李沐深度学习论文精读(一)AlexNet + ResNet
读论文顺序:
标题+摘要+结论 -> experiment 实验+method 方法 关键图表 x-y轴 点的含义 -> 是否精读
作者的方法与之前的方法 结果差别多大(之前谁提出的问题 在谁的方法上改进)
以下为AlexNet + ResNet 并附有原文pdf + 李沐老师B站讲解。
目录
1. AlexNet - 2012年
1. 摘要
2. 文末结论/讨论discussion
3. 一些图表
1. Introduction
2. Dataset 数据集介绍 + 像素预处理
3 The Architecture
4. Reducing Overfitting
2. ResNet 残差网络 - 2016年
1. 摘要
2. 一些图表 -- 实验结果
3. Introduction
4. 讨论
1. AlexNet - 2012年
ImageNet Classification with Deep Convolutional Neural Networks 原文pdf
9年后重读深度学习奠基作之一:AlexNet【论文精读·2】_哔哩哔哩_bilibili
前三部分为粗读;后续为精读
1. 摘要
1. 研究背景与目标(首句) ImageNet LSVRC-2010数据集 1000类图像分类
We trained a large, deep convolutional neural network to classify the 1.2 million high-resolution images in the ImageNet LSVRC-2010 contest into the 1000 different classes.
2. 核心成果展示(第二句)错误率与之前结果的对比。
On the test data, we achieved top-1 and top-5 error rates of 37.5% and 17.0% which is considerably better than the previous state-of-the-art.
3. 方法架构说明(第三句)
网络规模描述(参数/神经元数量)层级结构(5卷积层+3全连接层)输出层(softmax分类器)
The neural network, which has 60 million parameters and 650,000 neurons, consists of five convolutional layers, some of which are followed by max-pooling layers, and three fully-connected layers with a final 1000-way softmax.
4. 技术创新点(第四、五句)
训练效率优化(非饱和神经元+GPU实现)
To make training faster, we used non-saturating neurons and a very efficient GPU implementation of the convolution operation.
过拟合解决方案(dropout正则化)
To reduce overfitting in the fully-connected layers we employed a recently-developed regularization method called “dropout” that proved to be very effective.
5. 竞争性验证(末句)ILSVRC-2012横向对比强化说服力(15.3% vs 26.2%)
We also entered a variant of this model in the ILSVRC-2012 competition and achieved a winning top-5 test error rate of 15.3%, compared to 26.2% achieved by the second-best entry.
2. 文末结论/讨论discussion
1. 核心结论:大型深度卷积神经网络 + 纯监督学习 可以在极具挑战性的数据集上取得破纪录的结果。
(强调了两个关键要素:“大”和“深”,并划清了与当时流行的“无监督预训练”方法的界限。)
Our results show that a large, deep convolutional neural network is capable of achieving record-breaking results on a highly challenging dataset using purely supervised learning.
2. 证据支撑:删除网络中间某一层后的性能下降,消融实验 的结果证明“深度”的重要性。深度是成功的关键。这为后续深度学习领域“更深”的网络结构(如VGG, ResNet)的探索提供了直接依据。
It is notable that our network’s performance degrades if a single convolutional layer is removed. For example, removing any of the middle layers results in a loss of about 2% for the top-1 performance of the network. So the depth 深度 really is important for achieving our results.
3. 未来展望:
1. 只用纯监督学习 (当时无监督学习比较热门 因为有监督就SVM那种效果也没有太好)
没有用当时比较热的无监督学习,计算能力增长远超标注数据量增长的背景下。当网络可以变得极大,而标注数据相对不足时,无监督学习可以充分利用海量无标注数据来学习更好的特征表示,从而提升模型性能。
2. 识别正确率仍比人类低;
3.未来可以应用在 video视频上(静态图像丢失重要的时序信息)
3. 一些图表
在results 结果展示部分
CNN的效果 在Top-1 Top-5上都远好于另外两种。
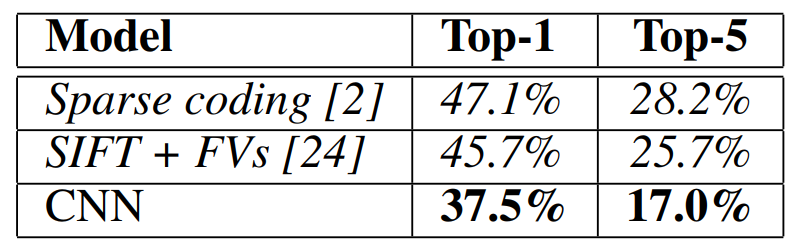
Eight ILSVRC-2010 test images and the five labels considered most probable by our model. The correct label is written under each image, and the probability assigned to the correct label is also shown with a red bar (if it happens to be in the top 5)
图像识别概率前五的标签概率 (红色为正确答案的)

Five ILSVRC-2010 test images in the first column. The remaining columns show the six training images that produce feature vectors in the last hidden layer with the smallest Euclidean distance from the feature vector for the test image.
