VMWare上搭建大数据集群
文章目录
- 1. 采用软件较新版本
- 2. 准备三台虚拟机
- 3. 搭建Hadoop集群
- 3.1 在主节点上配置Hadoop
- 3.1.1 编辑映射文件
- 3.1.2 配置免密登录
- 3.1.3 配置JDK
- 3.1.4 配置Hadoop
- 3.2 从主节点分发到从节点
- 3.3 格式化名称节点
- 3.4 启动Hadoop集群
- 3.5 使用Hadoop WebUI
- 3.6 运行MR应用:词频统计
- 3.7 关闭Hadoop集群
- 4. 搭建Hive集群
- 5. 搭建Spark集群
- 6. 搭建HBase集群
- 7. 搭建Flink集群
- 8. 安装配置Flume
- 9. 安装配置Kafka
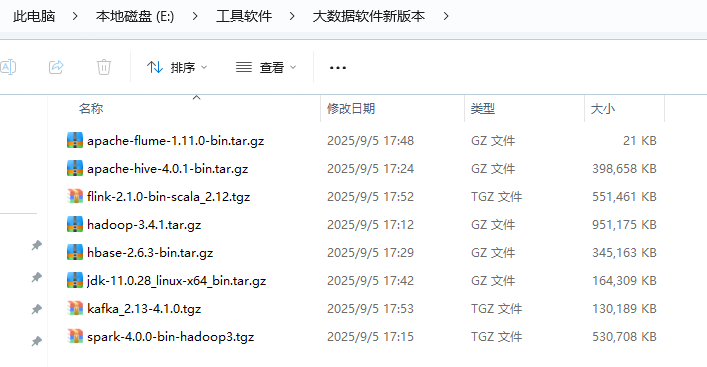
1. 采用软件较新版本
- 通过搭建集群,测试其兼容性
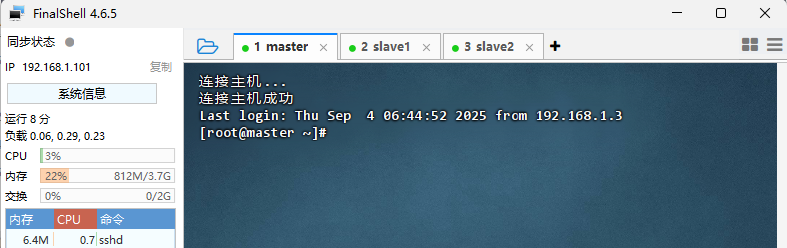
2. 准备三台虚拟机
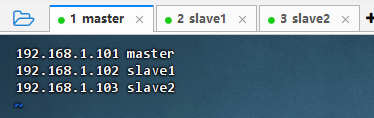
- 主机名与IP地址
| 主机名 | IP 地址 |
|---|---|
| master | 192.168.1.101 |
| slave1 | 192.168.1.102 |
| slave2 | 192.168.1.103 |
- 三台虚拟机已经关闭与禁用防火墙,关闭selinux安全机制
- FinalShell远程连接三台虚拟机
3. 搭建Hadoop集群
3.1 在主节点上配置Hadoop
3.1.1 编辑映射文件
- 执行命令:
vim /etc/hosts
- 注意:IP地址与主机名之间只有一个半角空格
3.1.2 配置免密登录
-
生成RSA密钥对
- 执行命令:
ssh-keygen
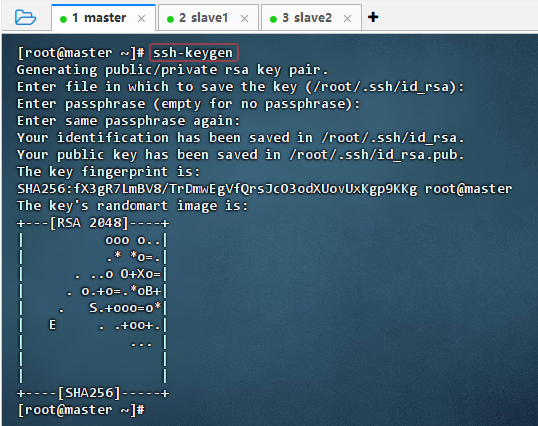
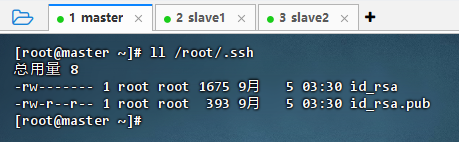
- 执行命令后,连续敲3次回车,生成节点的公钥和私钥,生成的密钥文件
id_rsa会自动放在/root/.ssh目录下。 - 查看生成的密钥对
- 私钥:id_rsa
- 公钥:id_rsa.pub
- 执行命令:
ll /root/.ssh
- 执行命令:
-
分发公钥
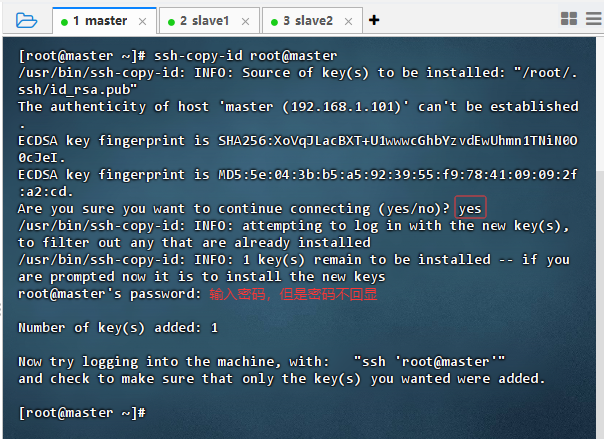
- 发送给master虚拟机
- 执行命令:
ssh-copy-id root@master
- 执行命令:
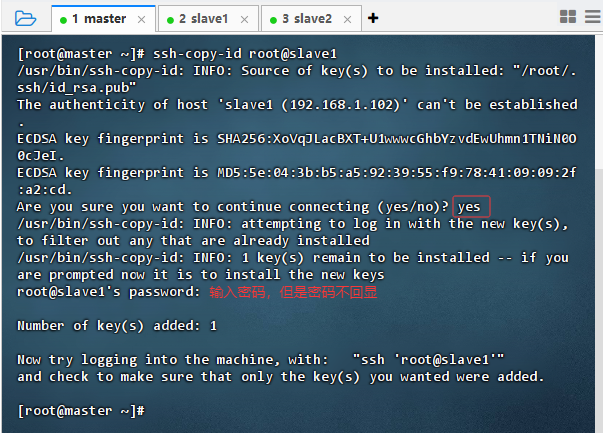
- 发送给slave1虚拟机
- 执行命令:
ssh-copy-id root@slave1
- 执行命令:
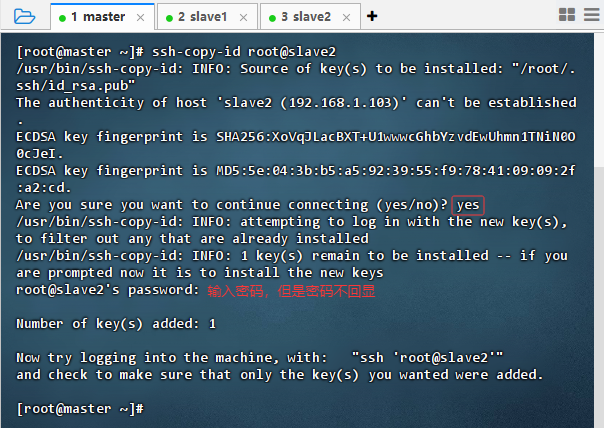
- 发送给slave2虚拟机
- 执行命令:
ssh-copy-id root@slave2
- 执行命令:
- 发送给master虚拟机
-
验证免密登录
-
免密登录master虚拟机
- 执行命令:
ssh master
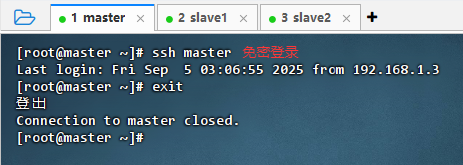
- 执行命令:
-
免密登录slave1虚拟机
- 执行命令:
ssh slave1
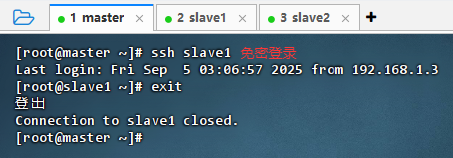
- 执行命令:
-
免密登录slave2虚拟机
- 执行命令:
ssh slave2
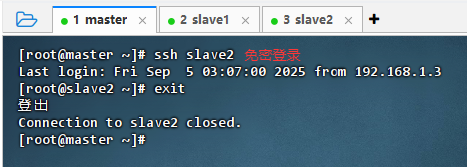
- 执行命令:
-
-
查看密钥对目录
-
执行命令:
ll /root/.ssh
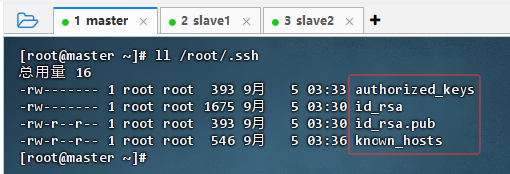
-
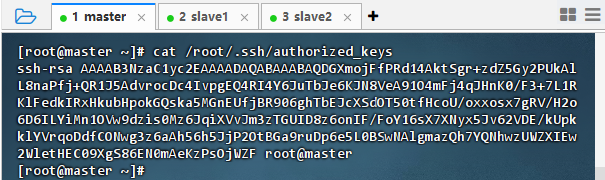
执行命令:
cat /root/.ssh/authorized_keys,查看授权密钥
-
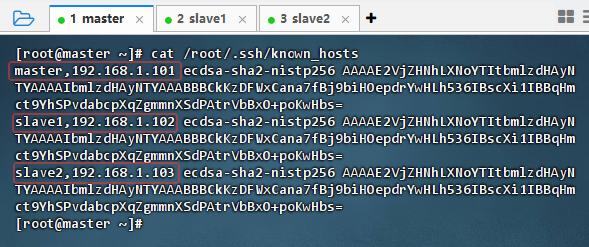
执行命令:
cat /root/.ssh/known_hosts,查看已知主机
-
3.1.3 配置JDK
-
上传安装包
-
进入/opt目录
- 执行命令:
cd /opt
- 执行命令:
-
上传jdk安装包
- 上传jdk安装包到
