机器学习基础-day06-TensorFlow线性回归
TensorFlow 是一个开源的机器学习框架,由 Google Brain 团队开发。它被广泛用于各种机器学习任务,从简单的线性回归到复杂的深度学习模型。
1 TensorFlow核心概念
1.1 张量 (Tensors)
张量是 TensorFlow 中的基本数据结构,可以看作是多维数组。张量有三个主要属性:
秩 (Rank):张量的维度数量(0维是标量,1维是向量,2维是矩阵等)
形状 (Shape):每个维度的大小
数据类型 (Data Type):张量中元素的类型(如 float32, int32 等)
# 创建张量的示例
scalar = tf.constant(5) # 0维张量(标量)
vector = tf.constant([1, 2, 3]) # 1维张量(向量)
matrix = tf.constant([[1, 2], [3, 4]]) # 2维张量(矩阵)1.2 计算图 (Computational Graph)
TensorFlow 使用计算图来表示计算任务。图由两种元素组成:
节点 (Nodes):表示操作(如加法、乘法等)
边 (Edges):表示张量,在节点之间流动
在 TensorFlow 2.x 中,默认使用 eager execution(即时执行),但底层仍然使用计算图。
1.3 操作 (Operations)
操作是计算图中的节点,它们接受零个或多个张量作为输入,并产生零个或多个张量作为输出。
# 操作示例
a = tf.constant(5)
b = tf.constant(3)
c = tf.add(a, b) # 加法操作1.4 变量 (Variables)
变量用于存储模型参数,在训练过程中会被更新。
# 变量示例
w = tf.Variable(0.5) # 创建初始值为0.5的变量
b = tf.Variable(1.0) # 创建初始值为1.0的变量2 模型训练流程
创建模型后,通常还需要:
2.1 编译模型
指定优化器、损失函数和评估指标
model.compile(optimizer='adam', # 优化器loss='sparse_categorical_crossentropy', # 损失函数metrics=['accuracy'] # 评估指标
)2.2 训练模型
使用训练数据拟合模型
history = model.fit(x_train, y_train, # 训练数据batch_size=32, # 批量大小epochs=10, # 训练轮数validation_data=(x_val, y_val) # 验证数据
)2.3 评估模型
检查模型在测试数据上的表现
test_loss, test_acc = model.evaluate(x_test, y_test)
print(f'Test accuracy: {test_acc}')2.4 使用模型
进行测试
predictions = model.predict(x_new)3 算法实现
import tensorflow as tf # TensorFlow用于构建和训练神经网络
import numpy as np # NumPy用于数值计算和数组操作# 1. 散点输入
data = [[-0.5, 7.7], [1.8, 98.5], [0.9, 57.8], [0.4, 39.2], [-1.4, -15.7], [-1.4, -37.3], [-1.8, -49.1], [1.5, 75.6],[0.4, 34.0], [0.8, 62.3]]
# data列表 10*2 十行两列,定义了一个包含10个数据点的列表,每个点是一个二维坐标[x, y]# 转换成numpy数组
data = np.array(data)
x_data = data[:, 0]
y_data = data[:, 1]
# 将列表转换为NumPy数组,然后分离出x值(第一列)和y值(第二列)。# 转换成tf的张量
x_train = tf.constant(x_data, dtype=tf.float32) # 将NumPy数组转换为TensorFlow常量张量,并指定数据类型为float32
y_train = tf.constant(y_data, dtype=tf.float32) # 将NumPy数组转换为TensorFlow常量张量,并指定数据类型为float32
print(x_train)
print(y_train)# 2. 定义前向模型
# 参数是一个列表,因为可能会有多个网络,本例只有一个网络
model = tf.keras.Sequential([tf.keras.layers.Dense(1, input_shape=(1,))] # 第一个1输出1个,第2个1表示输入1个
)
"""
创建一个Sequential模型,包含一个全连接层(Dense):1表示输出维度为1(单输出)input_shape=(1,)表示输入是单个数值
"""# 3. 定义损失函数和优化器
optimizer = tf.keras.optimizers.SGD(learning_rate=0.01 # 学习率
) # 创建随机梯度下降(SGD)优化器,设置学习率为0.01# 编译模型:让模型与优化器适配,指定优化器和损失函数(均方误差)。
model.compile(optimizer, # 优化器loss="mean_squared_error" # MSE
)# 4. 开始迭代
epochs = 500
for n in range(1, epochs + 1):# 开始模型训练,返回值包含损失函数等数值history = model.fit(x_train,y_train,verbose=0 # 禁止训练时fit方法输出)"""进行500次训练迭代,每次迭代使用全部数据训练模型,verbose=0表示不显示训练过程。"""# 5. 显示频率设置if n == 1 or n % 10 == 0:# 总的损失函数loss = history.history["loss"][0]print(f"epoch:{n},loss:{loss}")# w和bweights = model.layers[0].get_weights()# print(weights)w = weights[0][0][0]b = weights[1][0]print(f"w={w},b={b}")print("---------------")"""每10次迭代输出一次训练结果,包括:当前迭代次数损失值模型的权重(w)和偏置(b)"""代码运行结果: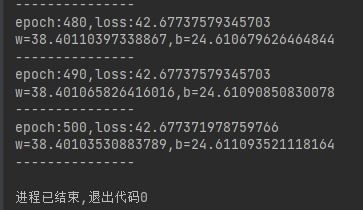
PyTorch训练的时候梯度下降的速度比TensorFlow要快,因此实际开发中PyTorch更容易过拟合,相反TensorFlow更容易欠拟合,通常的模型下两者的超参数可能需要手动修改一下才能达到理想的效果。
上面的写法主要是为了更贴合之前的PyTorch的写法,实际上TensorFlow可以更简单:
import tensorflow as tf # TensorFlow是用于机器学习的开源框架,
import numpy as np # NumPy是Python中用于科学计算的基础库# 1. 散点输入
data = [[-0.5, 7.7], [1.8, 98.5], [0.9, 57.8], [0.4, 39.2], [-1.4, -15.7], [-1.4, -37.3], [-1.8, -49.1], [1.5, 75.6],[0.4, 34.0], [0.8, 62.3]]
"""这里定义了一个包含10个数据点的列表,每个数据点是一个包含两个数值的子列表,表示(x, y)坐标对。"""
# data列表 10*2 十行两列
# 转换成numpy数组
data = np.array(data) # Python列表转换为NumPy数组,以便进行高效的数值计算。
x_data = data[:, 0]
y_data = data[:, 1]# 转换成tf的张量
x_train = tf.constant(x_data, dtype=tf.float32) # 将NumPy数组转换为TensorFlow常量张量,并指定数据类型为32位浮点数。
y_train = tf.constant(y_data, dtype=tf.float32)
print(x_train)
print(y_train)# 2. 定义前向模型
# 参数是一个列表,因为可能会有多个网络,本例只有一个网络
model = tf.keras.Sequential([tf.keras.layers.Dense(1, input_shape=(1,))] # 第一个1输出1个,第2个1表示输入1个
)
"""
创建一个顺序模型,包含一个全连接层(Dense):Dense(1)表示该层有1个神经元(输出维度为1)input_shape=(1,)表示输入数据的形状是1维的(每个样本只有一个特征)这相当于创建一个线性模型:y = wx + b,其中w是权重,b是偏置。
"""# 3. 定义损失函数和优化器
optimizer = tf.keras.optimizers.SGD(learning_rate=0.01 # 学习率
)
"""定义随机梯度下降(SGD)优化器,学习率设置为0.01。优化器的作用是根据损失函数的梯度更新模型参数。"""# 编译模型:让模型与优化器适配
model.compile(optimizer, # 优化器loss="mean_squared_error" # MSE
)
"""编译模型,指定使用的优化器和损失函数。这里使用均方误差(MSE)作为损失函数。"""# 4. 开始迭代
epochs = 500
history = model.fit(x_train,y_train,epochs=epochs # 告诉fit迭代多少次,自动迭代
)
# fit 可以直接打印,迭代后自行直接输出
"""
设置训练轮数为500,然后使用fit方法训练模型:x_train: 输入数据 y_train: 目标数据 epochs: 训练轮数训练过程中,模型会尝试找到最佳的w和b值,使预测值与真实值之间的均方误差最小。
"""
# 【下面是仿Pytorch代码】
# for n in range(1, epochs + 1):
# # 开始模型训练,返回值包含损失函数等数值
# history = model.fit(
# x_train,
# y_train,
# verbose=0 # 禁止训练时fit方法输出
# )
#
# # 5. 显示频率设置
# if n == 1 or n % 10 == 0:
# # 总的损失函数
# loss = history.history["loss"][0]
# print(f"epoch:{n},loss:{loss}")
# # w和b
# weights = model.layers[0].get_weights()
# # print(weights)
# w = weights[0][0][0]
# b = weights[1][0]
# print(f"w={w},b={b}")
# print("---------------")运行结果: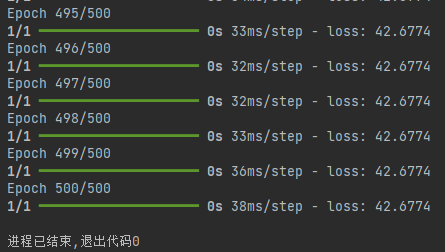
什么是梯度?