和测试集5张图 最后一层特征向量最接近的6张训练集图(可以看出都很像 证明模型有效性)

1. Introduction
机器学习需要:更大数据集、更强模型、更好防过拟合技术。(1500万张图片的ImageNet大规模标注数据集)
CNN训练不动;GPU 与高度优化的2D卷积实现相结合,使得训练大型CNN成为可能。
贡献1:竞赛中训练了当时最大的CNN之一,取得了迄今为止最好的成绩。
The specific contributions of this paper are as follows: we trained one of the largest convolutional neural networks to date on the subsets of ImageNet used in the ILSVRC-2010 and ILSVRC-2012 competitions [2] and achieved by far the best results ever reported on these datasets.
2. 开源GPU上 二维卷积。
We wrote a highly-optimized GPU implementation of 2D convolution and all the other operations inherent in training convolutional neural networks, which we make available publicly(开源).
Section 3 提升性能、减少训练时间的新颖特性(如ReLU、多GPU训练)
Our network contains a number of new and unusual features which improve its performance and reduce its training time, which are detailed in Section 3.
Section 4 正则化技术(如Dropout、数据增强)
The size of our network made overfitting a significant problem, even with 1.2 million labeled training examples, so we used several effective techniques for preventing overfitting, which are described in Section 4.
通过实验证明网络的深度是关键(删除任何一个卷积层都会导致性能下降)。
Our final network contains five convolutional and three fully-connected layers, and this depth seems to be important: we found that removing any convolutional layer (each of which contains no more than 1% of the model’s parameters) resulted in inferior performance.
2. Dataset 数据集介绍 + 像素预处理
ILSVRC (ImageNet挑战赛)
Top-1错误率: 模型预测的最高概率的标签不是正确标签的比率。
Top-5错误率: 正确标签不在模型预测的前五个最高概率标签中的比率。这是ImageNet任务的主要评价指标。
ImageNet consists of variable-resolution images, while our system requires a constant input dimensionality. Therefore, we down-sampled the images to a fixed resolution of 256 × 256.
矩形图像分辨率不同,首先缩放图像使其短边长度为256像素,然后从缩放后的图像中裁剪出中心的256×256区域。
Given a rectangular image, we first rescaled the image such that the shorter side was of length 256, and then cropped out the central 256×256 patch from the resulting image.
每个像素的RGB值中减去在整个训练集上计算得到的平均像素值(即“均值减法”,目的是对数据做中心化,便于模型训练)
We did not pre-process the images in any other way, except for subtracting the mean activity over the training set from each pixel. So we trained our network on the (centered) raw RGB values of the pixels.
预处理:统一像素为 256×256 并减去训练集平均值。
3 The Architecture
3.1 ReLU Nonlinearity
传统的饱和激活函数(如 tanh 或 sigmoid)在梯度下降时训练速度很慢。
-
解决方案:采用修正线性单元(ReLU):
f(x) = max(0, x)。
3.2 Training on Multiple GPUs 多GPU并行训练
-
动机:单个 GPU(GTX 580 仅 3GB 内存)无法容纳整个大型网络和 120 万训练样本。
-
方案:将网络并行分布在两个 GPU 上。spread the net across two GPUs
-
高效的跨 GPU 通信:GPU 可直接读写对方显存,无需经过主机内存。They are able to read from and write to one another’s memory directly, without going through host machine memory.
