联邦学习论文分享:Towards Building the Federated GPT:Federated Instruction Tuning
摘要
现有问题
指令微调(instruction tuning)的 LLMs(如 ChatGPT、GPT-4)需要大量高质量、多样化的指令数据。
人工编写的高质量指令获取困难,成本高、可获得性差。
隐私问题进一步限制了数据的收集和使用。
因此,模型的泛化能力受到限制,效果在某些场景下可能不足。
提出的方法:FedIT(Federated Instruction Tuning)
作者首次将**联邦学习(Federated Learning, FL)**用于 LLM 的指令微调。
动机是:用户本地设备上天然存在大量多样化、异质性的文本数据(如日常对话),可以帮助模型学到更自然、真实的语言能力。
通过 FL,可以在不泄露用户隐私数据的前提下,利用这些分散在不同客户端的指令数据来训练模型。
实验与结果
作者使用 GPT-4 自动评估方法,验证了 FedIT 可以利用用户端多样化的指令,提高 LLM 的性能,相比于仅依赖有限的集中数据训练效果更好。
实践贡献
作者开发了一个开源仓库 Shepherd:
为研究者提供了一个便捷的框架,用于在多样化的指令数据下进行联邦微调。
支持易用性、可扩展性和对新算法/配置的灵活集成。
引言
1. 研究背景与问题
LLMs 的现状:一个模型就能完成多种 NLP 任务(如文本生成、翻译、问答等)。
Instruction tuning 的重要性:通过在指令数据上微调,使模型更好地对齐人类意图,提升零样本和少样本能力。
问题与挑战:
获取高质量、多样化的指令数据成本高(时间、人力、资金)。
隐私问题:
日常对话虽有价值,但用户不愿共享。
公司将指令视为核心资产(例如制药公司),不愿公开。
传统的集中式训练方式因此难以大规模利用这些敏感数据。
2. 解决方案:FedIT(Federated Instruction Tuning)
使用 联邦学习 (FL):
客户端先下载全局 LLM,本地利用自己的指令数据更新模型参数,再上传更新结果,由中心服务器聚合。
避免了直接共享原始数据,从而保护隐私。
结合 参数高效微调 (PE-Tuning):
减少训练参数量,降低计算和通信开销。
让资源有限的边缘设备也能参与训练,而不依赖大型云服务器。
3. 主要贡献
首次提出:将联邦学习应用于 LLM 的指令微调(FedIT),解决高质量指令数据难以集中收集的问题。
实证研究:
分析了联邦学习场景下指令数据的异质性。
使用 GPT-4 自动评估验证 FedIT 的有效性,结果显示能提升模型生成质量。
工具支持:开源了 Shepherd 仓库,便于研究者定制、扩展和复现相关实验。
相关工作
大模型指令微调
Instruction Tuning 的发展与现状
Instruction tuning 是一种提升大语言模型(LLM)泛化能力的重要方法,尤其在复杂任务的零样本学习中效果显著。
提到了一些代表性工作:
FLAN:展示了显著的零样本性能。
Instruct-GPT:通过人工标注数据和 RLHF(强化学习+人类反馈)对 GPT-3 进行调优,直接推动了 ChatGPT 和 GPT-4 的成功。
Instruction tuning 的数据来源可以分为两类:
人工标注的任务提示与反馈。
机器生成的指令跟随数据(如 Self-Instruct 方法,教师模型生成指令数据供学生模型学习)。
开源模型 LLaMA 的出现,使得社区可以探索更多开源的 instruction-following LLMs。
文章提出了一个趋势:由于指令数据的敏感性和广泛需求,未来数据共享将趋向 去中心化(decentralization),因此作者尝试在 联邦学习(FL) 框架下解决这一问题。