在机器学习中,梯度是一个向量,表示函数在某一点上的方向导数沿着该方向取得最大值。
简单来说,梯度指向函数增长最快的方向,而负梯度指向函数下降最快的方向。
对于线性回归问题,我们的损失函数是均方误差(MSE):
L(w, b) = (1/n) * Σ(y_i - (w*x_i + b))^2
梯度计算,我们需要计算损失函数对参数w和b的偏导数:
对w的偏导数:∂L/∂w = (2/n) * Σ(y_i - (w*x_i + b)) * (-x_i)
对b的偏导数:∂L/∂b = (2/n) * Σ(y_i - (w*x_i + b)) * (-1)
梯度下降过程:
1.初始化参数w和b(通常是随机值或零)
2.前向传播:使用当前参数计算预测值
3.计算损失:比较预测值和真实值
4.反向传播:计算损失函数对各个参数的梯度
5.参数更新:沿着负梯度方向更新参数
6.重复步骤2-5直到收敛或达到最大迭代次数
学习率的作用:
学习率(learning_rate)控制每次参数更新的步长:
学习率太小:收敛速度慢,需要更多迭代次数
学习率太大:可能跳过最优解,甚至导致发散
TensorFlow中的梯度计算
在TensorFlow中,梯度计算是自动完成的:
当你定义模型和损失函数后,TensorFlow会构建计算图
在训练时,TensorFlow自动计算梯度(通过自动微分)
优化器使用这些梯度来更新参数
代码中的梯度应用
在上述代码中,虽然看不到显式的梯度计算,但TensorFlow在后台完成了:
计算预测值:y_pred = w*x + b
计算损失:MSE = mean((y_true - y_pred)^2)
计算梯度:∂L/∂w和∂L/∂b
更新参数:w = w - 0.01 * ∂L/∂w, b = b - 0.01 * ∂L/∂b
这个过程重复500次,直到损失函数收敛到最小值。
4 数据集加载
数据集比较大的时候,无法一次性加载到内存中,就分批次进行加载。
import tensorflow as tf # TensorFlow用于构建和训练机器学习模型
import numpy as np # NumPy用于数值计算# 【随机种子】
# torch.manual_seed(25)#在 PyTorch进行线性回归实现
tf.random.set_seed(25) # 设置随机种子为25,确保每次运行代码时随机过程(如权重初始化)的结果一致,便于结果复现。# 1. 散点输入
data = [[-0.5, 7.7], [1.8, 98.5], [0.9, 57.8], [0.4, 39.2], [-1.4, -15.7], [-1.4, -37.3], [-1.8, -49.1], [1.5, 75.6],[0.4, 34.0], [0.8, 62.3]]
# data列表 10*2 十行两列
# 转换成numpy数组
data = np.array(data)
# 组,然后分离出自变量x和因变量y。
x_data = data[:, 0]
y_data = data[:, 1]# 转换成tf的张量,将NumPy数组转换为TensorFlow常量张量,并指定数据类型为32位浮点数。
x_train = tf.constant(x_data, dtype=tf.float32)
y_train = tf.constant(y_data, dtype=tf.float32)
print(x_train)
print(y_train)# ----------------------start-------------------------# 打包x和y数据为Dataset
dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train)
) # 使用tf.data.Dataset.from_tensor_slices创建数据集,将x和y数据配对# for item in dataset: # 十个点的xy数据
# print(item)# 打乱顺序,参数要大于等于样本数
dataset = dataset.shuffle(buffer_size=10)
# 使用shuffle方法打乱数据顺序,buffer_size=10表示使用大小为10的缓冲区(等于样本总数)# for item in dataset: # 打乱后的十个点的xy数据
# print(item)# 设置批次,一个批次5个数据
dataset = dataset.batch(5) # 使用batch方法将数据分成批次,每批包含5个样本。# 预加载数据,参数可以加速,内部自动缓存
dataset = dataset.prefetch(buffer_size=tf.data.experimental.AUTOTUNE)
# 使用prefetch方法预加载数据,AUTOTUNE让TensorFlow自动决定预取缓冲区的最佳大小,提高数据加载效率。
for item in dataset: # 分批后的十个点的xy数据print(item)# ----------------------------end-------------------------------# 2. 定义前向模型
# 参数是一个列表,因为可能会有多个网络,本例只有一个网络
model = tf.keras.Sequential([tf.keras.layers.Dense(1, input_shape=(1,))] # 第一个1输出1个,第2个1表示输入1个
)
"""
创建一个顺序模型,包含一个全连接层(Dense):Dense(1)表示该层有1个神经元(输出维度为1) input_shape=(1,)表示输入数据的形状是1维的(每个样本只有一个特征)
这相当于创建一个线性模型:y = wx + b,其中w是权重,b是偏置。
"""# 3. 定义损失函数和优化器
optimizer = tf.keras.optimizers.SGD(learning_rate=0.01 # 学习率
)
# 编译模型:让模型与优化器适配
model.compile(optimizer, # 优化器loss="mean_squared_error" # MSE
)
# 定义随机梯度下降(SGD)优化器,学习率设置为0.01,
# 然后编译模型,指定使用的优化器和均方误差(MSE)损失函数。# 4. 开始迭代
epochs = 500
for n in range(1, epochs + 1):# ---------------------start2------------------------total_loss = 0 # 总损失for batch_x, batch_y in dataset:# 分批次训练,返回值是一个批次的损失函数值history = model.train_on_batch(batch_x,batch_y)# print(history)# 累加损失total_loss += history# 一次训练epoch的平均损失avg_loss = total_loss / len(dataset)"""自定义训练循环:外层循环遍历所有epoch(500次) 内层循环遍历每个批次的数据 使用train_on_batch方法对每个批次进行训练 计算并累加每个批次的损失 计算整个epoch的平均损失"""# 5. 显示频率设置if n == 1 or n % 10 == 0:# 总的损失函数print(f"epoch:{n},avg_loss:{avg_loss}")# w和bweights = model.layers[0].get_weights()# print(weights)w = weights[0][0][0]b = weights[1][0]print(f"w={w},b={b}")print("---------------")5 模型定义
5.1 方式1:在Sequential的构造函数中添加网络
import tensorflow as tf # TensorFlow用于构建和训练机器学习模型
import numpy as np # NumPy用于数值计算"""-----------------------0. 准备数据:创建数据集,打乱顺序,分批处理------------------------------"""
# 【随机种子】
# torch.manual_seed(25)#在 PyTorch进行线性回归实现
tf.random.set_seed(25) # 设置随机种子为25,确保每次运行代码时随机过程(如权重初始化)的结果一致,便于结果复现。# 1. 散点输入
data = [[-0.5, 7.7], [1.8, 98.5], [0.9, 57.8], [0.4, 39.2], [-1.4, -15.7], [-1.4, -37.3], [-1.8, -49.1], [1.5, 75.6],[0.4, 34.0], [0.8, 62.3]]
# data列表 10*2 十行两列
# 转换成numpy数组
data = np.array(data)
# 组,然后分离出自变量x和因变量y。
x_data = data[:, 0]
y_data = data[:, 1]# 转换成tf的张量,将NumPy数组转换为TensorFlow常量张量,并指定数据类型为32位浮点数。
