怎么用CXL加速数据库?· SIGMOD‘25
本文要介绍的是 SIGMOD’25 最佳工业论文《Unlocking the Potential of CXL for Disaggregated Memory in Cloud-Native Databases》。阿里云 PolarDB 团队基于 CXL 实现了 PolarDB 共享内存池,对比原有的 RDMA 方案实现了倍级性能提升。
背景
传统数据库是存算一体架构,如果要扩展资源,CPU 核、内存、存储必须一起扩,这带来了资源利用率低、成本高的问题。
比如,一台配置为 128 个 CPU 核 + 512 GB 内存 + 2 TB 存储的服务器上部署了一个数据库,业务高峰期只使用了 70% 的 CPU、60% 的内存,但存储已经接近 100%,必须再扩容一台服务器。这下,存储容量的问题解决了,但连带着增加了 CPU 和内存的成本,它们本无需扩容。
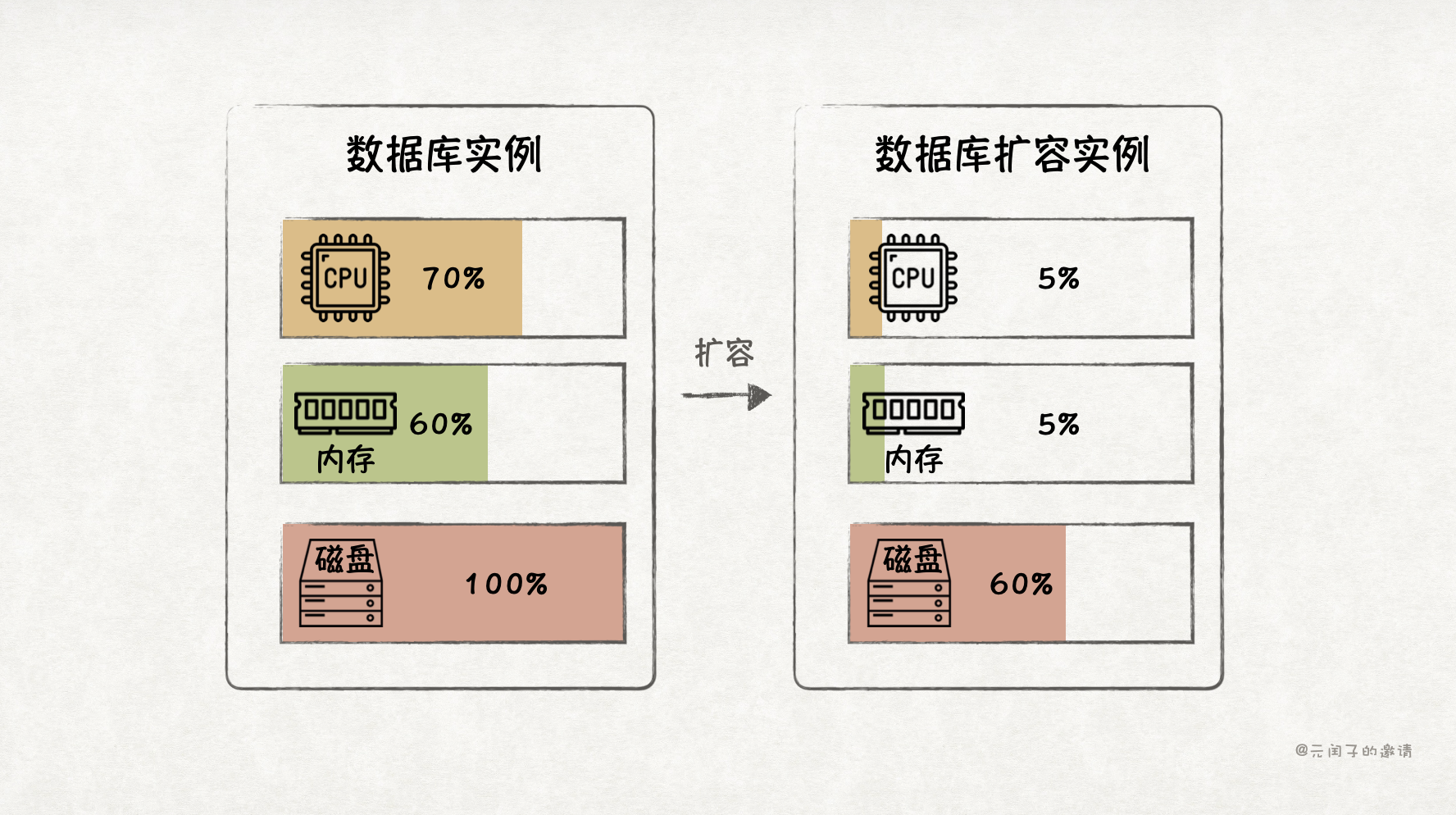
业界解决该问题的主要手段为分离和池化,也即云原生架构。
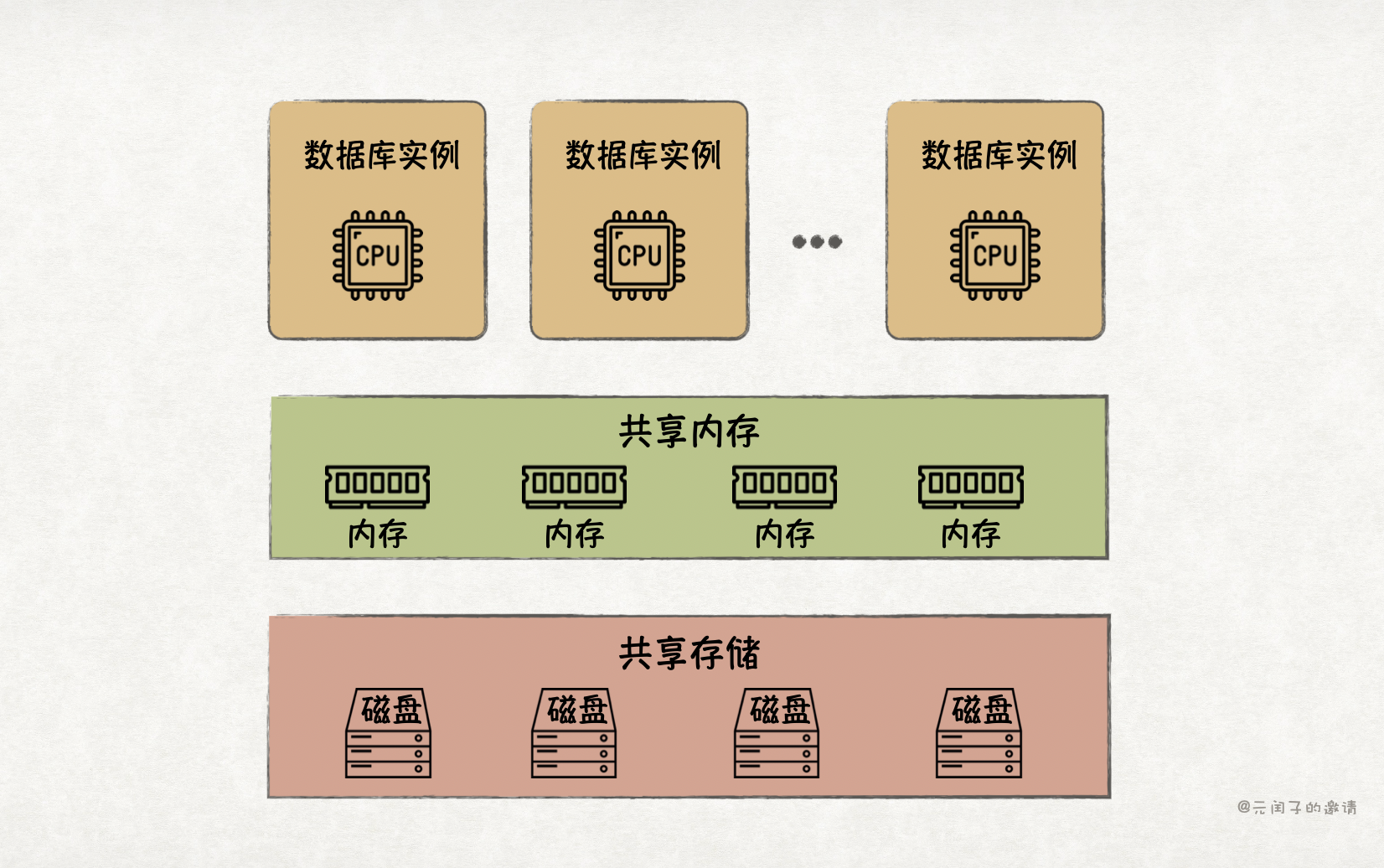
存储率先完成了分离。目前,存算分离已成为云原生数据库的主流架构,实现了低成本存储扩容。随着软硬件的发展,分离内存也逐渐流行了起来,旨在提升内存利用率。
