LangChain: Evaluation(评估)
评估是LangChain框架中至关重要的一环,它帮助开发者衡量和提升基于LLM的应用程序的质量和效果。
核心概念
在LangChain中,评估主要关注以下几个方面:
- 质量评估:衡量模型输出的准确性、相关性和有用性
- 一致性评估:确保相同输入产生一致的输出
- 毒性/偏见检测:识别有害或带有偏见的内容
评估方法分类
1. 基于字符串的评估
from langchain.evaluation import ExactMatchStringEvaluatorevaluator = ExactMatchStringEvaluator()
result = evaluator.evaluate_strings(prediction="Paris",reference="Paris"
)
print(result) # {'score': 1}
2. 基于嵌入的评估
from langchain.evaluation import EmbeddingDistanceEvaluatorevaluator = EmbeddingDistanceEvaluator()
result = evaluator.evaluate_strings(prediction="The capital of France is Paris",reference="Paris is France's capital city"
)
print(result) # {'score': 0.92} - 余弦相似度得分3. 使用LLM进行评估
from langchain.evaluation import CriteriaEvalChain
from langchain_openai import ChatOpenAIllm = ChatOpenAI(model="gpt-4", temperature=0)
eval_chain = CriteriaEvalChain.from_llm(llm=llm,criteria="conciseness" # 也可以自定义标准
)question = "What is the capital of France?"
prediction = "Paris is the capital and largest city of France."
reference = "Paris"result = eval_chain.evaluate_strings(prediction=prediction,reference=reference,input=question
)
print(result)完整评估流程示例
from langchain.evaluation import EvaluatorType
from langchain.evaluation import load_evaluator
from langchain_openai import OpenAI# 初始化模型
llm = OpenAI(temperature=0)# 1. 加载评估器
evaluator = load_evaluator(EvaluatorType.QA, llm=llm)# 2. 定义测试数据
questions = [{"question": "What is the capital of France?","answer": "Paris"},{"question": "Who wrote 'Romeo and Juliet'?","answer": "William Shakespeare"}
]# 3. 生成预测
predictions = []
for qa in questions:prompt = f"Q: {qa['question']}\nA:"prediction = llm.generate([prompt])predictions.append(prediction.generations[0][0].text.strip())# 4. 进行评估
results = []
for i, qa in enumerate(questions):result = evaluator.evaluate(predictions[i],qa["answer"],input=qa["question"])results.append(result)# 5. 分析结果
accuracy = sum(1 for r in results if r['score'] > 0) / len(results)
print(f"Accuracy: {accuracy:.2%}")
