JDK21对虚拟线程的实践
一、参考官方文档
Virtual ThreadsVirtual threads are lightweight threads that reduce the effort of writing, maintaining, and debugging high-throughput concurrent applications.![]() https://docs.oracle.com/en/java/javase/21/core/virtual-threads.html?utm_source=chatgpt.com#GUID-04C03FFC-066D-4857-85B9-E5A27A875AF9
https://docs.oracle.com/en/java/javase/21/core/virtual-threads.html?utm_source=chatgpt.com#GUID-04C03FFC-066D-4857-85B9-E5A27A875AF9
二、什么是虚拟线程
目标:用少量平台线程(Platform Threads)支撑海量并发任务(如 100 万请求),提升吞吐量。
| 类型 | 说明 |
|---|---|
| 平台线程(PlatformThread) | JVM 映射到操作系统线程(OS Thread),创建成本高(默认几百 KB 栈空间),数量受限(通常几千) |
| 虚拟线程(VirtualThread) | JVM 内部轻量线程,由 Thread.ofVirtual() 创建,不直接绑定 OS 线程,可创建百万级 |
平台线程 = 真实员工(数量少、成本高)
虚拟线程 = 临时工(数量多、任务来了再分配真实员工干活)适用场景:
| 场景 | 说明 |
|---|---|
| 🟢 高并发 I/O 任务 | 如 HTTP 请求、数据库查询、Redis 调用(阻塞多、CPU 少) |
| 🟢 Web 服务器处理请求 | Tomcat、Netty、Spring WebFlux 等每请求一线程模型 |
| 🟢 批量处理任务 | 如 10 万条数据同步、日志处理 |
| 🟢 调用多个外部服务 | 并行调用订单、用户、库存服务并聚合结果 |
不适用场景:
| 场景 | 说明 |
|---|---|
| 🔴 CPU 密集型任务 | 如图像处理、加密解密、大数据计算 → 用平台线程池(ForkJoinPool) |
| 🔴 长时间运行的无限循环 | 虚拟线程调度器可能“饿死”其他任务 |
| 🔴 JNI / Native 代码 | 虚拟线程会被挂起,直到 native 方法返回(阻塞平台线程) |
| 🔴 持有 synchronized 块太久 | 会阻塞平台线程,降低并发能力 |
三、几种用法
| 你的需求 | 推荐用法 |
|---|---|
| 学习虚拟线程 | Thread.ofVirtual().start() |
| 高并发 Web 请求、批量 I/O | ✅ newVirtualThreadPerTaskExecutor() |
| 并行调用多个服务,聚合结果 | ✅ Structured Concurrency |
| 虚拟线程中执行 Redis / DB 批量操作 | ✅ 虚拟线程 + executePipelined |
| CPU 密集型任务(如计算) | ❌ 不要用虚拟线程,用 ForkJoinPool |
1、Thread.ofVirtual().start()
—— 最基础的创建方式
Thread vt = Thread.ofVirtual().name("worker").start(() -> {System.out.println("Hello from " + Thread.currentThread());try {Thread.sleep(1000);} catch (InterruptedException e) {}System.out.println("Done");});vt.join(); // 等待完成✅ 适用场景
- 学习虚拟线程原理
- 单个、简单的并发任务
- 不需要任务管理或资源回收
❌ 不适用场景