参数高效微调(PEFT, Parameter-Efficient Fine-Tuning)
微调 LLM 的目标是提升模型能力,同时减少计算和存储开销。
常见的 PEFT 方法包括 LoRA、P-Tuning、Prefix Tuning、Prompt Tuning 等。
作者在其 FL 框架中选择 LoRA,因为它在近期 instruction tuning 的研究中(如 Alpaca-LoRA、Baize)表现较好。
其他方法(如 P-Tuning 等)会留到未来研究。
联邦学习在自然语言处理
联邦学习的基础与研究方向
FL 是一种去中心化的协作式机器学习方法,数据保留在用户设备上。
研究主要集中在解决 隐私 和 数据异质性 问题,并发展了许多高级方法,包括:
优化与聚合改进(提高模型聚合性能)。
鲁棒性增强(防御对抗攻击)。
客户端选择机制(选择合适的用户参与训练)。
个性化能力提升(适应不同用户的数据分布)。
系统效率提升(加速训练与通信)。
FL 在 NLP 任务中的应用
已经应用于多种 NLP 任务,如:
语言建模(Language Modeling)
文本分类(Text Classification)
序列标注(Sequence Tagging)
对话生成(Dialogue Generation)
也出现了支持研究的 开源基准与框架:Leaf、FedNLP、FedML、FedScale、FATE。
预训练模型在 FL 中的重要性与本文贡献
最近研究表明,预训练模型在 FL 中作为初始化 比从零训练效果更好,能够提高 收敛性与鲁棒性,特别是在面对数据异质性时。
作者的研究是 首次将 FL 用于 LLM 的 Instruction Tuning,希望推动 联邦学习和 LLM instruction tuning 两个领域的交叉探索。
联邦指令微调
概览
框架目标与优势
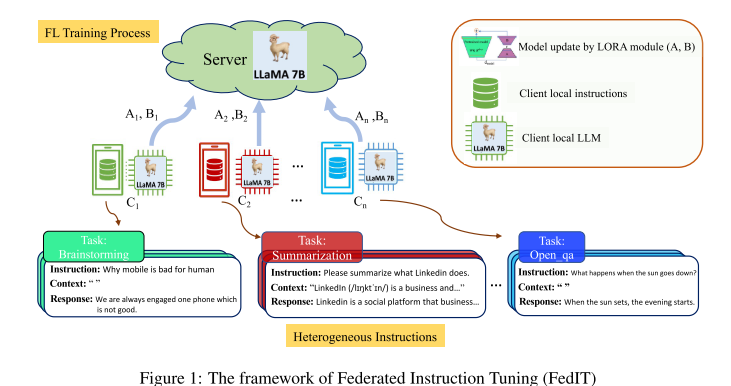
结合 联邦学习 (FL) 和 参数高效微调 (PEFT, LoRA),实现安全、低成本的大语言模型 (LLM) 指令微调。
保证数据隐私:指令数据始终保留在本地设备上,保护敏感信息,鼓励更多用户参与。
数据多样性:来自不同领域和地区的用户能贡献多样化、专业化的指令数据,使模型更鲁棒、更具泛化能力。
提升可扩展性:利用大量分布式的本地设备计算资源,而不是依赖集中式算力。
框架的运行机制

客户端 (local side):
每个客户端分配一个预训练的 LLM。
客户端在本地指令数据集上进行微调,更新的是 LoRA 适配器参数(而不是全部模型权重),从而降低计算和通信开销。
本地训练完成后,把更新的适配器参数发送给服务器。
服务器 (server side):
聚合所有客户端上传的适配器参数。
执行 客户端选择 (client selection),决定下一轮哪些客户端参与训练。
重复这一过程,直到训练收敛。
客户端选择的重要性
在真实场景中,并非所有客户端都能随时参与(可能被其他任务占用)。
客户端选择机制可以基于 数据分布 和 计算资源 来决定参与者,从而提升整体效率和训练效果。
补充
1. 什么是指令微调(Instruction Tuning)?
定义:指令微调是一种让大语言模型(LLM)学会 理解并遵循人类指令 的训练方法。
做法:收集大量 任务指令 + 示例回答(例如“总结这段文字”“把句子翻译成英文”),然后在预训练模型的基础上进行监督微调。
目标:让模型更好地遵循用户的自然语言指令,而不仅仅是完成语言建模(预测下一个词)。
通俗说:预训练的 LLM 会“懂语言”,但不一定会“听话”;指令微调就是教它“听懂并执行人类指令”。
2. 会有参数更新吗?
