网络通信 IO 模型学习总结基础强化
网络通信概念
网络通信因为要处理复杂的物理信号,错误处理等,所以采用了分层设计。
为什么要采用分层设计?
1. 每层可以独立开发,测试和替换;
2. 发生问题也可以快速定位到具体层次;
3. 协议标准化,不同厂商设备可通过标准协议实现互操作;
4. 降低复杂度,将通信功能拆解为独立的功能模块;
主流分层模型对比
| 模型 | 层次数 | 典型应用场景 | 特点 |
|---|---|---|---|
| OSI七层模型 | 7层 | 理论教学、复杂网络设计 | 严格分层,功能细分(如会话层管理会话,表示层处理加密) |
| TCP/IP四层模型 | 4层 | 实际网络部署(如互联网) | 合并OSI的会话层、表示层到应用层,更贴近实际实现 |
| 五层模型 | 5层 | 教材简化教学 | 合并物理层和数据链路层为“网络接口层”,保留OSI的核心逻辑 |
OSI七层模型
一、物理层
- 功能:传输原始比特流(0和1),定义物理介质的电气、机械和过程规范(如电压、电流、电缆类型、连接器形状等)。
- 设备:中继器、集线器、网线、光纤。
- 示例:通过网线传输电信号,或通过光纤传输光信号。
二、数据链路层
- 功能:
- 将比特流组装成帧(Frame),添加帧头和帧尾用于同步和错误检测。
- 通过MAC地址实现节点间通信,管理物理寻址。
- 提供流量控制和差错纠正(如CRC校验)。
- 设备:交换机、网桥、网卡。
- 协议:Ethernet(以太网)、Wi-Fi(IEEE 802.11)、PPP(点对点协议)。
- 示例:交换机根据MAC地址将数据帧转发到目标设备。
三、网络层
- 功能:
- 通过IP地址实现逻辑寻址和路由选择,确定数据包从源到目标的最佳路径。
- 处理分组转发和拥塞控制。
- 设备:路由器。
- 协议:IP(网际协议)、ICMP(互联网控制报文协议)、ARP(地址解析协议)。
- 示例:路由器根据IP地址将数据包从一个网络转发到另一个网络。
四、传输层
- 核心功能:提供端到端的可靠或不可靠传输,管理数据分段和重组。
- 关键协议:
- TCP(传输控制协议):
- 面向连接:传输前需建立三次握手(SYN→SYN-ACK→ACK),断开时需四次挥手(FIN→ACK→FIN→ACK)。
- 可靠传输:通过确认机制、重传和流量控制确保数据无差错、不丢失、按序到达。
- 应用场景:文件传输(FTP)、网页浏览(HTTP/HTTPS)、邮件(SMTP)。
- UDP(用户数据报协议):
- 无连接:无需建立连接,直接发送数据包。
- 不可靠传输:不保证数据顺序或到达,但开销小、速度快。
- 应用场景:实时通信(视频通话、在线游戏)、DNS查询、直播流。
- TCP(传输控制协议):
- 端口号:传输层用16位端口号标识应用进程(如HTTP默认端口80)。
五、会话层
- 功能:
- 建立、管理和终止应用程序间的会话(连接)。
- 提供同步点(Checkpoint),确保数据传输的完整性。
- 协议:RPC(远程过程调用)、SQL(数据库查询)。
- 示例:通过会话层保持用户登录状态,直到主动退出。
六、表示层
- 功能:
- 数据格式转换(如ASCII与Unicode编码互换)。
- 数据加密/解密(如HTTPS中的TLS/SSL)、压缩/解压。
- 协议:JPEG(图片压缩)、MPEG(视频压缩)、SSL/TLS(安全传输)。
- 示例:浏览器将加密的HTTPS数据解密后显示为网页。
七、应用层
- 功能:直接为用户应用程序提供网络服务接口。
- 协议:
- HTTP/HTTPS:网页传输。
- FTP/SFTP:文件上传/下载。
- SMTP/POP3/IMAP:邮件收发。
- DNS:域名解析(将域名转为IP地址)。
- Telnet/SSH:远程登录。
- 示例:浏览器通过HTTP协议访问网站,邮件客户端通过SMTP协议发送邮件。
TCP/IP 四层模型
将OSI七层模型中的物理层、数据链路层合并为网络接口层,并将会话层、表示层、应用层合并为应用层,最终形成四层结构(网络接口层、网络层、传输层、应用层)。
为什么要进行这种合并?
