逻辑回归基础
昨天一直在复盘梯度下降,都没咋预习逻辑回归,好在不是很难,来捋捋
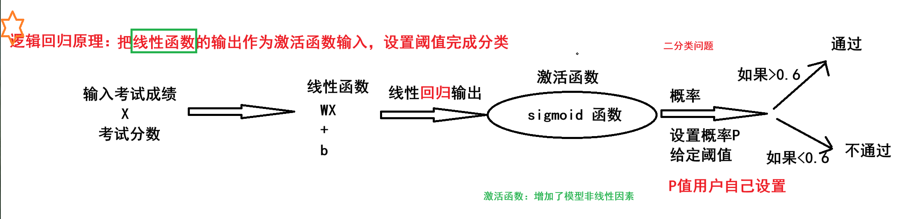
逻辑回归简介
逻辑回归是解决分类问题
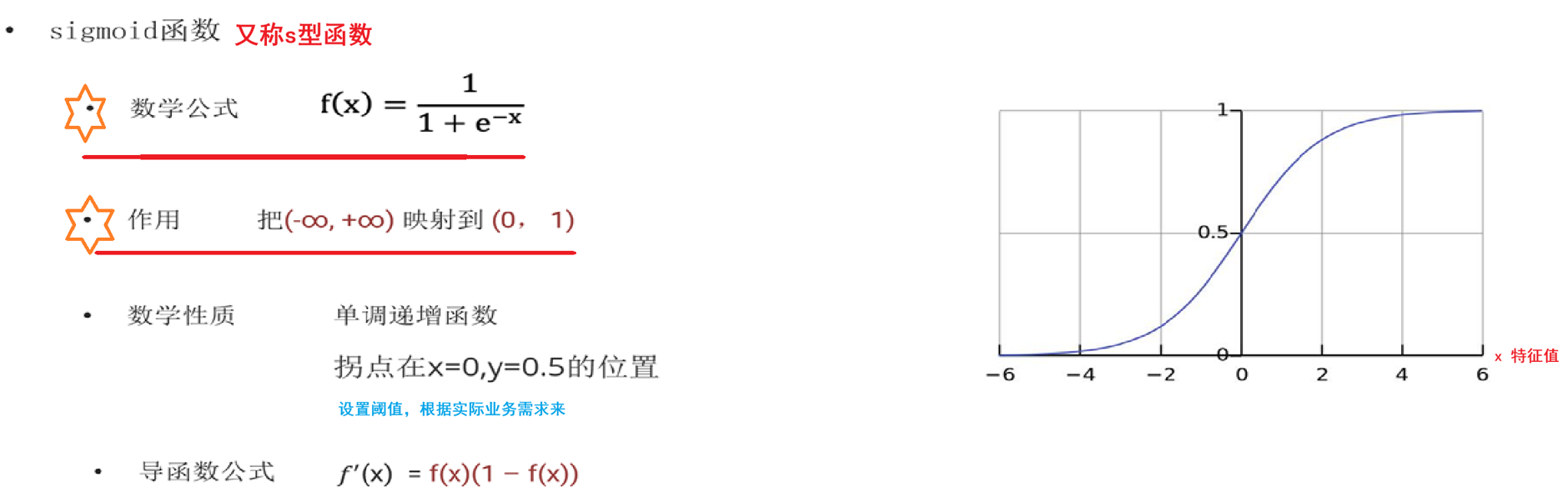
数学基础-sigmoid函数
还要回顾一下概率论