在指令微调过程中,模型会根据 指令数据集 调整参数,从而学习到如何遵循不同的任务指令。
但参数更新的范围可以不同:
全参数微调(Full fine-tuning):更新模型的所有参数(成本高,资源消耗大)。
参数高效微调(PEFT, e.g., LoRA, Prefix Tuning, Adapter Tuning):只更新一小部分参数(例如新增的低秩矩阵 LoRA 层、前缀向量等),而保持原模型权重冻结不变。这样大大降低计算与存储开销。
普通微调 (fine-tuning):
在特定任务的数据集上(例如情感分类、机器翻译),更新模型参数,使模型适应该任务。
指令微调 (instruction tuning):
把 训练数据集换成了「指令 + 响应」形式的数据。
例如:
指令:“请把下面的句子翻译成英文”
输入:“我喜欢机器学习”
输出:“I like machine learning.”
通过这种训练,模型不仅学会做翻译,还学会“看到指令 → 知道要做什么”。
也就是说,指令微调 ≈ 一种 特殊形式的监督微调,只是数据集换成了 “任务指令” 的形式。
指令数据的异质性
1. 异质性作为优势
在传统联邦学习中,数据的统计异质性(不同客户端数据分布差异)往往是个难题。
本研究指出,在 指令微调场景 下,这种异质性(不同任务、不同语言、不同领域的指令数据)反而可能成为 积极因素:
客户端拥有不同的任务(如 QA vs. 写作),能增加数据的多样性;
多样性有助于模型获得更广泛的能力,提升泛化性。
2. 数据集与实验设计
作者使用了 Databricks-dolly-15k 数据集,该数据集包含多种指令类别(如 brainstorming、classification、QA、generation 等)。
将其划分为 10 个 shard,分别分配给 10 个客户端,模拟联邦学习场景。
分析结果:
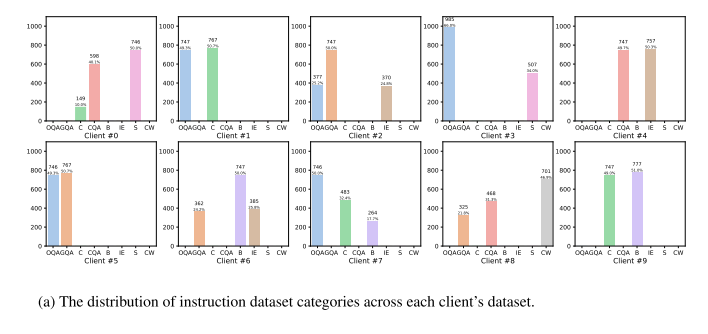
每个客户端的数据类别分布 不均衡,甚至缺失某些类别 → 符合真实世界的情况(不同用户专长不同)。
如果只在本地数据训练,模型的能力会受到限制;而通过 FedIT,可以聚合所有客户端的指令数据,得到更丰富、更全面的训练集。
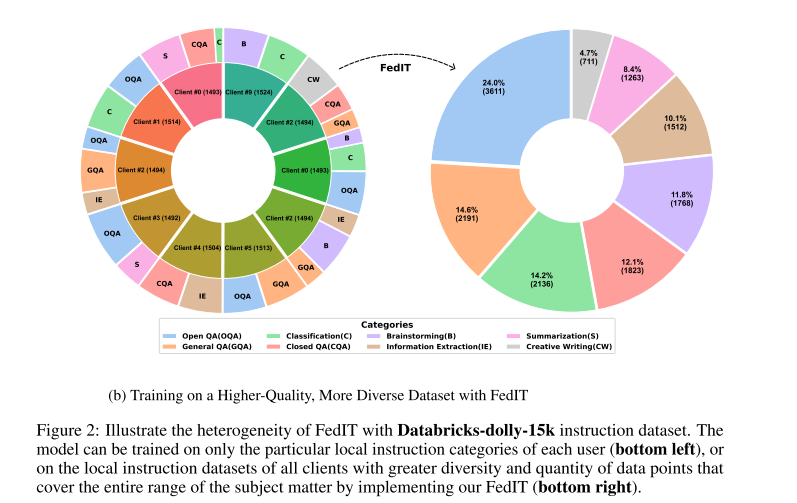
3. 异质性的不同维度
任务类别的差异:不同指令任务对应不同格式、内容(QA 要求事实,写作要求连贯性)。
语言多样性:真实应用中,LLM 面向多语言用户,训练需要关注:
模型能否理解多语言指令;
公平性:低资源语言可能被低估,需要特别关注。
领域差异:如法律、医学领域有特定术语和表达方式,和其他领域差异很大。
其他异质性来源:任务复杂度、歧义性、情绪色彩、文化因素等。
参数高效微调
1. 为什么需要参数高效微调
本地设备(客户端)计算能力有限,无法承担全参数微调 LLM。
因此需要采用 参数高效方法 (PEFT),在有限算力下完成本地训练。
2. LoRA 的方法原理
对预训练权重矩阵
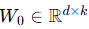
冻结 W0,只训练低秩增量部分 ΔW。
ΔW=BA,其中
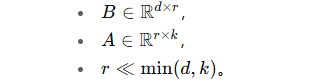
