2025国赛C题题目及最新思路公布!
C 题 NIPT 的时点选择与胎儿的异常判

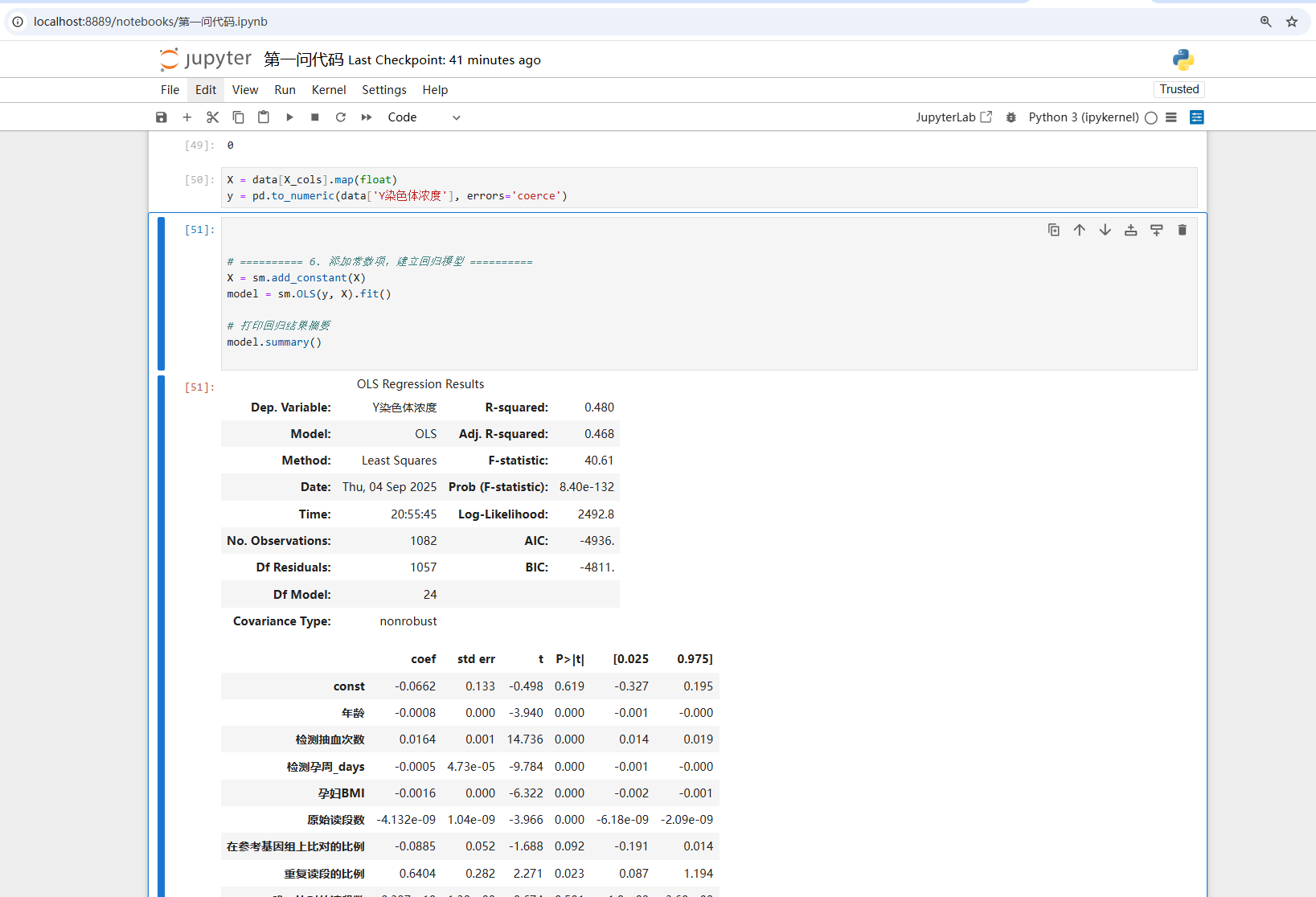
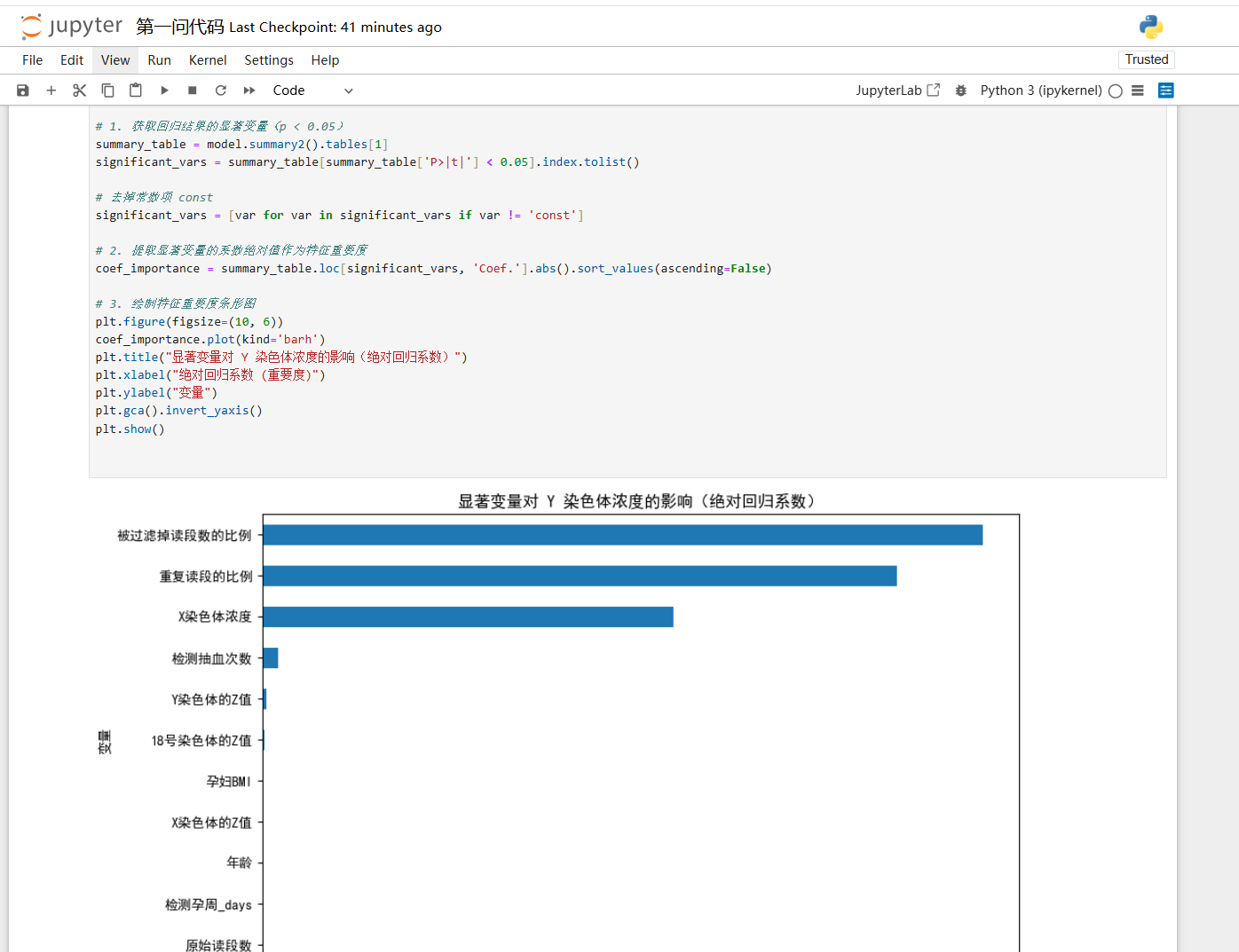
问题 1 试分析胎儿 Y 染色体浓度与孕妇的孕周数和 BMI 等指标的相关特性,给出相应的关系模
型,并检验其显著性。
思路1:
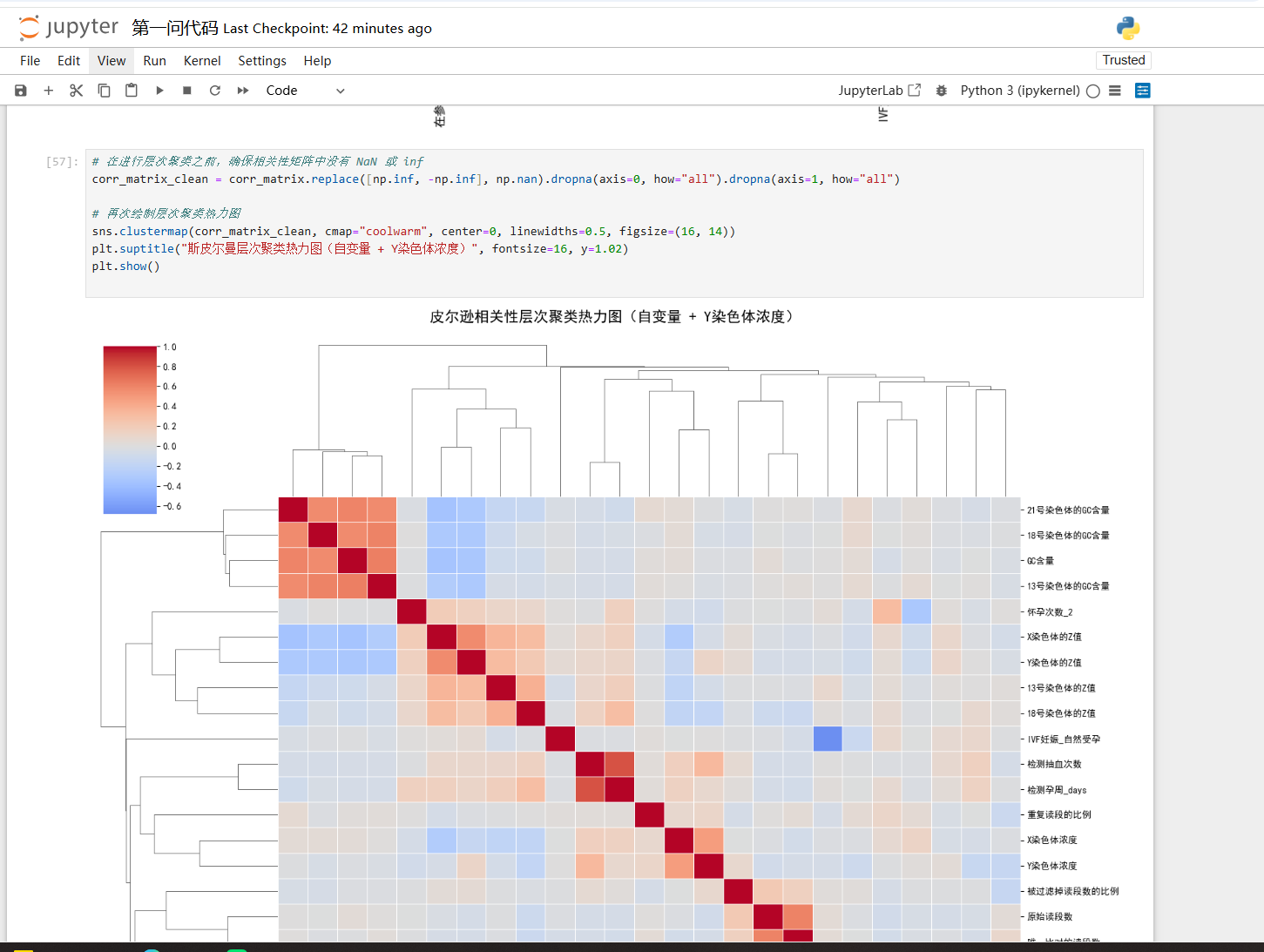
针对附件中孕妇的 NIPT 数据,首先对数据进行预处理,并对多次采样的情况采取均值或选取最可靠数据的方法进行整合。