/opt目录
- 上传jdk安装包到
-
查看jdk安装包
- 执行命令:
ll jdk-11.0.28_linux-x64_bin.tar.gz

- 执行命令:
-
-
解压缩安装包
-
解压缩
- 执行命令:
tar -zxvf jdk-11.0.28_linux-x64_bin.tar.gz -C /usr/local

- 执行命令:
-
查看解压目录
- 执行命令:
ll /usr/local/jdk-11.0.28
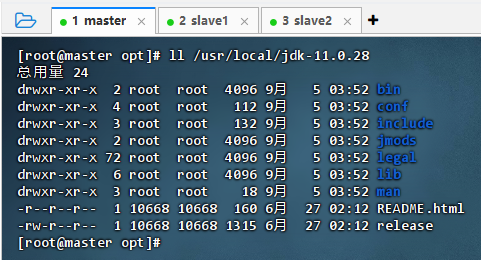
- 执行命令:
-
-
配置环境变量
-
执行命令:
vim /etc/profile
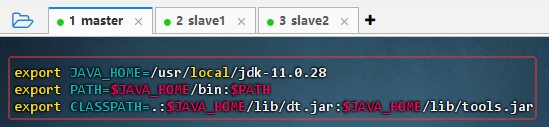
export JAVA_HOME=/usr/local/jdk1.8.0_231 export PATH=$JAVA_HOME/bin:$PATH export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar说明:设置CLASSPATH时,注意等号后有一个“.”,表示之前定义的类路径
-
存盘退出,执行命令:
source /etc/profile,让配置生效
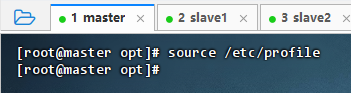
-
-
查看JDK版本
- 执行命令:
java -version
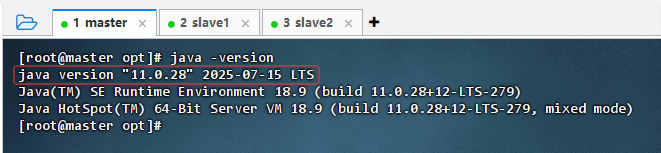
- 执行命令:
3.1.4 配置Hadoop
-
上传安装包
-
上传安装包
- 上传hadoop安装包:上传安装包到
/opt目录
- 上传hadoop安装包:上传安装包到
-
查看上传的hadoop安装包
- 执行命令:
ll hadoop-3.4.1.tar.gz
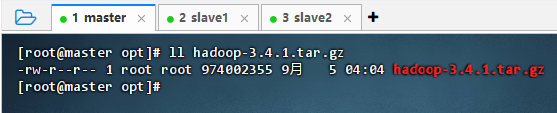
- 执行命令:
-
-
解压缩安装包
- 执行解压命令
- 执行命令:
tar -zxvf hadoop-3.4.1.tar.gz -C /usr/local

- 执行命令:
- 查看解压后的目录
- 执行命令:
ll /usr/local/hadoop-3.4.1
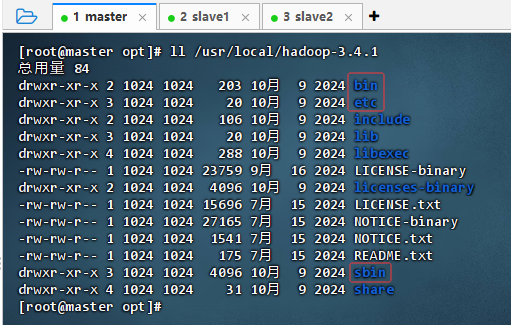
- 执行命令:
- 重要目录
bin:包含一些操作Hadoop集群的可执行文件etc/hadoop:包含Hadoop的各种配置文件sbin:主要存放管理Hadoop集群的系统级脚本
- 执行解压命令
-
配置环境变量
- 配置
- 执行命令:
vim /etc/profile
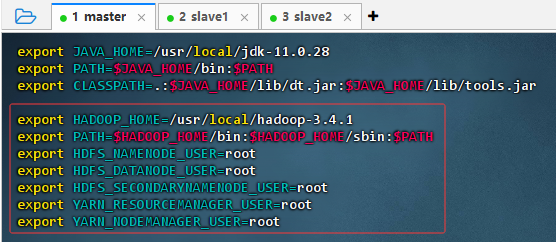
export HADOOP_HOME=/usr/local/hadoop-3.4.1 export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH export HDFS_NAMENODE_USER=root export HDFS_DATANODE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export YARN_RESOURCEMANAGER_USER=root export YARN_NODEMANAGER_USER=root
- 执行命令:
- 生效
- 执行命令:
source /etc/profile,让配置生效
- 执行命令:
- 查看版本
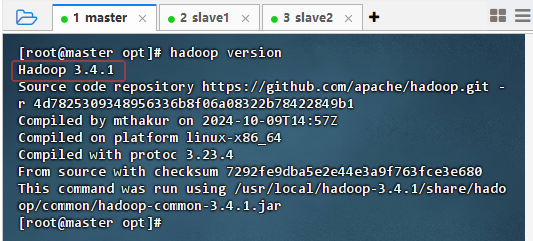
- 执行命令:
hadoop version
- 执行命令:
- 配置
-
编辑Hadoop环境配置文件
- 进入配置目录
- 执行命令:
cd $HADOOP_HOME/etc/hadoop
- 执行命令:
- 编辑配置文件
-
执行命令:
vim hadoop-env.sh
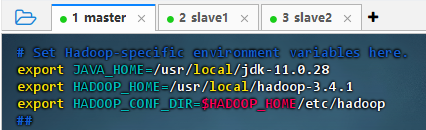
export JAVA_HOME=/usr/local/jdk-11.0.28 export HADOOP_HOME=/usr/local/hadoop-3.4.1 export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
-
- 让配置生效