x_train = tf.constant(x_data, dtype=tf.float32)
y_train = tf.constant(y_data, dtype=tf.float32)
print(x_train)
print(y_train)# 打包x和y数据为Dataset
dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train)
) # 使用tf.data.Dataset.from_tensor_slices创建数据集,将x和y数据配对# for item in dataset: # 十个点的xy数据
# print(item)# 打乱顺序,参数要大于等于样本数
dataset = dataset.shuffle(buffer_size=10)
# 使用shuffle方法打乱数据顺序,buffer_size=10表示使用大小为10的缓冲区(等于样本总数)# for item in dataset: # 打乱后的十个点的xy数据
# print(item)# 设置批次,一个批次5个数据
dataset = dataset.batch(5) # 使用batch方法将数据分成批次,每批包含5个样本。# 预加载数据,参数可以加速,内部自动缓存
dataset = dataset.prefetch(buffer_size=tf.data.experimental.AUTOTUNE)
# 使用prefetch方法预加载数据,AUTOTUNE让TensorFlow自动决定预取缓冲区的最佳大小,提高数据加载效率。
for item in dataset: # 分批后的十个点的xy数据print(item)"""-----------------------1. 创建模型------------------------------"""
# --------------------------start-------------------------------
# 2. 定义前向模型
# 参数是一个列表,因为可能会有多个网络,本例只有一个网络
model = tf.keras.Sequential([tf.keras.layers.Dense(1, input_shape=(1,))] # 第一个1输出1个,第2个1表示输入1个
)
"""
创建一个顺序模型,包含一个全连接层(Dense):Dense(1)表示该层有1个神经元(输出维度为1) input_shape=(1,)表示输入数据的形状是1维的(每个样本只有一个特征)
这相当于创建一个线性模型:y = wx + b,其中w是权重,b是偏置。
"""
# ----------------------------end-------------------------------"""-----------------------2. 编译模型------------------------------"""
# 3. 定义损失函数和优化器
optimizer = tf.keras.optimizers.SGD(learning_rate=0.01 # 学习率
)
# 编译模型:让模型与优化器适配
model.compile(optimizer, # 优化器loss="mean_squared_error" # MSE
)
# 定义随机梯度下降(SGD)优化器,学习率设置为0.01,
# 然后编译模型,指定使用的优化器和均方误差(MSE)损失函数。"""-----------------------3. 训练模型------------------------------"""
# 4. 开始迭代
epochs = 500
for n in range(1, epochs + 1):total_loss = 0 # 总损失for batch_x, batch_y in dataset:# 分批次训练,返回值是一个批次的损失函数值history = model.train_on_batch(batch_x,batch_y)# print(history)# 累加损失total_loss += history# 一次训练epoch的平均损失avg_loss = total_loss / len(dataset)"""自定义训练循环:外层循环遍历所有epoch(500次) 内层循环遍历每个批次的数据 使用train_on_batch方法对每个批次进行训练 计算并累加每个批次的损失 计算整个epoch的平均损失""""""-----------------------4. 评估模型------------------------------"""# 5. 显示频率设置if n == 1 or n % 10 == 0:# 总的损失函数print(f"epoch:{n},avg_loss:{avg_loss}")# w和bweights = model.layers[0].get_weights()# print(weights)w = weights[0][0][0]b = weights[1][0]print(f"w={w},b={b}")print("---------------")5.2 方式2:调用add函数
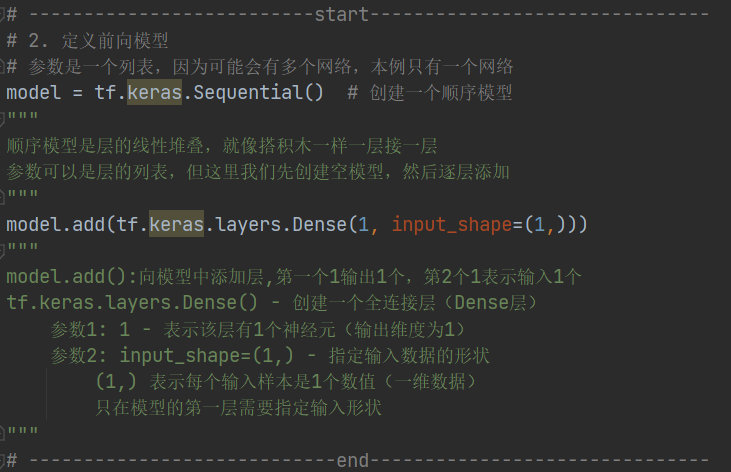
import tensorflow as tf # TensorFlow用于构建和训练机器学习模型import numpy as np # NumPy用于数值计算# 【随机种子】
# torch.manual_seed(25)#在 PyTorch进行线性回归实现
tf.random.set_seed(25) # 设置随机种子为25,确保每次运行代码时随机过程(如权重初始化)的结果一致,便于结果复现。# 1. 散点输入
data = [[-0.5, 7.7], [1.8, 98.5], [0.9, 57.8], [0.4, 39.2], [-1.4, -15.7], [-1.4, -37.3], [-1.8, -49.1], [1.5, 75.6],[0.4, 34.0], [0.8, 62.3]]
# data列表 10*2 十行两列
# 转换成numpy数组
data = np.array(data)
# 组,然后分离出自变量x和因变量y。
x_data = data[:, 0]
y_data = data[:, 1]# 转换成tf的张量,将NumPy数组转换为TensorFlow常量张量,并指定数据类型为32位浮点数。
x_train = tf.constant(x_data, dtype=tf.float32)
y_train = tf.constant(y_data, dtype=tf.float32)
print(x_train)
print(y_train)# 打包x和y数据为Dataset
dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train)
) # 使用tf.data.Dataset.from_tensor_slices创建数据集,将x和y数据配对# for item in dataset: # 十个点的xy数据
# print(item)# 打乱顺序,参数要大于等于样本数
dataset = dataset.shuffle(buffer_size=10)
# 使用shuffle方法打乱数据顺序,buffer_size=10表示使用大小为10的缓冲区(等于样本总数)# for item in dataset: # 打乱后的十个点的xy数据
# print(item)# 设置批次,一个批次5个数据
dataset = dataset.batch(5) # 使用batch方法将数据分成批次,每批包含5个样本。# 预加载数据,参数可以加速,内部自动缓存
dataset = dataset.prefetch(buffer_size=tf.data.experimental.AUTOTUNE)
# 使用prefetch方法预加载数据,AUTOTUNE让TensorFlow自动决定预取缓冲区的最佳大小,提高数据加载效率。
for item in dataset: # 分批后的十个点的xy数据print(item)# --------------------------start-------------------------------
# 2. 定义前向模型
# 参数是一个列表,因为可能会有多个网络,本例只有一个网络
model = tf.keras.Sequential() # 创建一个顺序模型
"""
顺序模型是层的线性堆叠,就像搭积木一样一层接一层
参数可以是层的列表,但这里我们先创建空模型,然后逐层添加
"""
model.add(tf.keras.layers.Dense(1, input_shape=(1,)))
"""
model.add():向模型中添加层,第一个1输出1个,第2个1表示输入1个
tf.keras.layers.Dense() - 创建一个全连接层(Dense层)参数1: 1 - 表示该层有1个神经元(输出维度为1) 参数2: input_shape=(1,) - 指定输入数据的形状(1,) 表示每个输入样本是1个数值(一维数据)只在模型的第一层需要指定输入形状