-
特定的连接模式:只在某些层进行 GPU 间通信 The GPUs communicate only in certain layers。例如,第 3 层卷积核接收第 2 层所有特征图的输入,而第 4 层卷积核只接收位于同一 GPU 的第 3 层特征图的输入。
-
3.3 Local Response Normalization 局部响应归一化 (日后被 BN 批归一化替代)
对同一空间位置上相邻的(n 个)特征图进行归一化。这创造了不同卷积核计算出的神经元输出之间的竞争,鼓励提取多样化的特征。
3.4 Overlapping Pooling 重叠池化
-
重叠池化:使步长小于窗口尺寸(文中使用
z=3, s=2),窗口会重叠。
3.5 Overall Architecture 总体架构
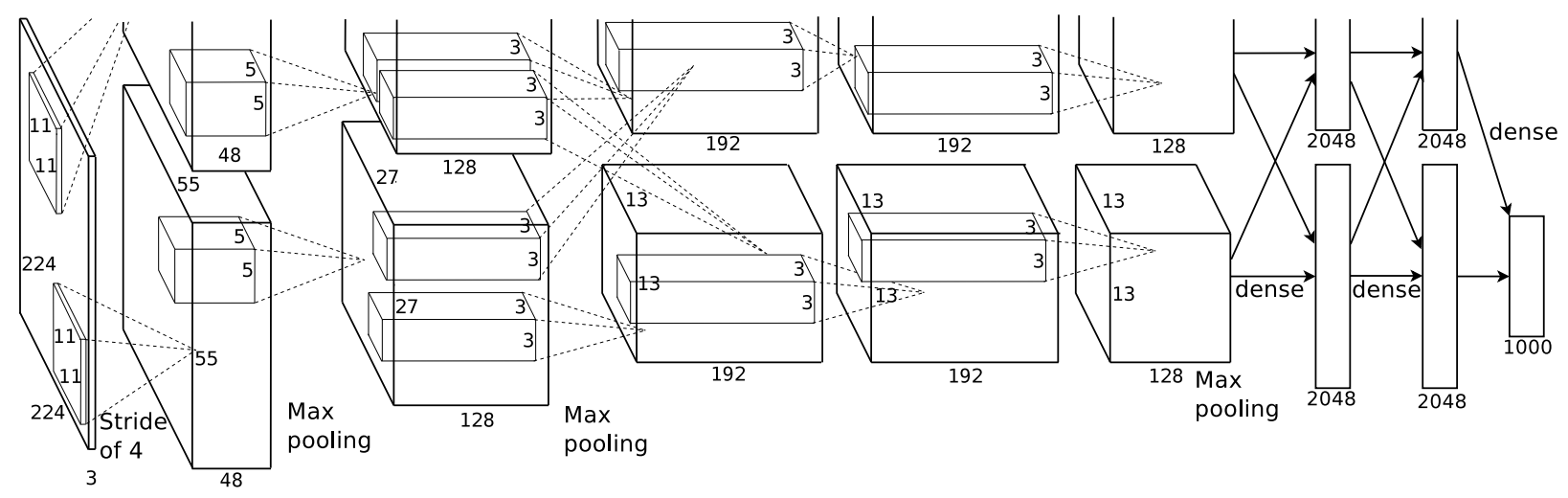
11×11×3; 5×5×48; 3×3×256; 3×3×192; 3×3×192; 4096 Dense ->1000
4. Reducing Overfitting
如何解决网络庞大(6000万参数)而训练数据(120万图像)相对不足所导致的严重过拟合问题。
-
数据增强 通过“免费”扩大数据量来直接缓解过拟合。
-
Dropout 通过随机“破坏”网络结构来防止神经元复杂的协同过拟合,是一种强大的正则化器。
4.1 Data Augmentation
图像平移与水平翻转:从原始的 256×256 图像中随机提取 224×224 的图像块(及其水平反射镜像),并用这些图像块来训练网络。
At test time, the network makes a prediction by extracting five 224 × 224 patches (the four corner patches and the center patch) as well as their horizontal reflections (hence ten patches in all), and averaging the predictions made by the network’s softmax layer on the ten patches.
测试阶段:为了充分利用图像信息,对每张测试图像提取 5 个 224×224 图像块(四个角块和中心块)及其水平翻转镜像(共10个),并将网络对这10个图像块的预测结果进行平均,作为最终的预测结果。
-
对整个 ImageNet 训练集的 RGB 像素值进行 PCA(主成分分析)。
-
对每张训练图像,添加一定量的这些主成分,其大小与对应的特征值和一个随机变量(均值为0,标准差为0.1的高斯分布)成正比。
This scheme approximately captures an important property of natural images, namely, that object identity is invariant to changes in the intensity and color of the illumination.
-
近似地捕捉了自然图像的一个重要特性:物体身份对光照强度和颜色变化的不变性。
4.2 Dropout
-
训练方法:以0.5的概率将每个隐藏神经元的输出置为零(即“丢弃”)。被丢弃的神经元不参与前向传播和反向传播。在网络的前两个全连接层中使用了 Dropout。
-
The recently-introduced technique, called “dropout” , consists of setting to zero the output of each hidden neuron with probability 0.5.
