | 2.3M | 6.7G | 38.5% | 1.84ms |
| YOLOv10-S | 640 | 7.2M | 21.6G | 46.3% | 2.49ms |
| YOLOv10-M | 640 | 15.4M | 59.1G | 51.1% | 4.74ms |
| YOLOv10-B | 640 | 19.1M | 92.0G | 52.5% | 5.74ms |
| YOLOv10-L | 640 | 24.4M | 120.3G | 53.2% | 7.28ms |
| YOLOv10-X | 640 | 29.5M | 160.4G | 54.4% | 10.70ms |
3. 安装与运行Demo
下面进行实操。首先安装模型并运行Demo,建议使用Coda环境:
conda create -n yolov10 python=3.9
conda activate yolov10
pip install -r requirements.txt
pip install -e .
# start demo
python app.py
# Please visit http://127.0.0.1:7860
requirements.txt中内容见Github。Demo中有演示模型使用的代码,其app.py的推理函数如下所示:
from ultralytics import YOLOv10
import tempfile
import cv2
def yolov10_inference(image, video, model_id, image_size, conf_threshold):model = YOLOv10.from_pretrained(f'jameslahm/{model_id}')if image:results = model.predict(source=image, imgsz=image_size, conf=conf_threshold)annotated_image = results[0].plot()return annotated_image[:, :, ::-1], Noneelse:video_path = tempfile.mktemp(suffix=".webm")with open(video_path, "wb") as f:with open(video, "rb") as g:f.write(g.read())cap = cv2.VideoCapture(video_path)fps = cap.get(cv2.CAP_PROP_FPS)frame_width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))frame_height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))output_video_path = tempfile.mktemp(suffix=".webm")out = cv2.VideoWriter(output_video_path, cv2.VideoWriter_fourcc(*'vp80'), fps, (frame_width, frame_height))while cap.isOpened():ret, frame = cap.read()if not ret:breakresults = model.predict(source=frame, imgsz=image_size, conf=conf_threshold)annotated_frame = results[0].plot()out.write(annotated_frame)cap.release()out.release()return None, output_video_path
其它部分代码请参照Github,建议读者仔细阅读并灵活运用。
4. 加载模型并验证、训练、预测和推送hub
安装完成后,可通过代码或命令行两种方式加载模型,如下所示:
from ultralytics import YOLOv10
model = YOLOv10.from_pretrained('jameslahm/yolov10{n/s/m/b/l/x}')
# or download from github
# wget https://github.com/THU-MIG/yolov10/releases/download/v1.1/yolov10{n/s/m/b/l/x}.pt
# model = YOLOv10('yolov10{n/s/m/b/l/x}.pt')
使用模型验证、训练、预测和推送hub的代码如下所示:
# Validation, Training and Prediction
model.val(data='coco.yaml', batch=256)
