初学Transformer核心——注意力机制
基础认知
Transformer是什么?为什么Transformer能成为目前最好的模型?
主要用于处理序列数据,是NLP中最常用架构之一。它替代了RNN及LSTM,并以此为基础衍生出诸如BERT、GPT、DeepSeek、LLaMA等几乎所有现代大语言模型。
Transformer不使用卷积和循环网络,是一个完全基于自注意力机制的模型。但为什么能有如今这个地位?原因就在自注意力机制。自注意力机制,Transformer的核心是自注意力机制,它允许模型在处理某个位置的输入时,能够直接与其他位置的输入交互,而不像CNN、RNN只能顺序处理数据。自注意力机制通过计算输入序列中各位置之间的相似度来决定各位置之间的影响力,大白话来讲,自注意力机制能得到每个句子中每个词之间的关系度,能得到谁和他关系近。从而提高了模型的表现力。
自注意力机制
出现背景
自注意力机制(Self-Attention Mechanism )的产生与序列建模任务(如机器翻译、文本生成等)中的挑战密切相关,比如RNN、LSTM等在处理长序列时有梯度消失(或爆炸)、计算效率低、难以并行化等诸多局限性。
实现过程
句子“我在学习人工智能”
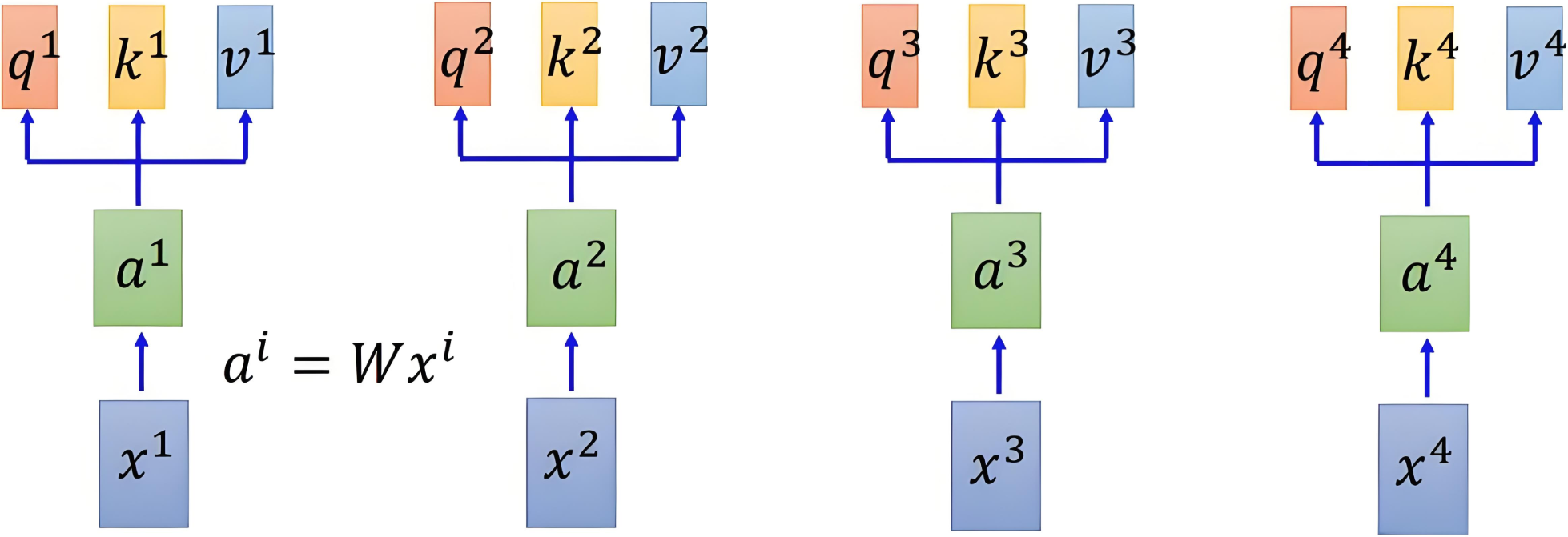
线性变换
同样的自注意力机制需要使用提取到的词嵌入向量,但不同的是自注意力机制中用到的每个词语有对应的三个不同的词向量,也就是引入查询向量(Query)、键向量(Key)、值向量(Value)概念来实现序列中各元素之间的信息交互和依赖建模。三个向量都通过初始的词嵌入向量乘以对应的可学习权重矩阵,维度为
,
是超参数,表示向量的维度。(d默认为512)
通过线性变换得到三个向量的变化如下图所示:
注意力得分
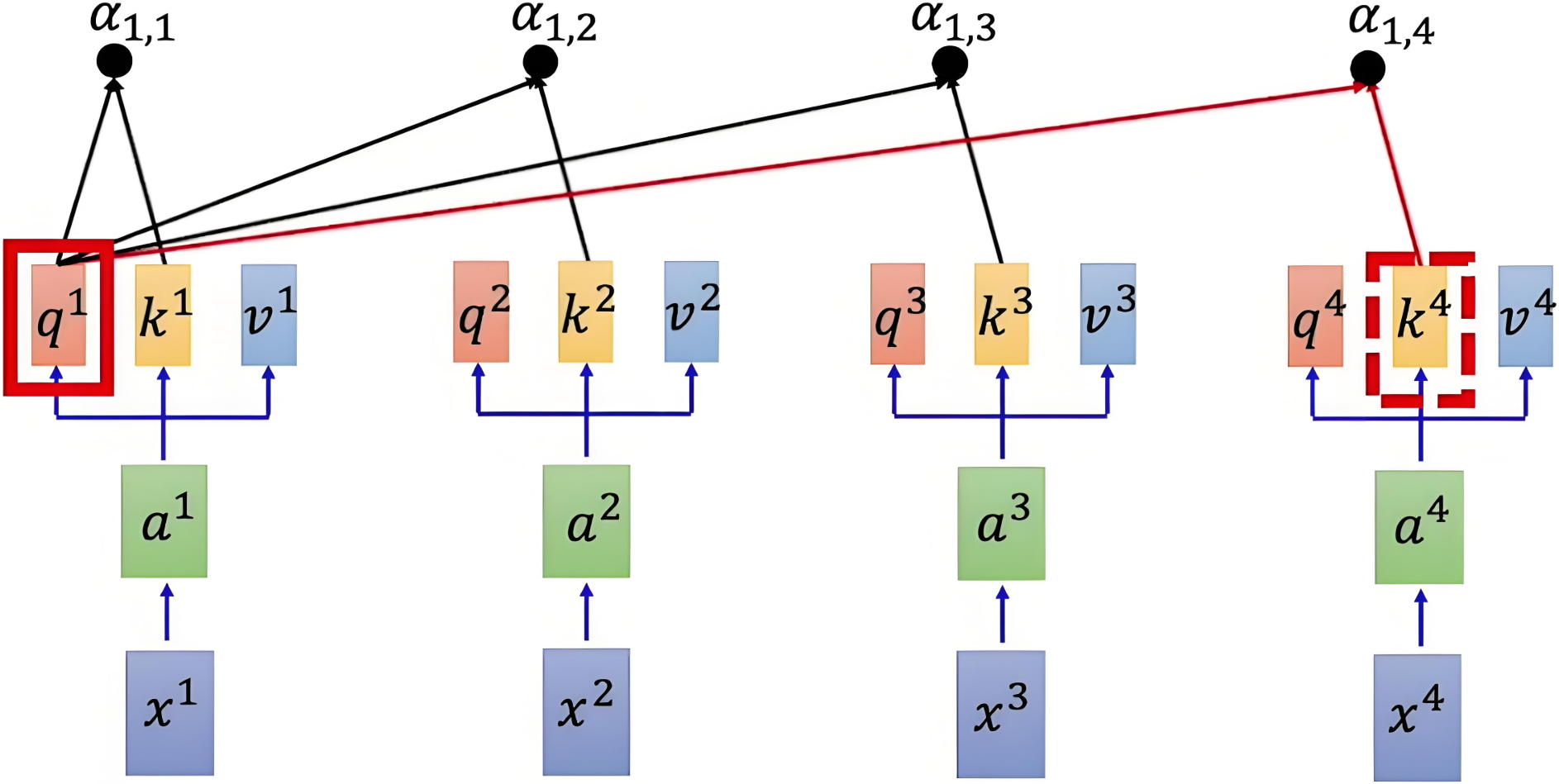