-
工作原理:
-
每次输入呈现时,网络都相当于在采样一个不同的“子架构”,但这些架构共享权重。
-
它减少了神经元之间复杂的共适应关系,因为一个神经元不能依赖于其他特定神经元的存在。
-
它迫使神经元学习更加鲁棒的特征,这些特征必须与许多其他神经元的随机子集一起有用。
-
2. ResNet 残差网络 - 2016年
Deep Residual Learning for Image Recognition 原文pdf
撑起计算机视觉半边天的ResNet【论文精读】_哔哩哔哩_bilibili
解决了深度神经网络训练中的梯度消失问题(即随着网络层数的增加,网络的性能反而可能下降)
1. 摘要
1. 问题与解决方案:网络越深,越难训练。随着网络越来越深,梯度就会出现爆炸或者消失。
一个名为 “残差学习” 的新框架,这个框架使得训练比以前深得多的网络变得容易。
Deeper neural networks are more difficult to train. We present a residual learning framework to ease the training of networks that are substantially deeper than those used previously.
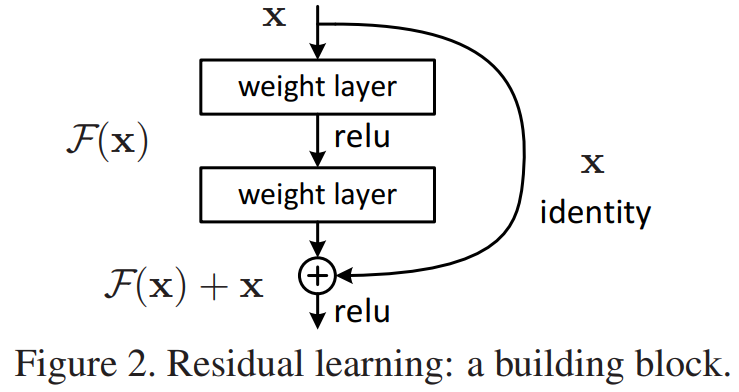
2. 核心创新点:传统网络让一层层直接学习一个目标映射 H(x)。
而 ResNet 创新性地让这些层学习残差函数 F(x) = H(x) - x。
We explicitly reformulate the layers as learning residual functions with reference to the layer inputs, instead of learning unreferenced functions.