前向传播修改为:
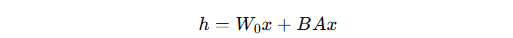
好处:相比全参数微调,可训练参数量大幅减少。
3. 通信效率
客户端训练完成后,只需上传 A 和 B 矩阵,而不是整个 LLM 的权重更新。
这样显著减少了通信开销。
服务器端通过 FedAvg 聚合 各客户端的 LoRA 参数,形成新的全局模型。
4. 推理效率
部署时可以直接合并参数:W0+BA。
推理速度与全参数微调相同,没有额外延迟。
5. 适应系统异质性
LoRA 的配置可根据客户端的资源情况灵活调整:
低资源客户端可以减少参与分解的矩阵元素数量。
或者降低低秩分解的秩 r,进一步减少参数量。
如何在 不同客户端 LoRA 配置不一致 时优化聚合过程,是未来值得研究的方向。
shepherd框架
1. Shepherd 框架的定位与特点
一个 轻量级、可扩展 的研究平台,专门为 联邦指令微调 和其他 NLP 任务设计。
支持多种主流开源 LLM(Alpaca、Vicuna、Pythia、Dolly、Baize、Koala 等)。
研究者可以在其上快速集成新算法和配置,处理大规模数据集。
2. 框架的四个主要组件
Client Data Allocation(客户端数据分配)
模拟真实世界中不同客户端拥有各自数据的情况。
提供两种划分方式:
类别数量不同但数据量相近;
数据量差异显著。
实现模块:
client_data_allocation.py。
Client Participation Scheduling(客户端参与调度)
决定哪些客户端参与训练。
默认是随机选择,未来会扩展为更高效的选择方法(考虑数据和系统异质性)。
模块:
fed_util/sclient_participation_scheduling.py。
Simulated Local Training(本地训练模拟)
模拟每个客户端的本地训练,出于效率考虑,顺序执行 而不是并行执行。
使用 Hugging Face
Trainer进行训练。集成 LoRA (PEFT) 来实现参数高效微调。
提供一个
GeneralClient类,封装了客户端的训练流程:数据准备 (
prepare_local_dataset)构建训练器 (
build_local_trainer)启动训练 (
initiate_local_training)执行训练 (
train)结束训练并保存模型 (
terminate_local_training)
Model Aggregation(模型聚合)
只聚合 LoRA 的可训练参数,减少计算和通信开销。
使用 FedAvg 等聚合方法。
模块:
fed_util/model_aggregation.py。
3. 当前状态与未来计划
目前 Shepherd 提供的是一个 基础、易理解、易修改的 vanilla 版本。
未来计划:
引入更复杂的 客户端选择策略 和 优化算法。
扩展支持更多 指令数据集和 NLP 任务。
增加更真实的 系统模拟功能(计算延迟、通信延迟、带宽限制等),提升实用性。
实验
设置
1. 实验环境与设置
客户端数量:100 个。
数据划分:使用 Shepherd 的 第二种数据划分方法,将 Databricks-dolly-15k 剩余数据划分为 100 份,每份对应一个客户端的数据。