- 批量任务(如 10 万个请求)
- 需要统一管理生命周期
- 生产环境高并发服务
📌 建议
不推荐用于生产环境。它没有资源池管理,无法限制并发,容易造成内存溢出。
2、Executors.newVirtualThreadPerTaskExecutor()
—— 最推荐的生产级用法
try (var executor = Executors.newVirtualThreadPerTaskExecutor()) {for (int i = 0; i < 10_000; i++) {executor.submit(() -> {Thread.sleep(Duration.ofSeconds(1));System.out.println("Task " + Thread.currentThread());return "result";});}
} // 自动等待所有任务完成✅ 适用场景
| 场景 | 说明 |
|---|---|
| 🟢 Web 请求处理 | 每个 HTTP 请求启动一个虚拟线程(Spring Boot 6+ 默认) |
| 🟢 批量 I/O 操作 | 如读取 10 万个文件、调用外部 API |
| 🟢 消息队列消费 | 每条消息一个虚拟线程处理 |
| 🟢 Redis / DB 批量查询 | 配合 multiGet 或 pipeline 使用 |
✅ 优势
- 自动管理虚拟线程生命周期
try-with-resources自动close()并等待所有任务完成- 无需担心资源泄漏
📌 建议
在生产环境中最应该使用的虚拟线程方式!尤其适合:高并发 + I/O 密集 + 短任务
3、Structured Concurrency(结构化并发)
—— 多任务协同、聚合结果,是虚拟线程 + 并发编程的“最佳实践”
// 用法示例(聚合多个远程调用)
try (var scope = new StructuredTaskScope.ShutdownOnFailure()) {Future<String> user = scope.fork(() -> fetchUser());Future<Integer> order = scope.fork(() -> fetchOrder());Future<List<String>> items = scope.fork(() -> fetchItems());scope.join(); // 等待所有任务scope.throwIfFailed(); // 抛出异常System.out.println("User: " + user.resultNow());System.out.println("Order: " + order.resultNow());
}✅ 适用场景 ✅
| 场景 | 说明 |
|---|---|
| 🟢 API 编排 | 同时调用用户、订单、商品服务,聚合返回 |
| 🟢 扇出(Fan-out)模式 | 一个请求触发多个并行子任务 |
| 🟢 需要统一超时控制 | 如 scope.joinUntil(Instant.now().plusSeconds(3)) |
| 🟢 需要失败传播 | 任一子任务失败,其他任务可取消 |
✅ 优势
- 结构清晰,父子任务关系明确
- 支持超时、取消、异常传播
- 可读性远高于
Future.get()
📌 建议
当你需要“并行调用多个服务 + 聚合结果”时,优先使用结构化并发。
四、监控对内存的使用情况
模拟10w虚拟线程
import java.lang.management.ManagementFactory;
import java.lang.management.MemoryMXBean;
