大模型术语
① 模型参数:大模型的“大脑容量”。
通常以十亿为单位,简称B
参数越多,模型能力越强,处理复杂问题更准确。
② 上下文长度:模型的“记忆范围”
模型一次性可以理解或者生成的文本的长度
思维链长度:模型输出答案前的思考步骤长度,提升答案准确性。
最大输出长度:模型单词输出的文本长度的上限
③ 量化:模型的“瘦身”术
降低模型参数精度,将高精度浮点数(FP32)转换至低精度整数(INT8,INT4).④
④ 蒸馏:知识的“传承”与“精炼”
将大型模型的知识和能力迁移到小模型的技术
⑤ Token:模型的“语言单位”
模型表示自然语言文本的最小单位,计费的基本单位。
可以是一个词、一个数字、一个标点符号。
⑥ MOE:混合专家的“分工协作”
Mixture of Experts(混合专家)结构,训练多个专家模块,每个专家负责特定任务。

⑦ RAG:检索增强生成的“知识外挂”
结合信息检索与生成式大模型,使得模型在回答问题时,实时引入外部知识库,提升模型的在知识密集任务中的表现。
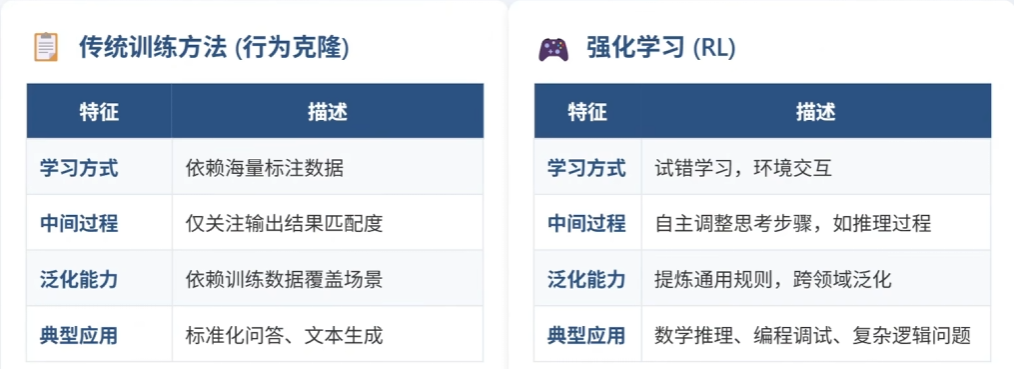
⑧ RL:强化学习的“试错进化”
模型通过试错学习和环境交互,自主优化策略
机制:奖励系统驱动模型在试错中优化策略,模拟人类“先思考后回答”的认知过程。
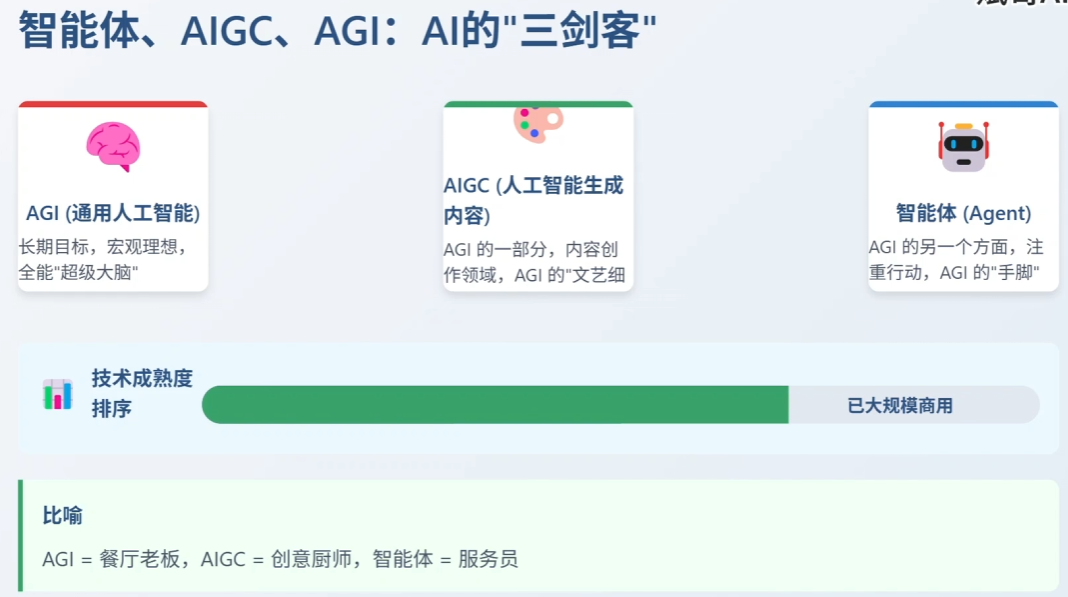
⑨ 智能体:AI的“自主行动者”
Agent(智能体),AI系统实现自主决策的核心载体。可以通过环境交互、多模态融合、策略优化不断拓展。
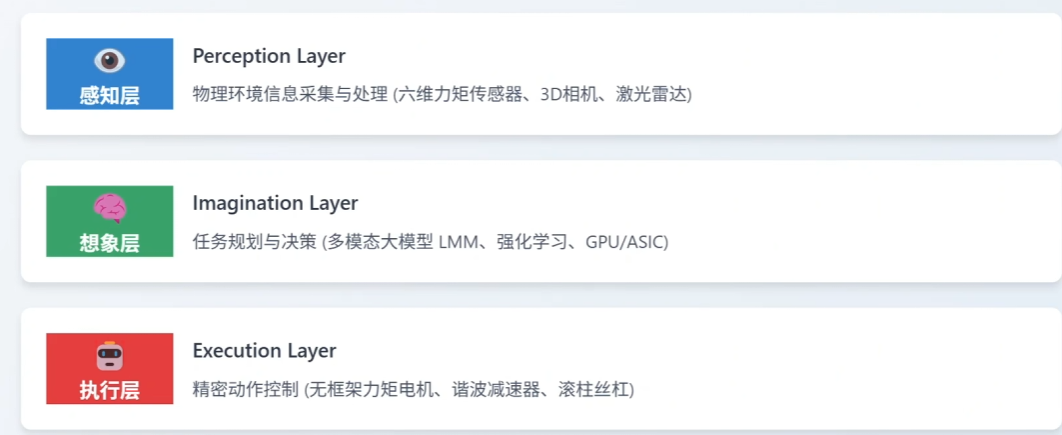
⑨ 具身智能:AI的“身体觉醒”
强调身体与环境交互对认知的重要性。
核心思想:智能并非孤立于大脑,而是身体、环境、感知运动系统协同作用的产物。