注意力得分也就是代表每个词对于这个词的相似度,使用点积来计算查询向量和键向量之间的相似度,除以缩放因子 来避免数值过大,使得梯度稳定更新。得到注意力得分矩阵:
注意力得分矩阵维度是 n*n的,其中 n 是序列的长度(词数量)。每个元素 (i, j) 表示第 i 个元素与第 j 个元素之间的相似度。
白话:求得对应词语注意力得分矩阵就是对应的Q向量与句子中的每个词的K向量进行上述计算得到的。
注意力得分矩阵就比如我,在,学习,人工智能。这句话n为4,行列都可理解标签为我,在,学习,人工智能每个词表示一行或者一列(实际中每个词对应词表,这里这是好理解)。第一行就表示了这4个词对于“我”这个词的相似度,第二行表示对于“在”这个词的相识度.......。
参考示意图如下:
归一化为了将注意力得分转换为概率分布,需按行对得分矩阵进行 softmax 操作,确保每行的和为 1,得到的矩阵表示每个元素对其他元素的注意力权重。是的,包括自己。
加权求和
通过将注意力权重矩阵与值矩阵 V 相乘,得到加权的值表示。
具体计算示意图如下:
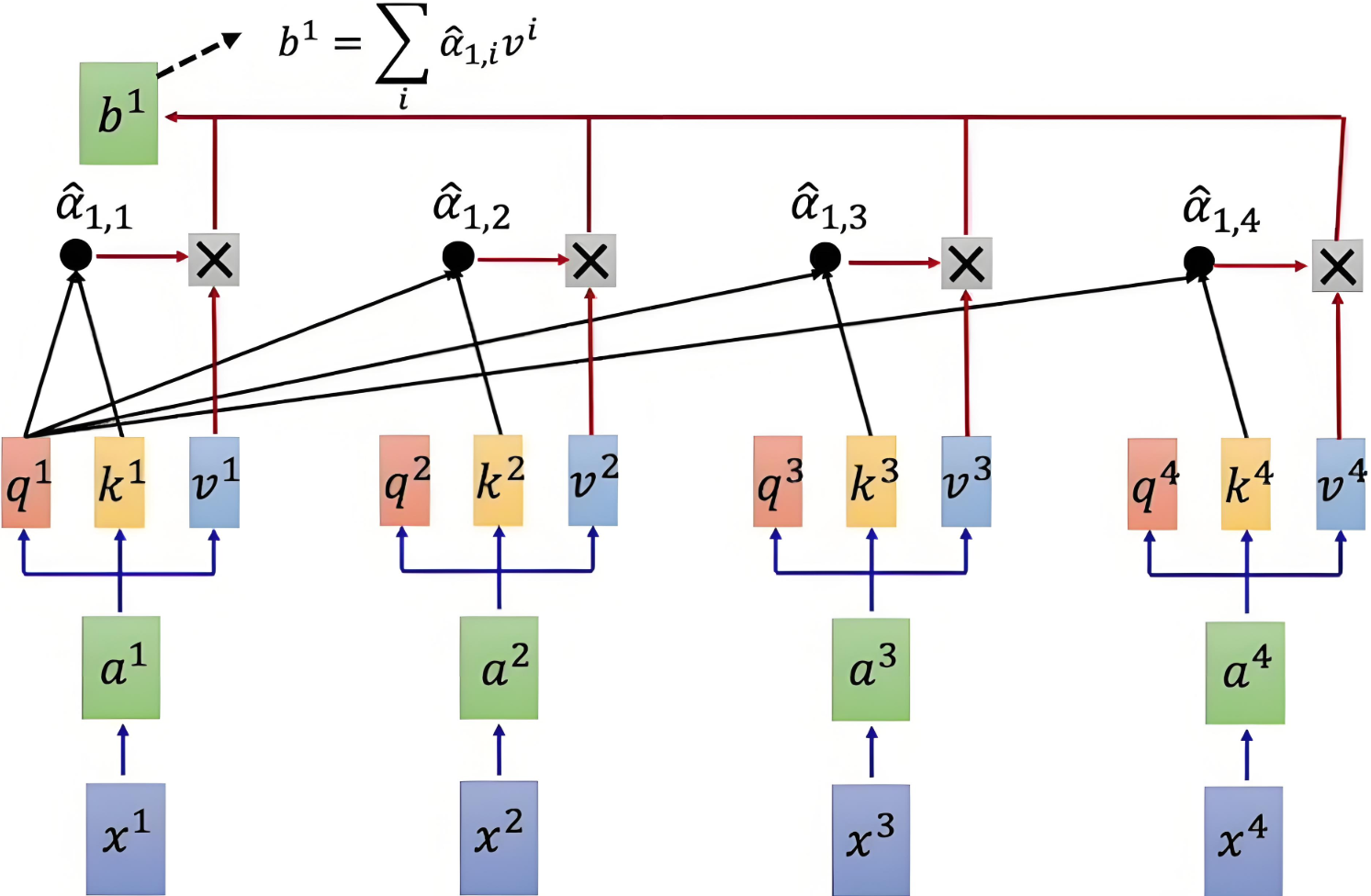
Q和K计算相似度后,经 softmax 得到注意力,再乘V,最后相加得到包含注意力的输出
注:通过上下文来描述每一个词
本质:将Query和Key分别计算相似性,然后经过softmax得到相似性概率权重即注意力,再乘以Value,最后相加即可得到包含注意力的输出
至此,艺术已成,"我"就是"我","我"不再是"我"。
多头注意力机制
Multi-Head Attention,多头注意力机制,是对自注意力机制的扩展。
概念和作用
多头注意力机制的核心思想是,将注意力机制中的 Q、K、V 分成多个头(组),每个头计算出独立的注意力结果,然后将所有头的输出拼接起来,最后通过一个线性变换得到最终的输出(分组的思想)。 