import java.lang.management.MemoryUsage;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;public class VirtualThreadTest {// 方法一:查看当前 JVM 内存使用情况public static void printMemoryUsage(String phase) {MemoryMXBean memoryMXBean = ManagementFactory.getMemoryMXBean();MemoryUsage heapMemory = memoryMXBean.getHeapMemoryUsage();System.out.printf("[%s] Heap Memory Used: %d MB / %d MB%n",phase,heapMemory.getUsed() / (1024 * 1024),heapMemory.getMax() / (1024 * 1024));}// 方法二:创建虚拟线程执行任务public static void runVirtualThreads(int taskCount) throws InterruptedException {ExecutorService executor = Executors.newVirtualThreadPerTaskExecutor();for (int i = 0; i < taskCount; i++) {int finalI = i;executor.submit(() -> {System.out.printf("虚拟线程[%s] 执行任务 %d%n",Thread.currentThread(),finalI);try {Thread.sleep(1000); // 模拟 IO 阻塞} catch (InterruptedException e) {Thread.currentThread().interrupt();}});}executor.shutdown();while (!executor.isTerminated()) {Thread.sleep(100);}}// 方法三:循环查看内存(模拟 GC 回收效果)public static void monitorMemory(int seconds) throws InterruptedException {for (int i = 0; i < seconds; i++) {printMemoryUsage("监控中");System.gc(); // 建议 GC,可能不会马上执行Thread.sleep(1000);}}// 主方法测试public static void main(String[] args) throws Exception {// 1. 初始内存printMemoryUsage("初始");// 2. 创建 1 万个虚拟线程任务runVirtualThreads(100_000);// 3. 任务执行后内存printMemoryUsage("任务执行后");// 4. 持续观察 GC 是否回收虚拟线程monitorMemory(10);}
}
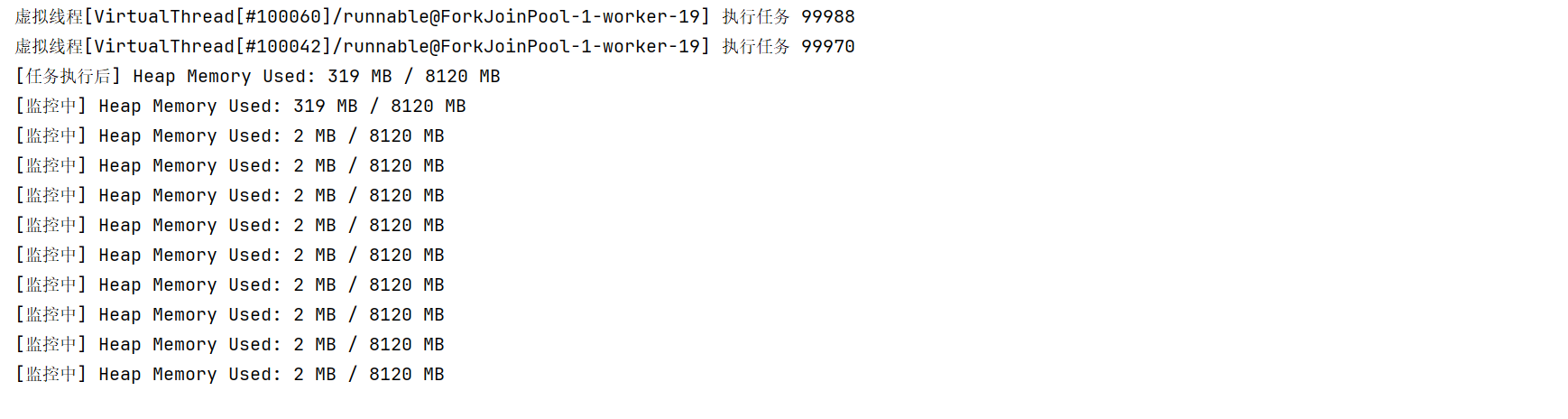
可以看到快速创建10万的虚拟线程也能很快的将内存进行回收,可能大家会想,不是说虚拟线程是创建一个线程就回收内存了吗,为啥你这里统一进行释放呢,可以看到我这里进行阻塞,模拟创建10万线程大概会占用多少内存

五、兼容ThreadLocal
在我们现阶段大多数用户信息都是通过ThreadLocal进行传递过来,每个线程绑定一个用户
1、传统平台线程 + ThreadLocal 的关系
下面我们回顾一下传统的ThreadLocal和线程的关系:
- 每个
Thread对象内部有一个ThreadLocal.ThreadLocalMap成员 ThreadLocal.set(value)→ 当前线程的map中存入<ThreadLocal 实例, value>ThreadLocal.get()→ 从当前线程的map中取出对应值- 生命周期与线程绑定:线程存活 →
ThreadLocal副本存在 - 实际并发 100 请求 → 最多 100 个副本(但线程池通常只有 200 个线程,会复用)
关系图如下:
平台线程 T1 → 有自己的 ThreadLocalMap → 存储 BaseContext.value
平台线程 T2 → 有自己的 ThreadLocalMap → 存储 BaseContext.value
