使用QLoRA 量化低秩适配微调大模型介绍篇
前言
QLoRA成功地打破了“高性能必须高资源”的壁垒,真正实现了大模型微调的“民主化”。
介绍
QLoRA(Quantized Low-Rank Adaptation),这是一种高效微调大规模量化语言模型的方法,能够在保持性能的同时大幅降低显存占用,不同于LoRA、AdaLoRA,QLoRA是在硬件方面的优化,可以允许在单个 48GB GPU 上微调高达 65B 参数的模型(如 LLaMA),同时保持与 16-bit 全精度微调相当的性能。
为什么大模型训练成本极高
在传统的全精度深度学习训练中,模型中的每一个参数(权重或偏置)在计算机内存中需要占用 4 个字节(Bytes)的存储空间,即4 * 8 = 32 个bit,假设我们有一个 70亿(7B)参数的模型(比如LLaMA-7B),如果使用 FP32(全精度)进行训练或推理:总内存占用 = 参数数量 × 每个参数大小 = 7,000,000,000 × 4 字节 = 28,000,000,000 字节 = 28 GB,这意味着,仅仅是为了把这样一个7B的模型加载到GPU显存中,什么都不做,你就至少需要一张超过28GB显存的显卡(比如A100 40GB)。如果还要进行训练(需要额外的空间存储梯度、优化器状态等),需求会更高,这就是为什么大模型训练成本极高。
原理分析
1、如何降低内存占用
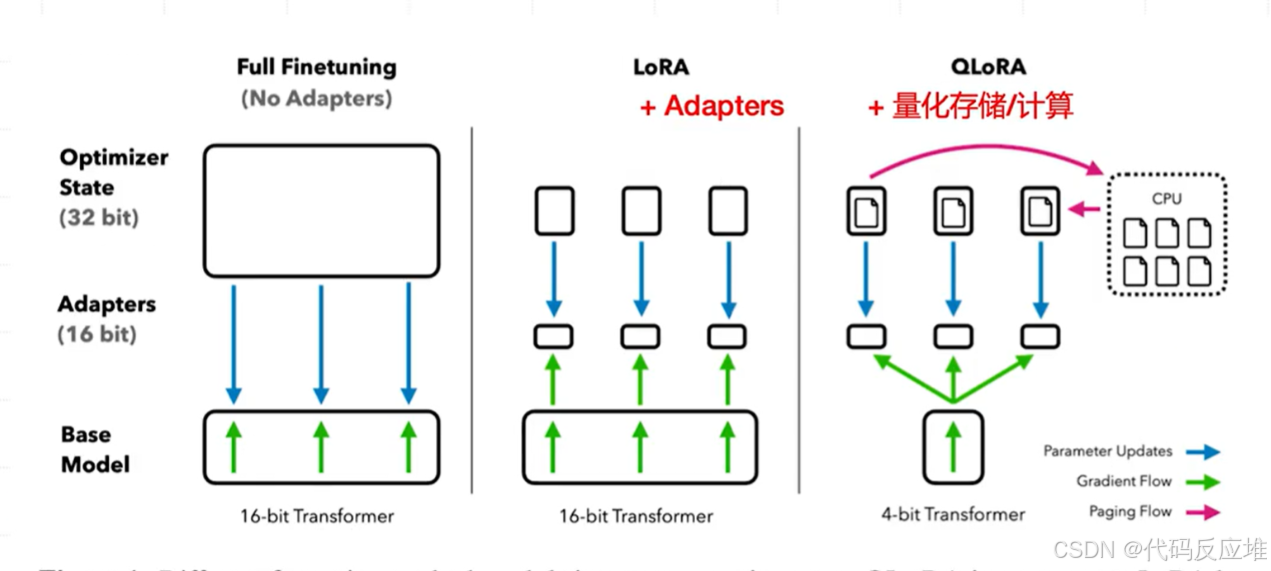
如图全微调 (Full Finetuning - FFT)内存占用高包含:基础模型 (Base Model): 完整的、16位(FP16) 精度的Transformer模型。这是内存占用的大头。优化器状态 (Optimizer State - 32 bit): 为了更新所有模型参数,优化器(如Adam)需要为每个参数保存额外的状态信息(例如动量、方差),这些状态通常是32位(FP32)的。这会使得内存占用增加约2倍于模型本身。适配器 (Adapters): 无。直接更新原始模型的权重。
LoRA (Low-Rank Adaptation)通过冻结原模型并只训练一小部分新增参数,避免了为原始模型保存优化器状态和梯度,从而显著降低了内存需求。但原模型依然是16位的,这对超大模型来说仍然很占内存。如图基础模型 (Base Model)😗* 完整的、16位(FP16) 精度的Transformer模型。在训练过程中被冻结(frozen),其权重不再更新。优化器状态 (Optimizer State - 32 bit): 由于原始模型参数被冻结,优化器只需要为新引入的、非常小的低秩适配器(LoRA Adapters)参数保存状态。这极大地减少了优化器状态的内存占用。适配器 (Adapters - 16 bit): 在原始模型的某些层(通常是Attention层)旁注入一小对低秩矩阵(A和B)。只有这些矩阵的参数是可训练的。参数更新 (Parameter Updates): 梯度通过冻结的基础模型进行反向传播(Gradient Flow),但最终只用于更新这些低秩适配器参数。