极大似然估计


再来看一下对数

逻辑回归原理

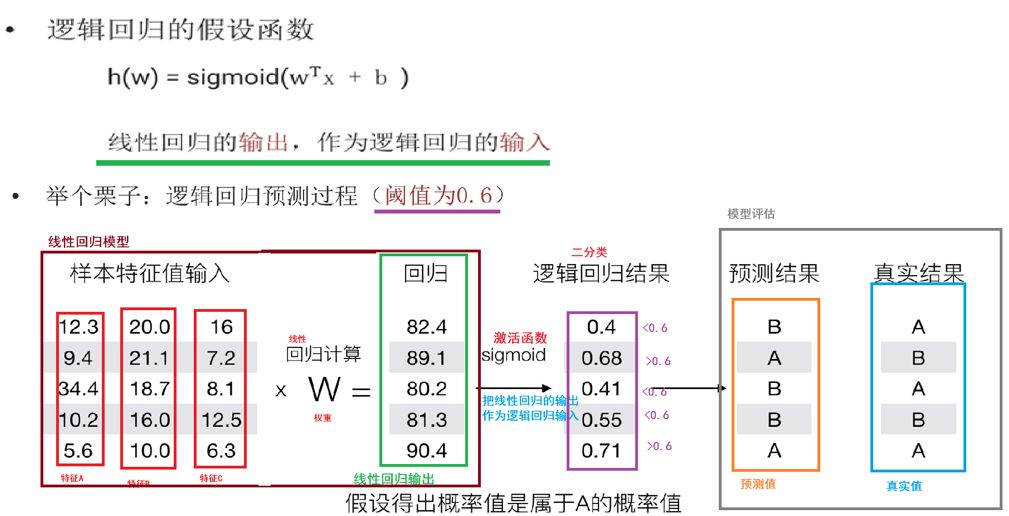
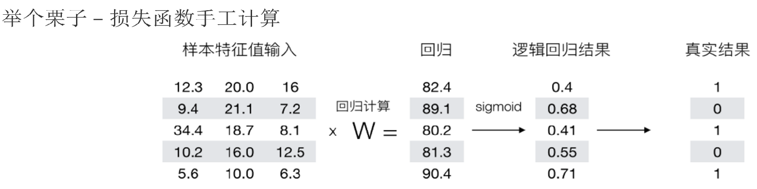
逻辑回归的损失函数

例子:
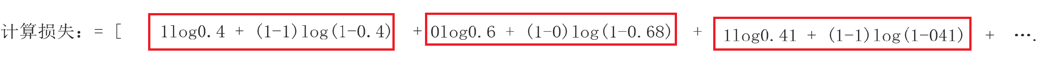
分类问题评估
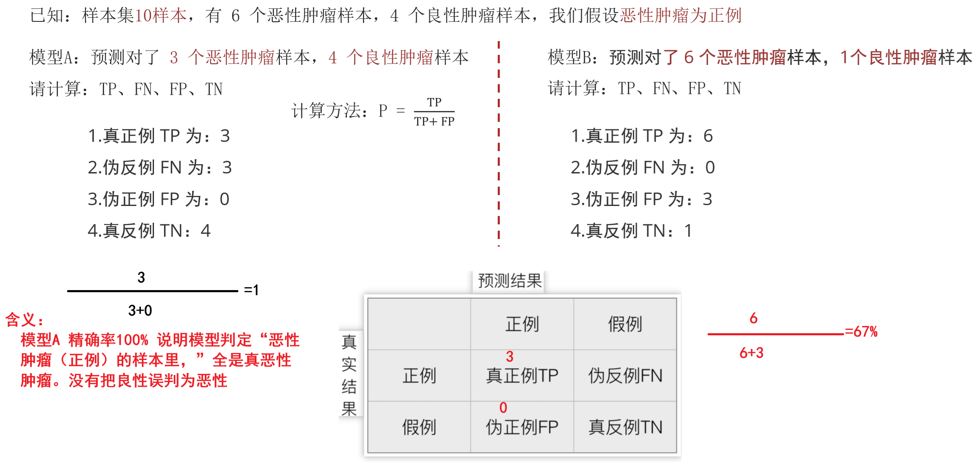
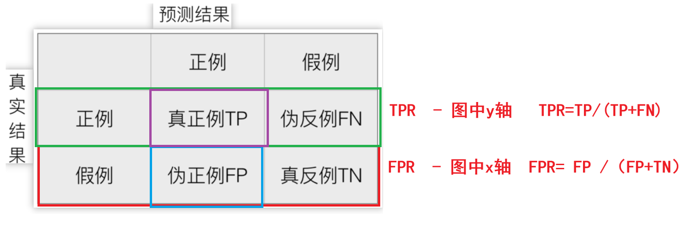
混淆矩阵(重点)