3. 实证效果:We provide comprehensive empirical evidence showing that
these residual networks are easier to optimize
更易优化:残差网络解决了深度网络的训练难题。
and can gain accuracy from considerably increased depth.
深度带来收益:网络可以真正从深度中获益,而不是像之前那样,深度增加后性能会饱和甚至下降。
4. 在ImageNet上的突破性成果
解释: 这里用具体数据和事实展示了ResNet的强大:
深度:提出了152层的网络(ResNet-152),这比当时最流行的VGG网络(19层)深了8倍,但计算复杂度反而更低。
On the ImageNet dataset we evaluate residual nets with a depth of up to 152 layers—8× deeper than VGG nets but still having lower complexity.
性能:通过模型集成(ensemble),在ImageNet测试集上达到了3.57% 的top-5错误率,这是一个惊人的突破。
An ensemble of these residual nets achieves 3.57% error on the ImageNet test set. This result won the 1st place on the ILSVRC 2015 classification task.
极致深度探索:甚至在CIFAR-10小数据集上成功训练了100层和1000层的网络,证明了其框架的强大泛化能力。
We also present analysis on CIFAR-10 with 100 and 1000 layers.
2. 一些图表 -- 实验结果
由于CVPR要求正文不超过8页,这篇最后没有conclusion。