数据库中,Buffer Pool 是内存消耗的大头,它将热数据缓存在内存里,能够有效提升数据库的读写性能。但受限于单机内存容量,Buffer Pool 无法做到很大,而且多节点间无法共享,限制了性能的进一步提升。有了内存分离技术,我们就能构建一个更大的全局共享 Buffer Pool,实现多写架构,提供更高的读写吞吐量。
分离就意味着远程通信,传统的 TCP/IP 通信方式存在用户态和内核态多次上下文切换和数据拷贝。虽然 DPDK 加速 TCP 能够实现内核旁路,但需要 CPU 在用户态轮训处理数据包、解析协议栈,效率仍是不高。
所以,目前数据库实现内存分离的主流技术方案是基于 RDMA 通信,绕过 CPU 实现远程内存读写。但基于 RDMA 实现共享内存池的方案也有它的局限。
RDMA 共享内存池的局限
(一)读写放大
虽然 RDMA 性能比 TCP 更高,但比起本地 DRAM 内存访问,还是差了不少。所以,现有的基于 RDMA 内存分离数据库通常会设置本地 Buffer Pool,作为远端内存池的近端缓存。
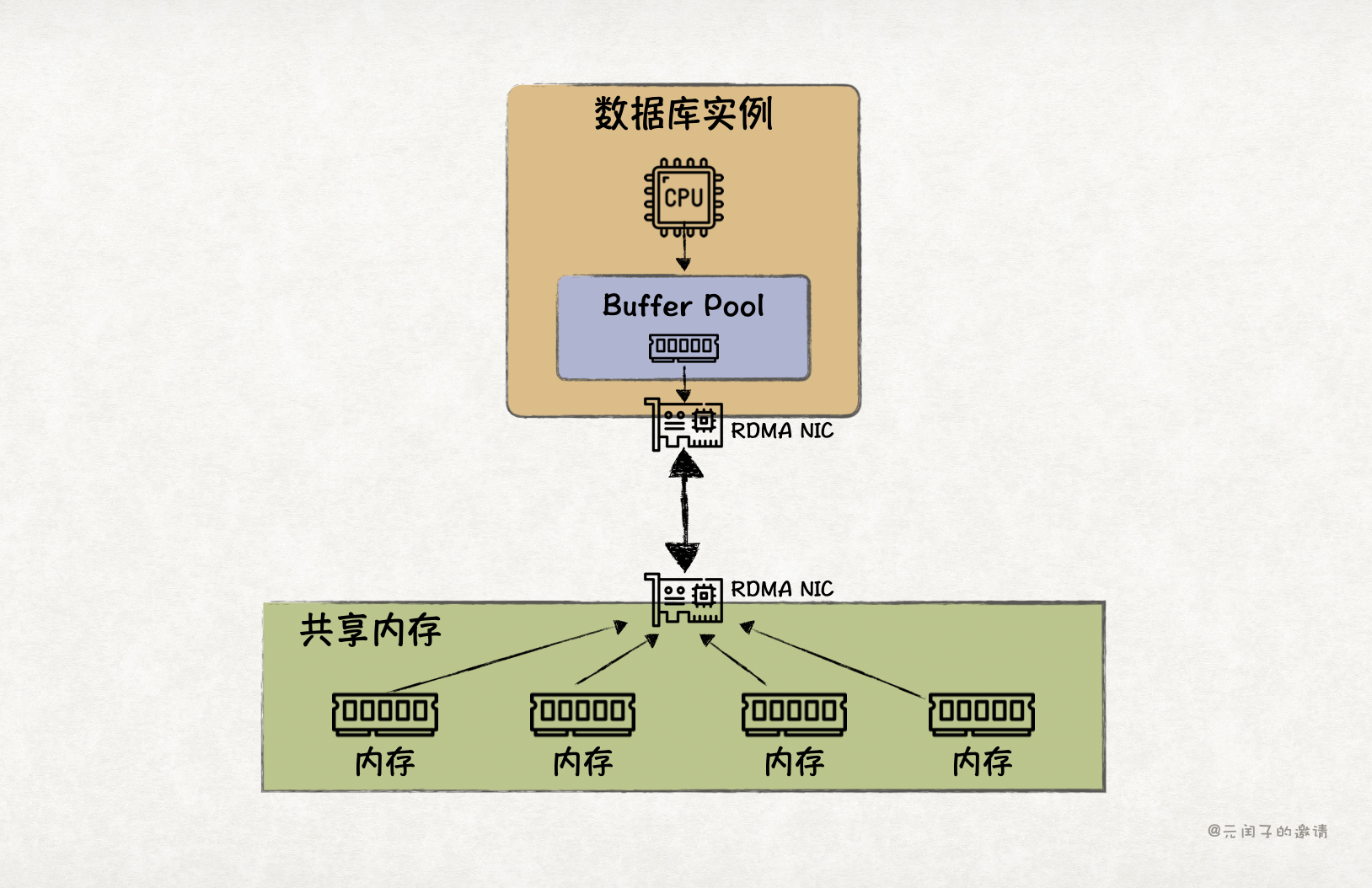
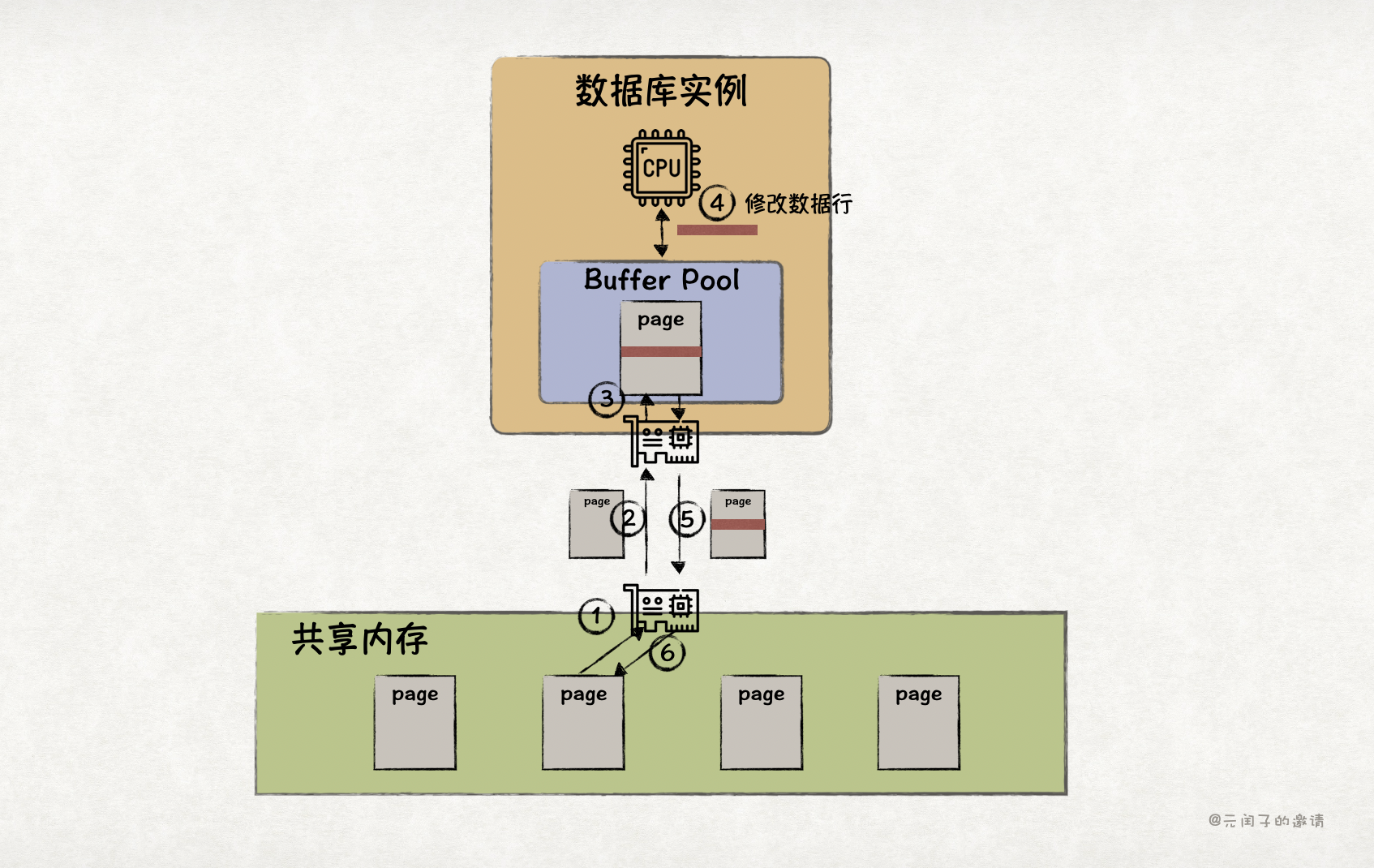
然而,RDMA 属于消息语义,数据库通过 RDMA 读取远端内存池时,会以 page 为粒度,从而带来读写放大的问题。
