ResNet(残差网络)-彻底改变深度神经网络的训练方式
ResNet 网络是在 2015年 由微软实验室中的何凯明等几位大神提出,斩获当年ImageNet竞赛中分类任务第一名,目标检测第一名。获得COCO数据集中目标检测第一名,图像分割第一名。
这个网络没有改变卷积神经网络的算法原理,只是在逻辑上对网络结构做出修改,但效果极好以至于残差学习的思想被引入到自然语言处理任务中,如文本分类和机器翻译,提升了模型的训练效率和性能。
模型引入
ResNet对网络的改进主要在于引入了残差块,使用跳跃连接。我们为什么引入这些这些呢?原来我们讲过,如果我们的传统神经网络层数很高,在参数传递的过程中很容易发生梯度消失和梯度爆炸,那么我们训练结果就会不受控,准确率降低。梯度消失和梯度爆炸主要首三种情况影响。然后我们残差网络可以很好解决这种情况。
梯度消失和梯度爆炸的三种情况
1 激活函数影响
在原来我们采取的措施是把sigmoid函数换成Relu函数
| 特性 | Sigmoid | ReLU |
|---|---|---|
| 数学表达式 | f(x)=1+e−x1 | f(x)=max(0,x) |
| 输出范围 | (0,1) | [0,+∞) |
| 导数特性 | 取值范围 (0,0.25],输入绝对值较大时接近0 | 正区间导数为1,负区间导数为0 |
| 计算效率 | 涉及指数运算,计算成本相对较高 | 仅需比较运算,计算简单高效 |
| 零中心输出 | 否,输出恒为正 | 否,输出非负 |
| 稀疏激活 | 否,输出稠密 | 是,约50%神经元被抑制 |
| 主要问题 | 梯度消失、输出非零中心 | 死亡 ReLU (神经元永久性失活) |
| 适用场景 | 二分类问题的输出层(输出概率) | 隐藏层,尤其是深层CNN和大型数据集 |
2 层数过深
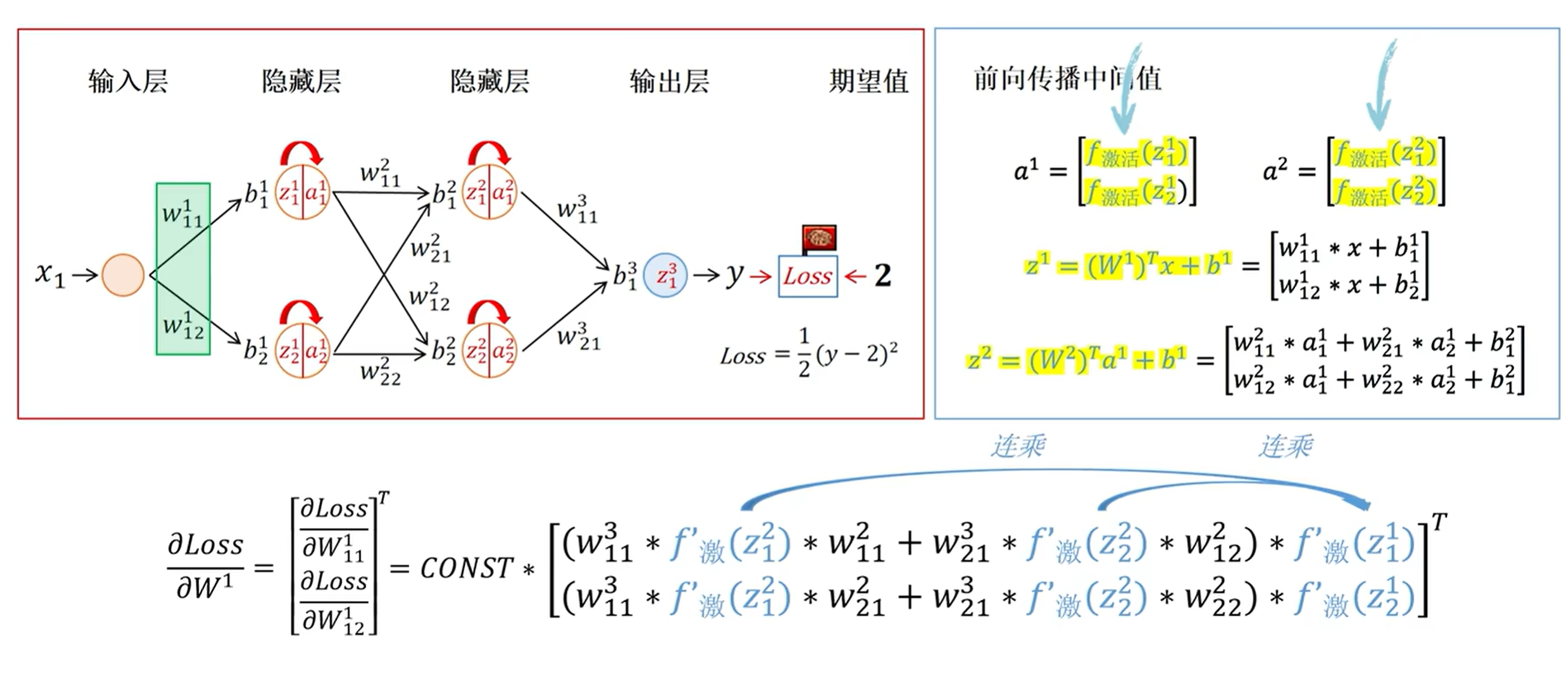
当我们初始化梯度小于1或者大于1的时候,
我们梯度更新的时候参数都是连乘的,如果我们初始化参数大于1,或者小于1,这样经过连乘就会产生梯度消失或者梯度爆炸的情况。
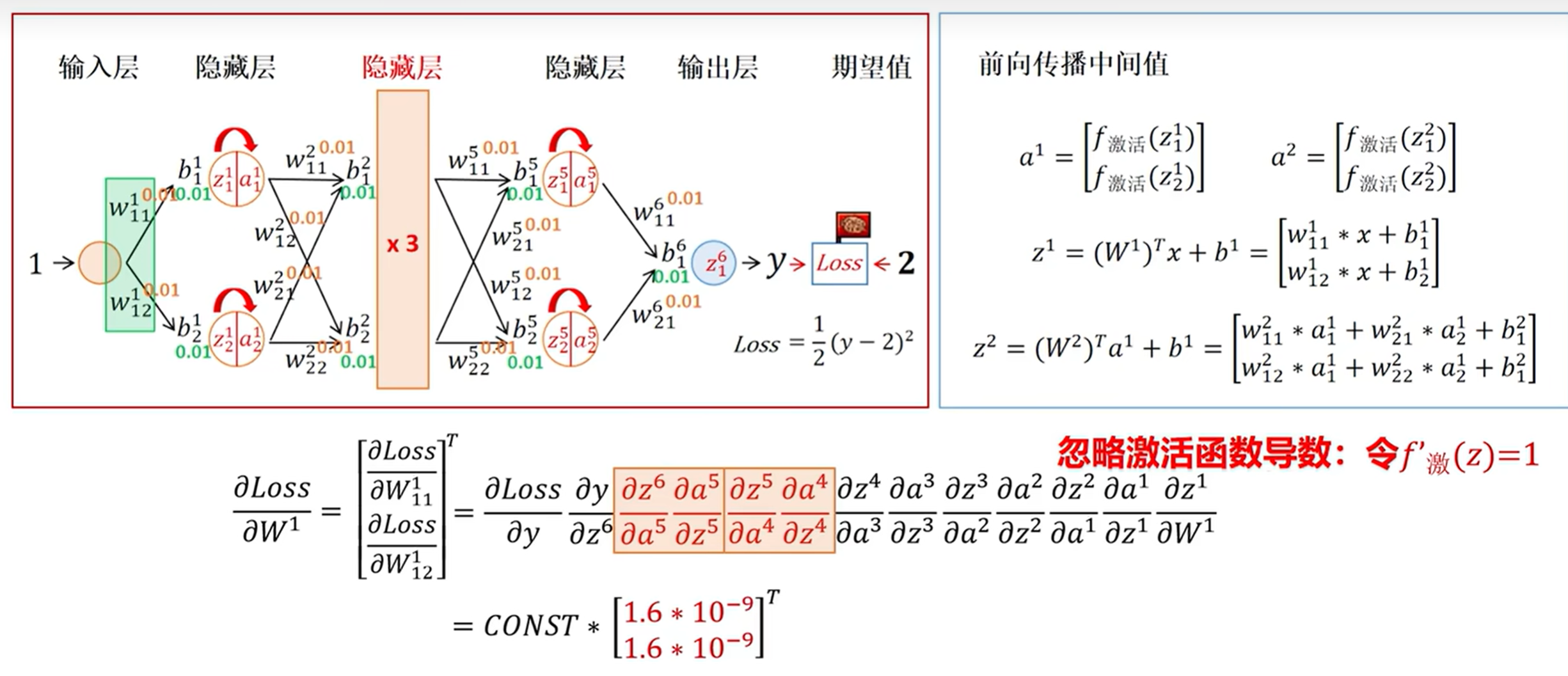
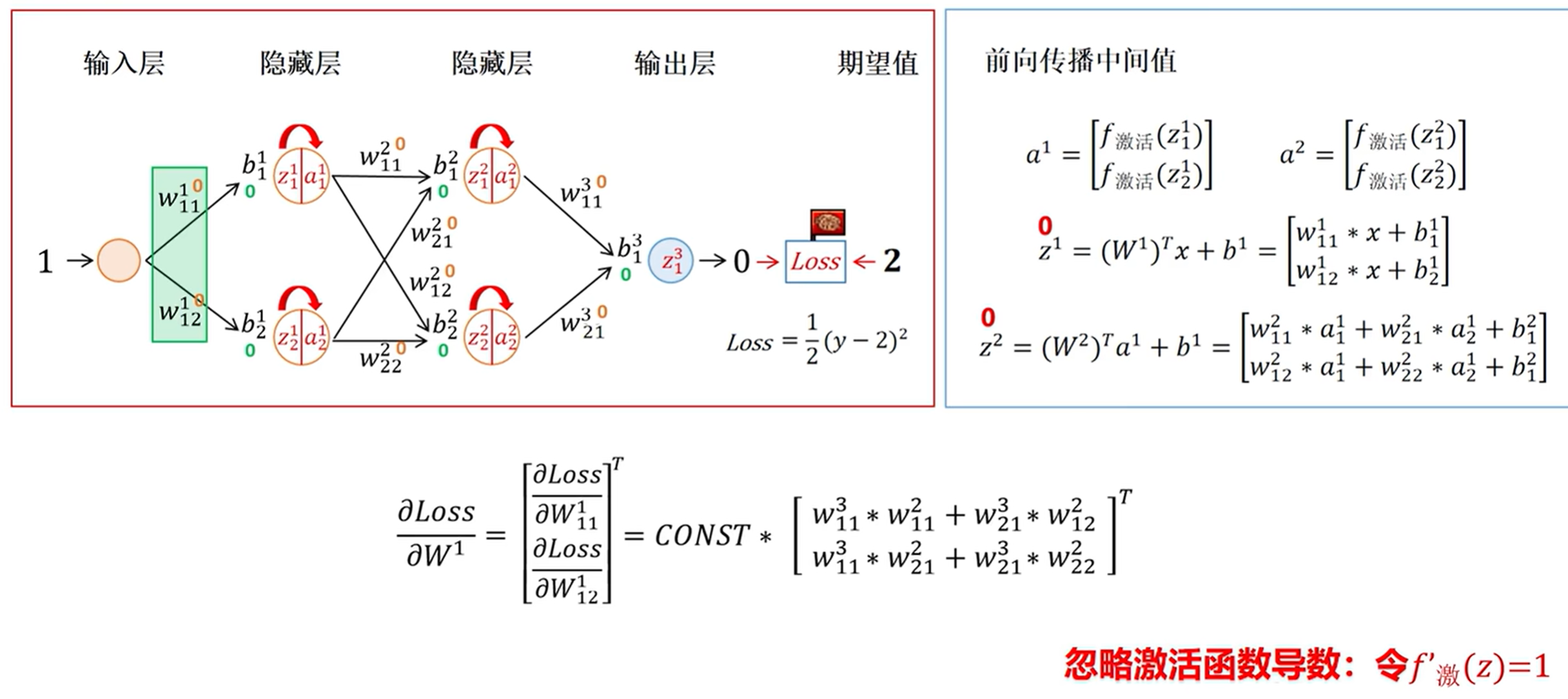
3 初始权重过小

例如这个取0.01,然后得到的值就会非常低了。

这样就会梯度消失,如果我们初始化值特别大,连乘之后结果就会特别大。
解决问题
ResNet在每一层都进行了Batch Normalization,把每一层的梯度进行了归一化。
那么对于梯度消失的或者梯度爆炸的,我们可以把那一层W设置为0,那么这一层就影响不到我们的原本的性能了。然后再加上了我们的副本X,对结果就没有影响了。