平台线程 T3 → 有自己的 ThreadLocalMap → 存储 BaseContext.value2、虚拟线程(Virtual Thread) + ThreadLocal 的关系
- JVM 实现的轻量级线程
- 多对一映射到“载体线程”(Carrier Thread,即平台线程)
- 栈在堆上分配,约 1KB
- 可创建 数十万甚至百万个
- 每个 HTTP 请求一个虚拟线程(高并发)
- 虚拟线程也是
java.lang.Thread的子类 - 所以它也有自己的
ThreadLocalMap set()/get()语法完全兼容
关系图如下:
载体线程 C1(平台线程) ├─ 虚拟线程 VT1 → 有自己的 ThreadLocalMap → 存储 BaseContext.value├─ 虚拟线程 VT2 → 有自己的 ThreadLocalMap → 存储 BaseContext.value└─ 虚拟线程 VT3 → 有自己的 ThreadLocalMap → 存储 BaseContext.value载体线程 C2├─ 虚拟线程 VT10001 → 有自己的 ThreadLocalMap → 存储 BaseContext.value└─ 虚拟线程 VT10002 → 有自己的 ThreadLocalMap → 存储 BaseContext.value3、两者的变化
- 传统:200 个线程 → 最多 200 个
ThreadLocal副本 - 虚拟线程:10 万个并发请求 → 10 万个
ThreadLocal副本
传统的线程的话会进行线程池排队,不会频繁创建线程,从而不会导致线程爆炸。要是某个虚拟线程执行什么任务。
4、怎么兼容线程模式下ThreadLocal
- 不全局使用虚拟线程(比如不设置
-Dspring.threads.virtual.enabled=true) - 只在特定地方手动创建虚拟线程
- 在这些虚拟线程中使用
ThreadLocal传递上下文(如用户信息)
// 获取当前用户信息(来自平台线程的 ThreadLocal)
String currentUser = BaseContext.getCurrentId(); // 假设这是从 ThreadLocal 拿的// 在虚拟线程中使用时,显式传入
Thread.startVirtualThread(() -> {// 显式使用传入的上下文processUserOrder(currentUser, orderId);
});5、检查自己的spingboot版本
import org.springframework.core.SpringVersion;public class SpringVersionCheck {public static void main(String[] args) {System.out.println("Spring Framework 版本: " + SpringVersion.getVersion());}
}6、检查自己是否默认开启全局的虚拟线程
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.context.ConfigurableApplicationContext;
import org.springframework.scheduling.annotation.EnableAsync;@SpringBootApplication
@EnableAsync
public class App {public static void main(String[] args) {ConfigurableApplicationContext ctx = SpringApplication.run(App.class, args);// 测试异步方法AsyncService service = ctx.getBean(AsyncService.class);service.asyncTask();}
}
import org.springframework.scheduling.annotation.Async;