1. 物理层、数据链路层功能高度耦合
2. 合并会话层、表示层、应用层大大简化了开发流程,会话管理和数据压缩功能可直接在应用层升级,无需修改底层协议。
RPC属于哪一层?
根据上面的介绍和前文RPC框架基本概念可以得出一个结论:在OSI七层协议中,RPC跨越了传输层,表示层,会话层和应用层;而在TCP/IP协议中,RPC跨越了传输层和应用层。
Socket套接字
socket是网络编程的核心抽象,屏蔽了底层网络协议的复杂性,为应用程序提供了统一的接口来发送和接收数据。属于应用层和传输层之间的编程接口。
各大操作系统的内核实现了Socket的底层逻辑,然后程序员就可以通过这些接口(API)来使用网络或进程间的通信功能,无需直接操作底层硬件或者协议细节,这也就是我们说的网络编程。
IO基本概念
什么是 IO?
指的是计算机内存和外部设备之前拷贝数据的过程。
网络 I/O
指内存与远程主机(通过网卡和网络介质)之间的数据传输
| 传统I/O | 网络I/O | 共性 | |
|---|---|---|---|
| 数据流向 | 内存 ↔ 本地存储设备 | 内存 ↔ 远程主机(通过网络) | 均涉及内存与外部实体的数据交换 |
| 核心操作 | 读写磁盘块 | 发送/接收数据包 | 均通过系统调用触发数据流动 |
| 优化目标 | 减少磁盘寻道、拷贝次数 | 降低延迟、提高吞吐量 | 均围绕“高效数据交换”展开 |
| 术语来源 | 输入/输出(Input/Output) | 继承自传统I/O的抽象命名 | 统一描述所有“内存与外部交互”的场景 |
关键步骤
网络数据到达网卡后要拷贝到内核空间(操作系统内核运行的内存区域,拥有最高权限,可直接访问硬件资源(如CPU、内存、设备等))
网络数据再从内核空间拷贝到用户空间(用户程序运行的内存区域,权限较低,无法直接访问硬件或内核数据)
因此,根据读写数据时候的不同表现形式,就会衍生出不同的IO模型。
在Linux操作系统中,根据数据从内核空间到用户空间的拷贝方式及进程的阻塞状态,主要存在以下五种I/O模型:
- 同步阻塞IO
- 同步非阻塞IO
- IO多路复用 (当前最流行)
- 信号驱动IO
- 异步IO
关于基本名词的解释:
同步:应用程序想要获取数据需要主动调用系统函数获取
阻塞:应用程序调用系统函数获取数据的时候还没有数据要等待数据的到来
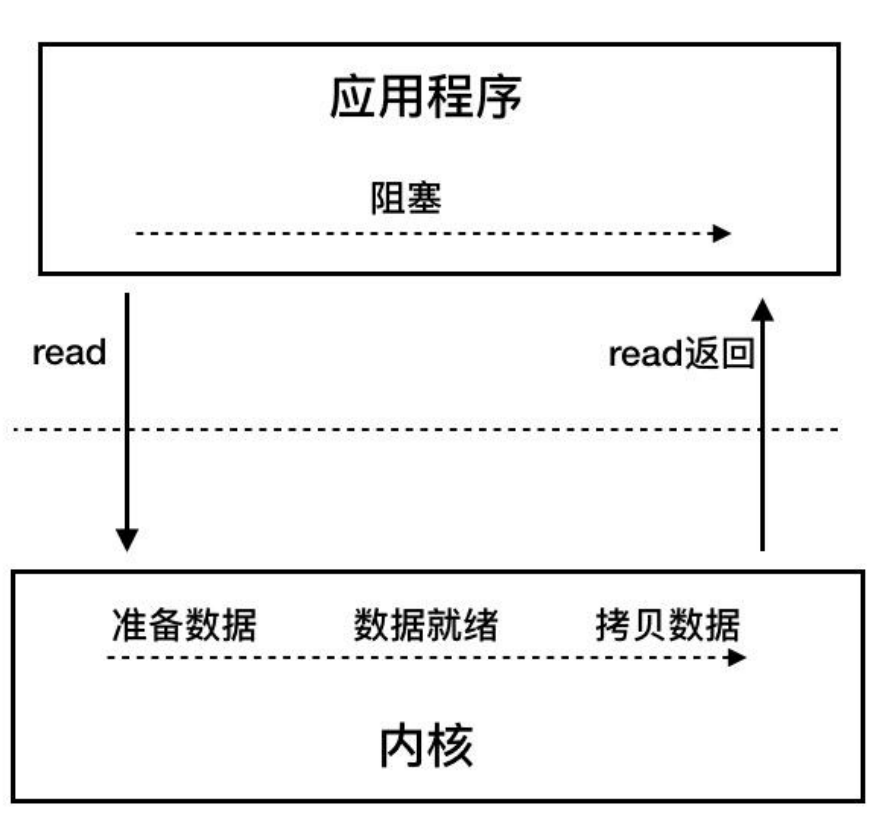
同步阻塞IO
服务端代码
public class BioBlock {public static void main(String[] args) {ServerSocket serverSocket = null;BufferedReader in = null;BufferedWriter out = null;try {// 创建服务端Socket,绑定接口 开启监听serverSocket = new ServerSocket(9999);// socket手动获取一个客户端连接final Socket socket = serverSocket.accept();in = new BufferedReader(new InputStreamReader(socket.getInputStream()));out = new BufferedWriter(new OutputStreamWriter(socket.getOutputStream()));String line = in.readLine();if (line == null){return ;}out.write("hello client" + socket.getInetAddress() + " i am server");out.flush();} catch (IOException e) {throw new RuntimeException(e);}}
}
客户端代码
public class BioClient {public static void main(String[] args) {Socket socket = null;BufferedReader in = null;BufferedWriter out = null;try {// 客户端Socket 通过ip+端口找到服务器socket = new Socket("127.0.0.1",9999);in = new BufferedReader(new InputStreamReader(socket.getInputStream()));out = new BufferedWriter(new OutputStreamWriter(socket.getOutputStream()));out.write("hello server,i am client! \n");out.flush();String line = in.readLine();System.out.println("msg from server:" + line);} catch (UnknownHostException e) {throw new RuntimeException(e);} catch (IOException e) {throw new RuntimeException(e);}}
}可以看到,服务端每次接收到一条信息,都需要阻塞等信息读取才能接收其他客户端发来的信息,很不方便,效率很低。
改进方法为每次服务端接收到一个请求,就开辟一个线程来接收客户端发来的信息。
改进代码如下:
服务端代码
public class NewBioBlock {public static void main(String[] args) {ServerSocket serverSocket = null;BufferedReader in = null;BufferedWriter out = null;try {// 创建服务端Socket,绑定接口 开启监听serverSocket = new ServerSocket(9999);while(true){Socket socket = serverSocket.accept();new Thread(new BioClientThread(socket)).start();}} catch (IOException e) {throw new RuntimeException(e);}}
}
客户端
public class BioClientThread implements Runnable{Socket socket = null;BufferedReader in = null;BufferedWriter out = null;BioClientThread(Socket socket){this.socket = socket;}@Overridepublic void run() {try {in = new BufferedReader(new InputStreamReader(socket.getInputStream()));out = new BufferedWriter(new OutputStreamWriter(socket.getOutputStream()));while(true){String line = in.readLine();if (line == null){return ;}out.write("hello client" + socket.getInetAddress() + " i am server");out.flush();}} catch (IOException e) {throw new RuntimeException(e);}}
}
可以发现还是有一个问题,就是客户端的并发数与后端的线程数是1:1,如果连接量增大,服务器压力就会过大,甚至会发生堆栈溢出的情况;
就算采用了线程池也无法解决改问题,因为如果连接没有断开改线程会一直占用,不能给其他客户端建立连接。
这种情况只适合点对点的情况,对并发数要求不高。
同步非阻塞IO
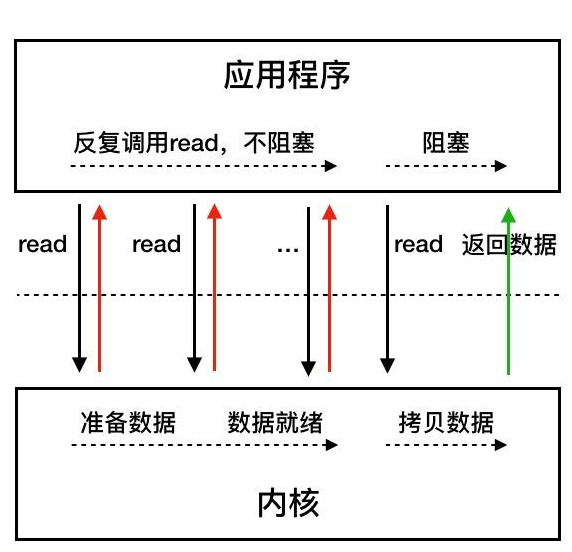
相比于同步阻塞IO,同步非阻塞IO在应用程序调用read等系统函数获取数据但是还没有数据的时候,直接返回,而不是等待数据的到来。
注意同步非阻塞在没有数据到来的情况下直接返回,那么数据到来后又怎么办呢,所以同步非阻塞IO需要在应用程序层做一个read调用轮询操作。
public class NioServer { // 定义服务器类public static void main(String[] args) { // 程序入口try {// 1. 创建服务端通道(相当于开了个门面)ServerSocketChannel serverSocketChannel = ServerSocketChannel.open();// 2. 绑定9999端口(门面挂上9999号招牌)serverSocketChannel.bind(new InetSocketAddress(9999));// 3. 设置非阻塞模式(店员不会傻等客人,而是同时看多个门)serverSocketChannel.configureBlocking(false);// 4. 创建多路复用器(相当于监控摄像头)Selector selector = Selector.open();// 5. 注册连接事件(监控摄像头对准9999门面,发现有人来就亮灯)serverSocketChannel.register(selector, SelectionKey.OP_ACCEPT);// 6. 事件轮询(监控室24小时值班)while (true){// 7. 等待事件发生(监控画面出现动静)selector.select();// 8. 获取所有触发事件的钥匙(拿到所有亮灯的监控画面)Iterator<SelectionKey> iterator = selector.selectedKeys().iterator();while (iterator.hasNext()){// 9. 取出第一把钥匙SelectionKey selectionKey = iterator.next();// 10. 