- 执行命令:
source hadoop-env.sh
- 执行命令:
- 进入配置目录
-
编辑Hadoop核心配置文件
-
执行命令:
vim core-site.xml
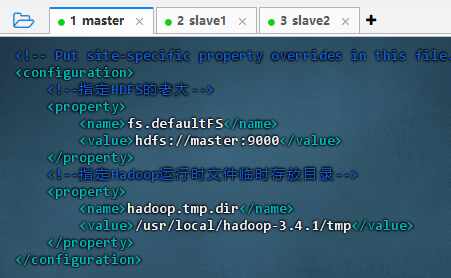
<configuration><!--指定HDFS的老大--><property><name>fs.defaultFS</name><value>hdfs://master:9000</value></property><!--指定Hadoop运行时文件临时存放目录--><property><name>hadoop.tmp.dir</name><value>/usr/local/hadoop-3.4.1/tmp</value></property> </configuration>
-
-
编辑HDFS配置文件
-
执行命令:
vim hdfs-site.xml
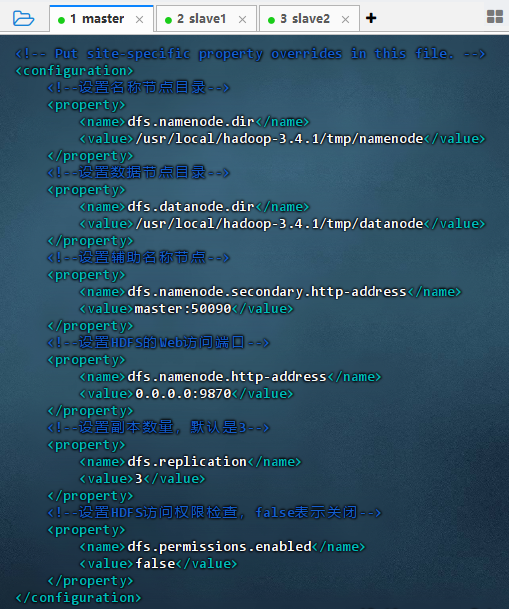
<configuration><!--设置名称节点目录--><property><name>dfs.namenode.dir</name><value>/usr/local/hadoop-3.4.1/tmp/namenode</value></property><!--设置数据节点目录--><property><name>dfs.datanode.dir</name><value>/usr/local/hadoop-3.4.1/tmp/datanode</value></property><!--设置辅助名称节点--><property><name>dfs.namenode.secondary.http-address</name><value>master:50090</value></property><!--设置HDFS的Web访问端口--> <property><name>dfs.namenode.http-address</name><value>0.0.0.0:9870</value></property><!--设置副本数量,默认是3--><property><name>dfs.replication</name><value>3</value></property><!--设置HDFS访问权限检查,false表示关闭--><property><name>dfs.permissions.enabled</name><value>false</value></property> </configuration>
-
-
编辑MapReduce配置文件
-
执行命令:
vim mapred-site.xml
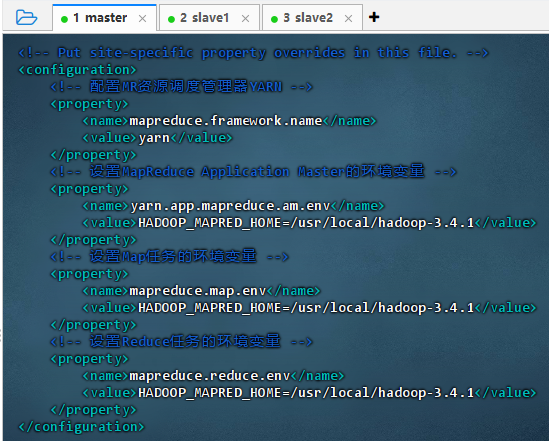
<configuration><!-- 配置MR资源调度管理器YARN --><property><name>mapreduce.framework.name</name><value>yarn</value></property><!-- 设置MapReduce Application Master的环境变量 --><property><name>yarn.app.mapreduce.am.env</name><value>HADOOP_MAPRED_HOME=/usr/local/hadoop-3.4.1</value></property><!-- 设置Map任务的环境变量 --><property><name>mapreduce.map.env</name><value>HADOOP_MAPRED_HOME=/usr/local/hadoop-3.4.1</value></property><!-- 设置Reduce任务的环境变量 --><property><name>mapreduce.reduce.env</name><value>HADOOP_MAPRED_HOME=/usr/local/hadoop-3.4.1</value></property> </configuration>
-
-
编辑YARN配置文件
-
执行命令:
vim yarn-site.xml
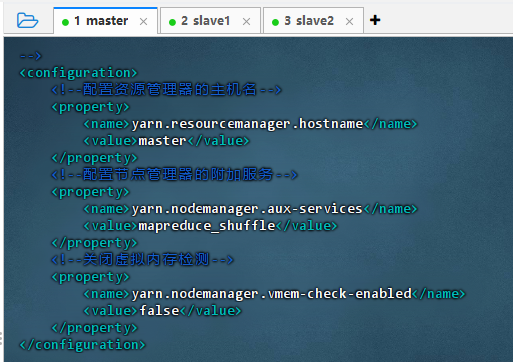