这个得记住,不难记,按英文名记就好了:
真实结果这边两个在预测的正例中就是Ture和False
在预测的反例就是倒过来False和Ture
预测的正例就是Positive,反例Negative
所以结合一下:
真正:Ture Positive(TP) 伪假:False Negative(FN)
伪正:False Positive(FP) 真假:Ture Negative(TN)
这样去理解:

例子:
![]()


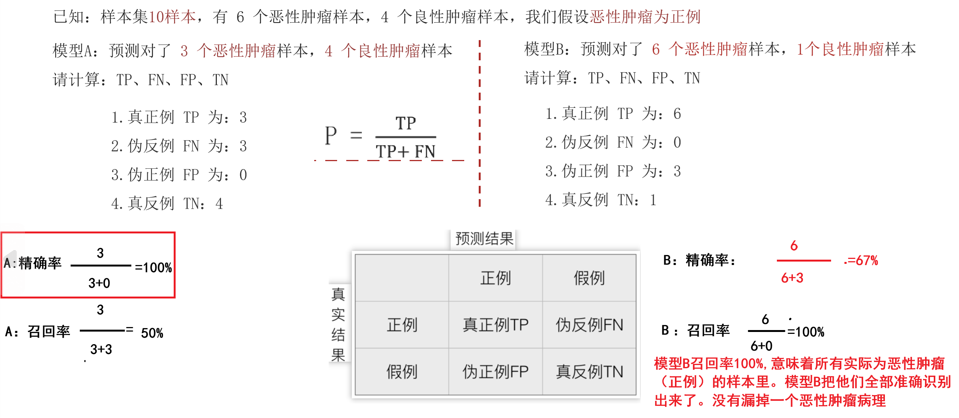
精确率(Precision)
召回率(recall)
也叫查全率,指的是预测为真正例样本占所有真实正例样本的比重例如:恶性肿瘤当做正例样本,则我们想知道模型是否能把所有的恶性肿瘤患者都预测出来。
计算方法:P = TP+ TP/(TP+ FN)

F1-score

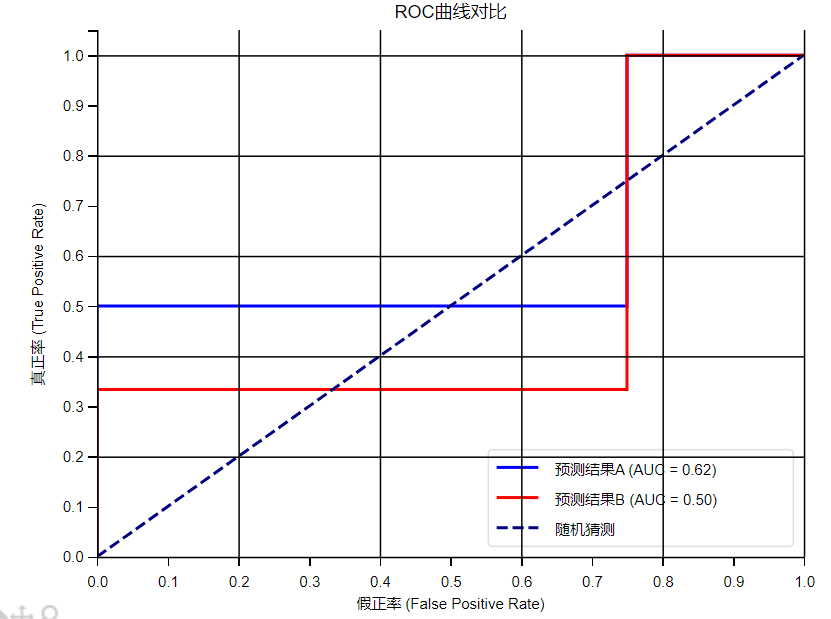
ROC曲线、AUC指标
真正率TPR与假正率FPR
正样本中被预测为正样本的概率TPR (True Positive Rate)
负样本中被预测为正样本的概率FPR (False Positive Rate)
通过这两个指标可以描述模型对正/负样本的分辨能力
真正率TRP(True Positive Rate)