随后以胎儿 Y 染色体浓度作为因变量,将孕周数、BMI 等指标作为自变量,采用多元线性回归模型或非线性回归模型(如二次回归、对数模型)建立浓度与各指标之间的关系式。为分析变量间的相关性,先进行皮尔逊相关系数或斯皮尔曼秩相关检验,再通过回归分析中的t 检验和 F 检验评估模型参数及整体显著性,并结合R²与调整 R²检验模型拟合优度。必要时可进行分组回归(不同 BMI 分组)或交互项分析,以揭示 BMI 对孕周—Y 染色体浓度关系的调节作用,从而获得合理的数学模型和可靠的显著性检验结论。
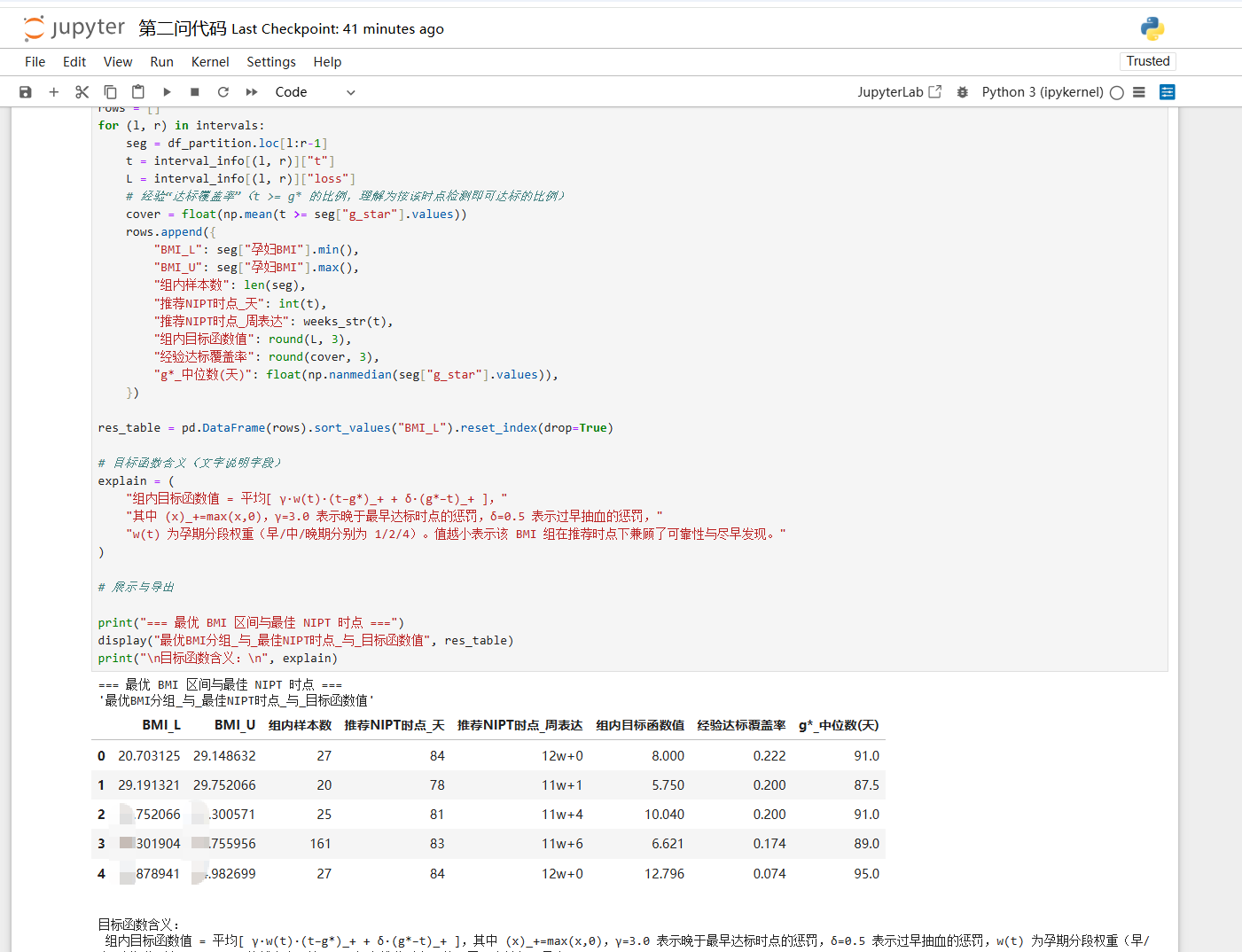
问题 2 临床证明,男胎孕妇的 BMI 是影响胎儿 Y 染色体浓度的最早达标时间(即浓度达到或超