<configuration><!--配置资源管理器的主机名--><property><name>yarn.resourcemanager.hostname</name><value>master</value></property><!--配置节点管理器的附加服务--><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><!--关闭虚拟内存检测--><property><name>yarn.nodemanager.vmem-check-enabled</name><value>false</value></property> </configuration>
-
-
编辑数据节点文件
- 执行命令:
vim workers
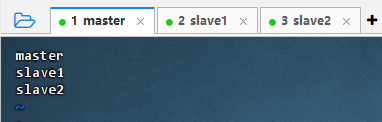
- 三台虚拟机上都有数据节点(DataNode)
- 执行命令:
3.2 从主节点分发到从节点
- 从master节点分发到slave1节点
-
分发JDK
- 执行命令:
scp -r $JAVA_HOME root@slave1:$JAVA_HOME

- 在slave1节点上查看拷贝的JDK目录

- 执行命令:
-
分发Hadoop
-
执行命令:
scp -r $HADOOP_HOME root@slave1:$HADOOP_HOME

-
在slave1节点上查看拷贝的hadoop目录
-
-
分发环境配置文件
- 执行命令:
scp /etc/profile root@slave1:/etc/profile
- 执行命令:
-
刷新环境配置文件
- 在slave1节点上执行命令:
source /etc/profile
- 在slave1节点上执行命令:
-
查看jdk和hadoop版本
-
在slave1节点上执行命令:
java -version
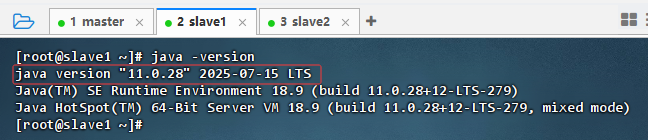
-
在slave1节点上执行命令:
hadoop version
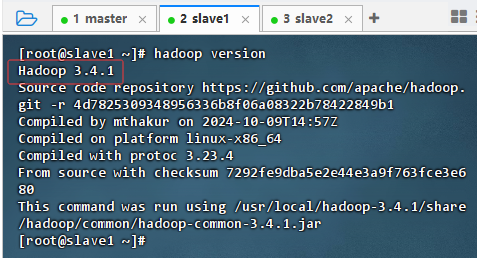
-
-
分发映射文件
- 执行命令:
scp /etc/hosts root@slave1:/etc/hosts
- 执行命令:
-
- 从master节点分发到slave2节点
-
分发JDK
- 执行命令:
scp -r $JAVA_HOME root@slave2:$JAVA_HOME

- 在slave2节点上查看拷贝的JDK目录
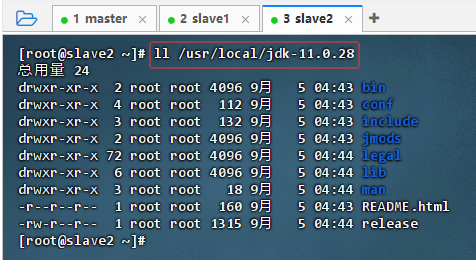
- 执行命令:
-
分发Hadoop
-
执行命令:
scp -r $HADOOP_HOME root@slave2:$HADOOP_HOME

-
在slave2节点上查看拷贝的hadoop目录
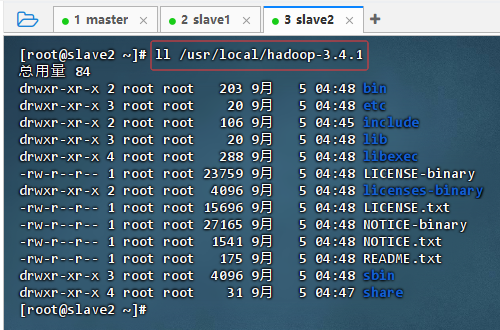
-
-
分发环境配置文件
- 执行命令:
scp /etc/profile root@slave2:/etc/profile
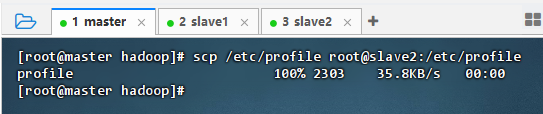
- 执行命令:
-
刷新环境配置文件
- 在slave2节点上执行命令:
source /etc/profile
- 在slave2节点上执行命令:
-
查看jdk和hadoop版本
-
在slave2节点上执行命令:
java -version
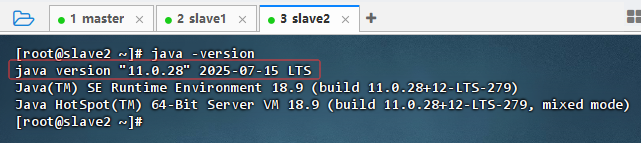
-
在slave2节点上执行命令:
hadoop version
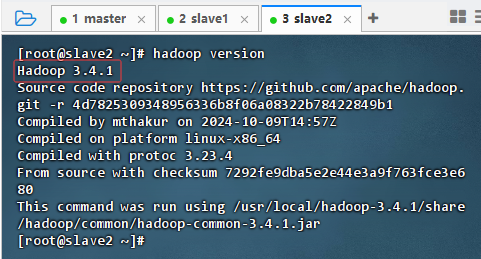
-
-
分发映射文件
- 执行命令:
scp /etc/hosts root@slave2:/etc/hosts
- 执行命令:
-
3.3 格式化名称节点
- 执行命令:
hdfs namenode -format
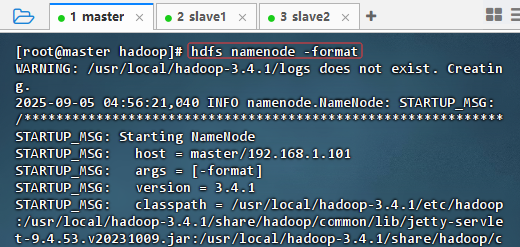
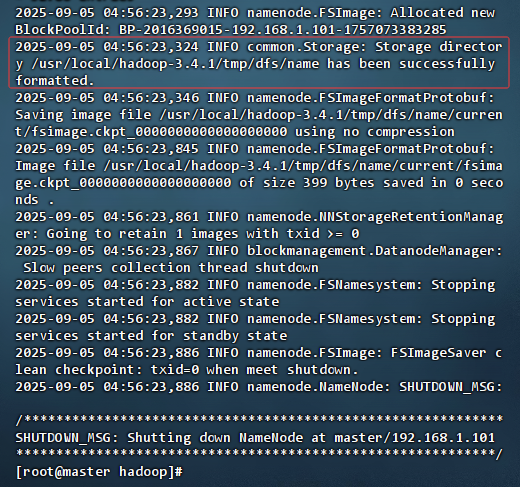
- 格式化成功信息:
2025-09-05 04:56:23,324 INFO common.Storage: Storage directory /usr/local/hadoop-3.4.1/tmp/dfs/name has been successfully formatted.