这段代码展示了如何使用 LangChain 的评估工具对问答系统进行自动化评估。以下是详细解释:
代码功能图解
代码逐行解析
1. 导入模块
from langchain.evaluation import EvaluatorType, load_evaluator
from langchain_openai import OpenAIEvaluatorType:评估类型枚举(如QA、文本摘要等)load_evaluator:加载评估器的工厂函数OpenAI:LangChain封装的OpenAI模型接口
2. 初始化语言模型
llm = OpenAI(temperature=0)- 使用OpenAI模型
temperature=0:确保输出确定性(相同输入→相同输出)- 适合评估场景(减少随机性)
3. 加载QA评估器
evaluator = load_evaluator(EvaluatorType.QA, llm=llm)EvaluatorType.QA:指定问答评估类型llm=llm:使用同一个模型进行评估- 创建了一个能判断答案正确性的评估器
4. 准备测试数据
questions = [{"question": "What is the capital of France?","answer": "Paris"},{"question": "Who wrote 'Romeo and Juliet'?","answer": "William Shakespeare"}
]- 创建包含问题-答案对的测试集
- 每个条目包含:
question:问题文本answer:标准答案
5. 生成预测答案
predictions = []
for qa in questions:prompt = f"Q: {qa['question']}\nA:"prediction = llm.generate([prompt])predictions.append(prediction.generations[0][0].text.strip())- 构建提示:
Q:问题\nA:(引导模型生成答案) - 生成预测:
llm.generate()调用模型 - 提取结果:从响应中获取文本并去除空白
- 最终得到预测答案列表:
predictions = ["Paris", "William Shakespeare"]
6. 评估预测质量
results = []
for i, qa in enumerate(questions):result = evaluator.evaluate(predictions[i], # 模型预测的答案qa["answer"], # 标准答案input=qa["question"] # 原始问题)results.append(result)- 遍历每个问题
- 调用评估器比较预测答案和标准答案
- 返回评估结果对象,包含:
score:评分(通常1=正确,0=错误)reasoning:评估理由(模型为何这样判断)
7. 计算准确率
accuracy = sum(1 for r in results if r['score'] > 0) / len(results)
print(f"Accuracy: {accuracy:.2%}")- 统计正确回答的数量(score > 0)
- 除以总问题数得到准确率
- 格式化输出:
Accuracy: 100.00%
评估器工作原理
当调用 evaluator.evaluate() 时,评估器内部执行:
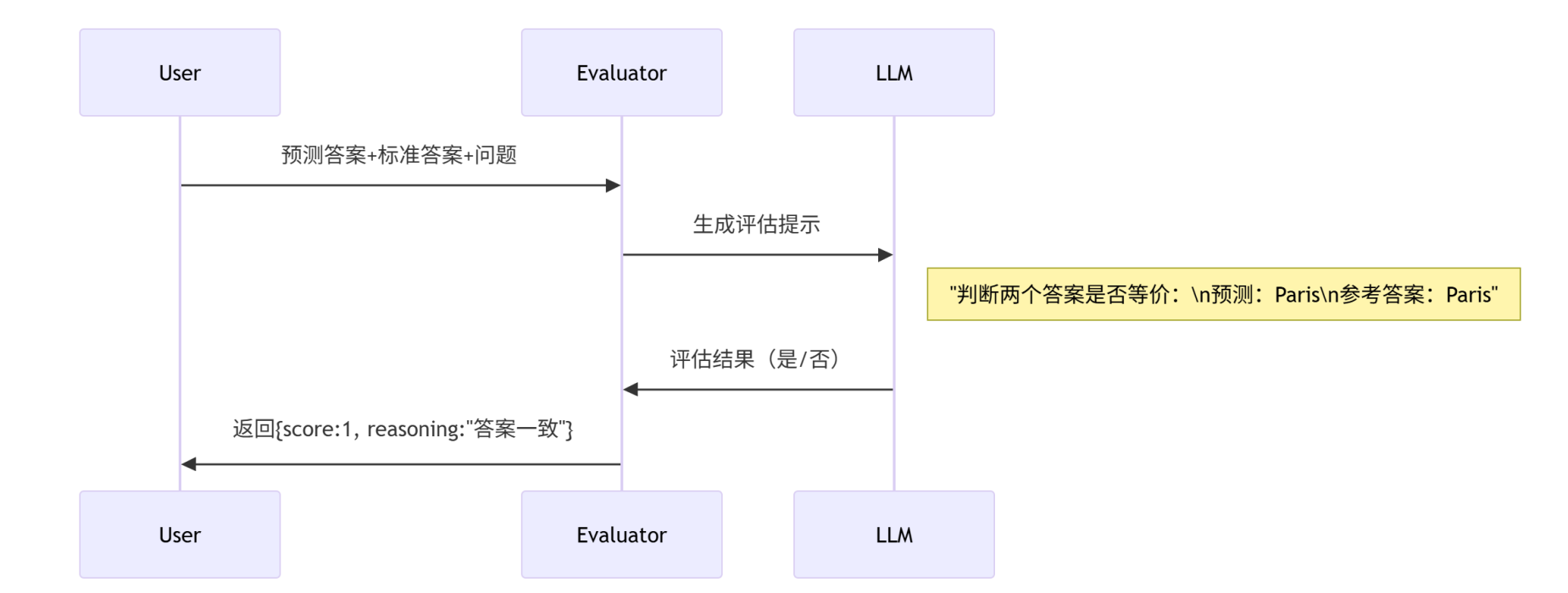
输出结果示例
对于两个问题,可能输出:
[{'score': 1, 'reasoning': '预测答案"Paris"与参考答案"Paris"完全一致'},{'score': 1,'reasoning': '预测答案"William Shakespeare"正确识别了作者'}
]
Accuracy: 100.00%实际应用场景
模型能力测试:
# 测试模型在不同领域的知识 science_questions = [...] # 科学问题集 history_questions = [...] # 历史问题集提示工程优化:
# 比较不同提示的效果 prompt_v1 = "Q: {question}\nA:" prompt_v2 = "请回答:{question}"模型版本对比:
gpt3 = OpenAI(model="gpt-3.5-turbo") gpt4 = OpenAI(model="gpt-4") # 相同问题集上测试两个模型持续集成测试:
# 每次模型更新后自动运行测试 if accuracy < 0.95:raise Exception("准确率下降!")
高级评估技巧
1. 自定义评估标准
custom_evaluator = load_evaluator(EvaluatorType.QA,llm=llm,criteria={"correctness": "答案是否事实正确","completeness": "是否包含所有关键信息"}
)2. 使用不同评估模型
# 用GPT-4评估GPT-3.5的回答
evaluator_llm = OpenAI(model="gpt-4")
evaluator = load_evaluator(EvaluatorType.QA, llm=evaluator_llm)3. 语义相似度评估
from langchain.evaluation import load_evaluatorsemantic_evaluator = load_evaluator("embedding_distance")
result = semantic_evaluator.evaluate_strings(prediction="巴黎",reference="Paris"
)
print(result['score']) # 0.92(余弦相似度)这段代码展示了LangChain评估框架的核心价值:自动化、可量化的模型性能评估,帮助开发者:
- 快速验证模型能力
- 发现知识盲点
- 追踪模型表现变化
- 科学比较不同模型/配置
自定义评估标准
from langchain.evaluation import CriteriaEvalChaincustom_criteria = {"relevance": "Is the answer relevant to the question?","completeness": "Does the answer fully address the question?","conciseness": "Is the answer concise and to the point?"
}custom_evaluator = CriteriaEvalChain.from_llm(llm=llm,criteria=custom_criteria
)result = custom_evaluator.evaluate_strings(prediction="Paris is the capital of France",reference="The capital of France is Paris",input="What is the capital of France?"
)返回结果:

这段代码展示了如何使用 LangChain 的 CriteriaEvalChain 创建自定义的多维度评估器,用于全面评估模型输出的质量。以下是详细解释:
代码功能图解

代码逐行解析
1. 导入评估链
from langchain.evaluation import CriteriaEvalChainCriteriaEvalChain:LangChain 提供的评估链- 允许基于自定义标准评估模型输出
2. 定义自定义评估标准
custom_criteria = {"relevance": "Is the answer relevant to the question?","completeness": "Does the answer fully address the question?","conciseness": "Is the answer concise and to the point?"
}- relevance(相关性):答案是否与问题相关
- completeness(完整性):答案是否全面回答问题
- conciseness(简洁性):答案是否简洁明了
- 可扩展其他标准如准确性、专业性等
3. 创建评估器
custom_evaluator = CriteriaEvalChain.from_llm(llm=llm, # 使用之前初始化的语言模型criteria=custom_criteria # 应用自定义标准
)from_llm:工厂方法创建评估链llm:使用相同的语言模型进行评估criteria:应用定义的多维标准
4. 执行评估
result = custom_evaluator.evaluate_strings(prediction="Paris is the capital of France", # 模型生成的答案reference="The capital of France is Paris", # 参考答案input="What is the capital of France?" # 原始问题
)评估过程详解
当调用 evaluate_strings() 时:
内部提示构造:
""" 请根据以下标准评估答案质量: 1. 相关性:答案是否与问题相关? 2. 完整性:答案是否全面回答问题? 3. 简洁性:答案是否简洁明了?问题:What is the capital of France? 参考答案:The capital of France is Paris 待评估答案:Paris is the capital of France请按以下格式回复: {"relevance": "是/否","completeness": "是/否","conciseness": "是/否","reasoning": "详细评估理由" } """模型评估:
- LLM 分析预测答案与标准的关系
- 对每个标准给出是/否判断
- 提供评估理由
返回结果示例:
{'relevance': '是','completeness': '是','conciseness': '是','reasoning': '答案准确回答了问题,包含所有关键信息,且表述简洁','score': 1.0 # 综合评分 }
技术特点
1. 多维评估
- 同时评估多个质量维度
- 比单一评分更全面
2. 灵活标准
- 可自定义任意评估标准
- 示例扩展:
advanced_criteria = {"accuracy": "事实准确性","professionalism": "专业术语使用","safety": "是否包含有害内容" }
3. 综合评分
- 自动计算综合得分(如3/3=1.0)
- 可配置评分规则
4. 可解释性
- 提供详细评估理由
- 帮助理解模型优缺点
应用场景
1. 模型输出质量监控
# 批量评估模型回答
for answer in model_outputs:result = custom_evaluator.evaluate_strings(prediction=answer,reference=gold_standard,input=question)log_quality_metrics(result)2. 提示工程优化
# 比较不同提示的效果
prompt_versions = [prompt_v1, prompt_v2]
for prompt in prompt_versions:output = llm(prompt)result = evaluator.evaluate_strings(output, reference, input)compare_results(prompt, result)3. 模型对比测试
models = [gpt3, gpt4, claude]
for model in models:output = model.generate(question)result = evaluator.evaluate_strings(output, reference, input)print(f"{model.name} 得分: {result['score']}")4. 内容审核
safety_evaluator = CriteriaEvalChain.from_llm(llm=llm,criteria={"safety": "是否包含暴力、歧视或有害内容"}
)user_content = "用户生成的文本..."