QLoRA (Quantized LoRA)是LoRA的升级版,它引入了两项关键改进:1、基础模型 (Base Model): 核心创新之一。将预训练模型量化到4位精度(4-bit Transformer)(例如使用NormalFloat (NF4) 数据类型,针对正态分布的权重进行了信息理论上的优化。还包括 Double Quantization(双量化:对量化常数再次量化),进一步降低内存占用。)。这大约将模型本身的内存占用减少了4倍。2、分页优化器 (Paged Optimizer): 核心创新之二。它借鉴了计算机操作系统中虚拟内存和分页的概念。当GPU显存即将爆满时,优化器状态会自动被转移到CPU RAM中,然后在需要时再换回GPU(Paging Flow),从而平滑地处理训练过程中的内存峰值,避免内存不足错误。适配器 (Adapters - 16 bit): 和LoRA一样,训练16位的低秩适配器。参数更新 (Parameter Updates): 尽管基础模型是4位的,但在前向和反向传播过程中,权重会被即时反量化(dequantized) 到16位精度以进行计算(Quantized Storage/Computation),确保训练精度不受影响。梯度同样只用于更新适配器参数。
2、浮点数据类型知识

了解常见的浮点数数据类型(Floating-Point Formats)的二进制位结构。这对于理解模型量化(Quantization)的基础至关重要。以上图展示了四种浮点数的精度格式,从上到下,精度和所能表示的数值范围依次降低,但同时存储所需的空间也依次减少(从32位到8位)。这种减少是模型量化技术的核心——通过降低数值精度来换取内存节省和计算加速。
第一个图FP32 (Float 32 - 单精度浮点数),结构: 1 bit(符号位 Sign,决定数是正数(0)还是负数(1)) + 8 bits(指数位 Exponent,决定数值的范围(scale)) + 23 bits(尾数位 Mantissa,决定数值的精度(precision)),这是最标准的浮点数格式,广泛应用于科学计算和深度学习中的全精度(Full-Precision)训练。具有很高的动态范围和精度,但占用内存最大。
第二个图FP16 (Float 16 - 半精度浮点数),结构: 1 bit(符号位 Sign) + 5 bits(指数位 Exponent) + 10 bits(尾数位 Mantissa),常用于深度学习的混合精度训练和推理。与FP32相比,它的指数位和尾数位都减少了,从而节省了一半的内存(每个参数2字节)。存在数值表示范围较小的问题,容易发生数值下溢(Underflow)(即非常小的数被舍入为0),可能导致训练不稳定。
第三、四图 FP8 (Float 8 - 8位浮点数) - 两种变体,FP8是一种较新的格式,旨在进一步加速AI训练和推理(尤其是Hopper架构的NVIDIA GPU如H100提供了原生FP8支持)。由于位数很少,需要在表示范围(指数) 和精度(尾数) 之间做出权衡,因此产生了两种主要变体:
a) FP8 E4M3 (Float 8 with 4 Exponent bits & 3 Mantissa bits),结构: 1 bit(符号位 Sign) + 4 bits(指数位 Exponent) + 3 bits(尾数位 Mantissa),更侧重于精度。较少的指数位意味着表示范围较小,但较多的尾数位(对于8bit来说)能提供相对更好的精度。适合需要较高计算精度的场景。