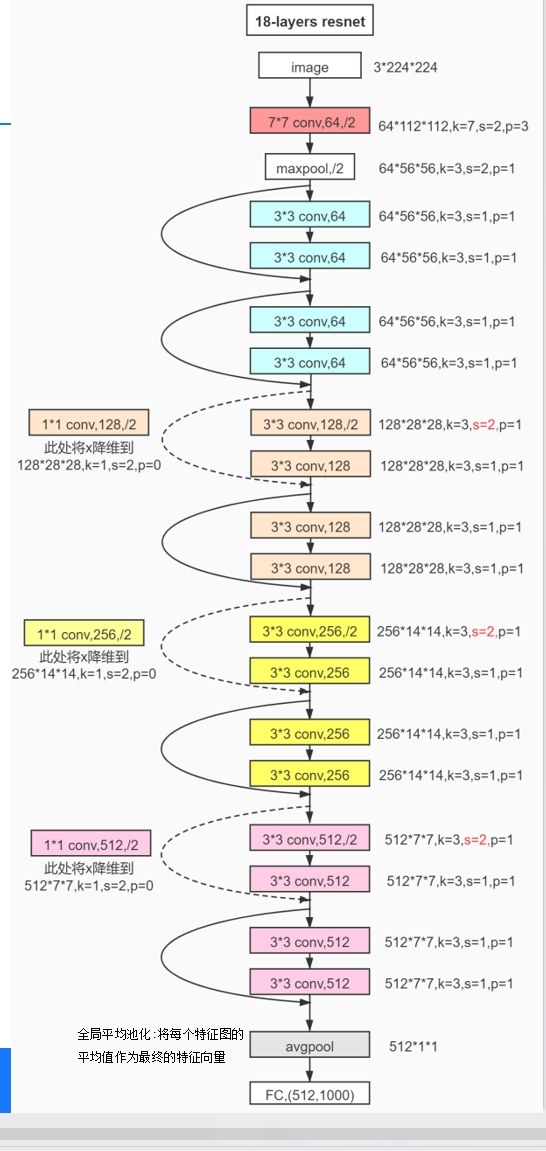
放大看就是这样的。我们这里引入一个残差块,来保存一个副本X,然后如果我这里如果把模型训练坏了,我再进行参数调整的时候,我们可以把这块参数设置为0,就是把跳跃的那一段给省略掉,也不至于让我们的模型更差。所以可以总结为,随着网路层数的增加,不应当让我们的网络性能变的更差。
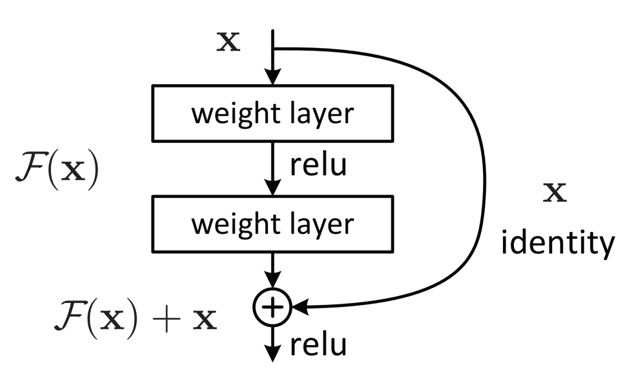
残差网络
代码部分
import torch
from torch.optim.lr_scheduler import ReduceLROnPlateauprint(torch.__version__)import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensortraining_data=datasets.MNIST(root='./data',train=True,download=True,transform=ToTensor())test_data=datasets.MNIST(root='./data',train=False,download=True,transform=ToTensor())train_dataloader=DataLoader(training_data,32)
test_dataloader=DataLoader(test_data,32)device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device)import torch.nn.functional as Fclass ResBlock(nn.Module):def __init__(self, channels_in): # channels_in: 输入特征图的通道数super().__init__()self.conv1 = torch.nn.Conv2d(channels_in, 30, 5, padding=2) # 卷积层1: 通道数 channels_in -> 30, 使用5x5卷积核,填充2以保持空间尺寸self.conv2 = torch.nn.Conv2d(30, channels_in, 3, padding=1) # 卷积层2: 通道数 30 -> channels_in, 使用5x5卷积核,填充1def forward(self, x):out = self.conv1(x) # 数据通过第一层卷积out = F.relu(out)out = self.conv2(out) # 数据通过第二层卷积out = F.relu(out)return F.relu(out + x) # 关键步骤: 将输出(out)与原始输入(x)相加,然后通过ReLU激活函数# 这里的 `out + x` 就是残差连接class ResNet(nn.Module):def __init__(self):super().