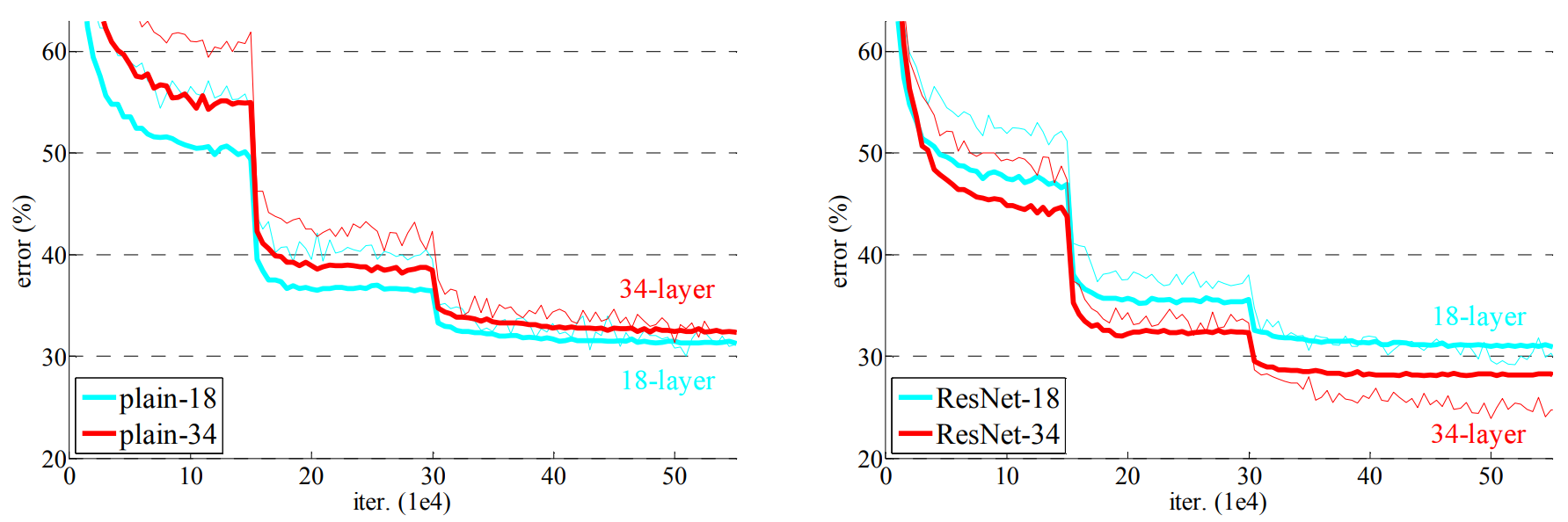
第一页开始放好看的图,在CIFAR-10 和20层网络比,56层的网络在训练集和测试集误差都更大
如果是 训练集误差小 测试集误差大 那就是过拟合了;但是这里训练集也误差大 深网络难训练。
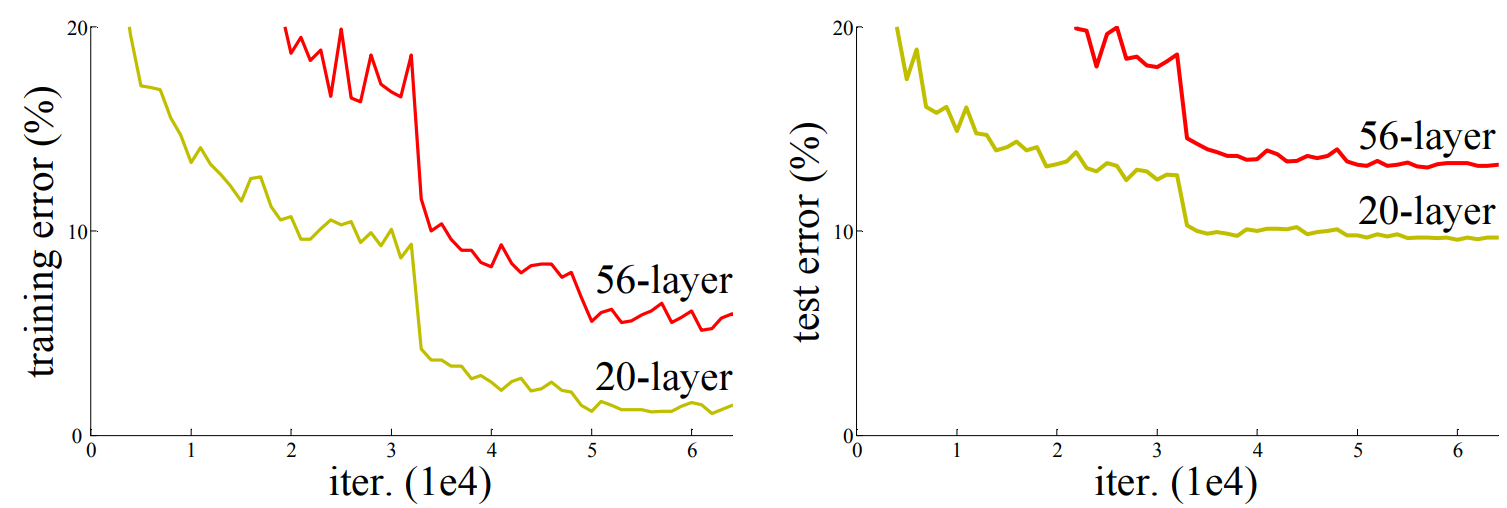
plain时 34层训练误差大于18层;用ResNet 则可以做到34层 更深的误差更小。
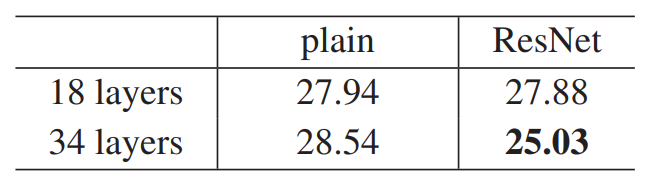
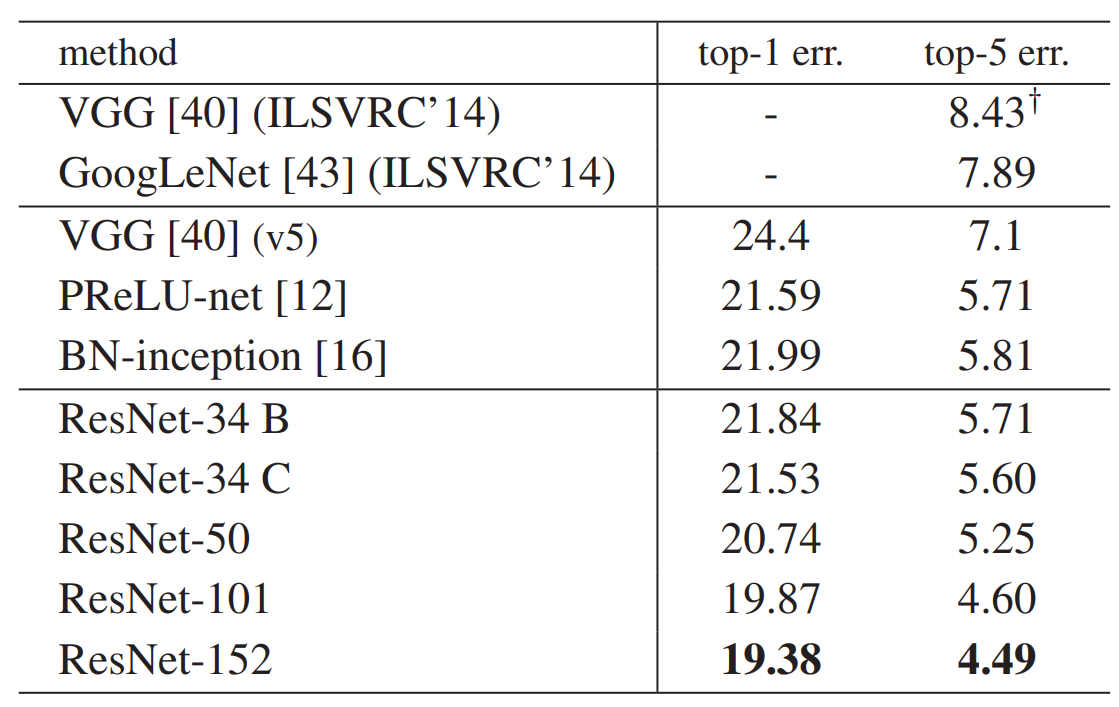
并且ResNet 和上一届比赛的 VGG和GoogLeNet也表现更好。
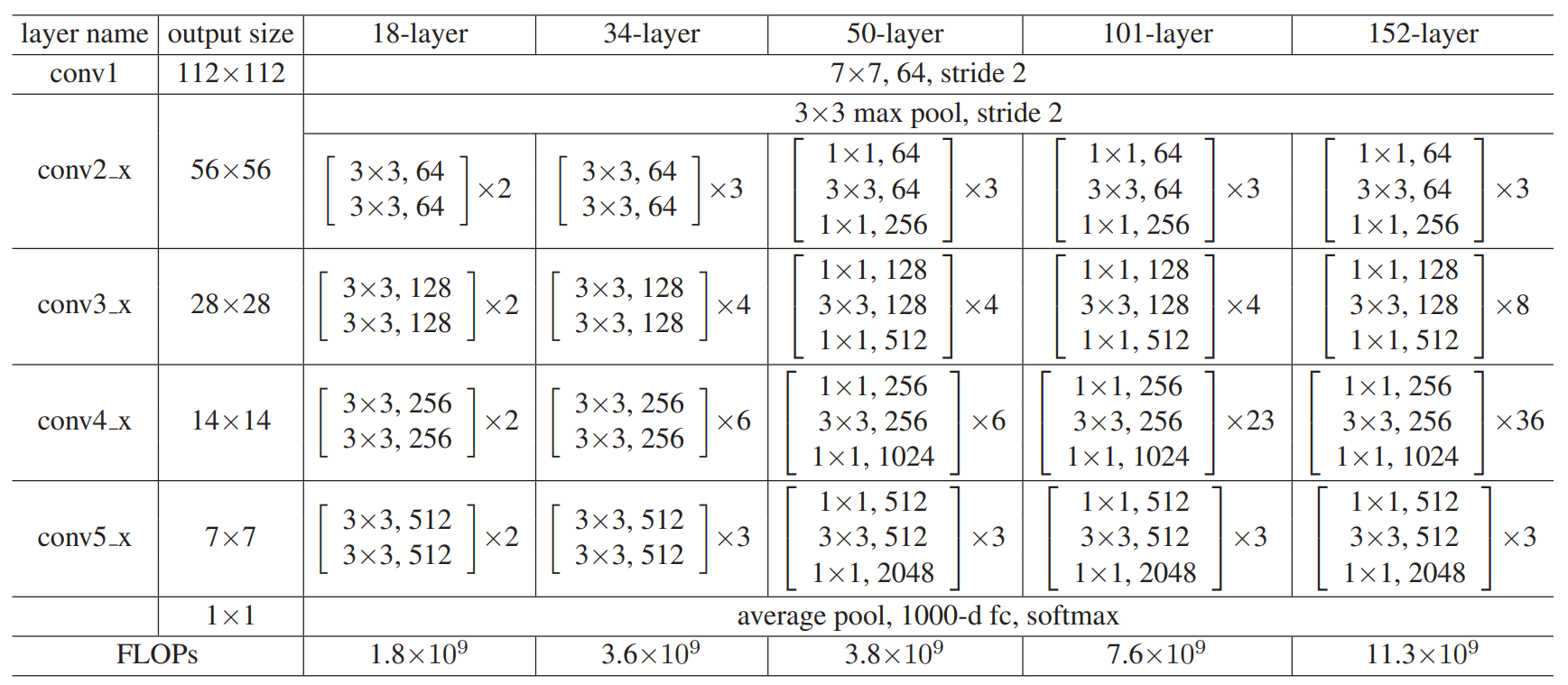
不同深度的ResNet 中间层数目 架构上的差异。
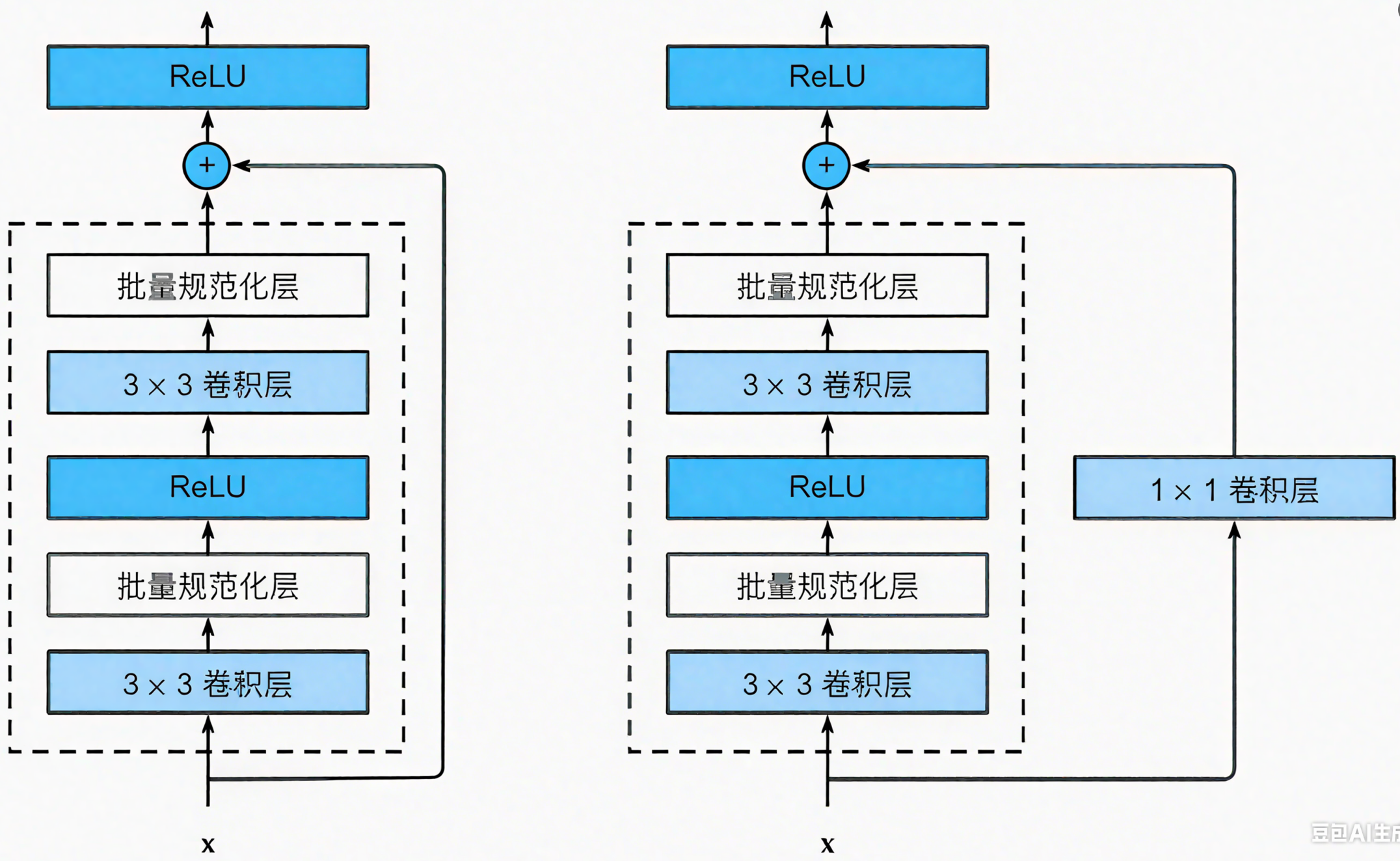
残差结构中,输入输出维度不一致:使其映射到统一维度,比如使用全连接或者是CNN中的1×1卷积(输出通道是输入的两倍)
瓶颈结构的使用:50 层及以上的 ResNet 使用瓶颈结构,这是因为随着网络深度的增加,参数数量会迅速增长,容易导致过拟合和计算量过大的问题。瓶颈结构通过先使用 1x1 卷积进行降维,减少 3x3 卷积的输入通道数,再通过 1x1 卷积恢复通道数,在保持感受野的同时,大大减少了参数数量和计算量。
左右分别为普通残差块和瓶颈残差块。
残差块 参考代码如下
import torch
from torch import nn
from torch.nn import functional as Fclass Residual(nn.Module): #@savedef __init__(self, input_channels, num_channels,use_1x1conv=False, strides=1):super().