堆的定义
1.满足完全二叉树的特性(除了最后一层外,每层节点都是满的;最后一层的节点从左到右连续排列。)
2.分为大顶堆和小顶堆(1)大顶堆:每个节点的值 ≥ 左右子节点的值 → 堆顶是最大值。(2)小顶堆:每个节点的值 ≤ 左右子节点的值 → 堆顶是最小值。
堆的建立过程
概述:
从最后一个非叶子节点开始堆化,从后往前,依次是7,20,4,8,为什么顺序看着是蛇形走位呢。
因为这是数组存储,8相当于索引0位置,4为索引1的位置,20相当于索引2的位置,
7相当于索引3的位置,依次类推.....,看着像是蛇形走位,其实就是从后面的索引往前比对
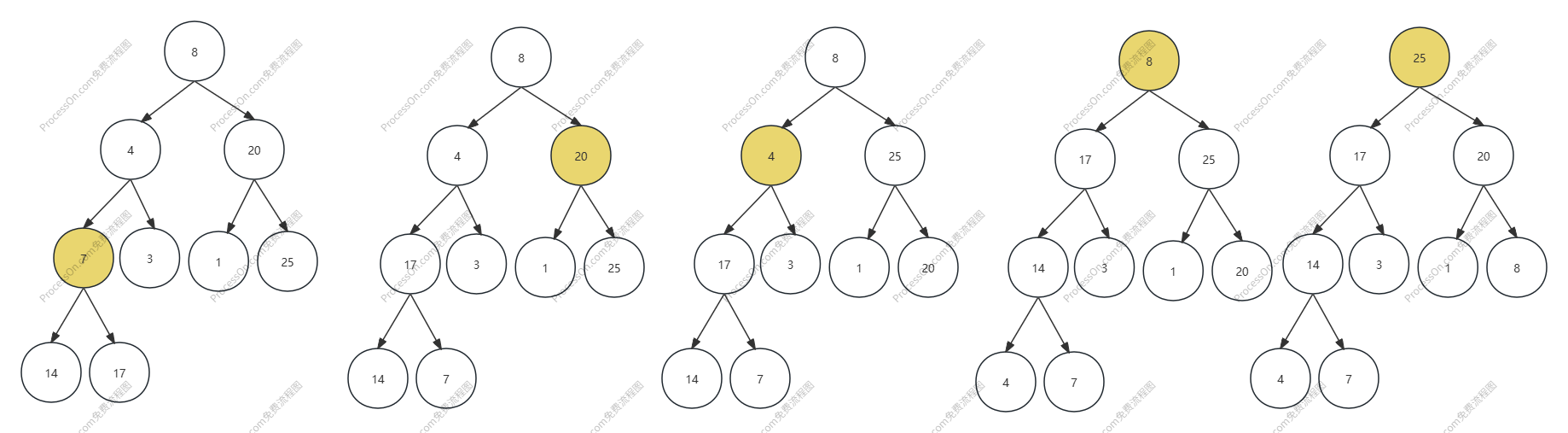
堆的排序过程
排序策略,将堆顶元素和最后一个元素交换,交换完成后进行一次下沉堆化操作,依次执行操作即可,
但是已经交换过的堆顶元素不需要再参与下沉堆化操作,因为默认堆顶元素就是最大的数字,
交换位置后本来就是最大的数字了,参与堆化无意义,也不能保证排序了。
(要明白在大顶堆中,堆顶的肯定是最大的,一次次结尾的与堆顶的交换,很显然顺序就出来了,
就跟小学课本高斯解1到100那个问题一样,只不过这块是交换,第一个与倒数第一个交换,
第二个与倒数第二个交换,以此类推,直到排序完成)

具体代码实现
package com.che.datajg;import java.util.Arrays;
public class HeapTree {public static void main(String[] args) {int[] a = {8, 4, 20, 7, 3, 1, 25, 14,17,2,100,54,67,89,32,8};heapSort(a);}public static void maxHeap(int[] data, int length) {for (int i = length / 2 - 1; i >= 0; i--) {heapify(data, i, length);}System.out.println("创建大顶堆:"+Arrays.toString(data));}public static void heapify(int[] data, int index, int length) {int a = index;int temp = data[a]; int leftIndex = a * 2 + 1;while (leftIndex < length) {int rightIndex = leftIndex + 1;int biggerIndex = leftIndex;if (rightIndex < length && data[rightIndex] >= data[leftIndex]) {biggerIndex = rightIndex;}if (data[biggerIndex] > temp) {data[a] = data[biggerIndex];leftIndex = biggerIndex * 2 + 1;} else {break;}}data[a] = temp;}public static void heapSort(int[] data) {maxHeap(data,data.length);int length = data.length;for (int i = length-1; i > 0; i--) {int max=data[0];int end=data[i];data[0]=end;data[i]=max;heapify(data,0, i);}System.out.println("最终排序结果:"+Arrays.toString(data));}
}