比如一个词有512维 那么可以把它分为n个组,然后每个组分别有三个w向量映射为qkv,那么qkv的结果就会得到有n组。
这样进行变化的主要目的就是可以得到各个方面的注意力,如语义方面,词性方面等等。
下面以2个头为例:
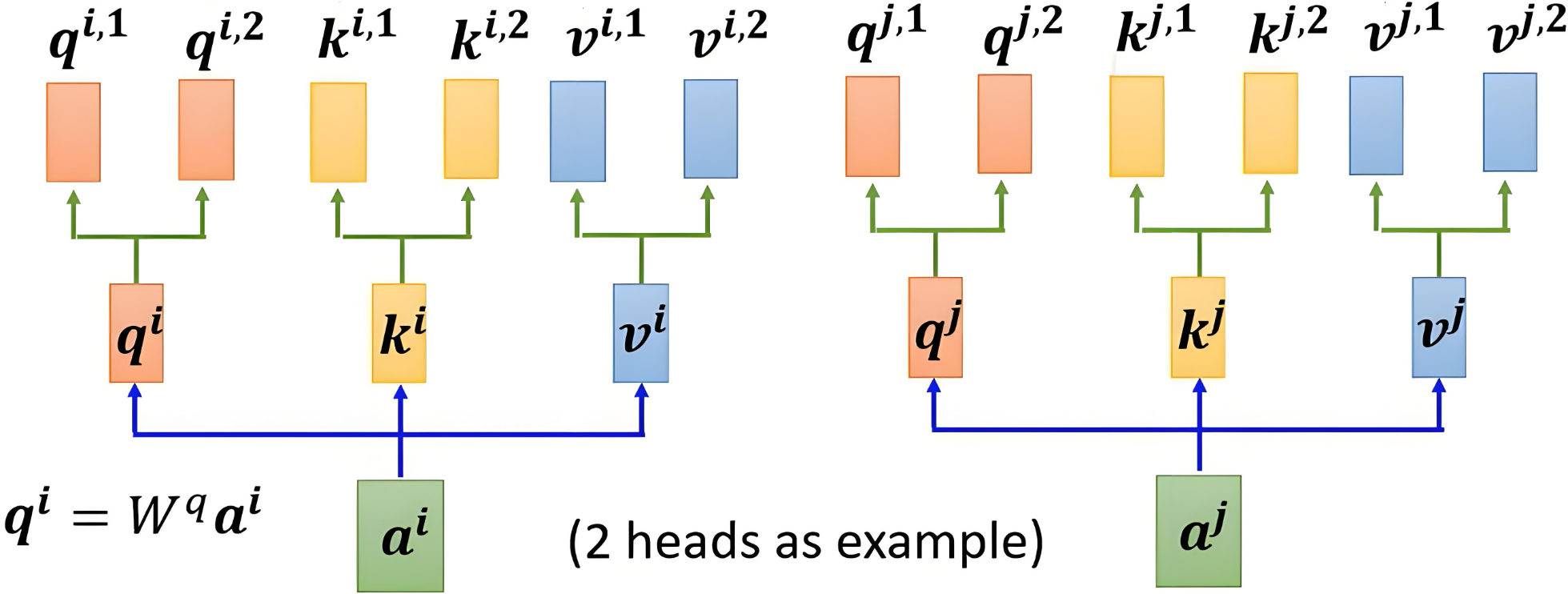
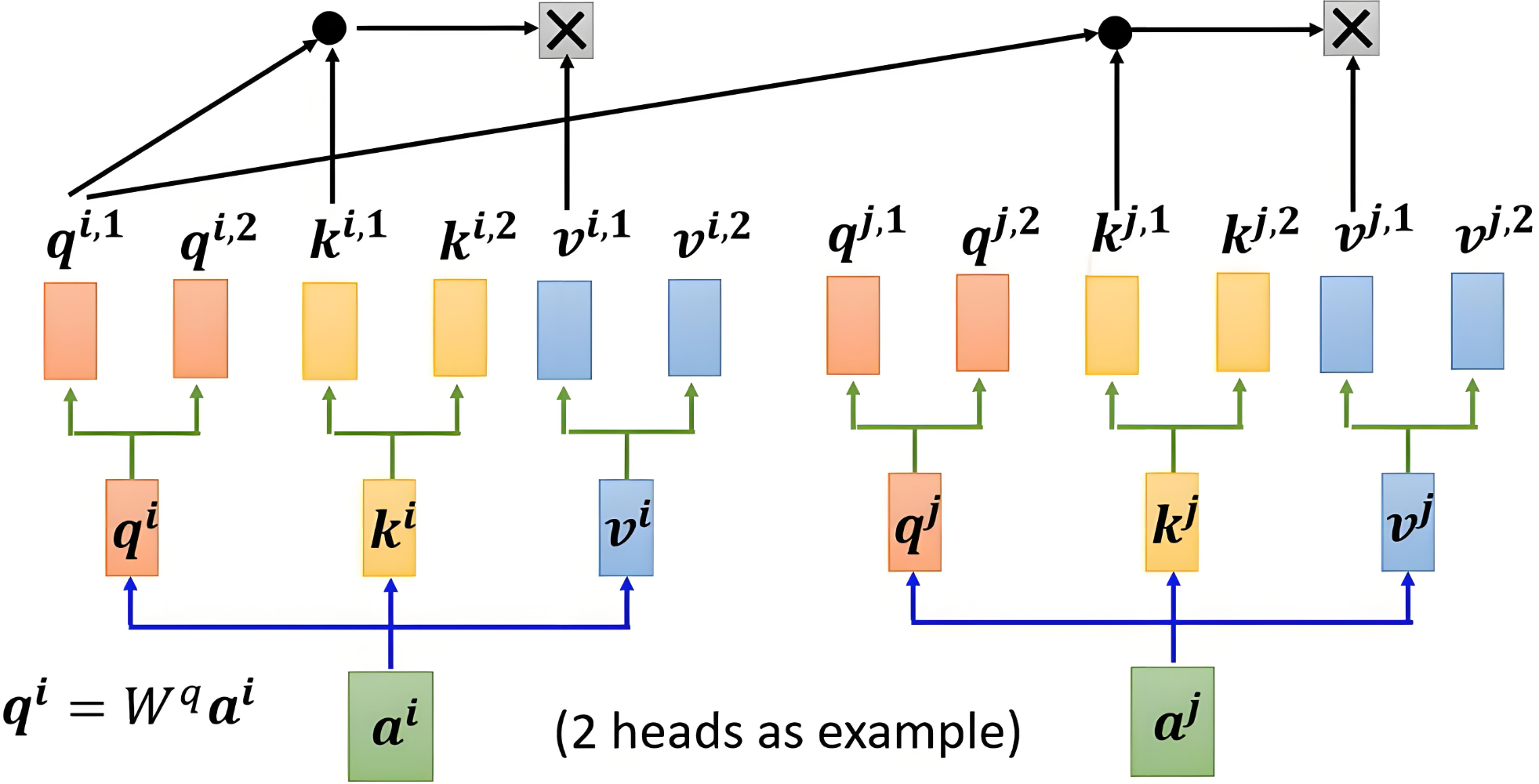
一个词本来是1维 就一个token id 一个数字 但是我们把它映射为了512维 也就是从512个方面(特征)来看待这个词:情感,词法,过去式,将来式,进行时,偏旁部首,名次,动词等等等我们都想不出来的一些方面
因为是n组注意力
比如第一组是512维中的64个 这64个可以表示从情感的特征
比如第二组是512维中的另外64个 这64个可以表示从词法上的特征
比如第x组......