__init__()self.conv1 = torch.nn.Conv2d(1, 20, 5, padding=2)self.conv2 = torch.nn.Conv2d(20, 40, 3, padding=1)self.conv3 = torch.nn.Conv2d(40, 80, 3, padding=1)self.conv4 = torch.nn.Conv2d(80, 160, 3, padding=1)self.maxpool = torch.nn.MaxPool2d(2, 2)self.resblock1 = ResBlock(channels_in=20)self.resblock2 = ResBlock(channels_in=40)self.resblock3 = ResBlock(channels_in=80)self.full_c = torch.nn.Linear(160, 10)def forward(self, x):size = x.shape[0] # 获取批处理大小(batch_size)# 第一组: 卷积 -> 池化(带ReLU激活)x=self.conv1(x)x=self.resblock1(x)x=F.relu(x)x=self.maxpool(x)x = self.conv2(x)x = self.resblock2(x)x = F.relu(x)x = self.maxpool(x)x = self.conv3(x)x = self.resblock3(x)x = F.relu(x)x = self.maxpool(x)x = self.conv4(x)x =F.relu(x)x = self.maxpool(x)x=x.view(size, -1)x=self.full_c(x)return xmodel = ResNet()
model.to(device)
loss_fn = nn.CrossEntropyLoss()
# optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)scheduler = ReduceLROnPlateau(optimizer,mode='min', # 监控验证损失,越小越好factor=0.1, # 每次降低10倍patience=5, # 给5个epoch的机会verbose=True, # 