【模型训练篇】VeRL核心思想 - 论文HybridFlow
继续学习字节家的VeRL,今天介绍的是VeRL的核心思想,论文 【HybridFlow: A Flexible and Efficient RLHF Framework】,是VeRL的第二篇文章:
- 底层分布式能力基础Ray(点击查看):
VeRL分布式能力的基础,框架Ray - VeRL的原理:HybridFlow
- VeRL的使用,普通RL(单轮RL)
- VeRL的使用,Agentic RL(多轮RL)
- VeRL的魔改
RL
先来回顾一下RLHF,当使用 PPO 的时候,需要 actor、reference、reward、critic 四个模型,其中:
actor和reference,来自sft后的模型reward和critic则是使用 偏好数据 进行训练好的LLM,只不过输出头替换成了 标量输出
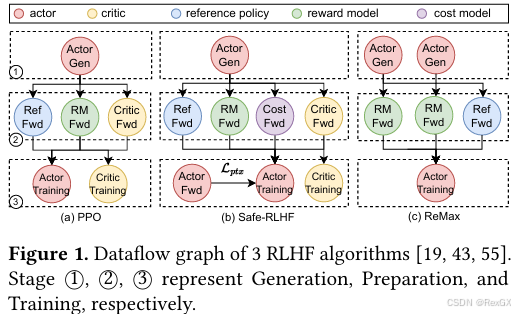
整个 PPO 过程,可以分成三部分:
Rollout,在VeRL中叫Generation:是用 batch prompts 通过actor生成的 response 轨迹数据- 将上述轨迹数据,用
reference、reward、critic这仨 make experience,在VeRL中叫Preparation - 用上述信息迭代
actor和critic
以上流程很简单本身上是种 DAG workflow,但当下分布式训练中,难点在于 DAG 中的每一个节点,都可以是分布式的,并且还需要使用不同DP策略;
现在市面上,大部分RL框架在执行训练任务的时候:
- 要么单独使用
single-croller:中心化的进程,管理整个workflow,控制数据、指令,worker可以MPMD - 要么单独使用
multi-controller:去中心化的,每个节点单独处理,属于 自驱,worker是SPMD
同时大部分RL框架并没有很好的处理一下case:
-
存储差异:对于
reward和reference这俩模型来说,只需要存储它们的权重参数到 GPU 即可,因为它们只做 FWD,而不像actor和critic需要存储参数、激活值、梯度、优化器等信息,所以它们对存储的需求差异很大 -
阶段差异:即使对于
actor这一个模型来说,在rollout和train这两个阶段的表现也不同,在train阶段属于compute-bound计算密集型,此时可以上大MP,但如果大MP也应用在了rollout阶段就很亏,所以即使同一个模型也有不同阶段不同策略 -
部署差异:PPO中有四个模型,它们的部署策略都不同,如下图所示,3台机器6张卡,其中