当本地 Buffer Pool 缓存缺失时,读取 page 中的某一行,需要从远端加载对应的 page 到本地;更新 page 中的某一行,需要先从远端把对应的 page 加载到本地,本地更新后,再将 page 写回到远端。带来了很多非必要的 RDMA 带宽浪费。
(二)故障恢复效率低
当计算节点故障后,存储在远端内存池的 page 仍存在,可以避免从磁盘中恢复所带来的 I/O 瓶颈。但因为数据库对 page 的写发生在本地 Buffer Pool,而本地的这些脏页仍需要传统的恢复流程:从远端内存加载 page 确认 PageLSN(最后修改的 LSN),扫描 redo log 找到恢复 LSN 点,回放 redo log 恢复。
另外,由于故障后 Buffer Pool 被清空,需要一定的预热时间才能恢复故障前的性能水平。
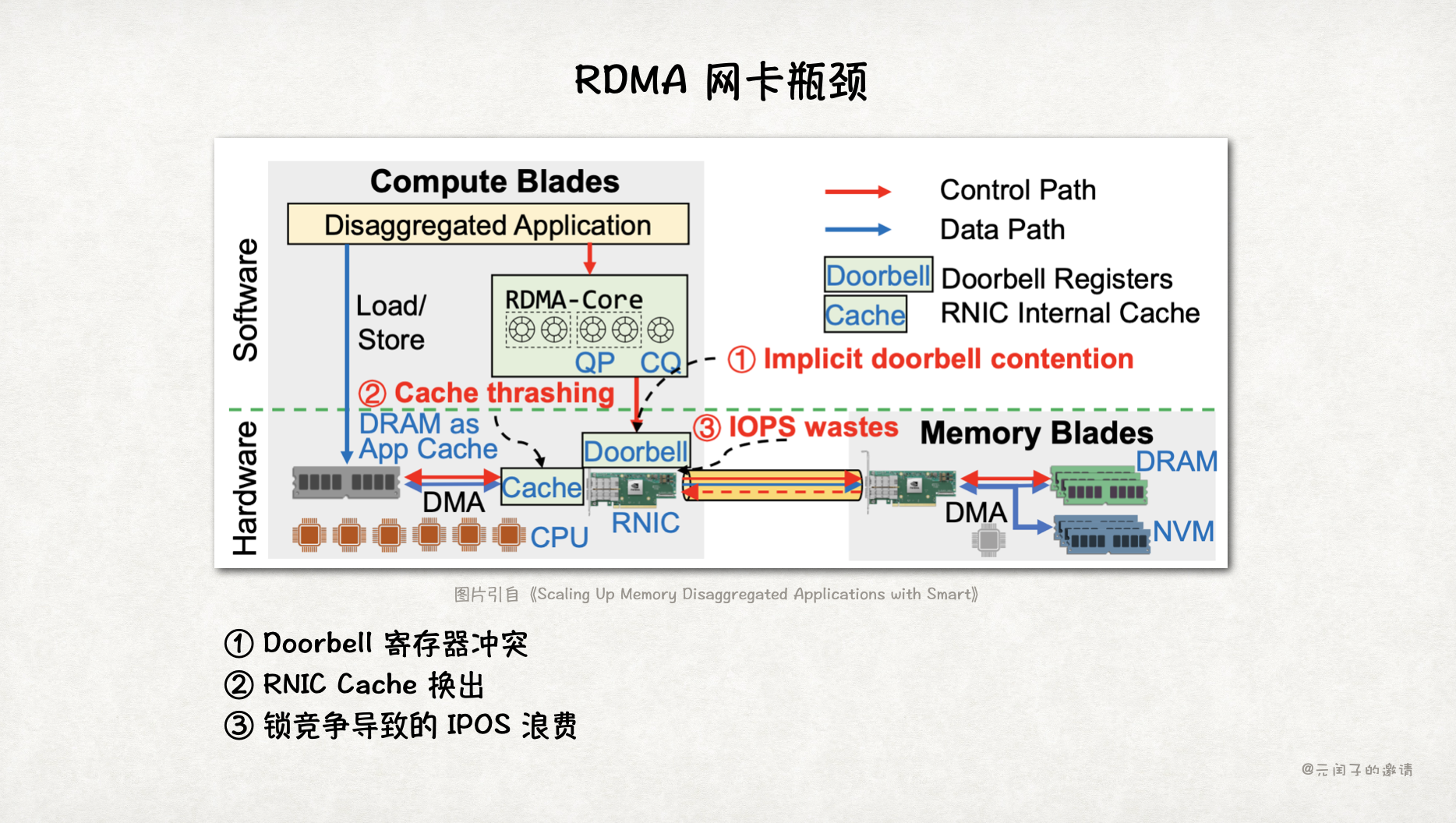
(三)RDMA 网卡瓶颈
RDMA 网卡(RNCI)在高并发场景下容易成为瓶颈,论文《Scaling Up Memory Disaggregated Applications with Smart》显示,当并发超过 32 核时,RDMA 的性能开始下降。主要原因是 RNIC 中 Doorbell 寄存器竞争过大成为瓶颈,RNIC Cache 中的元数据换出到主存等,导致时延进一步增大。
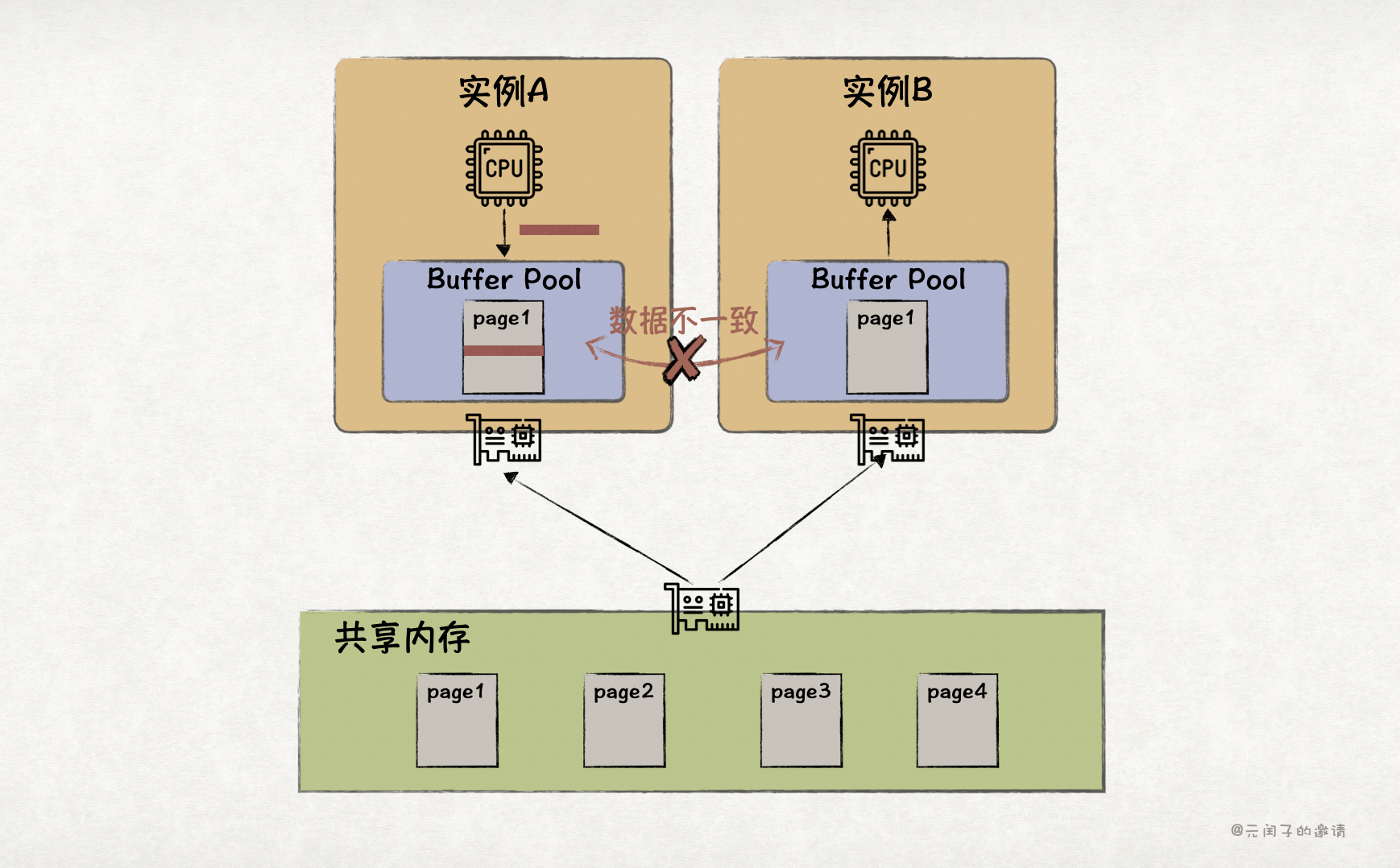
(四)缺少缓存一致性
