认知篇#11:计算机视觉研究领域的大致分类
一、概述
计算机视觉是一门研究如何让机器“看见”并“理解”数字图像或视频的科学。它旨在通过算法和模型,自动地从视觉数据中提取、分析和处理信息,从而感知环境、识别物体、跟踪运动、重建三维场景等。其最终目标是赋予机器像人类一样的视觉感知能力,让计算机能自动“看懂”世界,并应用于自动驾驶、医疗影像、安防监控、工业检测和增强现实等众多领域
二、分类
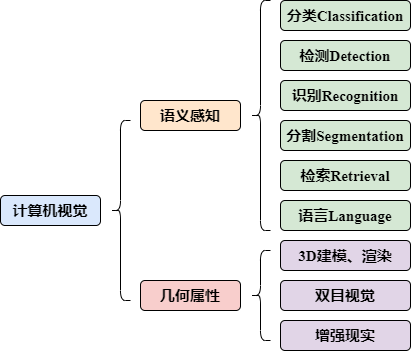
大体上讲,计算机视觉所研究的对象可以分为两类。第一是语义感知,第二是几何属性。
语义感知是目前研究最为广泛的领域,其中包括这不少于六个研究方向。包括分类(classification)、检测(detection)、识别(recognition)、分割(segmentation)、检索(retrieval)、语言(language)。
1、分类(classification)
视觉模型执行分类任务的对象通常是物体,简单说就是将图像中的主要元素进行分类。
2、检测(detection)
检测任务不仅需要分类,还需要进行多个目标的检测,并分别输出它们的置信度。
3、识别(recognition)
识别任务更加精确,需要区分同一种物体的细节不同,例如人脸识别、指纹识别等等。
4、分割(segmentation)
分割是指将目标物体从图像中“扣”出来。
5、检索(retrieval)
检索主要包括以文搜图、以图搜图等形式。
6、语言(language)
语言需要解决的是模型对图片的理解能力,进行问答或者语言描述。
三、可视化
四、总结
文章重点将其研究内容分为语义感知和几何属性两大类,并详细介绍了语义感知的六个核心任务:分类、检测、识别、分割、检索和基于图像的语言理解,清晰地勾勒出了该领域的技术框架。