import org.springframework.stereotype.Service;@Serviceclass AsyncService {@Asyncpublic void asyncTask() {Thread thread = Thread.currentThread();System.out.println("线程类型: " + (thread.isVirtual() ? "虚拟线程" : "平台线程"));System.out.println("线程名称: " + thread.getName());}}六、实战
新增conf配置类,让spring帮忙管理他的生命周期
import lombok.extern.slf4j.Slf4j;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.scheduling.annotation.AsyncConfigurer;
import org.springframework.scheduling.annotation.EnableAsync;import java.util.concurrent.Executor;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;@Slf4j
@Configuration
@EnableAsync // 启用 @Async 支持
public class VirtualThreadConfig implements AsyncConfigurer {private ExecutorService createVirtualThreadExecutor(String prefix) {return Executors.newThreadPerTaskExecutor(Thread.ofVirtual().name(prefix, 0).uncaughtExceptionHandler((thread, ex) ->log.error("虚拟线程 [{}] 执行异常", thread.getName(), ex)).factory());}/*** 用于单个用户收藏数据的异步回写(实时场景)*/@Bean("favoriteRedisWriterVirtualThreadExecutor")public Executor favoriteUserWriteVirtualThreadExecutor() {log.info("初始化虚拟线程池:favoriteUserWriteVirtualThreadExecutor");return createVirtualThreadExecutor("vt-fav-user-write-");}/*** 用于批量同步收藏数据到 Redis(定时任务场景)*/@Bean("favoriteBatchWriteVirtualThreadExecutor")public Executor favoriteBatchWriteVirtualThreadExecutor() {log.info("初始化虚拟线程池:favoriteBatchWriteVirtualThreadExecutor");return createVirtualThreadExecutor("vt-fav-batch-write-");}@Overridepublic Executor getAsyncExecutor() {return createVirtualThreadExecutor("vt-default-async-");}
}在定时任务中,我们需要对收藏数据进行全量重写到 Redis,以保证缓存一致性。由于数据量较大(3200+ 条记录),采用同步方式逐条写入会导致任务执行时间过长,影响系统响应性。为了提升任务执行效率,我们引入 虚拟线程(Virtual Threads),将每条 Redis 写入操作提交到独立的虚拟线程中并发执行。这样可以在不增加平台线程负担的前提下,显著提高 I/O 密集型操作的吞吐量,缩短全量刷新时间。


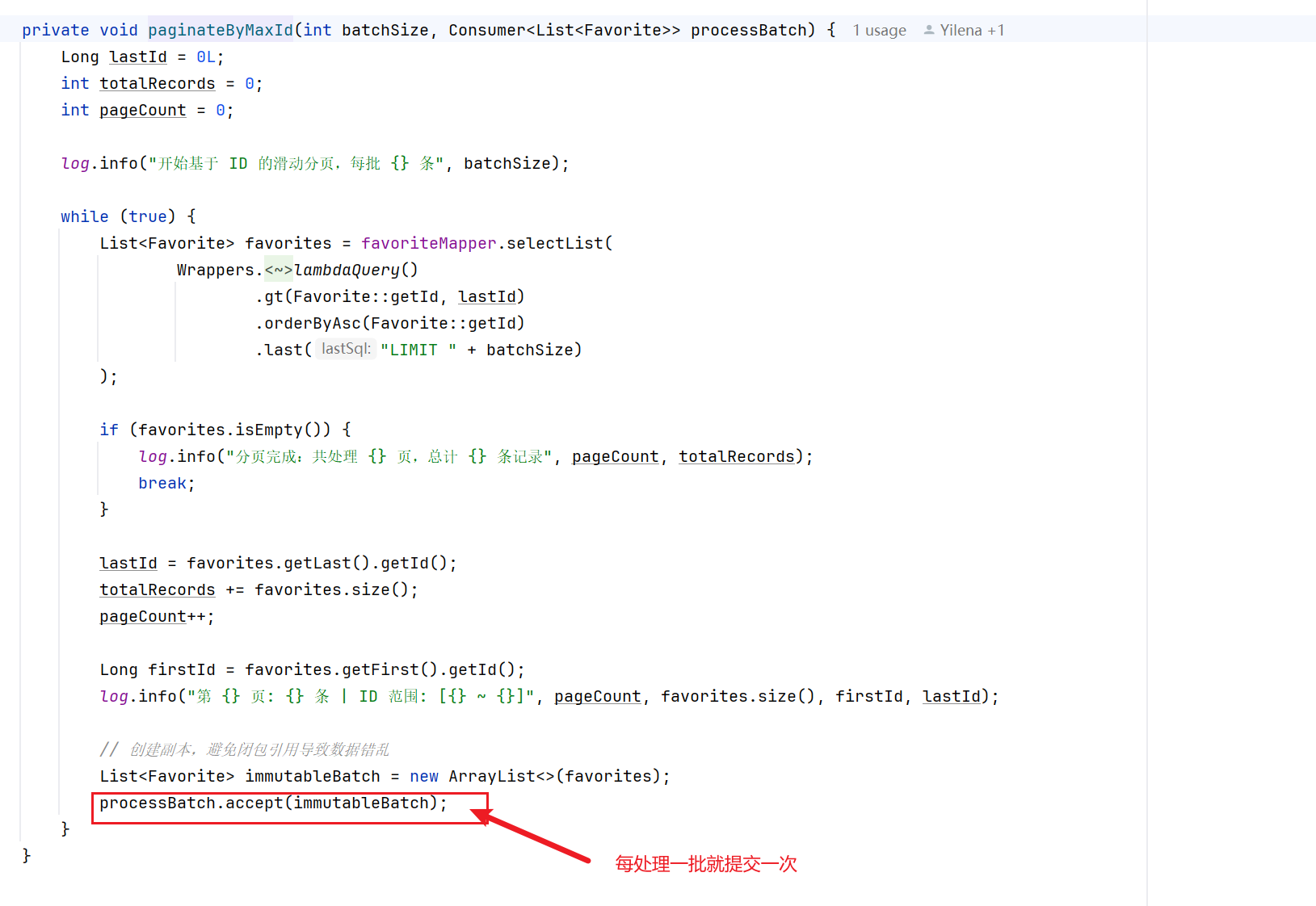

至此就简练的实现异步虚拟线程的改造方案