RDMA 不提供缓存一致性。这意味着在多写架构下,数据库需要建立一套缓存一致性机制。比如,page1 同时存在于节点 A 和节点 B 的本地 Buffer Pool 中,当节点 A 修改了 page1,数据库需要保证节点 B 的 Buffer Pool 以及 CPU Cache 中不能有脏数据。这无疑增加了一定的性能损耗。
针对 RDMA 共享内存池的这些局限,论文基于 CXL 重新实现了共享内存池,实现了倍级性能提升。
CXL 对比 RDMA 的优势
CXL,Compute Express Link,是一种建立在 PCIe 之上的低时延、高带宽的互联协议,能够实现 CPU 与内存、IO设备、XPU 加速芯片的互联。
目前,主流的 CPU 大部分都已经支持了 CXL 协议,比如 Intel 从第四代至强处理器开始、AMD 从 Zen 4 处理处理器开始。
CXL 对比 RDMA 有以下的优势:
- 更低的时延。远端内存数据从 RDMA 到本地内存,需要从 InfiniBand 到 PCIe 的一层协议转换,而且依赖 DMA 完成读写。而 CXL 则支持 CPU 直接读写,从而时延更低。
- 支持 Load/Store 内存语义。CXL 能够让 CPU 像读写本地内存一样,读写远端内存,避免了像 RDMA 一样先把数据读到本地内存再进行处理的流程,性能更高。
- 更简单的编程。RDMA 依赖特有的驱动程序和接口,比如 RDMA core,用户需要进行额外的适配。而 CXL 远端内存可通过