__init__()self.conv1 = nn.Conv2d(input_channels, num_channels,kernel_size=3, padding=1, stride=strides)self.conv2 = nn.Conv2d(num_channels, num_channels,kernel_size=3, padding=1)if use_1x1conv:self.conv3 = nn.Conv2d(input_channels, num_channels,kernel_size=1, stride=strides)else:self.conv3 = Noneself.bn1 = nn.BatchNorm2d(num_channels)self.bn2 = nn.BatchNorm2d(num_channels)#每个bn都有自己的参数要学习,所以需要定义两个def forward(self, X):Y = F.relu(self.bn1(self.conv1(X)))Y = self.bn2(self.conv2(Y))if self.conv3:X = self.conv3(X)Y += Xreturn F.relu(Y)3. Introduction
问题背景:解决更深的网络没有效果更好的问题
Driven by the significance of depth, a question arises: Is learning better networks as easy as stacking more layers? 深度是很重要的,但堆叠更多层的网络就更好吗?
problem of vanishing/exploding gradients 原来有梯度消失和爆炸问题
可以使用标准化初始化(如He初始化)和中间归一化层,使得通过SGD训练 可以收敛。
新加层之后 原始浅网络权重是后来深网络权重的子集,因为我可以把新加层设置为identity mapping
(输入等于输出 加了等于没加)所以深网络的最优损失 一定是不差于浅网络的。
Our current solvers on hand are unable to find solutions that are comparably good or better than the constructed solution.
但问题是求解器找不到最优解。这不是过拟合,是训练误差降不下去,测试误差也大。
核心思想:传统网络让一层层直接学习一个目标映射 H(x)。
而 ResNet 创新性地让这些层学习残差函数 F(x) = H(x) - x。
若 F(x) = 0 那么输入x还是输出x 就实现了identity mapping。(学习F(x)=0 比 F(x)=x 简单的多)
而且这个操作相比原网络 不需要学习任何参数,不增加模型的复杂度,就前馈时多了一个加法。
最后补充效果,在CIFAR-10、ImageNet、COCO segmentation表现很好。
论文写作上:这篇intro是对摘要的扩充版本,完整描述整个工作。
Related work:
Residual Representations. 其他领域上 残差思想的有效性。一种良好的重构或预处理方法可以简化优化过程。
Shortcut Connections. 在神经网络中添加跳过一层或多层的连接;
没有采用复杂的、带参数的门控机制(如高速公路网络),始终坚持无参数的恒等快捷连接和残差学习。
4. 讨论
1. 为什么ResNet训练起来比较快?
plain 深的网络 矩阵乘法次数多,在深层会梯度消失。加了残差连接,梯度多了一项,包含了之前层的梯度,这样不管加了多深,浅层网络的梯度都会有效。(优化器不会在误差很大的时候就收敛)
2. 为什么在cifar-10这样一个小的数据集上没有过拟合?
加了残差连接之后,模型内在复杂度大大降低了。而plain有些层原本就想要训练到identity mapping,但缺乏引导 模型变得很复杂。