通信轮次:20 轮。
客户端选择:每轮随机选取 5 个客户端(占 5%)参与训练。
本地训练:每个客户端训练 1 个 epoch,在单卡 Nvidia Titan RTX(24GB)上进行。
2. 模型与微调方式
初始化模型:LLaMA-7B。
训练策略:
冻结预训练模型参数,仅训练 LoRA 参数(降低显存占用、提升速度)。
LoRA 设置:
应用于所有线性层。
秩 r=8r = 8r=8。
初始化方式:
A 使用随机高斯分布。
B 初始化为 0(保证 BA 初始为 0)。
优化器:Adam。
训练超参:
batch size = 32
学习率 = 1.5e-4
最大输入序列长度 = 512
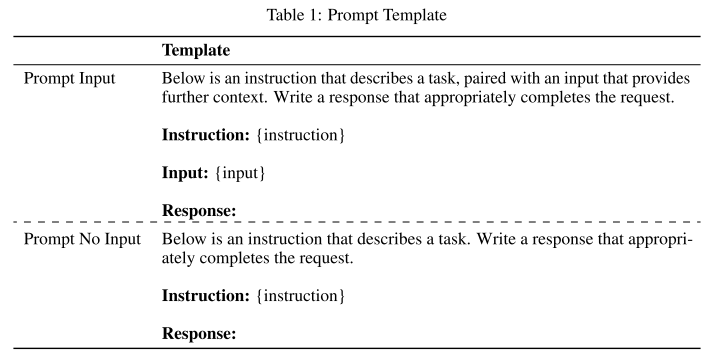
prompt 模板:采用 Alpaca-LoRA 的提示模板(见 Table 1)。
3. 实现与命名
实现工具:使用 Shepherd 框架实现 FedIT。
结果模型命名:Shepherd-7B。
实验指标:模型参数量、训练时间、显存占用(见 Table 2)。

评估
1. 评估方法
借鉴 Vicuna 和 GPT-4-LLM 的做法,用 GPT-4 自动评估 Shepherd-7B 与对照模型的回答质量。
评估数据:从 Vicuna 的评测集里随机抽取 20 个未见过的问题(如反事实问题、女性问题、数学问题等)。
评估流程:
每个模型对同一问题生成一个回答。
GPT-4 逐对比较两个模型的回答,打分范围 1–10。
为降低随机性,每对回答重复打分 3 次,取平均分。
2. 对照模型设置
LLaMA-7B(未微调):作为零微调基线。
Local 模型(3 个):
Local-1:仅在 “brainstorming” 本地数据集上微调。
Local-2:仅在 “closed QA” 数据上微调。
Local-3:在 “classification + brainstorming” 数据上微调。
→ 这些模型代表只依赖单个客户端数据的情况。
Centralized Model:在 完整 Databricks-dolly-15k 数据集上集中微调 1 epoch,被视为理想上界。
3. 结果与分析

Shepherd-7B 明显优于 LLaMA(未微调) → 证明 FedIT 有效。
Shepherd-7B 优于 Local 模型 → 说明 联邦环境下利用多客户端多样化数据 的优势。
Shepherd-7B 略逊于 Centralized Model → 主要原因是:
不同客户端的数据分布差异大。
各地模型学到的指令表示不一致,聚合时存在偏差。
→ 需要更高效的联邦优化和客户端调度方法(如 FA-LD, FedCBS, 贝叶斯采样方法)。
4. 与工业产品对比
Shepherd-7B 及基线模型与 ChatGPT(GPT-3.5-turbo) 比较,采用 GPT-4 自动评估。
结果(见 Figure 3):
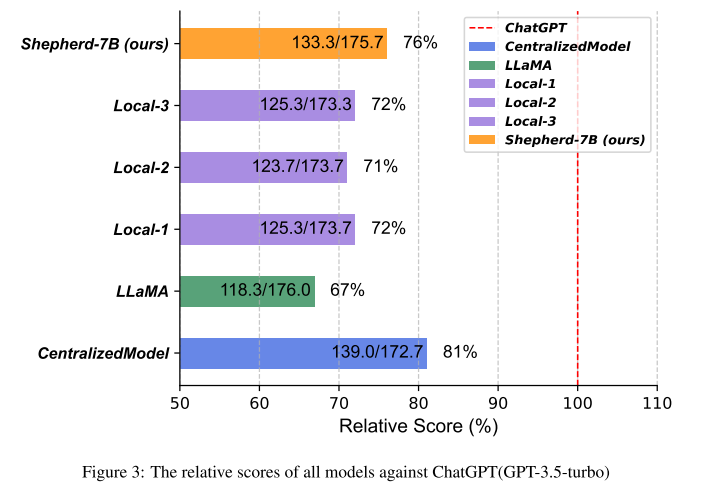
Shepherd-7B 表现优于所有基线模型,仅次于 Centralized Model。
说明该方法在 隐私敏感、难以集中收集指令数据的场景下具有实际应用价值。