过 4%的最早时间)的主要因素。试对男胎孕妇的 BMI 进行合理分组,给出每组的 BMI 区间和最佳 NIPT
时点,使得孕妇可能的潜在风险最小,并分析检测误差对结果的影响。
思路2:
针对男胎孕妇数据,首先整理出 首次 Y 染色体浓度 ≥4% 的孕周,若只知道在两次检测之间达标,则视为区间删失数据,若到末期仍未达标则为右删失数据。然后利用 生存分析方法(如 Turnbull 区间估计 或 AFT 模型)来估计不同 BMI 下的“达标时间分布”。接着,将 BMI 进行合理分组,可以通过 CART 决策树 或 网格搜索+交叉验证来确定分组区间,使各组的 最佳 NIPT 时点(可取 80%–90% 分位数的孕周)最优,从而降低检测失败和晚发现风险。最后,考虑检测误差的影响,可采用 测量误差模型 或 SIMEX 方法 进行敏感性分析,检验推荐时点和分组结果的稳健性。
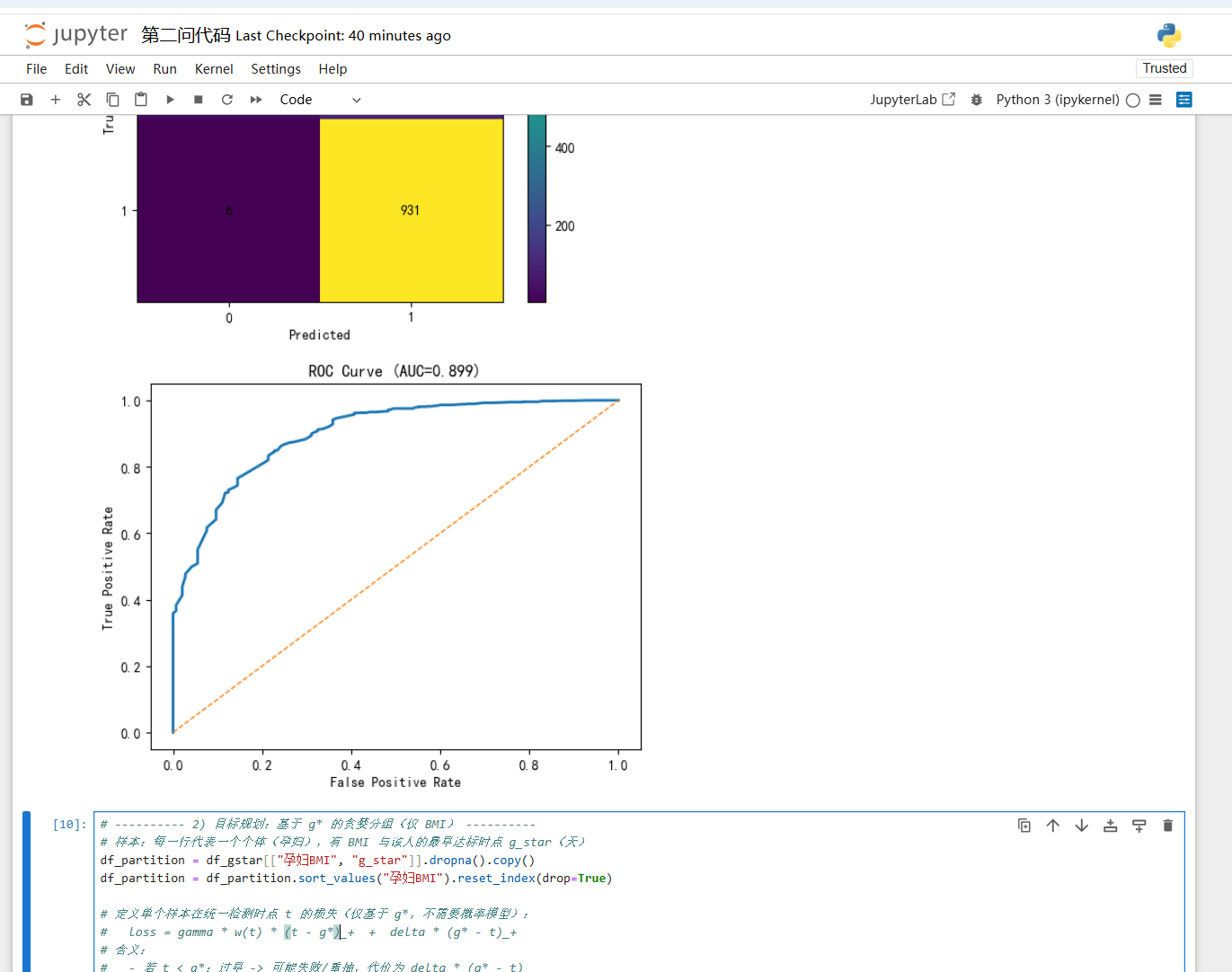
问题 3 男胎 Y 染色体浓度达标时间受多种因素(身高、体重、年龄等)的影响,试综合考虑这些因
素、检测误差和胎儿的 Y 染色体浓度达标比例(即浓度达到或超过 4%的比例),根据男胎孕妇的 BMI,
给出合理分组以及每组的最佳 NIPT 时点,使得孕妇潜在风险最小,并分析检测误差对结果的影响。
思路3:
我们先整理男胎的数据,把多次检测和测序失败情况合并,定义“Y 染色体浓度第一次 ≥4% 的孕周”为达标时间。接着,以 Y 染色体浓度为因变量,孕妇的 BMI、身高、体重、年龄等为自变量,建立 混合效应模型 或 Cox 回归/加速失效时间模型 来刻画达标时间与各因素的关系;同时用 LASSO 回归做变量选择,BMI 用 样条函数拟合非线性关系。根据模型结果,计算不同孕周的“达标概率”,并构造一个包含“未达标风险、超过 28 周风险、复检次数”的 风险函数,通过最小化风险函数确定每个 BMI 区间的最佳 NIPT 检测时点。BMI 分组可以用 CART 决策树或 模型驱动分区来自动寻找切点。最后,用 SIMEX 方法或 贝叶斯测量误差模型分析检测误差的影响,保证结果稳健。
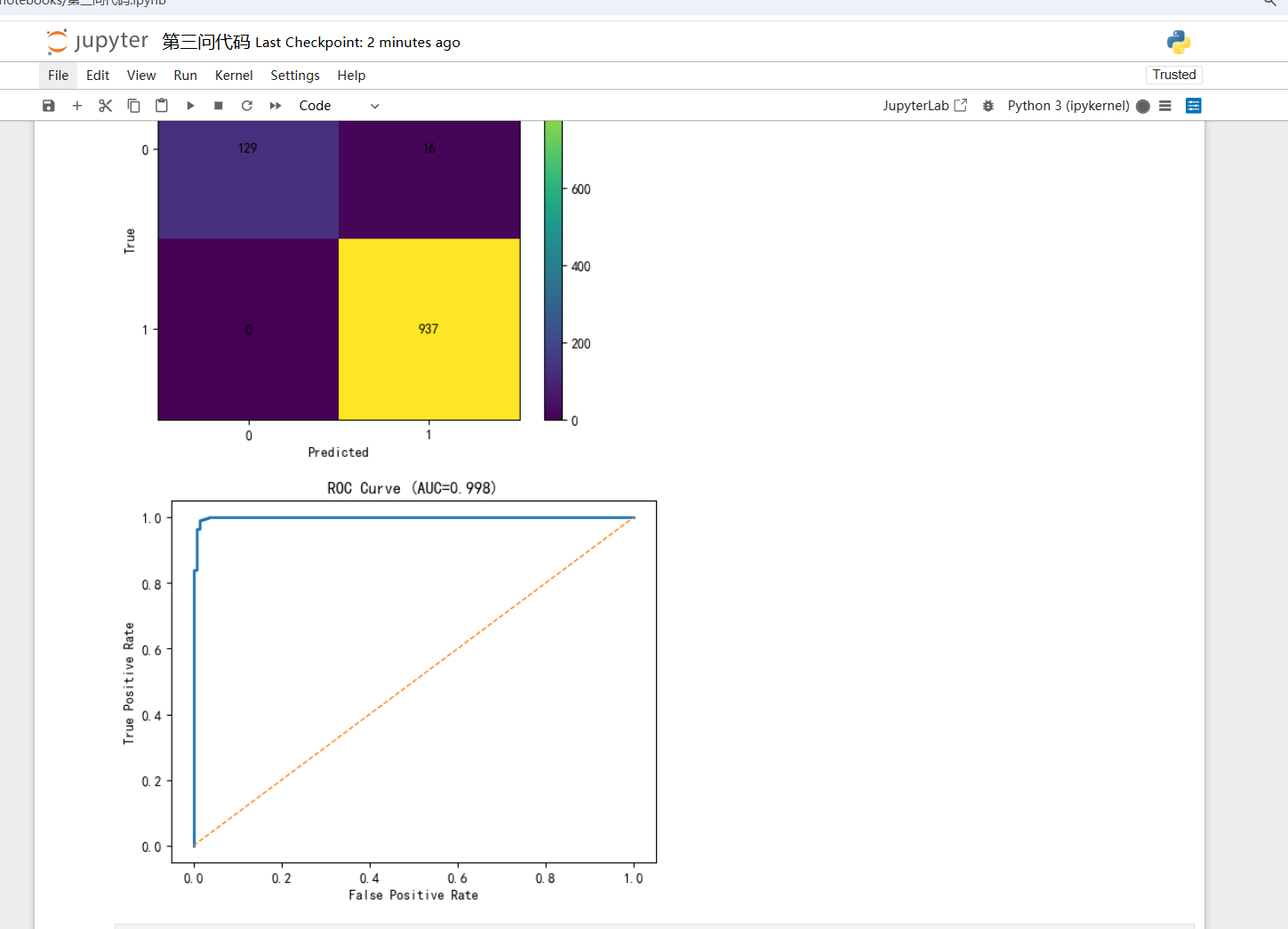
问题 4 由于孕妇和女胎都不携带 Y 染色体,重要的是如何判定女胎是否异常。试以女胎孕妇的 21
号、18 号和 13 号染色体非整倍体(AB 列)为判定结果,综合考虑 X 染色体及上述染色体的 Z 值、GC
含量、读段数及相关比例、BMI 等因素,给出女胎异常的判定方法。
思路4:先对女胎孕妇的数据做整理,把 21、18、13 号和 X 染色体的 Z 值、GC 含量、读段数及比例、以及孕妇的 BMI 等特征标准化处理,并去掉测序失败或极端值。然后以 AB 列的“是否异常”作为判定结果,建立判别模型。可以先用 逻辑回归,也可以尝试 LASSO 回归或 梯度提升树(XGBoost/GBDT) 来选择和组合变量。由于数据里“异常”样本可能很少,要用 SMOTE 过采样或类别加权的方法平衡训练。模型训练后,通过交叉验证评估,指标重点看 AUC、灵敏度和特异度。最后在 ROC 曲线上选择一个合适阈值,保证高灵敏度,输出一个“异常风险分数”,并根据分数把女胎分为低、中、高风险,辅助进一步诊断。
届时完成思路将在第一时间更新以及共享代码,大家可以关注一下,B站会第一时间发布思路视频
不知名数学家小P的个人空间-不知名数学家小P个人主页-哔哩哔哩视频space.bilibili.com/435530921?spm_id_from=333.1007.0.0