"""
# ----------------------------end-------------------------------# 3. 定义损失函数和优化器
optimizer = tf.keras.optimizers.SGD(learning_rate=0.01 # 学习率
)
# 编译模型:让模型与优化器适配
model.compile(optimizer, # 优化器loss="mean_squared_error" # MSE
)
# 定义随机梯度下降(SGD)优化器,学习率设置为0.01,
# 然后编译模型,指定使用的优化器和均方误差(MSE)损失函数。# 4. 开始迭代
epochs = 500
for n in range(1, epochs + 1):total_loss = 0 # 总损失for batch_x, batch_y in dataset:# 分批次训练,返回值是一个批次的损失函数值history = model.train_on_batch(batch_x,batch_y)# print(history)# 累加损失total_loss += history# 一次训练epoch的平均损失avg_loss = total_loss / len(dataset)"""自定义训练循环:外层循环遍历所有epoch(500次) 内层循环遍历每个批次的数据 使用train_on_batch方法对每个批次进行训练 计算并累加每个批次的损失 计算整个epoch的平均损失"""# 5. 显示频率设置if n == 1 or n % 10 == 0:# 总的损失函数print(f"epoch:{n},avg_loss:{avg_loss}")# w和bweights = model.layers[0].get_weights()# print(weights)w = weights[0][0][0]b = weights[1][0]print(f"w={w},b={b}")print("---------------")5.3 方式3:先 Input
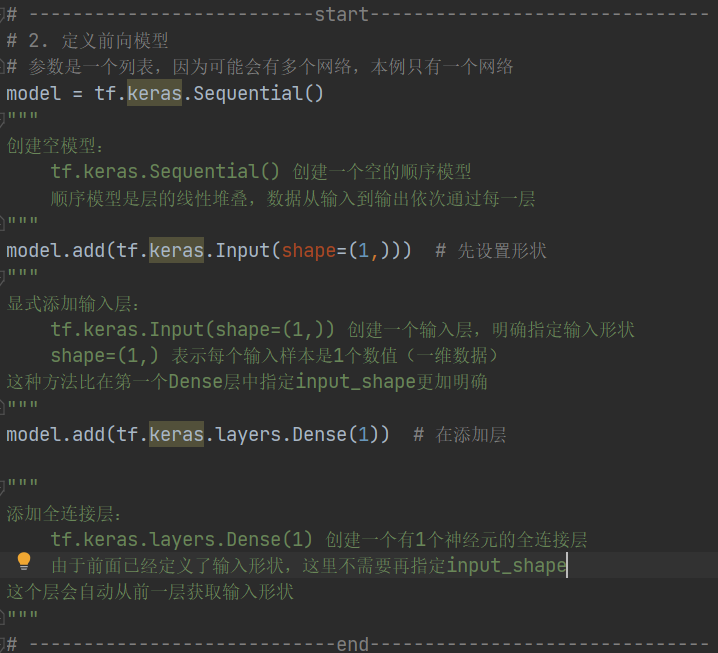
import tensorflow as tf # TensorFlow用于构建和训练机器学习模型
import numpy as np # NumPy用于数值计算# 【随机种子】
# torch.manual_seed(25)#在 PyTorch进行线性回归实现
tf.random.set_seed(25) # 设置随机种子为25,确保每次运行代码时随机过程(如权重初始化)的结果一致,便于结果复现。# 1. 散点输入
data = [[-0.5, 7.7], [1.8, 98.5], [0.9, 57.8], [0.4, 39.2], [-1.4, -15.7], [-1.4, -37.3], [-1.8, -49.1], [1.5, 75.6],[0.4, 34.0], [0.8, 62.3]]
# data列表 10*2 十行两列
# 转换成numpy数组
data = np.array(data)
# 组,然后分离出自变量x和因变量y。
x_data = data[:, 0]
y_data = data[:, 1]# 转换成tf的张量,将NumPy数组转换为TensorFlow常量张量,并指定数据类型为32位浮点数。
x_train = tf.constant(x_data, dtype=tf.float32)
y_train = tf.constant(y_data, dtype=tf.float32)
print(x_train)
print(y_train)# 打包x和y数据为Dataset
dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train)
) # 使用tf.data.Dataset.from_tensor_slices创建数据集,将x和y数据配对# for item in dataset: # 十个点的xy数据
# print(item)# 打乱顺序,参数要大于等于样本数
dataset = dataset.shuffle(buffer_size=10)
# 使用shuffle方法打乱数据顺序,buffer_size=10表示使用大小为10的缓冲区(等于样本总数)# for item in dataset: # 打乱后的十个点的xy数据
# print(item)# 设置批次,一个批次5个数据
dataset = dataset.batch(5) # 使用batch方法将数据分成批次,每批包含5个样本。# 预加载数据,参数可以加速,内部自动缓存
dataset = dataset.prefetch(buffer_size=tf.data.experimental.AUTOTUNE)
# 使用prefetch方法预加载数据,AUTOTUNE让TensorFlow自动决定预取缓冲区的最佳大小,提高数据加载效率。
for item in dataset: # 分批后的十个点的xy数据print(item)# --------------------------start-------------------------------
# 2. 定义前向模型
# 参数是一个列表,因为可能会有多个网络,本例只有一个网络
model = tf.keras.Sequential()
"""
创建空模型:tf.keras.Sequential() 创建一个空的顺序模型顺序模型是层的线性堆叠,数据从输入到输出依次通过每一层
"""
model.add(tf.keras.Input(shape=(1,))) # 先设置形状
"""
显式添加输入层:tf.keras.Input(shape=(1,)) 创建一个输入层,明确指定输入形状shape=(1,) 表示每个输入样本是1个数值(一维数据)
这种方法比在第一个Dense层中指定input_shape更加明确
"""
model.add(tf.keras.layers.Dense(1)) # 在添加层"""
添加全连接层:tf.keras.layers.Dense(1) 创建一个有1个神经元的全连接层由于前面已经定义了输入形状,这里不需要再指定input_shape
这个层会自动从前一层获取输入形状
"""
# ----------------------------end-------------------------------# 3. 定义损失函数和优化器
optimizer = tf.keras.optimizers.SGD(learning_rate=0.01 # 学习率
)
# 编译模型:让模型与优化器适配
model.compile(optimizer, # 优化器loss="mean_squared_error" # MSE
)
# 定义随机梯度下降(SGD)优化器,学习率设置为0.01,
# 然后编译模型,指定使用的优化器和均方误差(MSE)损失函数。# 4. 开始迭代
epochs = 500
for n in range(1, epochs + 1):total_loss = 0 # 总损失for batch_x, batch_y in dataset:# 分批次训练,返回值是一个批次的损失函数值history = model.train_on_batch(batch_x,batch_y)# print(history)# 累加损失total_loss += history# 一次训练epoch的平均损失avg_loss = total_loss / len(dataset)"""自定义训练循环:外层循环遍历所有epoch(500次) 内层循环遍历每个批次的数据 使用train_on_batch方法对每个批次进行训练 计算并累加每个批次的损失 计算整个epoch的平均损失"""# 5. 显示频率设置if n == 1 or n % 10 == 0:# 总的损失函数print(f"epoch:{n},avg_loss:{avg_loss}")# w和bweights = model.layers[0].get_weights()# print(weights)w = weights[0][0][0]b = weights[1][0]print(f"w={w},b={b}")print("---------------")5.4 方式4:定义函数
import tensorflow as tf
import numpy as np# 【随机种子】
# torch.manual_seed(25)
tf.random.set_seed(25)# 1. 散点输入
data = [[-0.5, 7.7], [1.8, 98.5], [0.9, 57.8], [0.4, 39.2], [-1.4, -15.7], [-1.4, -37.3], [-1.8, -49.1], [1.5, 75.6],[0.4, 34.0], [0.8, 62.3]]
# data列表 10*2 十行两列
# 转换成numpy数组
data = np.array(data)
x_data = data[:, 0]
y_data = data[:, 1]# 转换成tf的张量