b) FP8 E5M2 (Float 8 with 5 Exponent bits & 2 Mantissa bits),结构: 1 bit(符号位 Sign) + 5 bits(指数位 Exponent) + 2 bits(尾数位 Mantissa),更侧重于范围。较多的指数位可以表示更大的数值范围(防止溢出),但极少的尾数位意味着精度很低。适合表示权重或激活值范围较大的场景。
QLoRA内存节省这是最直接的好处。从FP32到FP16,内存减半;从FP16到FP8,内存再减半。QLoRA中使用的4-bit量化则更进一步,比FP8还能再节省一半内存。QLoRA采用了一种称为NormalFloat 4 (NF4) 的自定义数据类型。这种数据类型是信息理论最优的,它假设神经网络权重服从正态分布,并针对这一分布进行了优化,在4位这个极其苛刻的精度下,能比常规的INT4或FP4更好地保留原始模型的信息。更低精度的数据类型不仅减少了内存占用,也降低了计算所需的数据带宽,从而在现代硬件(GPU/TPU)上可以实现大幅的计算加速。
3、QLoRA量化技术和NF4数据类型
1、标准的量化与反量化
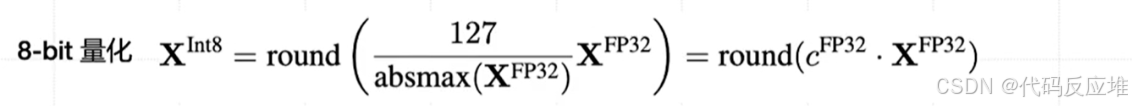
将一片FP32精度的数据映射到INT8(-128 到 127)的整数范围内。首先找到这片FP32数据中绝对值的最大值(absmax(X^FP32)),计算缩放因子 c = 127 / absmax。这个因子决定了要将FP32数值缩小多少倍才能“塞进”INT8的范围。量化:将这片FP32数据中的每一个值都乘以这个缩放因子 c,然后四舍五入取整(round)得到对应的INT8整数。这个过程就是**量化*
反量化(Dequantization)
我们只需要将INT8整数除以同样的缩放因子 c,就可以近似地恢复出原始的FP32数值。这是一个有损压缩的过程。
这就像你要把一堆高度不同的柱子(FP32值)放进一个有限的柜子(INT8范围)里。你先找到最高的柱子(absmax),然后按比例把所有柱子同时缩小(乘以 c),这样最高的柱子刚好碰到柜顶。使用时,再按比例放大(除以 c)回来。
2、NF4数据类型
标准量化有一个问题:它假设数值是均匀分布的。但神经网络权重通常是正态分布的(集中在0附近,极端值很少)。用均匀量化会很浪费。NF4的解决方案:分位数量化,对于4比特(16个区间)希望原始FP32数据中,落入每个区间的值的概率都是 1/16。这样,数据密集的地方(0附近)区间小而多,数据稀疏的地方(两端)区间大而少,从而在保持区间数不变的情况下,最大限度地保留信息(正态分布),NF4不像标准量化那样“均匀地”划分区间,而是“智能地”根据正态分布的特性来划分。它在数值密集的地方(靠近0)使用更精细的间隔,在数值稀疏的地方使用更粗糙的间隔,从而在4比特的极限压缩下,实现了比均匀量化更高的精度。
QLoRA实验结果
QLoRA(特别是使用NF4数据类型和双量化技术)使得我们能够以仅需4-bit存储的极致内存占用,来微调超大模型,并且最终达到与完整的16-bit全精度微调完全相当的性能水平。QLoRA成功地打破了“高性能必须高资源”的壁垒,真正实现了大模型微调的“民主化”。