ElasticSearch原理
ElasticSearch原理
ES的实现原理主要是什么
Elasticsearch(ES)的实现原理基于 分布式存储 + 倒排索引 + 近实时检索 三大支柱的深度协同,以下是其核心机制解析:
一、分布式架构设计(基石)
1.分片(Shard)机制
- 索引被拆分为多个 分片(如主分片 P0、P1),分散在不同节点。
- 优势:
- 水平扩展:数据突破单机限制(如 PB 级日志)。
- 并行计算:查询分散到多分片执行,合并结果(Map-Reduce 思想)。
- 分片策略:
PUT /my_index
{
“settings”: {
“number_of_shards”: 3, // 主分片数(创建后不可变)
“number_of_replicas”: 1 // 每个主分片的副本数(可动态调整)
}
}
2.集群协调(Zen Discovery) - 节点角色:
- Master Node:管理集群状态、分片分配。
- Data Node:存储数据、执行搜索。
- Ingest Node:数据预处理管道。
- 容错机制:
- 分片副本(Replica)分布在不同节点,主分片宕机时副本自动晋升。
- 7.x+ 版本采用 Raft 协议选主,避免脑裂(Split-Brain)。
二、倒排索引的工程优化(加速检索)
1.高效数据结构
- 词典(Term Dictionary) → FST(Finite State Transducer)压缩
- 内存占用仅为哈希表 1/10,支持前缀匹配(如通配符 elast*)。
- 倒排列表(Posting List) → Roaring Bitmaps
- 对文档ID集合高效压缩,快速计算交集(AND)、并集(OR)。
2.分层存储 - 倒排索引:内存中常驻热词(加速高频查询)。
- 列存(Doc Values):磁盘上行列混合存储(用于排序、聚合)。
- 默认对所有非 text 字段开启。
- 文件结构:
- .tip(词典索引)
- .tim(词项倒排列表)
- .dvd(Doc Values数据)
三、近实时(NRT)搜索的实现
1.写入流程
图片代码写入请求内存 BufferTranslog(事务日志)定期 Refresh:生成新 SegmentSegment 可被搜索(约 1s 延迟)周期 Flush:Segment 落盘 + 清空 Translog
- Refresh:内存数据转为不可变的 Lucene Segment(可搜但未持久化)。
- Translog:写操作先写日志(类似 WAL),保障宕机后数据恢复。
- Flush:Segment 刷盘并删除 Translog(默认每 30 分钟或 Translog 达 512MB)。
2.为什么是“近实时”? - 核心延迟:数据写入 → 可搜索需等待 refresh_interval(默认 1 秒)。
- 强制刷新:可通过 ?refresh=true 参数立即刷新(生产慎用,损耗性能)。
四、分布式搜索的执行流程(以 GET /index/_search 为例)
1.查询阶段(Query Phase)
- 客户端请求 → 协调节点(Coordinating Node)。
- 协调节点向 所有相关分片(主/副本)广播查询。
- 各分片本地执行搜索,返回 文档ID和相关性评分(不返回完整数据)。
2.取回阶段(Fetch Phase) - 协调节点汇总结果,按评分排序。
- 向持有目标文档的分片请求完整数据。
- 返回最终结果给客户端。
图片代码QueryQueryDocID, ScoreDocID, ScoreFetchFetch合并结果协调节点Shard1Shard2Shard1_DocShard2_Doc
五、关键工程挑战与解决方案
1.深度分页性能
- 问题:from=10000, size=10 需对所有分片排序 10,010 条记录。
- 优化:
- search_after:用上一页最后一条记录的排序值定位。
- 滚动查询(Scroll):创建快照遍历大量数据(用于导出)。
2.节点扩容再平衡 - 新节点加入后,集群自动迁移分片实现负载均衡(通过 cluster.routing.rebalance 参数控制策略)。
3.高并发写入优化 - Bulk 写入:合并多次请求减少网络开销(建议每批 5-15 MB)。
- 线程池调整:针对写入场景增大 write 队列大小。
六、与底层库 Lucene 的关系
- Lucene:单机搜索引擎库(负责索引创建、分词、检索算法)。
- Elasticsearch:
- 在 Lucene 上封装分布式协调、高可用、REST API。
- 补充监控、安全、可视化等企业级能力。
总结:ES 的核心竞争力
1.数据规模 → 分布式分片 + 副本机制
2.检索速度 → 倒排索引 + FST/RoaringBitmaps 优化
3.可用性 → 近实时刷新 + Translog 容错 + 自动故障转移
4.扩展性 → 无中心节点设计 + 动态分片再平衡
注:ES 并非银弹!