x_train = tf.constant(x_data, dtype=tf.float32)
y_train = tf.constant(y_data, dtype=tf.float32)
print(x_train)
print(y_train)# 打包x和y数据为Dataset
dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train)
)
# for item in dataset: # 十个点的xy数据
# print(item)# 打乱顺序,参数要大于等于样本数
dataset = dataset.shuffle(buffer_size=10)
# for item in dataset: # 打乱后的十个点的xy数据
# print(item)# 设置批次,一个批次5个数据
dataset = dataset.batch(5)# 预加载数据,参数可以加速,内部自动缓存
dataset = dataset.prefetch(buffer_size=tf.data.experimental.AUTOTUNE)
for item in dataset: # 分批后的十个点的xy数据print(item)# --------------------start----------------------
# 2. 定义前向模型
# 参数是一个列表,因为可能会有多个网络,本例只有一个网络
def linear():# 先定义输入input = tf.keras.Input(shape=(1,), # 输入的形状dtype=tf.float32 # 类型)# 定义线性层1layer1 = tf.keras.layers.Dense(1)(input)# 定义模型并加载线性层model = tf.keras.models.Model(inputs=input, outputs=layer1)# # 定义线性层2# layer2 = tf.keras.layers.Dense(1)(layer1)# # 定义模型并加载线性层# model = tf.keras.models.Model(inputs=input, outputs=layer2)return model# 创建模型
model = linear()# --------------------end----------------------# 3. 定义损失函数和优化器
optimizer = tf.keras.optimizers.SGD(learning_rate=0.01 # 学习率
)
# 编译模型:让模型与优化器适配
model.compile(optimizer, # 优化器loss="mean_squared_error" # MSE
)# 4. 开始迭代
epochs = 500
for n in range(1, epochs + 1):# ---------------------start2------------------------total_loss = 0 # 总损失for batch_x, batch_y in dataset:# 分批次训练,返回值是一个批次的损失函数值history = model.train_on_batch(batch_x,batch_y)# print(history)# 累加损失total_loss += history# 一次训练epoch的平均损失avg_loss = total_loss / len(dataset)# 5. 显示频率设置if n == 1 or n % 10 == 0:# 总的损失函数print(f"epoch:{n},avg_loss:{avg_loss}")# w和b# 【注意】此时layers[0]是输入层,layers[1]是输出层weights = model.layers[1].get_weights() # 在layer1中print(weights)w = weights[0][0][0]b = weights[1][0]print(f"w={w},b={b}")print("---------------")6 模型的保存与加载
6.1 保存
保存的格式为HDF5格式,扩展名为.h5
方案1:保存参数、模型结构、训练的配置等
方案2:只保存参数
import tensorflow as tf # TensorFlow是用于机器学习的开源框架,
import numpy as np # NumPy是Python中用于科学计算的基础库"""-----------------------0. 准备数据:创建数据集,打乱顺序,分批处理------------------------------"""
# 1. 散点输入
data = [[-0.5, 7.7], [1.8, 98.5], [0.9, 57.8], [0.4, 39.2], [-1.4, -15.7], [-1.4, -37.3], [-1.8, -49.1], [1.5, 75.6],[0.4, 34.0], [0.8, 62.3]]
"""这里定义了一个包含10个数据点的列表,每个数据点是一个包含两个数值的子列表,表示(x, y)坐标对。"""
# data列表 10*2 十行两列
# 转换成numpy数组
data = np.array(data) # Python列表转换为NumPy数组,以便进行高效的数值计算。
x_data = data[:, 0]
y_data = data[:, 1]# 转换成tf的张量
x_train = tf.constant(x_data, dtype=tf.float32) # 将NumPy数组转换为TensorFlow常量张量,并指定数据类型为32位浮点数。
y_train = tf.constant(y_data, dtype=tf.float32)
print(x_train)
print(y_train)"""-----------------------1. 创建模型------------------------------"""
# 2. 定义前向模型
# 参数是一个列表,因为可能会有多个网络,本例只有一个网络
model = tf.keras.Sequential([tf.keras.layers.Dense(1, input_shape=(1,))] # 第一个1输出1个,第2个1表示输入1个
)
"""
创建一个顺序模型,包含一个全连接层(Dense):Dense(1)表示该层有1个神经元(输出维度为1)input_shape=(1,)表示输入数据的形状是1维的(每个样本只有一个特征)这相当于创建一个线性模型:y = wx + b,其中w是权重,b是偏置。
""""""-----------------------2. 编译模型------------------------------"""
# 3. 定义损失函数和优化器
optimizer = tf.keras.optimizers.SGD(learning_rate=0.01 # 学习率
)
"""定义随机梯度下降(SGD)优化器,学习率设置为0.01。优化器的作用是根据损失函数的梯度更新模型参数。"""# 编译模型:让模型与优化器适配
model.compile(optimizer, # 优化器loss="mean_squared_error" # MSE
)
"""编译模型,指定使用的优化器和损失函数。这里使用均方误差(MSE)作为损失函数。""""""-----------------------3. 训练模型------------------------------"""
# 4. 开始迭代
epochs = 500
history = model.fit(x_train,y_train,epochs=epochs # 告诉fit迭代多少次,自动迭代
)
# fit 可以直接打印,迭代后自行直接输出
"""
设置训练轮数为500,然后使用fit方法训练模型:x_train: 输入数据 y_train: 目标数据 epochs: 训练轮数训练过程中,模型会尝试找到最佳的w和b值,使预测值与真实值之间的均方误差最小。
"""model.save('plan1_model.h5') # 方案1
model.save_weights('plan2.weights.h5') # 方案2
"""
保存的格式为HDF5格式,扩展名为.h5
方案1:保存参数、模型结构、训练的配置等
方案2:只保存参数
"""代码运行结果:
6.2 加载
6.2.1 加载方案1
加载方案1与保存方式1对应:保存时包含模型结构
与PyTorch相比,TensorFlow加载模型可以不手写类,因为模型文件里面有模型结构。
from keras import models # 从Keras库导入models模块"""Keras是一个高级神经网络API,models模块提供了创建、保存和加载模型的功能初学者提示: 这行代码让你能够使用Keras中与模型相关的功能
"""
import numpy as np"""
功能: 导入NumPy库并简写为np解释: NumPy是Python中用于科学计算的基础库,提供多维数组对象和各种数学函数初学者提示: np是社区约定俗成的缩写,后续代码中可以使用np.函数名()调用NumPy功能