mmap映射到本地内存,实现程序透明读写。 - 支持缓存一致性。CXL 3.0 后支持多节点间的硬件缓存一致性,这意味着程序不再需要单独维护缓存一致性。
PolarCXLMem: 基于 CXL 的共享内存池
基于 CXL 的低时延、高带宽能力,论文提出来了一个新的 CXL 实现的数据库共享内存池方案,PolarCXLMem。并在此基础上构建了效率更高的故障恢复机制,PolarRecv。
要想构建一个共享内存池,第一步就是将多个内存设备连在一起,PolarCXLMem 的硬件架构如下:
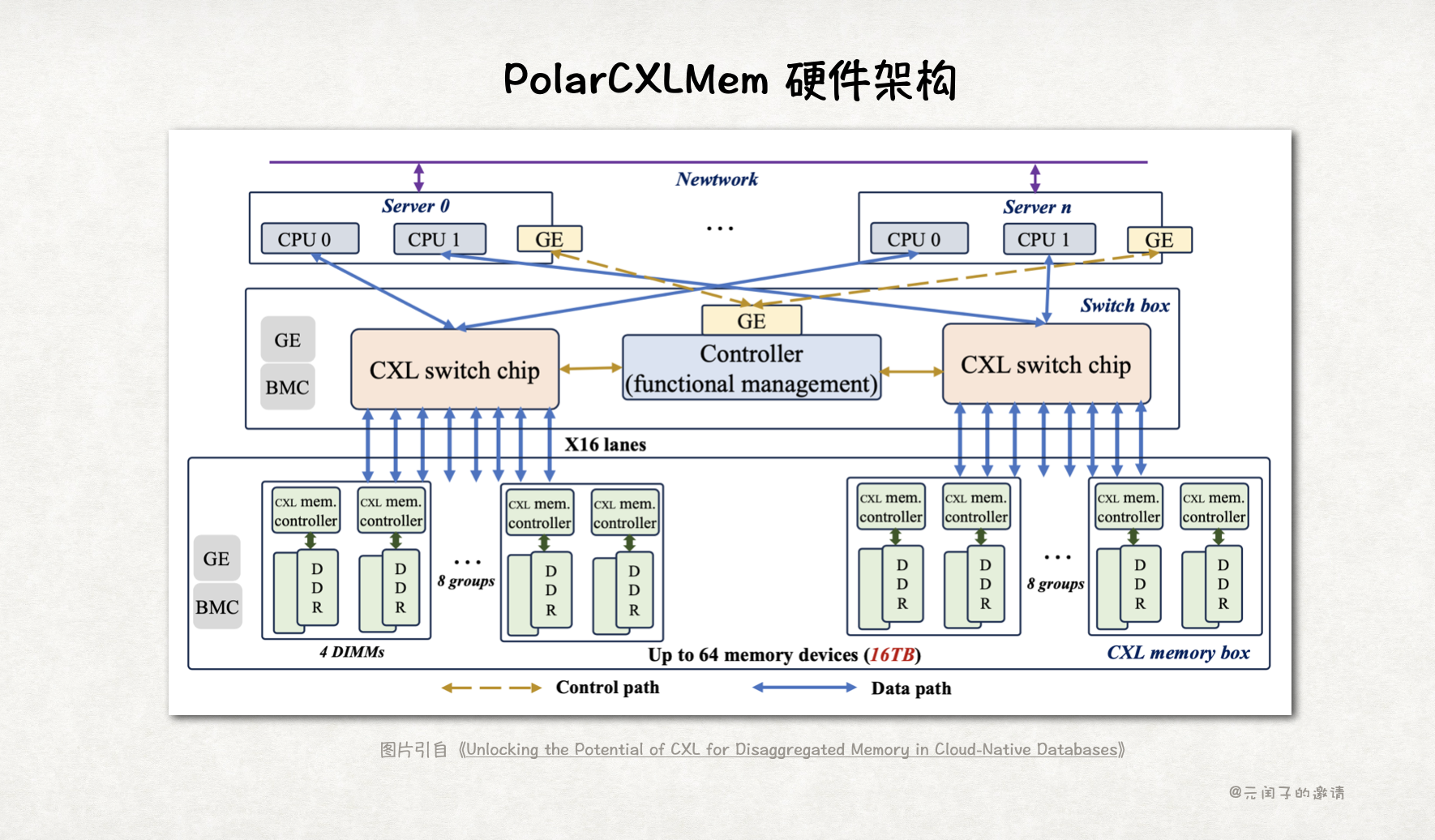
共享内存池由多个 CXL memory box 组成,每个 CXL memory box 内有多个 DDR,每个 DDR 都连接到 CXL mem controller 上。
不同节点的 CPU 通过 CXL switch 连接到内存池中,多个 CXL switch 间由 Controller 协同控制。
数据流走的是 CXL 通道,而控制流走的是传统以太网通道。
软件架构
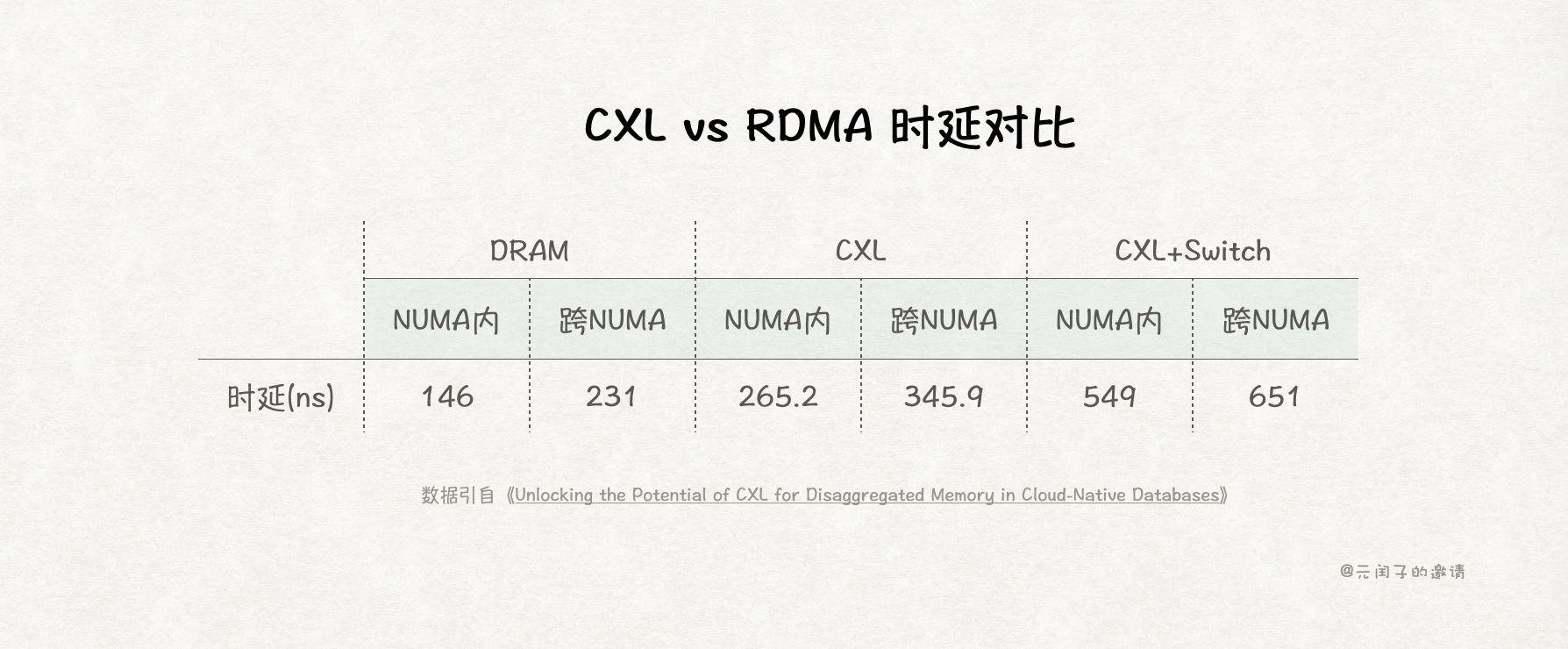
虽然 CXL 的时延和带宽都比 RDMA 更好,但对比本地 DRAM,仍有倍级的差距。
我们很容易想到通过像 RDMA 内存池方案一样,加一层本地 DRAM 缓存来弥补这性能差距。
但这真的需要吗?