3.4 启动Hadoop集群
-
启动服务
- 执行命令:
start-all.sh
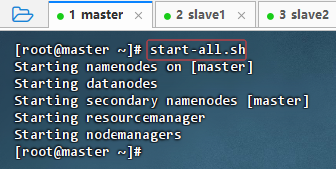
- 执行命令:
-
查看进程
- 执行命令:jps
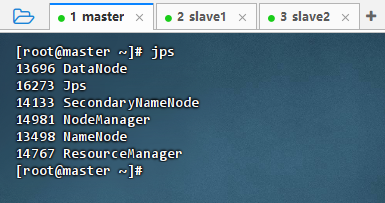
- 执行命令:jps
-
简单说明
start-dfs.sh- NameNode
- SecondaryNameNode
- DataNode
start-yarn.sh- ResourceManager
- NodeManager
3.5 使用Hadoop WebUI
-
查看HDFS集群状态
-
端口号说明
- hadoop2.x的端口号是50070,hadoop3.x的端口号是9870
-
用主机名访问
- 访问
http://master:9870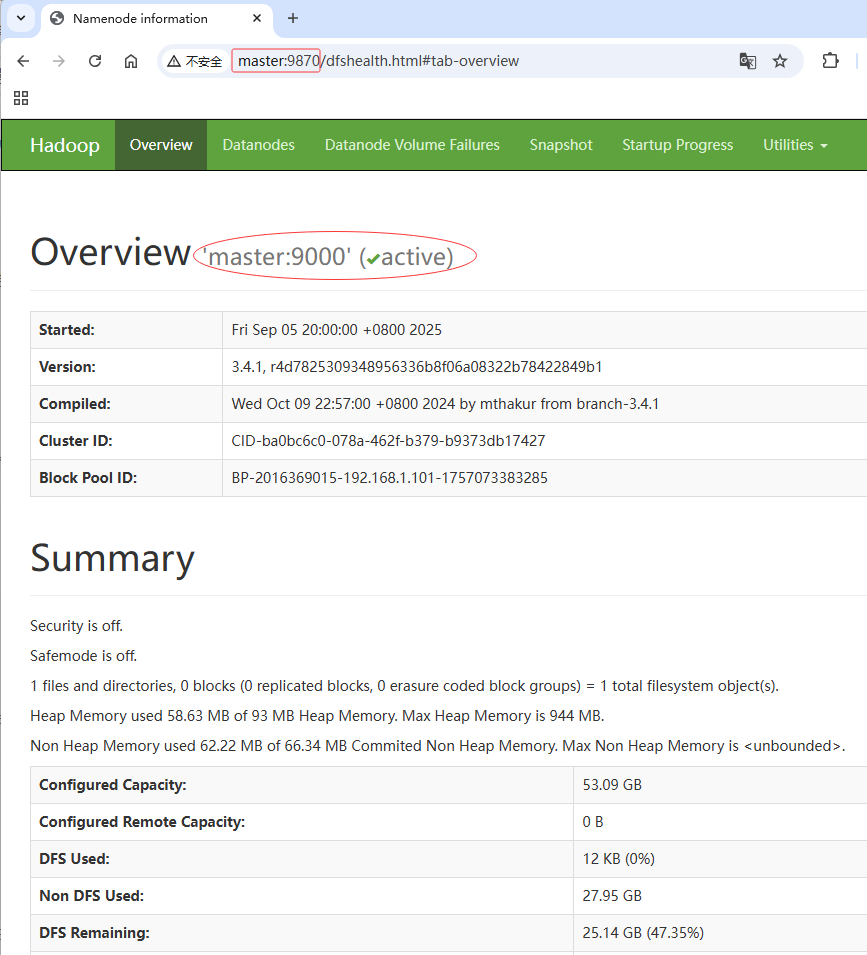
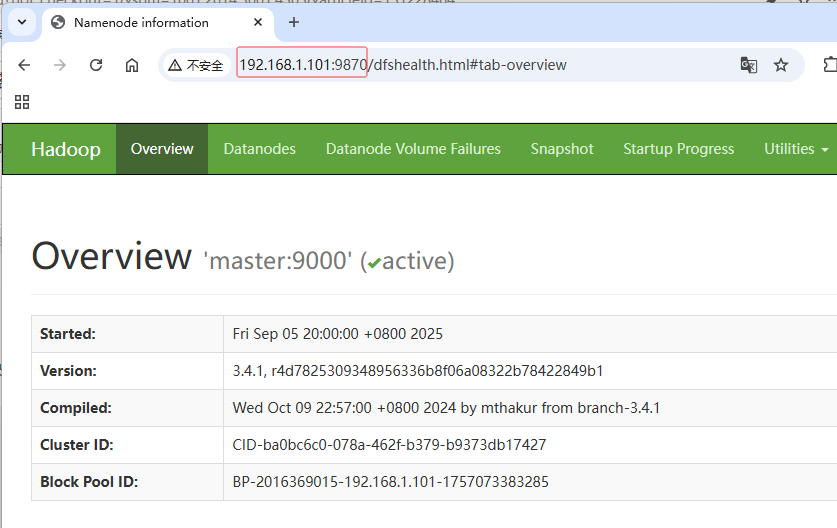
- 主节点状态:
active
- 访问
-
用IP地址访问
-
使用master主机的IP地址来访问,查看本机映射文件
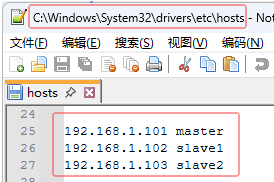
-
访问
http://192.168.219.83:9870
-
-
查看数据节点
- 单击绿色导航栏上的【Datanodes】选项卡