model.train(data='coco.yaml', epochs=500, batch=256, imgsz=640)
source = 'http://images.cocodataset.org/val2017/000000039769.jpg'
model.predict(source=source, save=True)
# after training, one can push to the hub
model.push_to_hub("your-hf-username/yolov10-finetuned")
11.3.2 YOLOE:实时高效感知任何物体
本节讲述YOLO系列最新模型YOLOE,首先讲解模型的技术特点及性能优势,然后介绍子模型区别并进行实战,实战包括安装并运行Demo、下载并导入模型。
1. 模型技术架构
YOLO系列的最新进展是YOLOE(ye):实时全场景视觉系统,它是一种高效、统一且开放的目标检测与分割模型,能够像人眼一样实时感知任何物体。该模型支持多种提示机制(包括文本提示、视觉输入提示以及无提示范式),且完全开源,与闭集YOLO模型相比,具有零推理和迁移开销的特性。
目标检测与分割在计算机视觉应用中广泛使用,但YOLO系列等传统模型虽高效精准,却受限于预定义类别,难以适应开放场景。现有开放集方法通过文本提示、视觉线索或无提示范式突破这一限制,却常因高计算量或部署复杂度而在性能与效率间妥协。而2025年3月提出的YOLOE,将多种开放提示机制下的检测与分割功能集成于单一高效模型中,实现实时"万物识别"。其提示机制包括:
- 针对文本提示,提出重参数化的区域-文本对齐策略(Re-parameterizable Region-Text Alignment,RepRTA),通过重参数化轻量辅助网络优化预训练文本嵌入,在零推理与迁移开销下增强视觉-文本对齐。
- 对于视觉提示,开发语义激活视觉提示编码器(Semantic-Activated Visual Prompt Encoder,SAVPE),采用解耦语义与激活分支,以极低复杂度并提升视觉嵌入质量与精度。
- 针对无提示场景,设计惰性区域-提示对比策略(Lazy Region-Prompt Contrast,LRPC),利用内置大型词表与专用嵌入识别所有对象,避免依赖高成本语言模型。YOLOE整体架构示意图如图11-4所示:
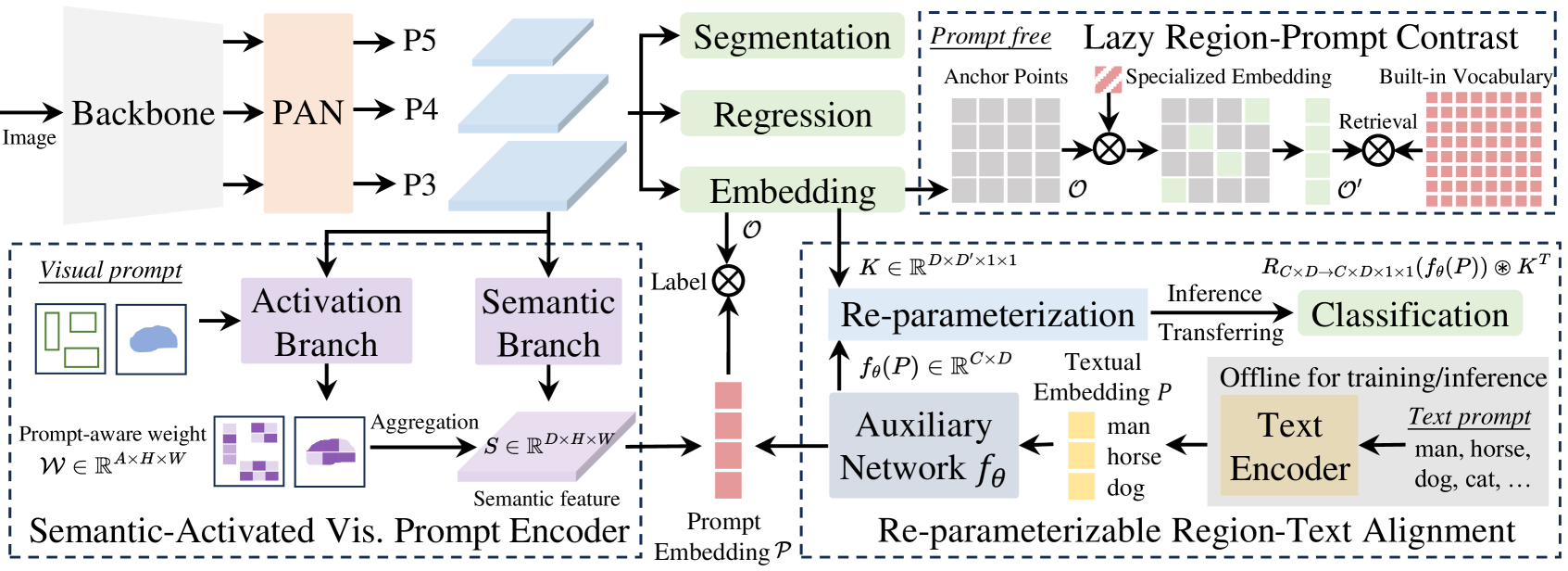
关于YOLOE的论文和实现代码请参阅YOLOE Github: Real-Time Seeing Anything🖇️链接11-24。
2. 性能表现
大量实验表明YOLOE在零样本性能与迁移性方面表现卓越,同时具备高推理效率与低训练成本。值得注意的是,在LVIS数据集上,YOLOE-v8-S以更低的3倍训练成本和1.4倍推理速度超越YOLO-Worldv2-S达3.5精度。迁移至COCO时,YOLOE-v8-L相比闭集YOLOv8-L亦有提升,且训练时间减少近4倍。
YOLOE的性能表现可以从零样本检测评估(Zero-shot detection evaluation)、零样本分割评价(Zero-shot segmentation evaluation)、无提示评价(Prompt-free evaluation)、COCO下行迁移(Downstream transfer on COCO)等方面衡量。以零样本检测评估为例,说明如下:
- 在LVIS minival数据集上报告固定AP精度值(基于文本提示(T)/视觉提示(V))。
- 针对文本提示的检测任务测得训练时间(基于8块NVIDIA RTX4090 GPU)。
- FPS指标分别在T4(TensorRT)和iPhone 12(CoreML)平台测得。
- 训练数据中,使用Objects365v1与GoldG的组合OG,数据量测试大小为640。
- 预训练完成后,YOLOE-v8/YOLOE-11可通过重参数化转为与YOLOv8/YOLO11完全相同的架构,且实现零迁移开销。零样本检测评估测试的数据统计如表11-3所示:
| 模型 | 提示类别 | 调用参数量 | 时长 | FPS | 精度值 |
|---|---|---|---|---|---|
| YOLOE-v8-S | T / V | 12M / 13M | 12.0h | 305.8 / 64.3 | 27.9 / 26.2 |
| YOLOE-v8-M | T / V | 27M / 30M | 17.0h | 156.7 / 41.7 | 32.6 / 31.0 |
| YOLOE-v8-L | T / V | 45M / 50M | 22.5h | 102.5 / 27.2 | 35.9 / 34.2 |