"""# 加载模型
loaded_model = models.load_model('plan1_model.h5') # 加载之前训练好的神经网络模型
"""
load_model()函数从文件中加载已经训练好的模型
'plan1_model.h5'是模型文件名,.h5是Keras模型的标准保存格式
加载后的模型存储在变量loaded_model中
初学者提示: 这就像打开一个已经写好的文档,可以直接使用而不需要重新编写
"""
# 预测
input_data = np.array([[-0.7], [-1.3], [0], [1.33], [1.67]]) # 创建输入数据数组,即需要预测的数据
""" ***
输入数据的形状不正确。
神经网络期望的输入通常是二维数组(多个样本),即使只有一个样本也需要保持正确的形状。
***"""
"""
np.array()创建NumPy数组
数组中的5个数值是模型的输入特征
这些数值应该与模型训练时使用的数据格式相同(已经标准化/归一化)
初学者提示: 想象这是你要问模型的问题,这些数字是问题的描述
"""y_pre = loaded_model.predict(input_data) # 使用模型进行预测
"""
predict()方法使用加载的模型对输入数据进行预测
input_data作为输入传递给模型
预测结果存储在变量y_pre中
初学者提示: 这行代码相当于"让模型思考并给出答案"
"""
print(y_pre) # 打印预测结果代码运行结果: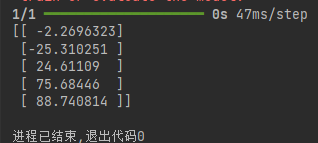
6.2.2 加载方案2
加载方案2与保存方式2对应:如果保存时谁用方案2,没有保存模型结构只有模型参数,此时加载时是需要手写模型结构代码的。
from keras import models # keras: 高级神经网络API
import tensorflow as tf # tensorflow: 机器学习框架,Keras的后端
import numpy as np # numpy: 科学计算库,处理数组数据def linear(): # 定义一个名为linear的函数,这个函数将创建一个简单的线性模型# 先定义输入input = tf.keras.Input( # 定义模型的输入层shape=(1,), # 输入的形状dtype=tf.float32 # 类型)"""shape=(1,): 指定每个输入样本的形状是1维的标量值dtype=tf.float32: 指定输入数据类型为32位浮点数初学者提示: 这定义了模型期望接收的数据格式"""# 定义线性层1layer1 = tf.keras.layers.Dense(1)(input) # 创建一个全连接层(Dense层)"""Dense(1): 创建一个有1个神经元的全连接层(input): 将输入连接到这一层这是最简单的神经网络层,执行线性变换: y = wx + b"""# 定义模型并加载线性层model = tf.keras.models.Model(inputs=input, outputs=layer1) # 创建模型实例"""inputs=input: 指定模型的输入outputs=layer1: 指定模型的输出 初学者提示: 这定义了从输入到输出的计算图"""return model # 返回创建的模型,函数执行完毕后,将模型对象返回给调用者# 创建模型对象
loaded_model = linear() # 调用linear函数创建模型实例
"""
执行linear()函数,将返回的模型赋值给变量loaded_model
初学者提示: 现在loaded_model是一个具有线性结构的神经网络
"""# 加载之前的训练参数
loaded_model.load_weights('plan2.weights.h5') # 加载预训练的权重
"""
load_weights(): 从文件加载模型权重
'plan2.weights.h5': 权重文件名
初学者提示: 这相当于给模型"灌输知识",使其具备预测能力
"""# 预测
input_data = np.array([[-0.7], [-1.3], [0], [1.33], [1.67]]) # 需要预测的数据
y_pre = loaded_model.predict(input_data) # 使用模型进行预测
"""
predict(): 模型的方法,对输入数据进行预测
将input_data传递给模型,得到预测结果
初学者提示: 这是模型"思考"并给出答案的过程
"""
print(y_pre)代码运行结果: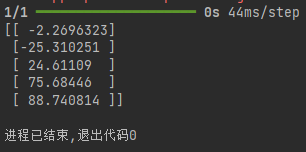
7 查看网络结构
基于下面代码查看网络结构:
import tensorflow as tf # TensorFlow是用于机器学习的开源框架,
import numpy as np # NumPy是Python中用于科学计算的基础库"""-----------------------0. 准备数据:创建数据集,打乱顺序,分批处理------------------------------"""
# 1. 散点输入
data = [[-0.5, 7.7], [1.8, 98.5], [0.9, 57.8], [0.4, 39.2], [-1.4, -15.7], [-1.4, -37.3], [-1.8, -49.1], [1.5, 75.6],[0.4, 34.0], [0.8, 62.3]]
"""这里定义了一个包含10个数据点的列表,每个数据点是一个包含两个数值的子列表,表示(x, y)坐标对。"""
# data列表 10*2 十行两列
# 转换成numpy数组
data = np.array(data) # Python列表转换为NumPy数组,以便进行高效的数值计算。
x_data = data[:, 0]
y_data = data[:, 1]# 转换成tf的张量
x_train = tf.constant(x_data, dtype=tf.float32) # 将NumPy数组转换为TensorFlow常量张量,并指定数据类型为32位浮点数。
y_train = tf.constant(y_data, dtype=tf.float32)
print(x_train)
print(y_train)"""-----------------------1. 创建模型------------------------------"""
# 2. 定义前向模型
# 参数是一个列表,因为可能会有多个网络,本例只有一个网络
model = tf.keras.Sequential([tf.keras.layers.Dense(1, input_shape=(1,))] # 第一个1输出1个,第2个1表示输入1个
)
"""
创建一个顺序模型,包含一个全连接层(Dense):Dense(1)表示该层有1个神经元(输出维度为1)input_shape=(1,)表示输入数据的形状是1维的(每个样本只有一个特征)这相当于创建一个线性模型:y = wx + b,其中w是权重,b是偏置。
""""""-----------------------2. 编译模型------------------------------"""
# 3. 定义损失函数和优化器
optimizer = tf.keras.optimizers.SGD(learning_rate=0.01 # 学习率
)
"""定义随机梯度下降(SGD)优化器,学习率设置为0.01。优化器的作用是根据损失函数的梯度更新模型参数。"""# 编译模型:让模型与优化器适配
model.compile(optimizer, # 优化器loss="mean_squared_error" # MSE
)
"""编译模型,指定使用的优化器和损失函数。这里使用均方误差(MSE)作为损失函数。""""""-----------------------3. 训练模型------------------------------"""
# 4. 开始迭代
epochs = 500
history = model.fit(x_train,y_train,epochs=epochs # 告诉fit迭代多少次,自动迭代
)
# fit 可以直接打印,迭代后自行直接输出
"""
设置训练轮数为500,然后使用fit方法训练模型:x_train: 输入数据 y_train: 目标数据 epochs: 训练轮数训练过程中,模型会尝试找到最佳的w和b值,使预测值与真实值之间的均方误差最小。
"""7.1 summary
import tensorflow as tf # tf是TensorFlow的主要模块,用于构建和训练神经网络
import numpy as np # np是NumPy库,用于科学计算,特别是数组操作# 1. 散点输入
data = [[-0.5, 7.7], [1.8, 98.5], [0.9, 57.8], [0.4, 39.2], [-1.4, -15.7], [-1.4, -37.3], [-1.8, -49.1], [1.5, 75.6],[0.4, 34.0], [0.8, 62.3]]