actor部署到01这两张卡上,critic部署到23这两张卡上,ref和rm部署到45这两卡上,按顺序执行,如果没有数据依赖的可以并行执行,有数据依赖的就等着;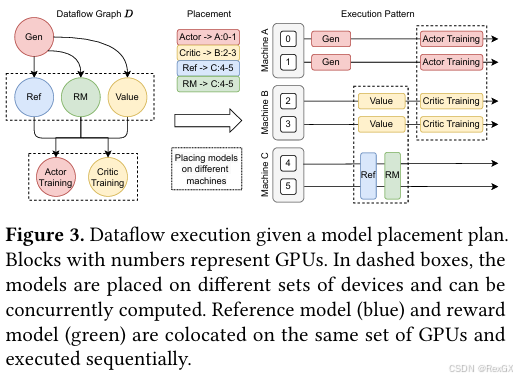
同时论文中也对比了一下,当下不同RL框架的部署策略: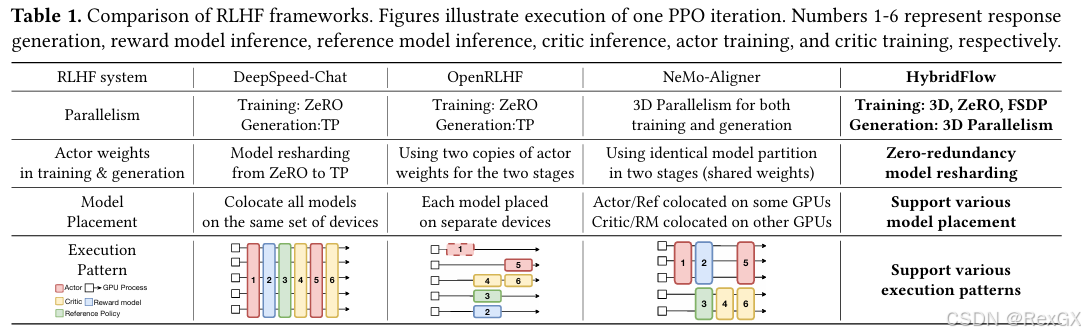
HybridFlow
在了解了以上RL的各种问题,以及当下RL框架的劣势后,HybridFlow给出了如下解法:
整体架构上: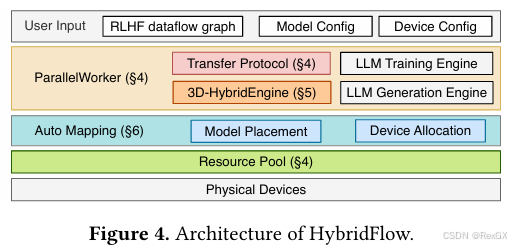
要注意的是:
3D-HybridEngine专门负责actor的rollout和train两个stage,使得actor可以实现不同的3D并行策略,并且高效的在这两个stage间切换auto mapping算法是套自研算法可以高效的优化模型部署
整体流程:
- 首先需要准备的东西有:
- PPO的4个模型
- 用auto-mapping算法结合GPU集群资源,跑出来的模型部署策略
- 这4个模型在各个阶段中的并行策略
single-controller:拿着上边的信息,去初始化模型、资源池、根据部署策略部署模型、和各个节点的multi-controller交互执行调用multi-contoller:其实就是各个节点worker,叫做ParallelWorker,它根据每个模型的并行策略,组建parallel group,调用3D-HybridEngine去执行actor的两个stage,也可以整合现有的其他LLM框架进行训练和推理
整体使用上: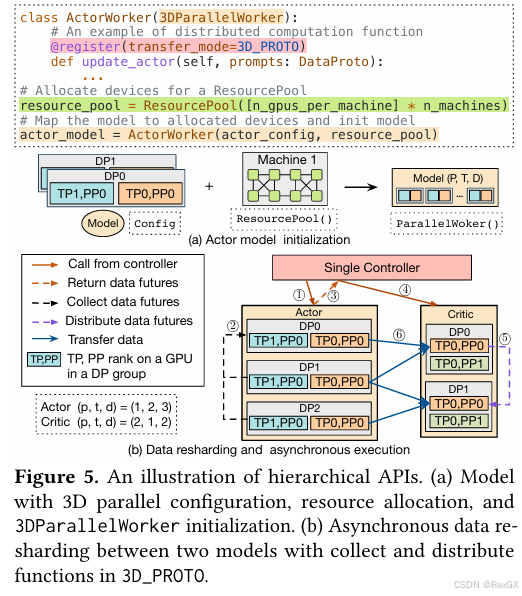
3DParallelWroker是负责实现并行策略的,它根据不同模型的分布式权重初始化策略,组建3DParallelGroup3DParallelGroup是一组GPU,负责特定的并行策略:group是一组spmd进程的抽象,像单个程序一个被调用ActorWroker实现了3DParallelWorker,其他类似的还有实现了PyTorch FSDP的FSDPWorker、Zero的ZeroWroker@register的作用是:在不同模型跑在不同节点上的不同并行策略间,进行数据传输,所有的数据传输protocol都包含:
- 1个
collect方法用于收集数据:注意dispatch的是input数据,把input数据dispatch到各个worker上 - 1个
distribute方法用于distribute数据,各个worker处理完在通过aggregation进行整合,所以整合的是output数据