处理完要销毁证据(避免重复处理)iterator.remove();// 11. 根据钥匙类型处理具体事件processSelectedKey(selectionKey,selector);}}} catch (IOException e) {// 12. 异常处理(出问题直接撂挑子)throw new RuntimeException(e);}}private static void processSelectedKey(SelectionKey selectionKey, Selector selector) throws IOException {// 13. 检查钥匙是否有效(门是否被拆了)if (selectionKey.isValid()) {// 14. 判断是否是新连接事件(有人推门进来)if (selectionKey.isAcceptable()) {// 15. 获取门面对应的通道ServerSocketChannel serverSocketChannel = (ServerSocketChannel) selectionKey.channel();// 16. 接受新连接(把客人迎进门)SocketChannel socketChannel = serverSocketChannel.accept();// 17. 设置非阻塞(客人不会堵住门口)socketChannel.configureBlocking(false);// 18. 注册读事件(给客人递上意见簿)socketChannel.register(selector, SelectionKey.OP_READ);return; // 处理完连接事件直接返回}// 19. 判断是否有数据可读(客人写意见了)if (selectionKey.isReadable()) {// 20. 获取客户端通道SocketChannel socketChannel = (SocketChannel) selectionKey.channel();// 21. 准备意见簿(1024字节的缓冲区)ByteBuffer readBuffer = ByteBuffer.allocate(1024);// 22. 读取意见(可能客人写了0-1024字节)int read = socketChannel.read(readBuffer);// 23. 确实有内容才处理if (read > 0 ) {// 24. 翻到意见页(切换缓冲区为读模式)readBuffer.flip();// 25. 撕下意见页(复制数据到字节数组)byte[] bytes = new byte[readBuffer.remaining()];readBuffer.get(bytes);// 26. 破译客人笔迹(转为字符串)String msg = new String(bytes, Charset.defaultCharset());System.out.println("服务端收到来自客户端的数据:" + msg);// 27. 准备回信(256字节的回复缓冲区)ByteBuffer sendBuffer = ByteBuffer.allocate(256);sendBuffer.put("hello nio client ,i am nio server \n".getBytes(StandardCharsets.UTF_8));// 28. 翻到回信页(切换为读模式)sendBuffer.flip();// 29. 塞给客人(发送回复)socketChannel.write(sendBuffer);}return;}}}