是作为ROC曲线的Y轴
假正率FPR(False Positive Rate)

作X轴
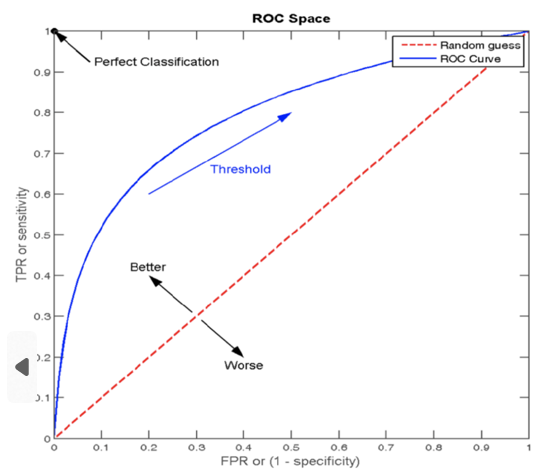
ROC曲线(Receiver Operating Characteristic curve)
是一种常用于评估分类模型性能的可视化工具。ROC曲线以模型的真正率TPR为纵轴,假正率FPR为横轴,它将模型在不同阈值下的表现以曲线的形式展现出来
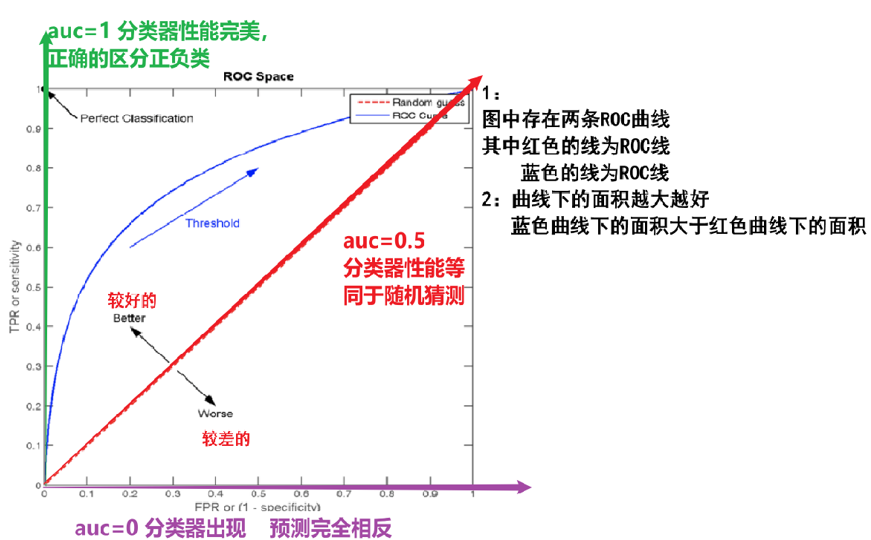
AUC (Area Under the ROC Curve)曲线下面积
ROC曲线的优劣可以通过曲线下的面积(AUC)来衡量,AUC越大表示分类器性能越好。
当AUC=0.5时,表示分类器的性能等同于随机猜测
当AUC=1时,表示分类器的性能完美,能够完全正确地将正负例分类。
图像中四个特殊点(顶点)的意义要稍微记一下