| YOLOE-11-S | T / V | 10M / 12M | 13.0h | 301.2 / 73.3 | 27.5 / 26.3 |
| YOLOE-11-M | T / V | 21M / 27M | 18.5h | 168.3 / 39.2 | 33.0 / 31.4 |
| YOLOE-11-L | T / V | 26M / 32M | 23.5h | 130.5 / 35.1 | 35.2 / 33.7 |
3. 安装与运行Demo
下面进行实操。首先安装模型并运行Demo,建议使用Coda环境。可以通过requirements.txt安装,或直接安装代码库自带的第三方库,命令如下所示:
conda create -n yoloe python=3.10 -y
conda activate yoloe
# If you clone this repo, please use this
git clone https://github.com/THU-MIG/yoloe.git
cd yoloe
pip install -r requirements.txt
# Or you can also directly install the repo by this
pip install git+https://github.com/THU-MIG/yoloe.git#subdirectory=third_party/CLIP
pip install git+https://github.com/THU-MIG/yoloe.git#subdirectory=third_party/ml-mobileclip
pip install git+https://github.com/THU-MIG/yoloe.git#subdirectory=third_party/lvis-api
pip install git+https://github.com/THU-MIG/yoloe.git
wget https://docs-assets.developer.apple.com/ml-research/datasets/mobileclip/mobileclip_blt.pt
也可以从PyPI安装,然后运行Demo,命令如下所示:
# Optional for mirror: export HF_ENDPOINT=https://hf-mirror.com
pip install gradio==4.42.0 gradio_image_prompter==0.1.0 fastapi==0.112.2 huggingface-hub==0.26.3 gradio_client==1.3.0 pydantic==2.10.6
python app.py
# Please visit http://127.0.0.1:7860
限于篇幅,这里不再展示app.py中的推理函数,感兴趣读者可参考YOLOE Github。
4. 下载与导入模型
下载预训练模型,命令如下所示:
# Download pretrained models
# Optional for mirror: export HF_ENDPOINT=https://hf-mirror.com
# Please replace the pt file with your desired model
pip install huggingface-hub==0.26.3
huggingface-cli download jameslahm/yoloe yoloe-v8l-seg.pt --local-dir pretrain
导入模型的代码如下所示:
from ultralytics import YOLOE
model = YOLOE.from_pretrained("jameslahm/yoloe-v8l-seg")
或者在代码中直接初始化模型:
from huggingface_hub import hf_hub_download
from ultralytics import YOLOE
def init_model(model_id, is_pf=False):filename = f"{model_id}-seg.pt" if not is_pf else f"{model_id}-seg-pf.pt"path = hf_hub_download(repo_id="jameslahm/yoloe", filename=filename)model = YOLOE(path)model.eval() # 将模型切换至评估模式,停止参数更新model.to("cuda" if torch.cuda.is_available() else "cpu")return model
model = init_model("yoloe-v8l")
其他操作如验证、训练、预测和推送hub等,可参考YOLOv10中的操作。