打印更新信息min_lr=1e-6) # 最低学习率def train(dataloader,model,loss_fn,optimizer):model.train()batch_size_num=1for X, y in dataloader:X,y=X.to(device),y.to(device)output = model(X) #model和model.forward一样效果loss = loss_fn(output,y)optimizer.zero_grad()loss.backward()optimizer.step()a=loss.item()if batch_size_num %100 ==0:print(f"Batch size: {batch_size_num}, Loss: {a}")batch_size_num+=1# print(model)return lossdef test(dataloader,model,loss_fn):size = len(dataloader.dataset)num_batches = len(dataloader)model.eval()batch_size_num=1loss,correct=0,0with torch.no_grad():for X, y in dataloader:X,y=X.to(device),y.to(device)pred = model(X)loss = loss_fn(pred,y)+losscorrect += (pred.argmax(1) == y).type(torch.float).sum().item()loss/=num_batchescorrect/=sizeprint(f'Test result: \n Accuracy: {(100*correct)}%,Avg loss: {loss}')return correct# model.to(device)
# model.load_state_dict(torch.load('best_model.pth'))
# model.eval()
# loss_fn = nn.CrossEntropyLoss()
# # # # optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
# # optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# # test(test_dataloader,model,loss_fn)
# test(train_dataloader,model,loss_fn)# train(train_dataloader,model,loss_fn,optimizer)
# test(test_dataloader,model,loss_fn)
accuracy_list=[]