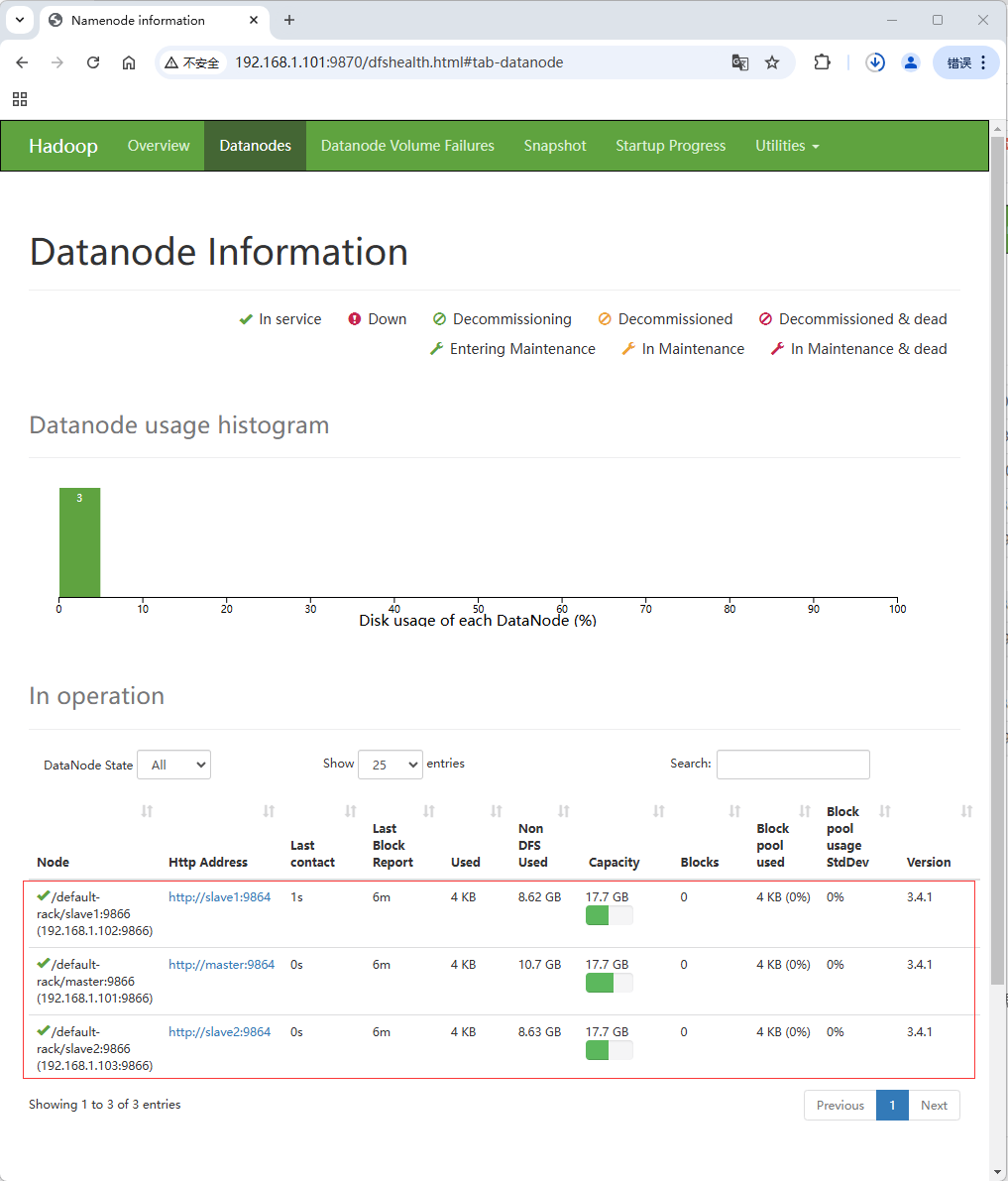
- 单击绿色导航栏上的【Datanodes】选项卡
-
-
查看YARN集群状态
- 在浏览器里查看
http://master:8088

- 目前没有运行过的MR应用,因此表格里没有任何数据
- 在浏览器里查看
3.6 运行MR应用:词频统计
-
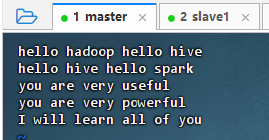
在master虚拟机上准备数据文件
- 执行命令:
vim test.txt
- 执行命令:
-
文件上传到HDFS指定目录
-
创建HDFS目录
- 执行命令:
hdfs dfs -mkdir -p /wordcount/input

- 执行命令:
-
上传文件到HDFS
- 执行命令:
hdfs dfs -put test.txt /wordcount/input
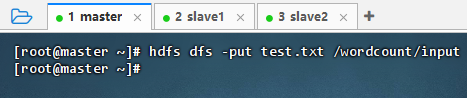
- 执行命令:
-
查看上传的文件
-
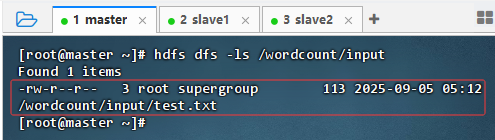
执行命令:
hdfs dfs -ls /wordcount/input,查看文件信息
-
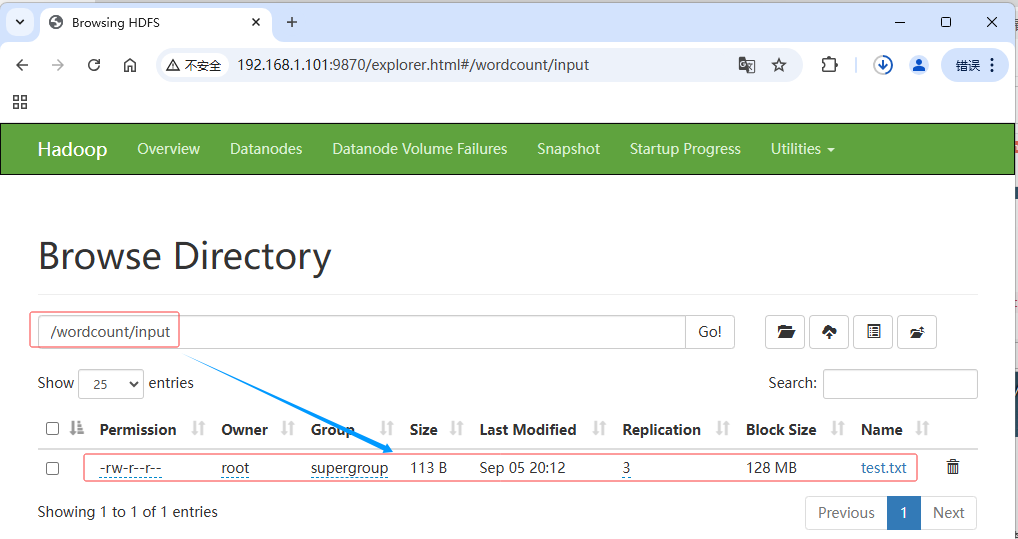
利用Hadoop WebUI查看
-
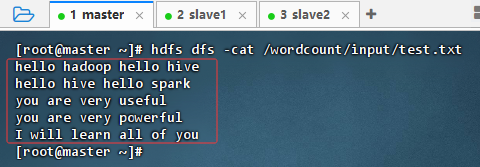
执行命令:
hdfs dfs -cat /wordcount/input/test.txt,查看文件内容
-
-
-
运行词频统计程序的jar包
-
查看Hadoop自带示例jar包
- 执行命令:
cd $HADOOP_HOME/share/hadoop/mapreduce,切换到MR示例目录
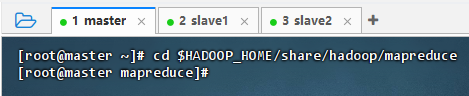
- 执行命令:
ls,列表显示目录信息
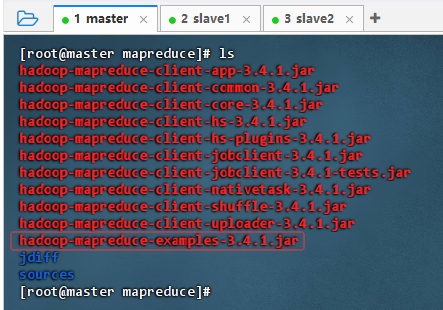
- 示例程序jar包:
hadoop-mapreduce-examples-3.4.1.jar
- 执行命令:
-
运行示例jar包里的词频统计
- 执行命令:
hadoop jar ./hadoop-mapreduce-examples-3.4.1.jar wordcount /wordcount/input/test.txt /wordcount/output
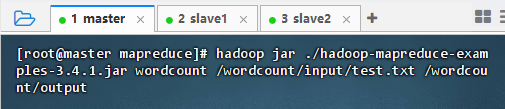
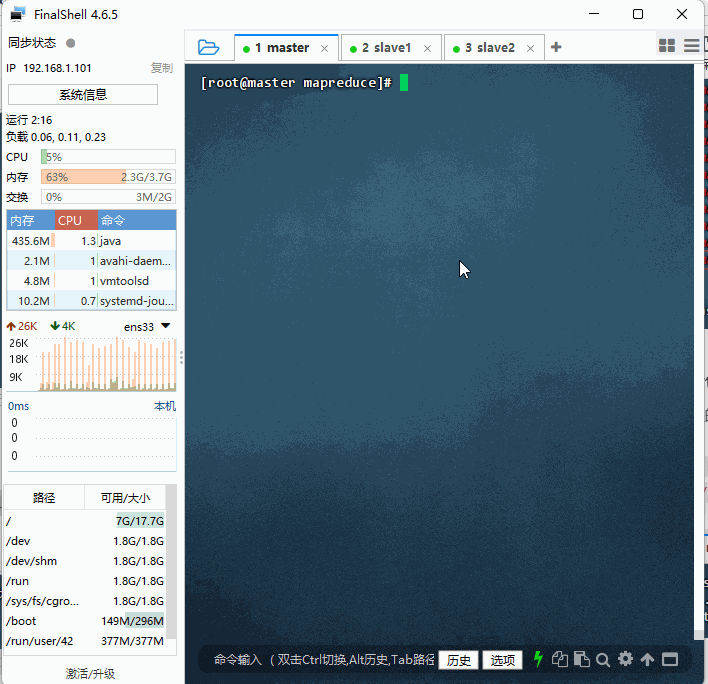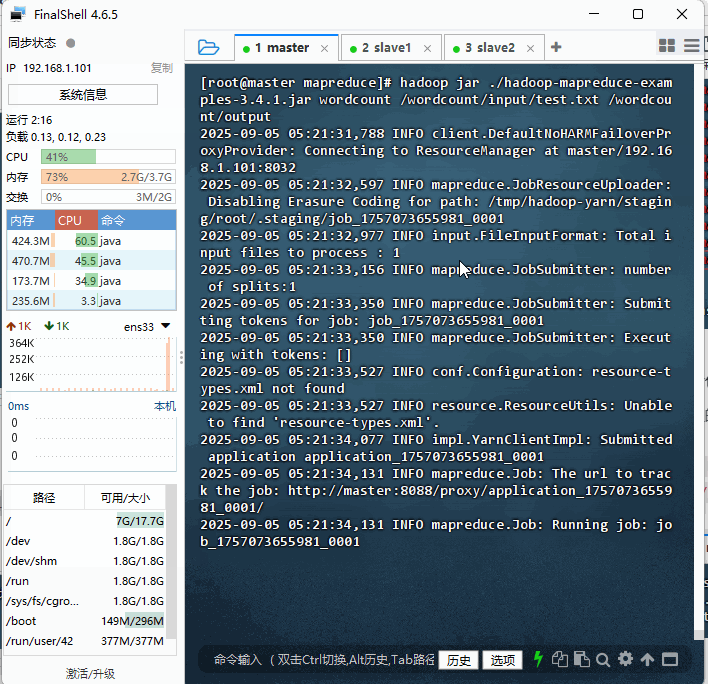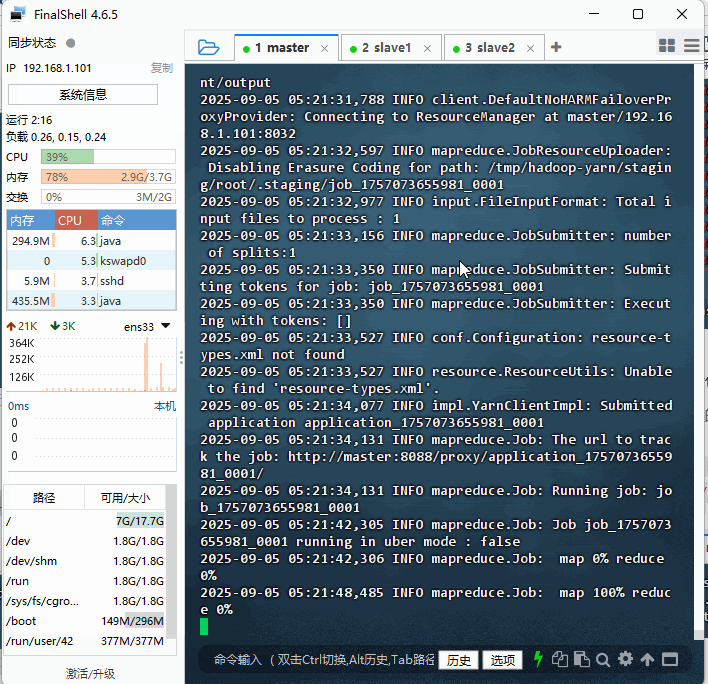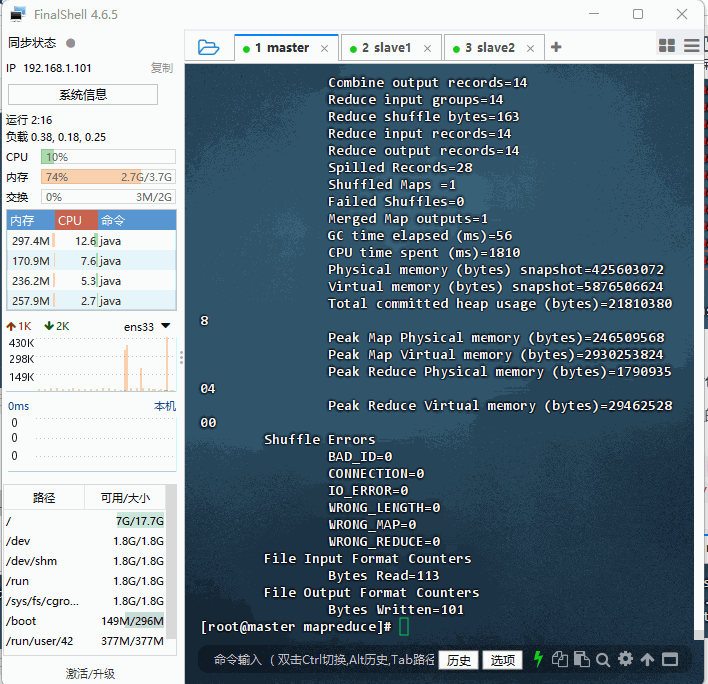