案例
1. 案例来源
第一个例子:来自 Vicuna 的 20 个未见问题集。
第二个例子:来自 Databricks-dolly-15k 数据集。
2. 对比分析(例子一:牛顿如果研究生物学会怎样)
Shepherd-7B:回答更准确、更相关,覆盖多个潜在方向(进化论、遗传学、细胞生物学、免疫学、传染病、疫苗)。
Local-3:包含一些无关信息,相关性较差。
Local-2:主要集中在疫苗和疾病治疗,缺少对具体生物学研究领域的展开。
Local-1:因主要训练于“头脑风暴”数据,回答过于浅显,没有涉及到反事实推理所需的历史因果理解。
LLaMA:未微调,回答更弱。
→ 说明:多样化的指令调优让 Shepherd-7B 更具深度和广度。
3. 对比分析(例子二:分类任务)
Shepherd-7B:回答准确,直接解决问题。
ChatGPT(GPT-3.5-turbo):回答错误,还虚假声称进行了网络搜索,影响可靠性。
Local-3:因训练过类似分类指令,也表现良好。
→ 说明:即使对比工业模型,Shepherd-7B 在某些任务上也能更可靠。
4. 关键结论
多样化的 指令异质性 对提升模型能力至关重要。
Shepherd-7B 在许多情况下优于本地模型,也能在部分任务上挑战甚至超越 ChatGPT。
FedIT 能在 数据敏感、不易集中收集 的现实场景中展现价值,拓展了 LLM 的应用前景。
讨论
1. Computation and Communication Overhead(计算与通信开销)
问题:
LLM 参数量巨大,导致在 FL 场景下需要 超大规模的通信(GB 级参数传输),远超可接受范围。
客户端往往 算力不足,无法完整微调 LLM,也难以存储多个任务实例。
解决思路:
引入 参数高效调优(PEFT)方法(如 Prefix-tuning、LoRA、BitFit),降低计算和通信开销。
未来研究可专门为 FL 设计更适合的 PEFT 方法。
2. Privacy(隐私问题)
优势:FL 天然能在隐私敏感的 NLP 应用中保护数据(如医疗文本、金融分类),结合 LLM 更具潜力。
挑战:
恶意客户端可能注入“有害指令”,污染模型,引发偏见或降低性能。
未来方向:
开发 鲁棒聚合方法 与 异常检测机制,以识别并剔除异常或恶意客户端。
3. Personalization(个性化需求)
问题:
客户端间指令数据差异大(语言多样性、领域专属、任务复杂度、情感语气、文化差异),单纯参数平均难以满足个性化需求。
例如多语言应用中,低资源语言难以得到公平表现。
潜在方案:
元学习、小样本学习、个性化嵌入(personal embeddings / preference embeddings),在共享上下文的基础上兼顾个体需求,避免大量反向传播开销。
4. Defense Against Attacks(对抗攻击)
问题:
研究表明可以从语言模型的梯度中恢复文本,或因模型“记忆”而泄露训练数据。
在 FL 中,这一风险更严重,恶意用户可能利用该漏洞提取本地敏感文本。
现有方法:
梯度裁剪 / 修剪、差分隐私 SGD(DPSGD)。
但这些方法通常导致模型效用大幅下降。
未来方向:
针对文本特性设计更高效的防御机制,兼顾隐私与性能。