# data列表 10*2 十行两列
# 转换成numpy数组
data = np.array(data) # 将Python列表转换为NumPy数组,便于进行数值计算# 从数据数组中提取特征列和目标列
x_data = data[:, 0] # 获取所有行的第0列(x值)
y_data = data[:, 1] # 获取所有行的第1列(y值)# 转换成tf的张量
x_train = tf.constant(x_data, dtype=tf.float32)
y_train = tf.constant(y_data, dtype=tf.float32)
"""
将NumPy数组转换为TensorFlow张量
tf.constant创建不可变的张量
dtype=tf.float32指定数据类型为32位浮点数(神经网络常用)
"""
print(x_train)
print(y_train)# 2. 定义前向模型
# 参数是一个列表,因为可能会有多个网络,本例只有一个网络
model = tf.keras.Sequential([tf.keras.layers.Dense(1, input_shape=(1,))] # 第一个1输出1个,第2个1表示输入1个
)
"""
创建Sequential模型(线性堆叠层)
添加一个Dense(全连接)层:units=1:该层有1个神经元(输出维度为1)input_shape=(1,):输入是1维的标量(单个数值)
"""# 3. 定义损失函数和优化器
optimizer = tf.keras.optimizers.SGD(learning_rate=0.01 # 学习率
)
"""
创建随机梯度下降(SGD)优化器
learning_rate=0.01:设置学习率,控制每次参数更新的步长
"""
# 编译模型:让模型与优化器适配
model.compile(optimizer, # 优化器loss="mean_squared_error" # MSE
)
"""
编译模型,配置训练过程
optimizer:使用上面定义的SGD优化器
loss="mean_squared_error":使用均方误差作为损失函数
"""# 4. 开始迭代
epochs = 100
history = model.fit(x_train,y_train,epochs=epochs # 告诉fit迭代多少次,自动迭代
)
"""
设置训练轮数为100model.fit():开始训练模型
x_train, y_train:训练数据和标签
epochs=epochs:训练轮数
返回一个History对象,包含训练过程中的损失和指标值
"""# 输出网络结构
print(model.summary()) # 打印模型的结构信息,包括层类型、输出形状和参数数量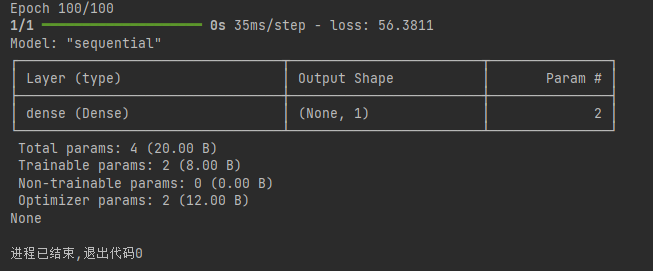
7.2 plot_model
使用前需要配置两个环境:pydot、graphviz
import tensorflow as tf
import numpy as np# 1. 散点输入
data = [[-0.5, 7.7], [1.8, 98.5], [0.9, 57.8], [0.4, 39.2], [-1.4, -15.7], [-1.4, -37.3], [-1.8, -49.1], [1.5, 75.6],[0.4, 34.0], [0.8, 62.3]]
# data列表 10*2 十行两列
# 转换成numpy数组
data = np.array(data)
x_data = data[:, 0]
y_data = data[:, 1]# 转换成tf的张量
x_train = tf.constant(x_data, dtype=tf.float32)
y_train = tf.constant(y_data, dtype=tf.float32)
print(x_train)
print(y_train)# 2. 定义前向模型
# 参数是一个列表,因为可能会有多个网络,本例只有一个网络
model = tf.keras.Sequential([tf.keras.layers.Dense(1, input_shape=(1,))] # 第一个1输出1个,第2个1表示输入1个
)# 3. 定义损失函数和优化器
optimizer = tf.keras.optimizers.SGD(learning_rate=0.01 # 学习率
)
# 编译模型:让模型与优化器适配
model.compile(optimizer, # 优化器loss="mean_squared_error" # MSE
)# 4. 开始迭代
epochs = 100
history = model.fit(x_train,y_train,epochs=epochs # 告诉fit迭代多少次,自动迭代
)# 方案2:
tf.keras.utils.plot_model(model, # 模型对象to_file='model.png', # 保存的文件名,图片格式show_shapes=True # 是否展示形状
)代码运行结果:
练习:
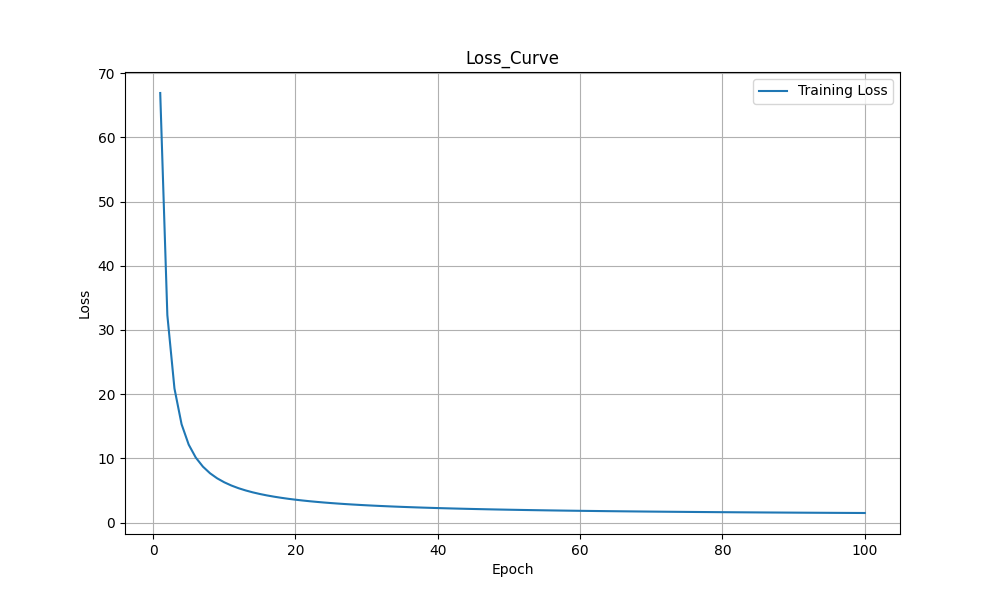
使用 TensorFlow 对100个点进行线性回归,生成昨天的损失函数图。
"""使用tf对100个点进行线性回归,生成昨天的损失函数图(可以使用tensorboard绘图)。"""
# 1.导入库
import tensorflow as tf
import numpy as np
from matplotlib import pyplot as plt# 2.数据准备
# 散点输入
x_data = [[1.09762701], # 输入特征[1.43037873],[1.20552675],[1.08976637],[0.8473096],[1.29178823],[0.87517442],[1.783546],[1.92732552],[0.76688304],[1.58345008],[1.05778984],[1.13608912],[1.85119328],[0.14207212],[0.1742586],[0.04043679],[1.66523969],[1.5563135],[1.7400243],[1.95723668],[1.59831713],[0.92295872],[1.56105835],[0.23654885],[1.27984204],[0.28670657],[1.88933783],[1.04369664],[0.82932388],[0.52911122],[1.54846738],[0.91230066],[1.1368679],[0.0375796],[1.23527099],[1.22419145],[1.23386799],[1.88749616],[1.3636406],[0.7190158],[0.87406391],[1.39526239],[0.12045094],[1.33353343],[1.34127574],[0.42076512],[0.2578526],[0.6308567],[0.72742154],[1.14039354],[0.87720303],[1.97674768],[0.20408962],[0.41775351],[0.32261904],[1.30621665],[0.50658321],[0.93262155],[0.48885118],[0.31793917],[0.22075028],[1.31265918],[0.2763659],[0.39316472],[0.73745034],[1.64198646],[0.19420255],[1.67588981],[0.19219682],[1.95291893],[0.9373024],[1.95352218],[1.20969104],[1.47852716],[0.07837558],[0.56561393],[0.24039312],[0.5922804],[0.23745544],[0.63596636],[0.82852599],[0.12829499],[1.38494424],[1.13320291],[0.53077898],[1.04649611],[0.18788102],[1.15189299],[1.8585924],[0.6371379],[1.33482076],[0.26359572],[1.43265441],[0.57881219],[0.36638272],[1.17302587],[0.04021509],[1.65788006],[0.00939095]]