通过多个并行的头在不同的子空间中学习上下文信息,让同一个句子在不同场景下表达不同的意思,增强模型的表达能力和灵活性。
机制实现
import torch
import torch.nn as nn# ======================
# 1. 词嵌入层 (Embedding)
# ======================
# 创建词嵌入层:假设10个单词,每个单词映射为512维向量
vocab_size = 10 # 词汇表大小
embed_dim = 512 # 嵌入维度
embedding = nn.Embedding(vocab_size, embed_dim)# 生成随机输入:序列长度为512的token索引
input_seq = torch.randint(0, vocab_size, (512,), dtype=torch.long)# 通过嵌入层:将索引转换为向量
# 输出形状: (序列长度, 嵌入维度) = (512, 512)
embedding_out = embedding(input_seq)
print("嵌入层输出形状:", embedding_out.shape) # torch.Size([512, 512]) 有512个单词,每个单词映射为512维向量# ==============================
# 2. 多头注意力权重矩阵初始化
# ==============================
num_heads = 8 # 注意力头数量
head_dim = embed_dim // num_heads # 每个头的维度 512/8=64# 初始化Q、K、V的投影矩阵 (标准Transformer实现方式)
# 注意:使用单个大矩阵而不是多个小矩阵
W_Q = torch.randn(embed_dim, embed_dim) # (512, 512)
W_K = torch.randn(embed_dim, embed_dim) # (512, 512)
W_V = torch.randn(embed_dim, embed_dim) # (512, 512)# =====================================
# 3. 计算Query, Key, Value (正确实现)
# =====================================
# 一次性计算所有头的投影
all_queries = torch.matmul(embedding_out, W_Q) # (512,512) × (512,512) = (512,512)
all_keys = torch.matmul(embedding_out, W_K) # (512,512)
all_values = torch.matmul(embedding_out, W_V) # (512,512)# 将投影结果分割成多个头
# 步骤:
# 1. 重塑形状: (seq_len, num_heads, head_dim)
# 2. 调整维度顺序: (num_heads, seq_len, head_dim)
queries = all_queries.view(512, num_heads, head_dim).permute(1, 0, 2)
keys = all_keys.view(512, num_heads, head_dim).permute(1, 0, 2)
values = all_values.view(512, num_heads, head_dim).permute(1, 0, 2)print("Queries形状:", queries.shape) # torch.Size([8, 512, 64])
print("Keys形状:", keys.shape) # torch.Size([8, 512, 64])
print("Values形状:", values.shape) # torch.Size([8, 512, 64])# ==============================
# 4. 计算注意力分数 (Scaled Dot-Product)
# ==============================
# 计算Q和K的点积 (每个头独立计算)
# 矩阵乘法: (8,512,64) × (8,64,512) = (8,512,512)
attention_scores = torch.matmul(queries, keys.permute(0, 2, 1))# 缩放因子 (sqrt(d_k))
scale_factor = torch.sqrt(torch.tensor(head_dim, dtype=torch.float))
attention_scores = attention_scores / scale_factor# 应用softmax得到注意力权重
attention_weights = torch.softmax(attention_scores, dim=-1)
print("注意力权重形状:", attention_weights.shape) # torch.Size([8, 512, 512])# ==============================
# 5. 计算注意力输出
# ==============================
# 注意力权重与Value相乘
# (8,512,512) × (8,512,64) = (8,512,64)
attention_output = torch.matmul(attention_weights, values)# ==============================
# 6. 合并多头输出
# ==============================
# 步骤:
# 1. 调整维度顺序: (num_heads, seq_len, head_dim) -> (seq_len, num_heads, head_dim)
# 2. 重塑形状: (seq_len, embed_dim)
attention_output = attention_output.permute(1, 0, 2).contiguous() # (512, 8, 64)
combined_output = attention_output.view(512, embed_dim) # (512, 512)
print("合并后的注意力输出形状:", combined_output.shape) # torch.Size([512, 512])官方用法
# ===========================================
# 7. 使用PyTorch内置多头注意力层
# ===========================================
# 实际开发中推荐使用内置实现
multihead_attn = nn.MultiheadAttention(embed_dim, num_heads)
# 传入qkv
attn_output, attn_weights = multihead_attn(embedding_out, # (512,1,512)embedding_out, # (512,1,512)embedding_out # (512,1,512)
)
print("内置多头注意力输出形状:", attn_output.shape) # torch.Size([512,512])
print("内置多头注意力权重形状:", attn_weights.shape) # torch.Size([512,512])