上图中Actor的upadte_actor使用3D并行策略,所以它使用@register(3D_PROTO);
同时可以看到Actor的并行策略是(1,2,3),而critic的并行策略是(2,1,2)使用了不同的3D并行策略:
single-controller通过3D_PROTO从actor收集数据的futures对象①②③,因为都是异步的(这里的异步futures估计都是通过Ray实现的)- 然后
single-controller再把收集到的futures对象,通过critic的3D_PROTO把数据发送到critic的每一个DP组④⑤ - 真实的数据传输只发生在Actor和Critic对应的各GPU rank之间⑥
- 将GPU资源初始化成
resource_pool后,结合并行策略config,可以实现模型的初始化 3D-HybridEngine专门负责actor的rollout和train两stage
首先为了不部署重复的actor,VeRL提倡将Actor的rollout和train部署到同一套设备上 colocate/共置,这样在同一台设备上可以直接使用上一轮更新后的权重,尽量省掉权重同步,不然就要存两份;
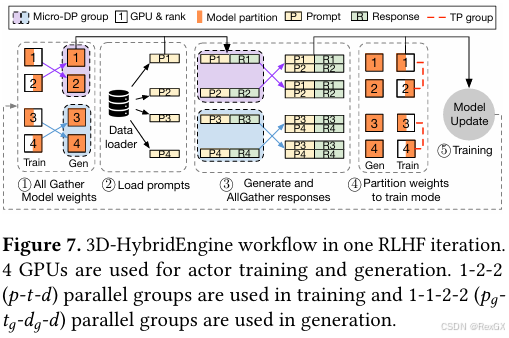
用p-t-d表示3D策略,ppp 表示模型被拆分成了ppp 个stage,ttt 表示模型tensor被拆分成了 ttt 份,ddd 表示数据被拆分成了 ddd 份,每一份都拥有一个完整的模型,也就是完整的 p∗dp*dp∗d
- 第 iii 轮的rollout收集第 i−1i-1i−1 轮train
actor更新后的模型权重①,这是一个all-gather操作 - 然后load prompt后,DP进行
rollout拿到轨迹数据,再发送给train阶段进行训练④⑤继续下一轮的迭代
既然actor的rollout和train两个stage可以使用不同的并行策略,但却在同一套set上只部署1份,那么如何处理模型在设备上的冗余?
冗余指的就是图中灰色overlap部分: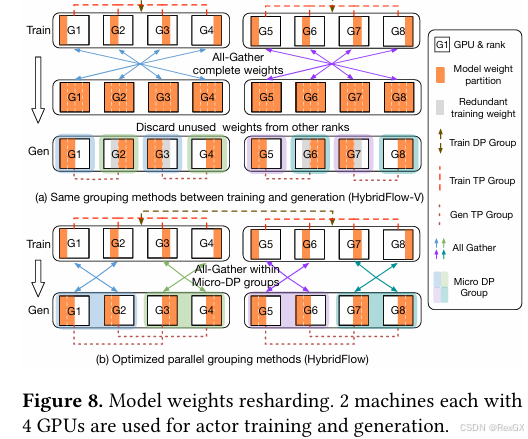
就是在两个阶段进行转换的时候,G2/G3/G6/G7灰色那部分,这部分冗余的模型权重就需要占着显存;
所以VeRL优化了这类场景,消除了这部分的冗余,就是上图中 (b),使得两个阶段可以reuse模型权重,尽最大可能overlap,降低显存占用;
7. auto mapping 算法:map的是device和模型的并行部署策略,具体算法就不看了(毕竟他们喜欢出 变种困难leetcode题…)
以上分析了在VeRL出现前RL框架的困境,以及VeRL的解题思路,下篇文章就重点看下使用与代码细节。