论文实验表明,数据库场景,DRAM-Based Buffer Pool 和 CXL-Based Buffer Pool 的吞吐量差不多。
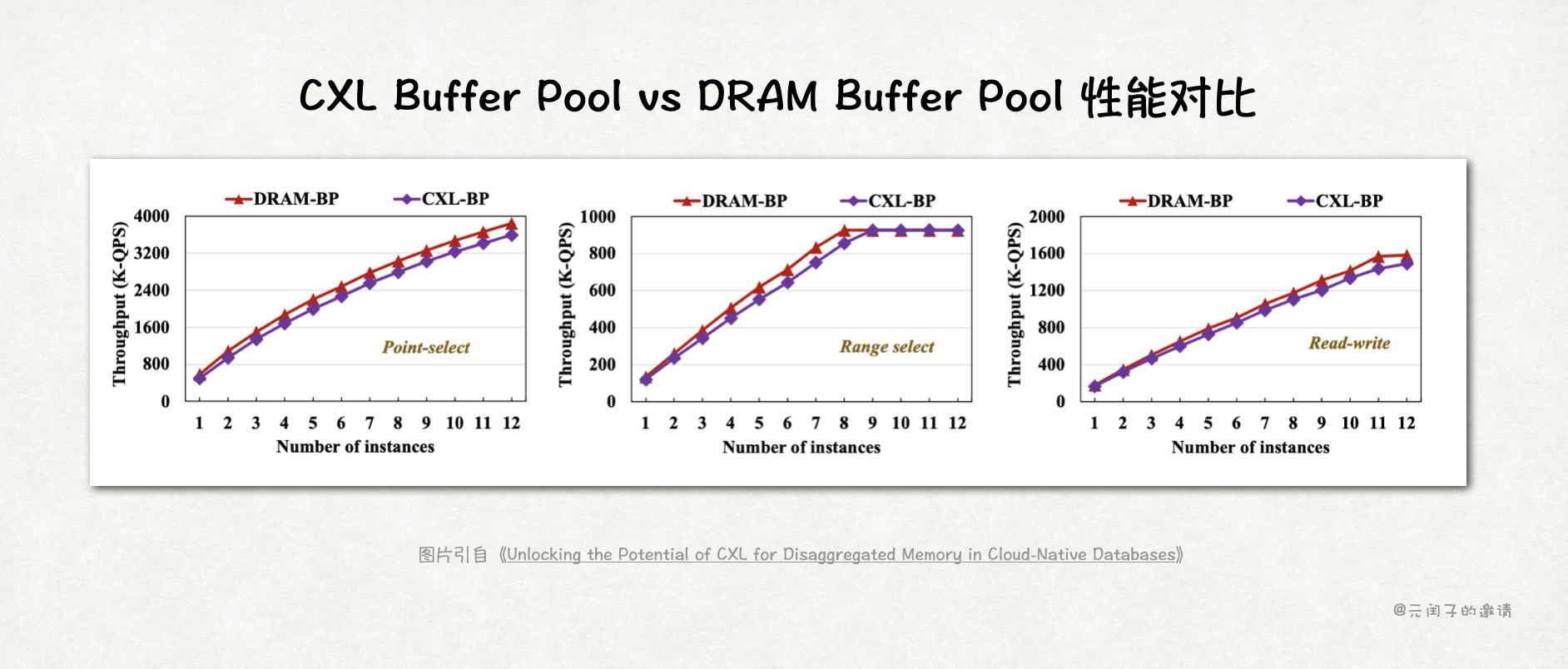
所以,对数据库来说,CXL 内存池已经够了,不用本地 DRAM 缓存。这样既可以节省掉 30% 的 DRAM 成本,又能简化数据流。
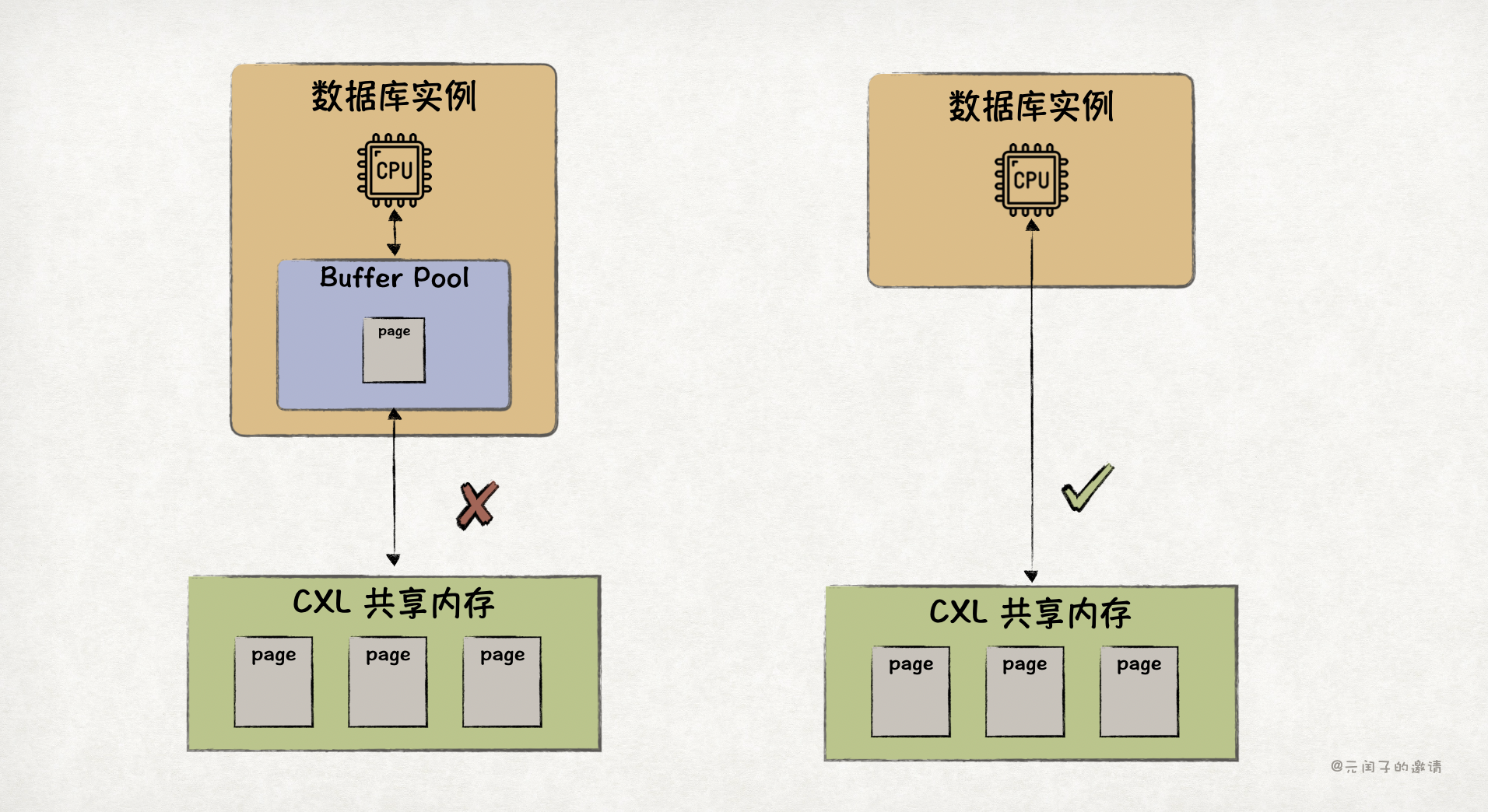
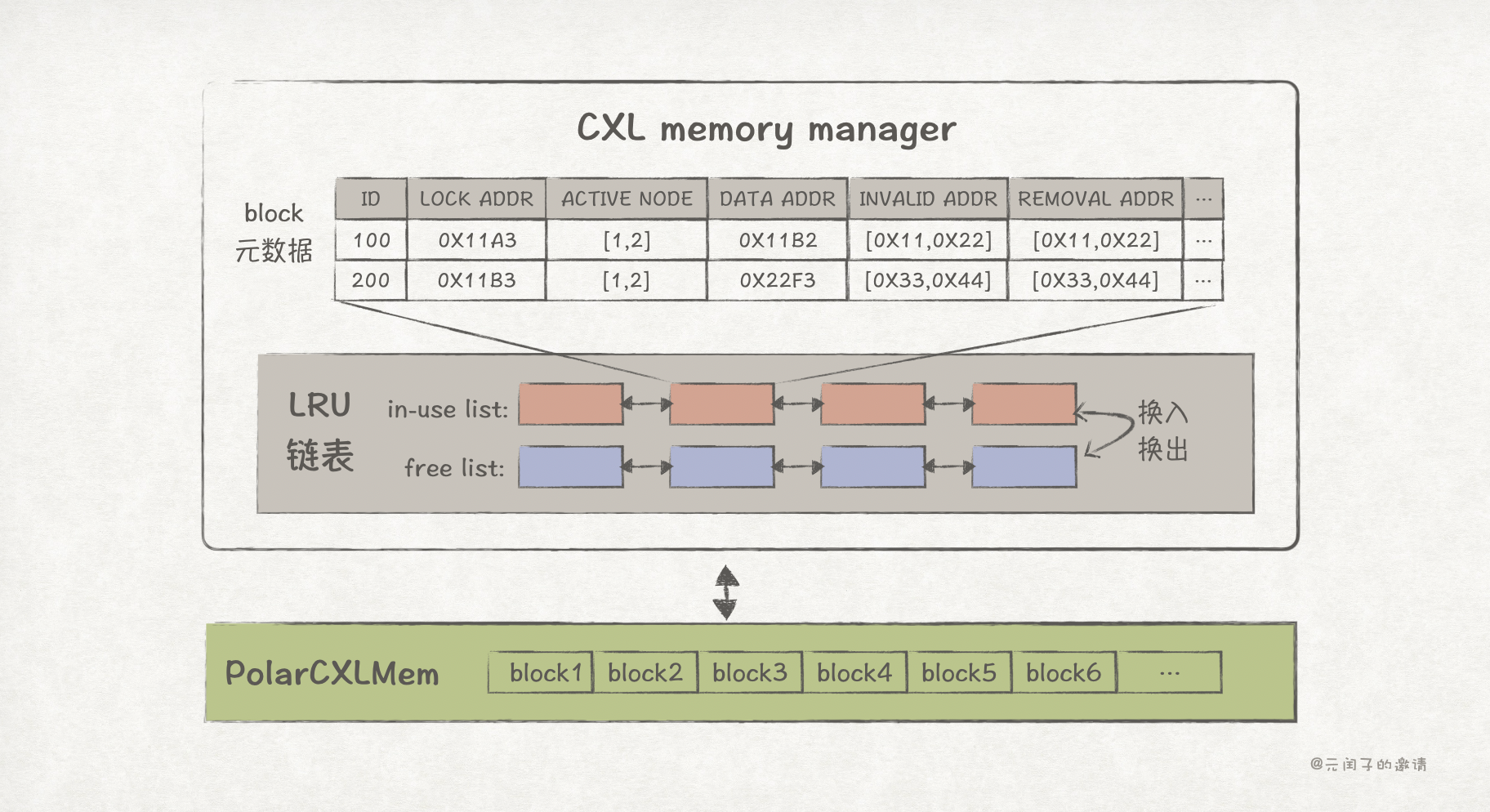
因为 CXL 内存池是全局的,会在不同实例、不同租户间共享,论文设计了一个 CXL memory manager 来统一管理它:
- 数据库节点启动时,CXL memory manager 会为其分配可用的 CXL 内存地址空间。
- CXL 内存池划分成 block 来管理,每个 block 包含 page 数据和对应的元数据。
- page 的元数据包括 page ID,page 所在的 CXL 地址(data addr),正在使用该 page 的节点 ID(active node),脏页标志位所在的 CXL 地址(invalid addr),缓存淘汰标志位所在的 CXL 地址(removal addr)、锁状态(lock state)等信息。
- CXL memory manager 按照 LRU 淘汰策略管理 page,通过 in-use list 和 free list 实现。in-use list 为正在被使用的 block,free list 为空闲的 block,当 page 长时间未被使用时,对应的 block 会从 in-use list 释放回 free list。
为避免数据库节点频繁与 CXL memory manager 交互而形成瓶颈,节点本地 Buffer Pool 会存有一份它自己的元数据。
所以,PolarCXLMem 的整体软件架构是这样的:
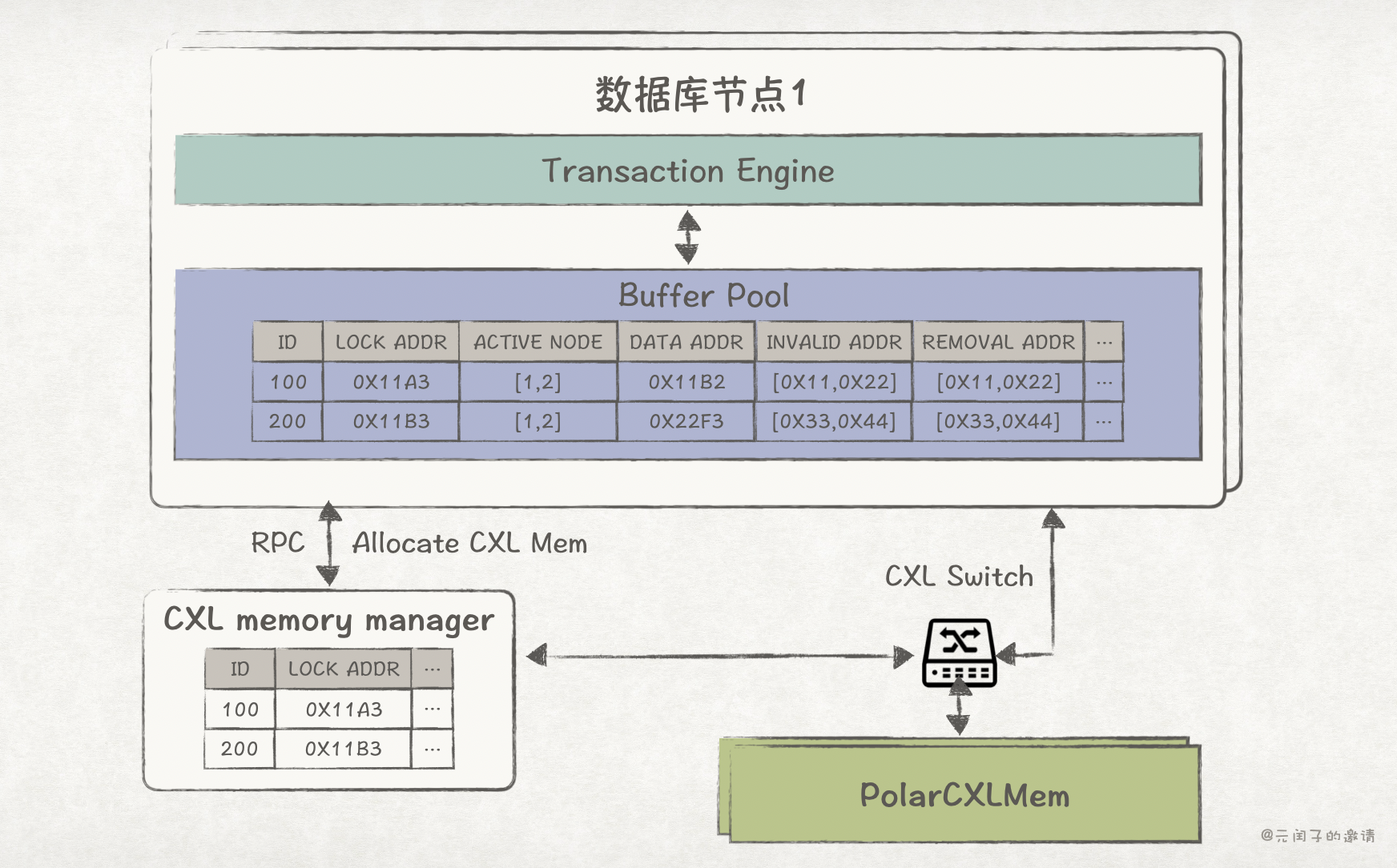
读写数据时,数据库会先从本地 Buffer Pool 中的元数据找到对应 page 在 CXL 内存池中的地址,如果本地元数据缺失,会通过 RPC 请求从 CXL memory manager 中拉取,并更新到本地。
CXL memory manager 收到节点的拉取请求后,首先从 in-use list 中寻找该 page,若存在,则将对应元数据返回给节点;若不存在,则从 free-list 中申请一个 block,更新元数据,然后返回给节点。