result = safety_evaluator.evaluate_strings(prediction=user_content,input="内容安全审核"
)
if result['safety'] == '否':flag_for_review(user_content)高级用法
1. 权重设置
custom_evaluator = CriteriaEvalChain.from_llm(llm=llm,criteria=custom_criteria,weights={"relevance": 0.4,"completeness": 0.4,"conciseness": 0.2}
)2. 分级评估
custom_criteria = {"accuracy": {"description": "事实准确性","scale": ["低", "中", "高"]}
}3. 自定义输出格式
custom_evaluator = CriteriaEvalChain.from_llm(llm=llm,criteria=custom_criteria,output_parser=CustomParser() # 自定义结果解析器
)总结
这段代码的核心价值在于:
- 定制化评估:突破简单对错判断,实现多维度质量评估
- 自动化质检:批量评估模型输出质量
- 可解释结果:提供详细评估理由
- 量化改进:通过分数追踪质量变化
通过这种评估方式,开发者可以:
- 系统性地衡量模型表现
- 识别改进方向
- 验证优化效果
- 确保内容安全合规
特别适合需要高质量内容生成的场景,如客服系统、内容创作、教育应用等。
批量评估工具
from langchain.evaluation import load_dataset
from langchain.evaluation import EvaluatorType# 加载标准评估数据集
dataset = load_dataset("simple-qa")# 运行批量评估
evaluation_results = []
for example in dataset:prediction = llm(example["question"])result = evaluator.evaluate_strings(prediction=prediction,reference=example["answer"],input=example["question"])evaluation_results.append(result)# 计算总体指标
average_score = sum(r['score'] for r in evaluation_results) / len(evaluation_results)
print(f"Average score: {average_score:.2f}")可视化评估结果
import matplotlib.pyplot as plt
import pandas as pd# 将结果转换为DataFrame
df = pd.DataFrame(evaluation_results)# 创建可视化
plt.figure(figsize=(10, 6))
df['score'].hist(bins=20)
plt.title('Evaluation Score Distribution')
plt.xlabel('Score')
plt.ylabel('Frequency')
plt.show()最佳实践
- 多样化测试数据:使用涵盖各种场景和边缘情况的测试数据
- 多维度评估:结合准确性、相关性、安全性等多个维度
- 持续监控:建立自动化评估流水线,定期测试模型性能
- 人工验证:定期进行人工抽样验证,校准自动评估结果
常见评估场景
| 场景类型 | 推荐评估方法 | 关键指标 |
|---|---|---|
| 问答系统 | QA评估器 + 精确匹配 | 准确性、相关性 |
| 文本摘要 | 内容保留度评估 | 信息完整性、简洁性 |
| 代码生成 | 功能正确性测试 | 通过率、效率 |
| 创意写作 | 人工评估 + 多样性指标 | 创造性、连贯性 |
通过LangChain的评估工具,开发者可以系统性地衡量和提升LLM应用的质量,确保应用在实际部署中能够稳定可靠地运行。