import pandas as pd
from sklearn.metrics import confusion_matrix,precision_score,recall_score,f1_score, roc_curve, auc
import matplotlib.pyplot as plt
import numpy as np# 设置中文字体支持
plt.rcParams['font.sans-serif'] = ['SimHei', 'Arial Unicode MS', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False#todo 1、定义数据集 真实样本(10个 6个恶性 4个良性) -》手动设置 恶性(正例) 良性(反例)
y_train=['恶性','恶性','恶性','恶性','恶性','恶性','良性','良性','良性','良性']#todo 2、 定义标签名
label=['恶性','良性'] #标签1:正样本(正例) 标签2:负样本(反例)
df_label=['恶性(正例)','良性(假例)'] #这是为了让格式好看#todo 3、定义 预测结果A 3个恶性 ,4个良性 改完后数据集 3个恶性 7个良性
y_pre_A=['恶性','恶性','恶性', '良性','良性','良性', '良性','良性','良性','良性']#todo 4、 把上述的预测结果A 转换为 混淆矩阵
cm_A=confusion_matrix(y_train,y_pre_A,labels=label)
# print(f"混淆矩阵A:\n{cm_A}") #美化#todo 5、把混淆矩阵 转化为 DataFrame格式
df_A=pd.DataFrame(cm_A,index=df_label,columns=df_label)
print(f"预处结果A对应的DataFrame对象:\n{df_A}")#todo 6、 定义 预测结果B 预测对了 -》 6个恶性 1个良性
y_pre_B=['恶性','恶性','恶性','恶性','恶性','恶性','良性','恶性','恶性','恶性']
cm_B=confusion_matrix(y_train,y_pre_B,labels=label)
df_B =pd.DataFrame(cm_B,index=df_label,columns=df_label)
print(f"预处结果B对应的DataFrame对象:\n{df_B}")#总结: 混淆矩阵已经开发完成,接下来,计算他的TP\FN\FP\TN#todo 7 打印预测结果
#精确率 参1: 真实样本 参2:预测样本 参3:正例标签
print(f"预测结果A的精确率:{precision_score(y_train,y_pre_A,pos_label='恶性')}")
print(f"预测结果B的精确率:{precision_score(y_train,y_pre_B,pos_label='恶性')}")#召回率
print(f"预测结果A的召回率:{recall_score(y_train,y_pre_A,pos_label='恶性')}")
print(f"预测结果B的召回率:{recall_score(y_train,y_pre_B,pos_label='恶性')}")#F1值
print(f"预测结果A的F1值:{f1_score(y_train,y_pre_A,pos_label='恶性')}")
print(f"预测结果B的F1值:{f1_score(y_train,y_pre_B,pos_label='恶性')}")# 绘制ROC曲线
# 首先需要将标签转换为数字
y_train_num = [1 if label == '恶性' else 0 for label in y_train]
y_pre_A_num = [1 if label == '恶性' else 0 for label in y_pre_A]
y_pre_B_num = [1 if label == '恶性' else 0 for label in y_pre_B]# 为了获得更平滑的ROC曲线,我们需要生成预测概率而不是硬分类
# 这里我们模拟概率值来演示平滑的ROC曲线
np.random.seed(42) # 为了结果可重现
y_pre_A_proba = []
for label in y_pre_A:if label == '恶性':# 对于预测为恶性的,我们生成一个相对高的恶性概率y_pre_A_proba.append(np.random.uniform(0.6, 1.0))else:# 对于预测为良性的,我们生成一个相对低的恶性概率y_pre_A_proba.append(np.random.uniform(0.0, 0.4))y_pre_B_proba = []
for label in y_pre_B:if label == '恶性':# 对于预测为恶性的,我们生成一个相对高的恶性概率y_pre_B_proba.append(np.random.uniform(0.7, 1.0))else:# 对于预测为良性的,我们生成一个相对低的恶性概率y_pre_B_proba.append(np.random.uniform(0.0, 0.3))# 计算ROC曲线
fpr_A, tpr_A, _ = roc_curve(y_train_num, y_pre_A_proba)
fpr_B, tpr_B, _ = roc_curve(y_train_num, y_pre_B_proba)# 计算AUC值
auc_A = auc(fpr_A, tpr_A)
auc_B = auc(fpr_B, tpr_B)# 绘制ROC曲线
plt.figure(figsize=(8, 6))
plt.plot(fpr_A, tpr_A, color='blue', lw=2, label=f'预测结果A (AUC = {auc_A:.2f})')
plt.plot(fpr_B, tpr_B, color='red', lw=2, label=f'预测结果B (AUC = {auc_B:.2f})')
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--', label='随机猜测')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('假正率 (False Positive Rate)')
plt.ylabel('真正率 (True Positive Rate)')
plt.title('ROC曲线对比')
plt.legend(loc="lower right")
plt.grid(True)
plt.show()由于这个案例是将结果分成了几个类,而不是计算概率,所以曲线图变成了折线图,不过大家理解这个意思就好