}ByteBuffer 的直接缓冲区(Direct Buffer)是在操作系统管理的物理内存中分配空间,而不是在JVM堆内存开辟空间,这样可以通过减少用户空间与内核空间之间的数据拷贝次数,显著提升 I/O 操作的性能。
需要应用程序做轮询调用,有系统开销并且不会释放线程资源。
IO多路复用
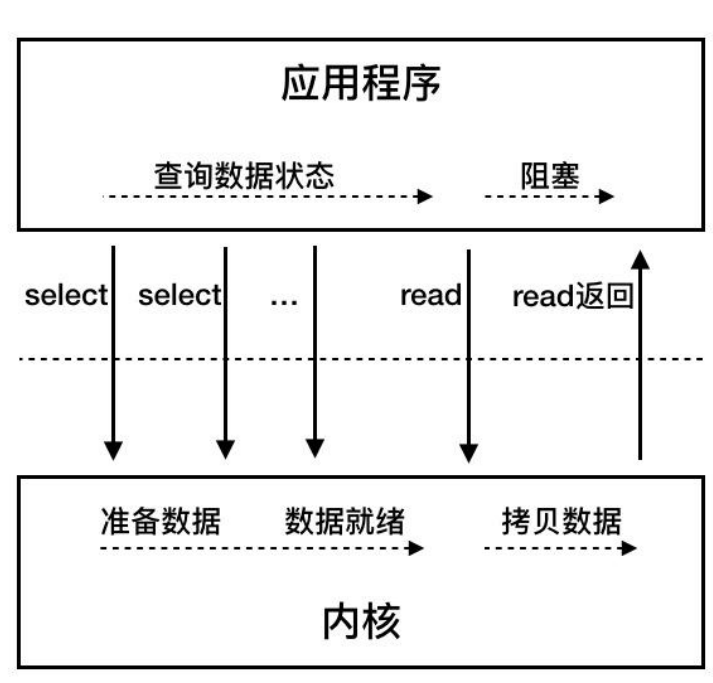
同步阻塞IO和同步非阻塞IO有一个问题,就是不知道什么时候数据会到来,需要不停的检测。而多路复用IO能提前知道Socket是否有数据到来,有再调用系统函数read。
简而言之IO多路复用其实在思想上和同步非阻塞IO有相似之处,但是IO多路复用将事件检测逻辑下沉到内核,减少用户态与内核态的上下文切换,性能自然更高。
IO多路复用模型下提供了几种不同的系统调用来检测socket是否有数据到来:
- select
- poll
- epoll
- kqueue
select
平台移植性很好
通过轮询方式检查一组文件描述符(fd)的状态(可读、可写、异常)。
用户态需传递三个文件描述符集合(readfds、writefds、exceptfds),内核遍历集合并返回就绪的描述符数量。
缺点:
1. 可以监听的fd数量有限,默认是1024个。
2. 需要维护一个存放大量fd的数据结构,调用select时这些数据从用户空间拷贝到内核空间开销大,但是对比同步非阻塞IO就快很多了,因为只需要拷贝fd_set集合一次到内核态,再在内核态遍历fd_set集合。
3. select调用返回后需要线性扫描fd_set来获取就绪的fd,fd数量增多遍历速度就慢。
poll
poll调用 和 select 调用差不多,poll是对select的改进,理论上可监听的fd没有select那样的数量限制(动态数组),而且针对于fd_set遍历事件复杂度更加低,更高效。
epoll
在linux平台上面十分成熟,但移植到其他平台有障碍
可监听的fd数量理论上没有限制,支持fd数量上限是最大可以打开文件的数量,可以查看/proc/sys/fs/file-max
进一步减少了从内核态到用户态的拷贝次数,也不需要维护一个fd集合,不需要在用户空间和内核空间来回拷贝全量fd,应用不需要线性遍历所有fd来获取就绪的fd,epoll_wait返回的就是已就绪的,复杂度大大降低,性能提高。
采用红黑树管理所有注册的文件描述符,支持高效插入、删除和查找。通过 epoll_ctl 函数一次性注册文件描述符,避免重复拷贝,仅在文件描述符状态变化时更新内核数据结构。
异步IO
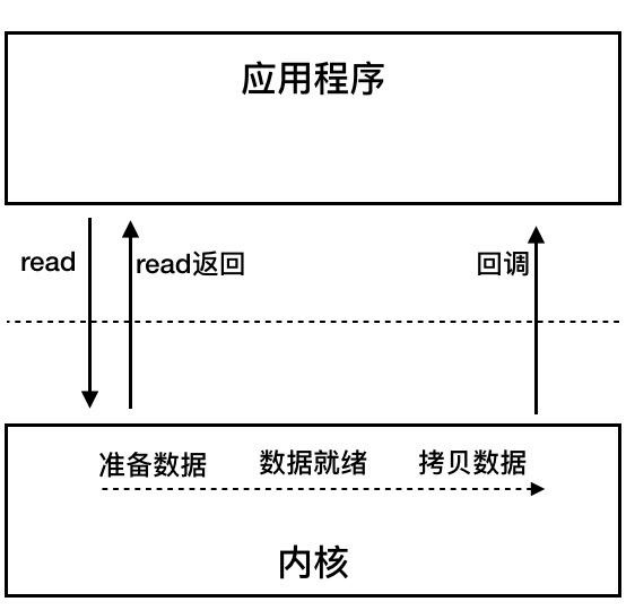
同步IO指的是socket缓冲区有数据后应用主动调用read等系统函数来完成从内核缓冲区到用户空间的拷贝,并且拷贝过程中应用线程是阻塞住的。
上面介绍的三种模型都属于同步IO
异步IO(AIO)指的是整个过程均由内核完成,即内核等待数据到来,内核读取数据到内核缓冲区,然后将数据拷贝到用户空间,完成后通知用户进程,整个IO操作期间都不会阻塞用户进程。
windows下实现成熟,但很少作为百万级别以上高并发服务器操作系统来使用,因为其不如nio稳定。linux系统下并不完善,主要还是采用io多路复用模型为主。