- 查看作业号:2025-09-05 05:21:34,131 INFO mapreduce.Job: Running job:
job_1757073655981_0001
- 执行命令:
-
查看词频统计结果
-
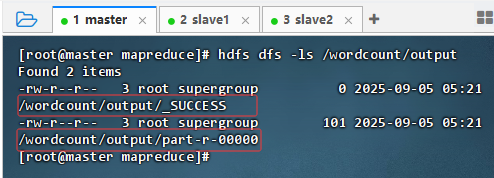
执行命令:
hdfs dfs -ls /wordcount/output,查看结果文件
-
一个是成功标识文件:
_SUCCESS,一个结果文件:part-r-00000 -
利用HDFS的WebUI查看结果文件
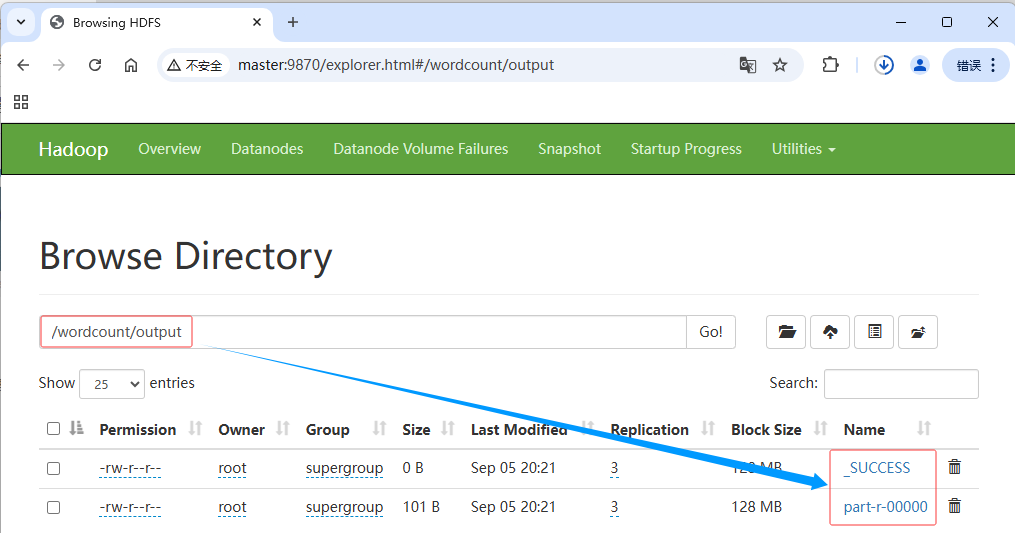
-
执行命令:
hdfs dfs -cat /wordcount/output/*,查看结果内容
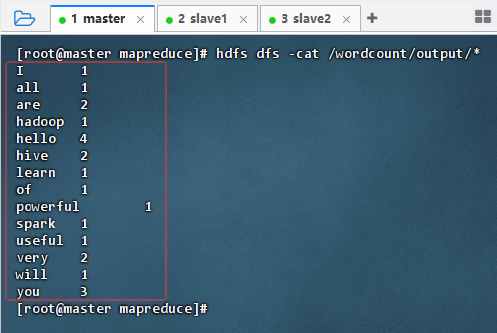
-
-
-
在YARN集群UI界面查看程序运行状态
- 在浏览器里查看
http://master:8088,最终状态是SUCCEEDED
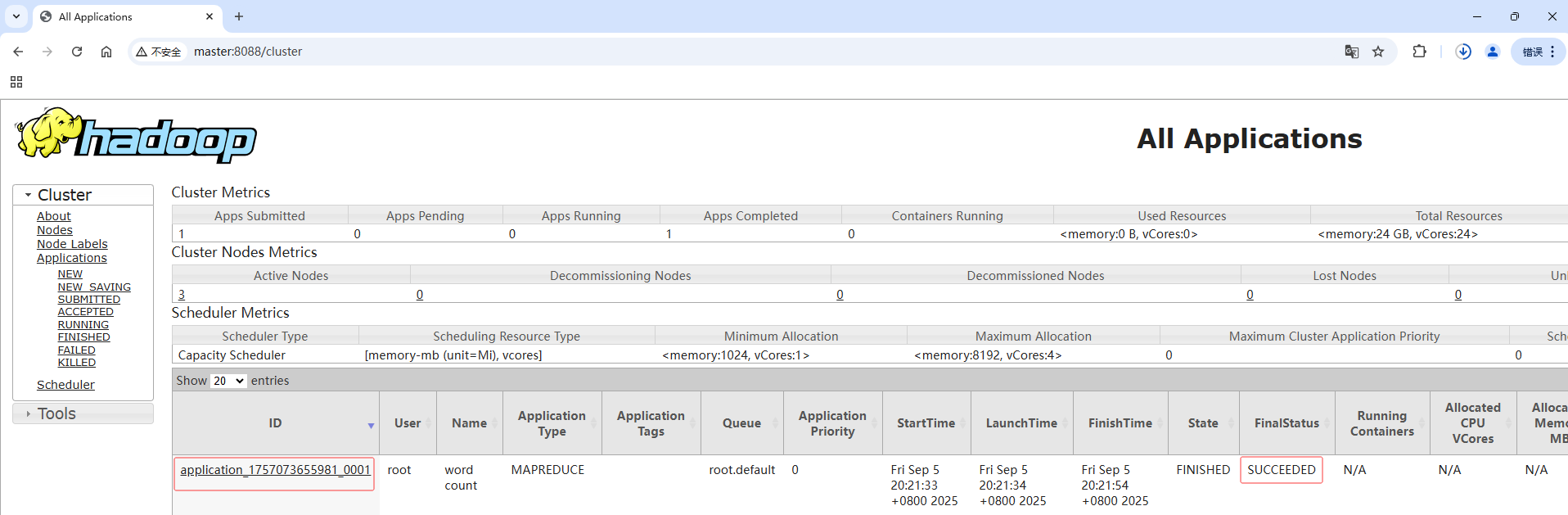
- 在浏览器里查看
3.7 关闭Hadoop集群
- 关闭Hadoop集群
-
执行命令:
stop-all.sh
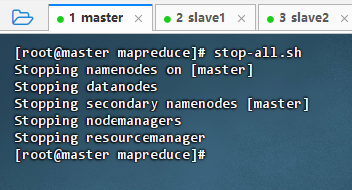
-
注意:也可以分开执行
stop-dfs.sh:关闭HDFS服务stop-yarn.sh:关闭YARN服务
-