节点拿到了 page 的元数据,就可直接通过 CXL 读写远端内存池中的 page 了。
数据一致性机制
共享内存池难免会出现数据一致性的问题,论文的内存池基于 CXL 2.0 实现,硬件缓存一致性需要到 CXL 3.0 才提供,而且尚未成熟。因此,PolarCXLMem 必须实现一套数据一致性的机制。
PolarCXLMem 的数据一致性主要通过元数据中的 lock state 和 invalid 两个标志位来实现。
节点对 page 的读写都必须首先获得锁,避免写冲突或读到脏数据。
当节点完成 page 更新后,会先执行 clflush 指令将 CPU Cache 中被修改的 cache line 刷回到 CXL 内存中,保证 CXL 内存数据是最新的。
随后通知 CXL memory manager 更新所有其他持有该 page 的节点的 invalid 标志位,随后释放锁。
这样,当其他节点读数据前,会先检查 invalid 标志位,若为 1,就会执行 clflush 指令将 CPU Cache 的缓存数据清空,从而保证了数据的一致性。
page 淘汰机制
CXL memory manager 为每个数据库申请的 CXL 内存容量有限,因此必须要一套 page 淘汰机制。
如前文所述,PolarCXLMem 基于 LRU 算法,通过 in-use list 和 free list 来实现。
CXL memory manager 会有个后台线程定期检查 in-use list 中的 page 使用情况,将最近最少使用的 page 回收至 free-list,并更新所有其他持有该 page 的数据库节点的 removal 标志位。
节点在读数据前,也会检查 removal 标志位,若为 1,就会重新向 CXL memory manager 拉取该 page 的最新元数据。
另外,节点侧也会有一个后台进程定期清理 removal 标志位为 1 的元数据条目。
故障恢复机制
基于 RDMA 的内存分离方案在故障恢复时效率不高的原因主要是,本地 Buffer Pool 数据会被清空,从而需要走传统的恢复流程。
而在 PolarCXLMem 中,page 数据和元数据都存储在共享内存池中,有独立的供电系统,即使数据库节点故障也不会受影响,从而绕过了传统低效的故障恢复流程。
论文在 PolarCXLMem 设计了一套新的故障恢复机制,PolarRecv。