y_data = [[6.12773118], # 目标值[9.19196269],[8.0822427],[5.73305541],[8.03018099],[9.77125385],[7.80430284],[9.17071317],[8.71122394],[7.35510084],[8.34717328],[8.39581459],[7.61654234],[10.53021887],[4.78258275],[5.22934897],[4.13181041],[10.78158957],[8.7958526],[9.62206225],[11.75486075],[7.44719232],[5.49839118],[9.65257177],[3.53652315],[9.78314731],[4.44650074],[8.92055869],[9.05403196],[7.96848643],[7.45489263],[9.55144679],[5.87567631],[9.32066865],[3.84473543],[8.50826938],[8.6198263],[7.54659389],[10.27656784],[9.01312847],[6.53347293],[5.52279093],[8.48402535],[5.68773873],[7.30603243],[7.87419268],[4.82714181],[6.62282151],[6.56486486],[6.58972646],[6.65126455],[7.17085827],[9.25591037],[4.64409942],[4.61741446],[5.6442904],[8.49524077],[5.31145086],[7.19387135],[4.37349204],[3.46255991],[5.10164255],[8.10465103],[5.46412914],[7.56263894],[7.15683051],[8.01313715],[5.69962394],[7.71176203],[4.11500584],[9.79051518],[8.52524993],[9.11581171],[6.80263458],[8.33712895],[3.57164847],[6.8234777],[3.64124786],[4.62937253],[4.27454627],[5.40986663],[8.41511002],[5.33430579],[8.24238396],[6.17417321],[6.43669992],[6.13927297],[3.01887197],[8.64370877],[9.8927198],[6.83227254],[8.32318993],[5.64761779],[7.64693763],[4.70219372],[5.78074269],[6.71566794],[3.4310955],[8.51810767],[4.04565202]]# 转换为 PyTorch 张量
# 转换为np数组
x_data = np.array(x_data).flatten() # 将列表转换为 NumPy 数组以便进行矩阵操作
y_data = np.array(y_data).flatten() # 将列表转换为 NumPy 数组以便进行矩阵操作
print(x_data)
print(y_data)# 转换成tf的张量
x_train = tf.constant(x_data, dtype=tf.float32) # 将NumPy数组转换为TensorFlow常量张量,并指定数据类型为32位浮点数。
y_train = tf.constant(y_data, dtype=tf.float32)
print(x_train)
print(y_train)# 打包x和y数据为Dataset
dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train)
) # 使用tf.data.Dataset.from_tensor_slices创建数据集,将x和y数据配对# for item in dataset: # 十个点的xy数据
# print(item)# 打乱顺序,参数要大于等于样本数
dataset = dataset.shuffle(buffer_size=10)
# 使用shuffle方法打乱数据顺序,buffer_size=10表示使用大小为10的缓冲区(等于样本总数)# for item in dataset: # 打乱后的十个点的xy数据
# print(item)# 设置批次,一个批次5个数据
dataset = dataset.batch(5) # 使用batch方法将数据分成批次,每批包含5个样本。# 预加载数据,参数可以加速,内部自动缓存
dataset = dataset.prefetch(buffer_size=tf.data.experimental.AUTOTUNE)
# 使用prefetch方法预加载数据,AUTOTUNE让TensorFlow自动决定预取缓冲区的最佳大小,提高数据加载效率。
for item in dataset: # 分批后的十个点的xy数据print(item)# 2. 定义前向模型
# 参数是一个列表,因为可能会有多个网络,本例只有一个网络
model = tf.keras.Sequential([tf.keras.layers.Dense(1, input_shape=(1,))]
)
"""
创建一个顺序模型,包含一个全连接层(Dense):Dense(1)表示该层有1个神经元(输出维度为1)input_shape=(1,)表示输入数据的形状是1维的(每个样本只有一个特征)这相当于创建一个线性模型:y = wx + b,其中w是权重,b是偏置。
"""
# 3.定义损失函数和优化器
optimizer = tf.keras.optimizers.SGD(learning_rate=0.01 # 学习率
)
"""定义随机梯度下降(SGD)优化器,学习率设置为0.01。优化器的作用是根据损失函数的梯度更新模型参数。"""# 编译模型:让模型与优化器适配
model.compile(optimizer, # 优化器loss='mean_squared_error' # MSE
)
"""编译模型,指定使用的优化器和损失函数。这里使用均方误差(MSE)作为损失函数。"""# 4.开始迭代
epochs = 100
losses = [] # 用于记录每个epoch的损失值for n in range(1, epochs + 1):total_loss = 0 # 总损失for batch_x, batch_y in dataset:# 分批次训练,返回值是一个批次的损失函数值history = model.train_on_batch(batch_x,batch_y)# print(history)# 累加损失total_loss += history# 一次训练epoch的平均损失avg_loss = total_loss / len(dataset)# 记录损失值losses.append(avg_loss.item()) # 使用.item()获取标量值"""自定义训练循环:外层循环遍历所有epoch(500次) 内层循环遍历每个批次的数据 使用train_on_batch方法对每个批次进行训练 计算并累加每个批次的损失 计算整个epoch的平均损失"""# 5. 显示频率设置if n == 1 or n % 10 == 0:# 总的损失函数print(f"epoch:{n},avg_loss:{avg_loss}")# w和bweights = model.layers[0].get_weights()# print(weights)w = weights[0][0][0]b = weights[1][0]print(f"w={w},b={b}")print("---------------")
# 8.绘制损失曲线
plt.figure(figsize=(10, 6)) # 创建图形窗口,设置大小
plt.plot(range(1, epochs + 1), losses, label='Training Loss')
"""
绘制折线图,x轴是epoch,y轴是loss
range(1, epochs + 1): 生成x轴的值(epoch编号)
range(start, stop) 生成从start开始到stop-1的整数序列
epochs 是训练的总轮次数(在代码中设置为500)
range(1, 501) 会生成 [1, 2, 3, ..., 500] 的序列
这样x轴就表示从第1个epoch到第500个epochlosses: 提供y轴的值(损失值)label='Training Loss'(训练损失): 为曲线设置标签
"""
plt.xlabel('Epoch') # x轴标签
plt.ylabel('Loss') # y轴标签
plt.title('Loss_Curve') # 标题
plt.legend() # 显示图例
plt.grid(True) # 显示网格线
# 保存图片
plt.savefig('Loss_Curvee_100_.png') # 保存图片
plt.show() # 显示图形"""
训练过程解析初始化: 模型参数w和b被随机初始化 前向传播: 计算预测值 y_pred = w*x + b 计算损失: 比较预测值和真实值,计算均方误差 反向传播: 计算损失关于参数的梯度 参数更新: 沿着梯度反方向更新参数,减小损失 重复: 重复上述过程,直到损失收敛或达到最大迭代次数随着训练的进行,可以看到:损失值逐渐减小 参数w和b逐渐接近最优值 梯度逐渐变小(接近零),表示接近最优解
"""代码运行结果: