[论文阅读] 人工智能 + 软件工程 | 大模型破局跨平台测试!LLMRR让iOS/安卓/鸿蒙脚本无缝迁移
大模型破局跨平台测试!LLMRR让iOS/安卓/鸿蒙脚本无缝迁移
论文信息
- 论文原标题:基于大模型语义匹配的跨平台移动应用测试脚本录制回放
- 主要作者及研究机构:
虞圣呈1,2、房春荣1,2(通信作者)、钟葉1,2等;- 计算机软件新技术全国重点实验室(南京大学),江苏南京;
- 南京大学软件学院,江苏南京
- APA引文格式:
Yu, S. C., Fang, C. R., Zhong, Y., Zhang, Q. J., Liu, Q., Liu, J., Zheng, T., & Chen, Z. Y. (2025). Semantic Matching-based Cross-platform Mobile App Test Script Record and Replay via Large Language Models. Ruan Jian Xue Bao/Journal of Software (in Chinese). https://www.jos.org.cn/1000-9825/7414.htm - 基金项目:国家自然科学基金(62272220, 62372228);中央高校基本科研业务费专项资金(14380029)
- 开源地址:代码与数据已开源至GitLink:https://gitlink.org.cn/yusc/LLMRR
一段话总结
为解决移动应用跨平台GUI测试中“多对多”事件映射(如鸿蒙无广告步骤、iOS需关广告)和脚本迁移难题(尤其鸿蒙与iOS/安卓底层差异),本文提出LLMRR方法——录制阶段用图像分割记录操作信息(截图、坐标等),回放阶段先通过“模板匹配+SIFT+VGG16图标分类”做图像匹配,再用“OCR+Sentence Transformers”做文本匹配,两者均失败时调用GPT-4o大模型判断“录制冗余”(跳过步骤)或“回放冗余”(补充操作);通过20个应用100个脚本在iOS/安卓/鸿蒙间的测试,LLMRR回放成功率最高达68%(安卓→iOS),鸿蒙相关迁移成功率56%-65%,远超LIRAT(1%-11%)、MAPIT(1%-7%)等传统方法,为国产鸿蒙生态测试提供关键技术支撑。
思维导图
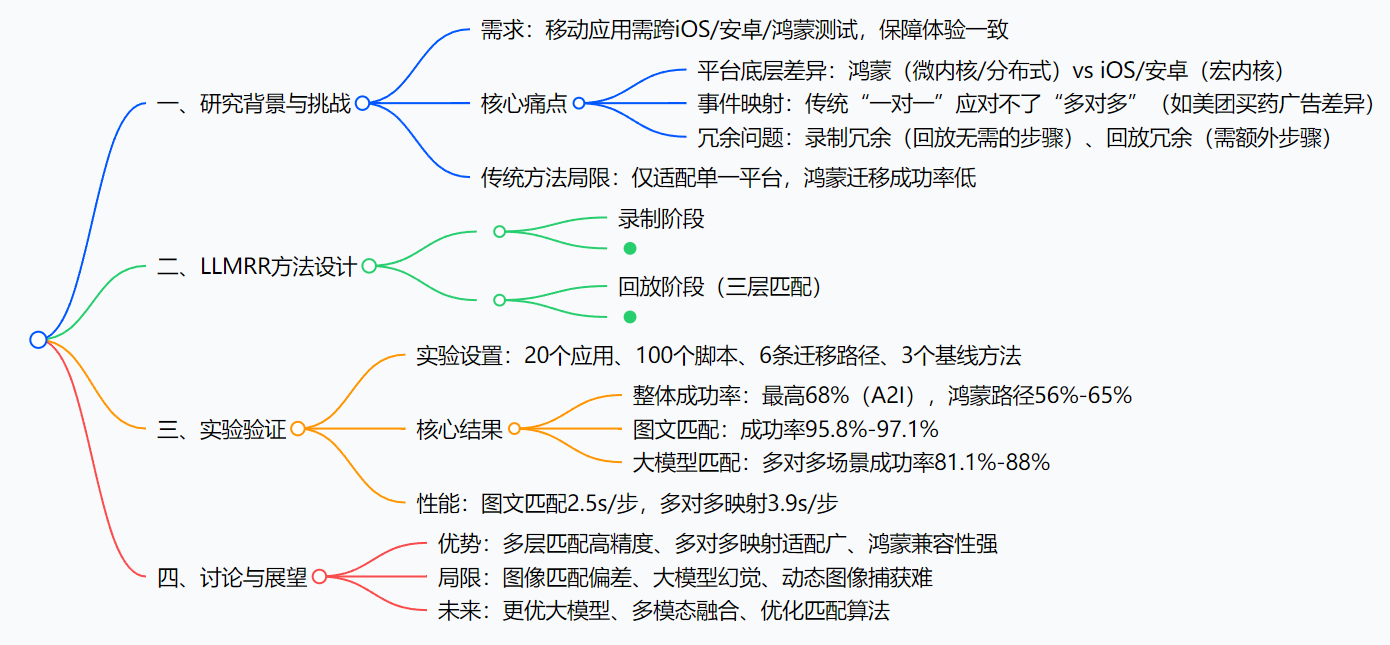
研究背景:跨平台测试的“老大难”问题
现在手机系统不止iOS和安卓了,国产鸿蒙系统起来了——2023年已经成了第三大手机OS,很多App要同时做iOS、安卓、鸿蒙三个版本。但做测试的时候,麻烦就来了:同一个功能,在不同系统上的操作步骤可能完全不一样,传统测试脚本根本没法复用。
举个最直观的例子(论文里的“美团买药”案例):在鸿蒙手机上点“美团买药”,直接就能进买药界面;但在iOS上点同一个按钮,会先弹个广告,得手动关了才能进——这就导致“鸿蒙录的脚本,iOS没法用”,因为步骤对不上。这种“一个功能对应不同步骤”的情况,就是论文说的“多对多”事件映射,传统方法只能处理“一步对一步”的简单场景,遇到这种情况就歇菜了。
还有两个常见坑:
- 录制冗余:比如第一次打开App会弹“新手引导”,录制脚本时得关了才能操作,但回放时App不会再弹,这时候脚本里的“关引导”步骤就成了多余的,传统脚本会卡在这一步;
- 回放冗余:比如安卓上“同意条款”只需要点一下,但iOS上条款分两页,得先点“下一页”再点“同意”,回放时脚本里没有“下一页”步骤,就会失败。
这些问题的根源,其实是不同系统的“底层差异”:鸿蒙是微内核,能适配手机、手表、电视各种设备;iOS和安卓是宏内核,功能固定。底层不一样,GUI控件的定位方式、页面结构也不一样——就像不同国家的插座,插头形状不同,传统“单接口转换器”(传统测试脚本)根本用不了,我们需要一个“万能转换器”,这就是LLMRR要解决的问题。
创新点:LLMRR的“三板斧”
和传统跨平台测试工具比,LLMRR的创新点主要在三个地方,正好对应解决上面的痛点:
1. 首次搞定“多对多”事件映射
传统方法要么只处理“一对一”,要么靠人工改脚本;LLMRR直接让大模型(GPT-4o)当“测试工程师”,通过理解业务逻辑判断“哪些步骤多余”“哪些步骤要补充”——比如看到iOS弹广告,就知道要加“关广告”步骤;看到鸿蒙没有新手引导,就知道要跳过“关引导”步骤。
2. “图文+大模型”的多层匹配机制
不依赖单一技术,而是像“过滤漏斗”一样层层递进:
- 先靠图像匹配(SIFT算法+VGG16图标分类)找控件——比如“搜索”按钮不管是蓝色还是灰色,都能通过图标形状或类型认出来;
- 图像找不到,再用文本匹配(OCR+语义理解)——比如“提交”和“完成”字面不一样,但语义相同,能匹配上;
- 最后才调用大模型,既保证效率(图文匹配快),又覆盖复杂场景(大模型处理多对多)。
3. 专门适配国产鸿蒙生态
之前的测试工具基本忽略鸿蒙,LLMRR专门针对鸿蒙的分布式架构做了优化——实验里鸿蒙和其他平台的迁移成功率最低56%,而传统工具最高才18%,相当于给鸿蒙App测试开了“绿色通道”。
研究方法:LLMRR是怎么工作的?
把LLMRR拆成“录制”和“回放”两步,就能轻松理解:
第一步:录制阶段——记全操作细节
就像用手机录屏,但比录屏更细致:
- 你在手机上操作App(比如点“美团买药”、选“感冒发烧”),系统会实时截图当前页面;
- 用Canny图像分割算法,把页面里的按钮、输入框这些“控件”拆出来,单独保存控件截图;
- 同时记录下“操作坐标”(点了屏幕哪个位置)和“动作类型”(是点击还是输入文字);
- 把这些信息(页面截图、控件截图、坐标、动作)打包成“测试脚本”,存起来备用。
第二步:回放阶段——三层匹配,不行就找大模型
回放就是让系统在目标手机(比如用鸿蒙录的脚本,在iOS上回放)自动复现操作,核心是“找到对应控件”,分三层做:
第一层:图像匹配——先看“长得像不像”
- 模板匹配:简单对比两张图的相似度,比如一模一样的“关闭”按钮,快速定位(但分辨率不一样时不准,只当辅助);
- SIFT算法:这是核心——不管屏幕放大缩小、旋转,都能认出相同的控件(比如“搜索”图标,不管在iOS还是安卓,形状特征不变,SIFT能抓住);
- VGG16图标分类:有些图标长得不一样但功能相同(比如鸿蒙的“返回”是箭头,iOS的是“<”),用预训练的VGG16模型给图标分类(论文分了14类,比如“返回”“关闭”“搜索”),靠“功能类型”匹配,而不是“长相”。
第二层:文本匹配——再看“文字意思对不对”
如果图像没找到,就看控件上的文字:
- 先用OCR技术把页面里的文字提取出来(比如“同意条款”“下一页”),并记录文字在屏幕上的位置;
- 如果文字完全一样(比如都是“同意”),直接匹配;如果文字不一样但意思相同(比如“分享新鲜事”和“分享一下你的新鲜事吧”),就用Sentence Transformers模型做语义匹配——这个模型能理解文字的深层意思,支持13种语言,不怕措辞差异。
第三层:大模型匹配——实在找不到,让AI出主意
如果图文都没匹配到,就轮到GPT-4o出场了:
- 把“录制的步骤”(比如“鸿蒙上点美团买药直接进界面”)和“当前回放页面”(比如“iOS上弹了广告”)的信息传给大模型;
- 大模型根据提示词判断:是“录制冗余”(比如鸿蒙没广告,脚本里没关广告步骤,iOS需要补充),还是“回放冗余”(比如iOS录的关广告步骤,鸿蒙不需要,得跳过);
- 大模型输出结果:如果是录制冗余,输出“-1 -1”(表示跳过当前步骤);如果是回放冗余,输出要点击的控件坐标(比如广告的“关闭”按钮位置);
- 系统根据这个结果继续回放,确保流程不中断。
主要成果:LLMRR到底有多厉害?
论文用实验说话,结果很直观——LLMRR在所有场景下都碾压传统工具,尤其在鸿蒙测试上优势明显。
核心实验结果(表格总结)
| 研究问题(RQ) | 对比维度 | LLMRR表现 | 传统方法(LIRAT/MAPIT/AppTestMigrator)表现 | 结论 |
|---|---|---|---|---|
| RQ1:整体效果 | 回放成功率 | 最高68%(A2I),鸿蒙路径56%-65% | 最高19%(AppTestMigrator),最低1%(MAPIT) | LLMRR整体优势显著 |
| RQ2:图文匹配 | 一对一场景成功率 | 95.8%-97.1% | 85.3%-94.2% | 图文匹配精度高 |
| RQ3:大模型匹配 | 多对多场景成功率 | 81.1%-88% | 0%-19.7% | 大模型是多对多关键 |
关键价值:解决了两个实际问题
- 减少重复劳动:以前要给iOS、安卓、鸿蒙各写一套脚本,现在录一套就能用,测试效率翻三倍;
- 支撑鸿蒙生态:鸿蒙App测试终于有了靠谱的跨平台工具,成功率从1%-18%提升到56%-65%,帮开发者快速验证鸿蒙版本的功能。
开源资源
- 代码和实验数据已开源:https://gitlink.org.cn/yusc/LLMRR ——可以直接下载复现实验,或基于这个项目做二次开发。
关键问题:LLMRR的核心答案
1. LLMRR怎么解决“多对多”事件映射?
靠大模型的语义理解:先通过图文匹配过滤简单的“一对一”场景,遇到步骤不匹配时,让GPT-4o分析“录制步骤”和“回放页面”的业务逻辑,判断是该跳过步骤(录制冗余)还是补充步骤(回放冗余),直接生成操作建议,不用人工改脚本。
2. 为什么LLMRR在鸿蒙测试上表现好?
因为它没硬套iOS/安卓的测试逻辑,而是针对鸿蒙的特点做了适配:
- 图像匹配用VGG16识别鸿蒙特有的图标(比如分布式设备切换图标);
- 大模型能理解鸿蒙的“无广告”“一步直达”等流程差异,不会因为鸿蒙和iOS的步骤不同就卡住;
- 实验中鸿蒙相关迁移成功率56%-65%,是传统工具的3-5倍。
3. 大模型“幻觉”(生成错误建议)怎么处理?
论文里用了两个办法控制:
- 把GPT-4o的temperature设为0,让输出结果固定,减少随机错误;
- 设计结构化提示词(比如先告诉模型“你是软件测试工程师”,再给具体案例),明确任务边界,避免模型“瞎猜”;
未来还可以用“领域微调”(用鸿蒙测试数据训练模型)进一步减少幻觉。
4. LLMRR的效率怎么样?会不会很慢?
不慢,甚至比传统工具快:
- 图文匹配平均2.5秒/步,比LIRAT(4.3秒/步)、MAPIT(5.6秒/步)快很多;
- 就算调用大模型处理多对多场景,平均也只要3.9秒/步,测试一个脚本(平均14步)也就1分钟左右,完全能满足实际测试需求。
总结
LLMRR本质是一个“跨平台测试的万能转换器”——通过“图像+文本+大模型”的三层匹配,解决了传统工具搞不定的“多对多”事件映射和鸿蒙适配难题。实验证明,它的回放成功率最高能到68%,鸿蒙相关测试也能稳定在56%以上,比传统工具强太多。
当然它也有缺点:比如模糊图片会导致匹配不准,大模型偶尔会“说胡话”(幻觉),但这些问题未来都能通过优化算法和模型解决。对做App测试的人来说,这个方法不仅能省掉重复写脚本的时间,还能帮鸿蒙App快速落地,算是个“又实用又有技术含量”的方案。