当数据库节点故障重启后,针对那些“干净”的 page,节点可以直接从 CXL 内存池中读取,无需回放 redo log 重建,也无需预热。
对于那些“脏”的 page,需要进行单独的处理,分成以下几种情况:
- 写 page 过程中故障。检查是否处于写锁状态来判断,通过回放 redo log 来进行重建。
- B-Tree SMO(页面合并或分裂)过程中故障。B-Tree SMO 由 mini-transaction 保证一致性,这过程中相关的 page 会处于锁状态。恢复过程同上。
- “过新”的 page。这种情况出现在 redo log 未来得及从 redo log buffer 刷盘时发生故障,这样,CXL 内存中的 PageLSN 就会比 redo log 中的 LSN 更新。恢复时,需要舍去 CXL 内存中的 page,通过回放 redo log 来进行重建。
- LRU 链表(in-use list 和 free list)不一致。LRU 链表本身也有一个锁,如果重启时发现 LRU 处于锁状态,则会重建整个 LRU 链表。
最后
本文主要介绍了 PolarCXLMem 的基本实现原理,它最亮点的创新之一,就是打破传统 CPU -> 本地内存 -> 远端内存 的数据流设计,让 CPU 能够直接读写远端内存,既能简化系统设计、又能降低本地内存消耗、还能实现性能不下降,一石三鸟。
虽然 CXL 内存池实现比 RDMA 内存池性能更高,但也不是完美的。
首先是成本问题。虽然论文提到 CXL 方案可以降低 30% 的 DRAM 成本,但 CXL 方案的硬件起建成本更高,包括 CXL 内存模组、CXL Switch 交换机等。这也是 CXL 这些年很难推广开的原因。而 RDMA 硬件在现有数据中心中已经很普遍,可以直接复用。
另外,CXL 内存池虽然有独立的供电系统,但也有故障的可能,而且一旦故障,影响范围更大。
总之,基于 CXL 内存分离的数据库离正式大规模商用还有很长的路要走。
文章配图
可以在 用Keynote画出手绘风格的配图 中找到文章的绘图方法。
参考
[1] Unlocking the Potential of CXL for Disaggregated Memory in Cloud-Native Databases, 阿里云
[2] Scaling Up Memory Disaggregated Applications with Smart, 清华大学
(完)