best_acc=0
epochs=25
for i in range(epochs):print(f"Epoch {i+1}")loss=train(train_dataloader,model,loss_fn,optimizer)corrects = test(test_dataloader,model,loss_fn)accuracy_list.append(corrects)if corrects>best_acc:print(f"Best Accuracy: {corrects}%")best_acc=corrects#第一种torch.save(model.state_dict(),'best_model.pth')#第二种# torch.save(model,'best1.pth')scheduler.step(loss)
print('最高:',best_acc)
print(accuracy_list)
model = ResNet()import matplotlib.pyplot as plt# 假设这是你的准确率数据,请替换为你的实际数据
# accuracy_list 应为一个列表,包含每个epoch后的准确率值
epochs = list(range(1, len(accuracy_list) + 1)) # 横坐标,从1开始# 创建图表
plt.figure(figsize=(10, 6)) # 设置图表大小# 绘制准确率曲线
plt.plot(epochs, accuracy_list, marker='o', linestyle='-', linewidth=2, markersize=6, label='Training Accuracy')# 设置图表标题和坐标轴标签
plt.title('Model Accuracy over Epochs', fontsize=15)
plt.xlabel('Epoch', fontsize=12)
plt.ylabel('Accuracy', fontsize=12)# 设置坐标轴范围,可以根据你的数据调整
plt.xlim(1, len(accuracy_list))
plt.ylim(min(accuracy_list) - 0.01, max(accuracy_list) + 0.05) # 留一些边距# 添加网格线以便于读取数值
plt.grid(True, alpha=0.3)# 显示图例
plt.legend()# 显示图表
plt.tight_layout()
plt.show()