- 弱事务:不适用银行转账等 ACID 场景(可改用 MongoDB 或 TiDB)。
- 冷数据成本:历史数据可迁移至 冻结层(Frozen Tier) 或对象存储(如 S3)。
- 实时性要求极高:考虑 Redis 或 Pulsar 作为缓存层弥补 refresh 延迟。
ES搜索引擎特点和常见问题
以下是关于Elasticsearch(ES)搜索引擎的核心特点及常见问题的总结,适用于技术选型、运维优化和故障排查场景:
一、Elasticsearch 核心特点
1.分布式架构
- 数据自动分片(Shard)存储在多节点,支持横向扩展(PB级数据)。
- 副本机制(Replica)保障高可用,主分片故障时副本自动接管。
2.近实时搜索(NRT, Near Real-Time) - 写入数据后延迟约 1秒 即可被检索(因 refresh_interval 默认 1s)。
3.全文检索能力 - 基于 倒排索引(Inverted Index) 支持高速文本模糊匹配。
- 支持分词器(Analyzer):内置英文、IK中文分词等。
4.丰富的查询语法 - 组合查询:bool 嵌套 must/should/filter。
- 高级功能:短语匹配(match_phrase)、模糊匹配(fuzziness)、同义词扩展等。
5.聚合分析(Aggregation) - 支持多维度统计分析:terms(分组)、date_histogram(时间统计)、metric(平均值/百分位数)。
6.数据建模灵活 - Schema-Free(动态映射),可自定义字段类型(如 keyword 精确匹配 vs text 分词匹配)。
- 支持嵌套对象(nested)和父子文档(join)。
7.生态系统完善 - ELK Stack:通过 Logstash 采集数据,Kibana 可视化分析。
- Beats:轻量级数据收集器(如 Filebeat 采集日志)。
8.RESTful API - 所有操作通过 HTTP API 执行,如 GET /index/_search?q=keyword。
二、常见问题及解决方案
1. 性能问题
- 现象:搜索延迟高或写入慢原因与解决:
- 分片过多:控制单个分片大小(建议 20GB-50GB),减少分片总数。
- 堆内存不足:ES 堆内存 ≤ 物理内存的 50%(不超过 31GB)。
- 磁盘 I/O 瓶颈:使用 SSD 硬盘,避免分片热点集中在少数节点。
2. 集群状态异常 - 现象:yellow 或 red 状态原因:
- yellow:副本分片未分配(节点数=1时不分配副本)。
- red:主分片缺失(数据丢失风险)。解决:
- 扩容节点确保副本分配,或通过 PUT /_settings 临时降低副本数:
{ “index.number_of_replicas”: 0 }
3. 查询语法错误 - 案例:term 查询失效原因:对 text 类型字段使用 term(需用 keyword子字段)。正确写法:
{
“query”: {
“term”: {
“title.keyword”: “精确匹配内容”
}
}
}
4. 脑裂问题(Split-Brain) - 现象:节点分裂成多个集群预防:配置法定票数(discovery.zen.minimum_master_nodes,7.x 后已废弃,由集群自主控制)。
5. 数据一致性 - 写入丢失风险
- 默认写入仅保证 1 个主分片成功(ack=1)。
- 强一致性场景:设置 ack=all(所有分片副本确认)。
6. 资源占用过高 - 现象:CPU、内存飙升排查工具:
- GET /_nodes/hot_threads:定位高消耗线程。
- 监控 segments.memory:优化索引(_forcemerge)减少段文件。
三、最佳实践建议
1.索引生命周期管理(ILM)
- 自动滚动创建新索引(如按日切分),过期数据自动删除。
2.冷热数据分离 - 热节点(SSD):处理实时读写;冷节点(HDD):存储历史数据。
3.避免大查询拖垮集群 - 限制 max_result_window(默认 10,000),使用游标查询(Scroll) 或 Search After 分页。
4.安全加固 - 开启 xpack.security 插件,配置 TLS 加密通信和角色权限控制。
学习资源
- 官方文档:elastic.co/guide(必看,更新快且权威)
- 调试工具:Kibana Dev Tools(交互式 API 控制台)
- 书籍推荐:《Elasticsearch 权威指南》(O’Reilly)
注:ES 8.x 版显著强化了安全性(如默认启用 TLS)、向量搜索(推荐型、Hybrid 检索)等新特性,生产升级时需全面测试兼容性。遇到复杂场景可结合机器学习(如异常检测)与 APM 工具进行根因分析。
倒排索引
倒排索引(Inverted Index) 是搜索引擎的核心数据结构,与传统数据库的 正排索引(通过文档ID查内容)相反,它通过 关键词定位文档,实现海量文本的高效检索。以下是其核心原理和应用解析:
一、对比正排索引 vs 倒排索引
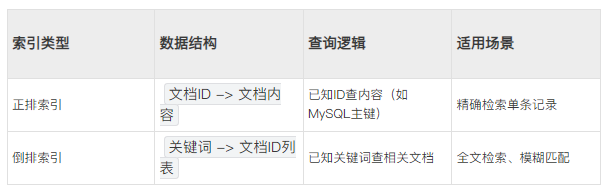
示例:
假设有2个文档:
- Doc1: “Elasticsearch is fast”
- Doc2: “Search in Elasticsearch”
倒排索引构建结果:
![词项(Term)文档ID列表其他信息(如词频)elasticsearch[Doc1, Doc2]Doc1频次:1, Doc2频次:1fast[Doc1]Doc1频次:1in[Doc2]Doc2频次:1is[Doc1]Doc1频次:1search[Doc2]Doc2频次:1](https://i-blog.csdnimg.cn/direct/43e77bf06def4eeb944a3f131c1c18ba.png)
二、倒排索引的组成
1.词典(Term Dictionary)
- 存储所有 唯一词项(如 elasticsearch, fast),通常用 B树 或 FST(Finite State Transducer) 压缩存储(ES采用FST节省内存)。
2.倒排列表(Posting List) - 记录每个词项出现的 文档ID集合 及 元数据:
- 文档ID(DocID)
- 词频(TF, Term Frequency):该词在文档中出现的次数(用于相关性评分)。
- 位置(Position):词在文档中的偏移量(支持短语查询 “quick brown”)。
- 偏移量(Offset):词在文本中的起止位置(用于高亮显示)。
3.跳表(Skip List)优化 - 加速 多倒排列表的交集运算(如 搜索 A AND B),快速跳过不匹配的文档ID。
三、倒排索引在Elasticsearch中的工作流程
1.数据写入
- 文档经过 分词器(Analyzer) 处理(如拆分、转小写、过滤停用词):“Elasticsearch IS fast!” → [“elasticsearch”, “fast”]
- 生成词项并更新倒排索引。
2.搜索过程(以查询 “fast search” 为例): - Step 1:解析查询,拆分为词项 [“fast”, “search”]
- Step 2:从词典中定位词项,获取倒排列表:
- fast → [Doc1]
- search → [Doc2]
- Step 3:根据查询逻辑合并结果(默认 OR 逻辑,返回 Doc1 + Doc2)。
- Step 4:按相关性排序(使用 TF-IDF / BM25 算法):
- 若为 AND 则返回空集(无文档同时含两个词)。
四、核心优势
1.高速检索
- 时间复杂度接近 O(1)(词典哈希定位),百万级文档查询可在毫秒级响应。
2.灵活匹配 - 支持模糊查询、通配符、正则表达式等复杂文本匹配。
3.高效聚合 - 基于词项的统计数据(如词云、热门关键词)可直接从索引生成。
五、生产场景优化点
1.合理分词
- 中文需选 IK分词器,避免无意义单字(如“的”、“了”)。
- 对无需分词的字段(如ID)设为 keyword 类型,节省资源。
2.压缩存储 - ES 默认使用 FST 压缩词典,减少内存占用。
- 对 数值/日期字段 使用 BKD树 结构(范围查询更快)。
3.避免大文档 - 单个文档过大(>10MB)会拖慢索引更新,需拆分子文档。
4.深度分页优化 - 避免使用 from + size(消耗堆内存),改用 Search After 或 Scroll API。
六、典型问题案例
问题: 搜索 “中国银行” 时,结果包含无关内容(如“中国人民银行”)
原因分析:
- 分词器将“中国银行”切为 [中国, 银行],导致匹配所有含“银行”的文档。
解决方案:
1.使用 IK分词器 的 smart 模式(保留完整语义):
// IK配置示例
{ “analyzer”: “ik_smart” }
2.对专有名词设置 同义词词典:
“filter”: {
“my_synonyms”: {
“type”: “synonym”,
“synonyms”: [“中国银行, 中行”]
}
}
总结
倒排索引是全文检索的 基石技术,ES 基于此实现了 毫秒级搜索响应 + 灵活文本分析。生产环境中需重点把控:
1.分词策略(匹配精度与召回率的平衡)
2.索引结构设计(字段类型、分片大小)
3.查询优化(避免低效语法,如通配符 * 开头的查询)。
注:ES 7.0+ 引入了 稀疏向量 支持语义搜索,可与倒排索引组成 混合检索(Hybrid Search),应对复杂搜索场景。
ES的分词器有哪些?怎么使用?
一、分词器核心组件
每个分词器(Analyzer)由三部分组成:
1.1.Character Filters
a.•预处理原始文本(如删除HTML标签、替换字符)。
b.•示例:html_strip(清理HTML标签)。
2.2.Tokenizer
a.•将文本切分为词元(Token)。必选且唯一。
b.•示例:standard(按空格和标点分词)、ik_max_word(中文细粒度切分)。
3.3.Token Filters
a.•对词元进行二次处理(如转小写、去停用词、同义词扩展)。
b.•示例:lowercase、stop(过滤停用词)、synonym(同义词替换)。
二、ES 内置分词器一览
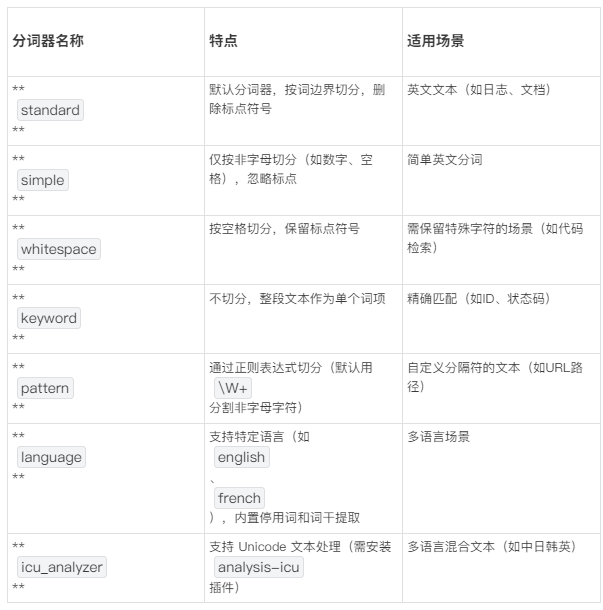
注:中文场景必须用第三方分词器(如 IK、THULAC),内置分词器会将中文逐字分割。
三、中文分词器推荐(第三方插件)
- IK Analyzer(最常用)
- •安装方式:./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v8.11.0/elasticsearch-analysis-ik-8.11.0.zip
- •两种模式:模式特点示例输入 → 输出ik_max_word细粒度切分(尽可能拆出更多词)苹果手机 → [苹果, 手机, 苹果手机]ik_smart粗粒度切分(保留完整语义)苹果手机 → [苹果手机]
- THULAC(清华大学自然语言处理实验室)
- •特点:支持中文分词和词性标注(需 Java 环境编译)。
- •安装:./bin/elasticsearch-plugin install https://github.com/microbun/elasticsearch-thulac-plugin/releases/download/v8.11.0/elasticsearch-thulac-plugin-8.11.0.zip
- HanLP(功能全面)
- •支持自定义词典、命名实体识别等高级功能。
- •项目地址:https://github.com/hankcs/HanLP
四、分词器的配置与使用
步骤1:定义自定义分词器
PUT /my_index
{
“settings”: {
“analysis”: {
“analyzer”: {
“my_custom_analyzer”: { // 自定义分词器名称
“type”: “custom”,
“tokenizer”: “ik_max_word”, // 使用IK分词器
“char_filter”: [“html_strip”], // 清理HTML标签
“filter”: [
“lowercase”, // 转小写
“stop”, // 过滤英文停用词(the, a, an)
“synonym_filter” // 同义词扩展
]
}
},
“filter”: {
“synonym_filter”: {
“type”: “synonym”,
“synonyms”: [ “手机, 移动电话 => 智能手机” ] // 同义词规则
}
}
}
}
}
步骤2:测试分词效果
POST /my_index/_analyze
{
“analyzer”: “my_custom_analyzer”,
“text”: “小米手机降价了!”
}
输出结果:
{
“tokens”: [
{ “token”: “小米”, “position”: 0 },
{ “token”: “智能手机”, “position”: 1 }, // 同义词替换
// “strong” 标签被 html_strip 移除
{ “token”: “降价”, “position”: 3 }
]
}
步骤3:映射字段使用分词器
PUT /my_index/_mapping
{
“properties”: {
“product_name”: {
“type”: “text”,
“analyzer”: “my_custom_analyzer”, // 写入时分词
“search_analyzer”: “ik_smart” // 搜索时分词(可不同)
}
}
}
注意:写入和搜索可用不同分词器(如写入用 ik_max_word 增加召回率,搜索用 ik_smart 提升精度)。
五、生产环境最佳实践
1.词库热更新
a.•IK 分词器支持远程词典(避免重启集群):properties复制# config/elasticsearch.yml
es.ext.dic.remote_url: http://your-api/custom_words.dic
es.ext.dic.auto_refresh: 60s # 每60秒更新
2.避免全字段模糊查询
a.•禁止对未分词的 keyword 字段使用 wildcard 查询(性能杀手)。
b.•改用 text 类型分词后查询 + ngram 分词器实现部分匹配。
3.特殊符号处理
a.•邮箱/URL等字段需自定义分词规则:json复制"tokenizer": “pattern”,
“pattern”: “([^@]+)@|\.|://” // 按@、.、😕/分割
4.性能监控
a.•通过 _nodes/stats/analysis 检查分词耗时,优化高负载分词器配置。
六、常见问题排查
问题1:搜索“中国银行”匹配到“中国人民银行”
- •原因:分词器将“中国银行”切为 [中国, 银行]。
- •解决:// 在IK词典中添加专有名词
中国银行
问题2:数值范围查询失效(如 price:100~200)
原因:字段被错误设为 text 类型(分词后存储)。
解决:// 改用 keyword + numeric 类型
“price”: {
“type”: “text”,
“fields”: {
“raw”: { “type”: “keyword” }, // 精确匹配
“num”: { “type”: “integer” } // 范围查询
}}
问题3:同义词不生效 - •原因:同义词规则需在索引创建前定义或通过 _close 关闭索引后更新。
- •解决:1.使用 POST /my_index/_close 关闭索引2.更新同义词配置3.POST /my_index/_open 重新打开
通过合理选择和调优分词器,可大幅提升搜索相关性及性能。中文场景推荐 IK + 动态词典更新,欧州多语言选 ICU,需要词性标注则考虑 THULAC 或 HanLP。