大数据框架Doris全面解析
Apache Doris 简介 - Apache Doris
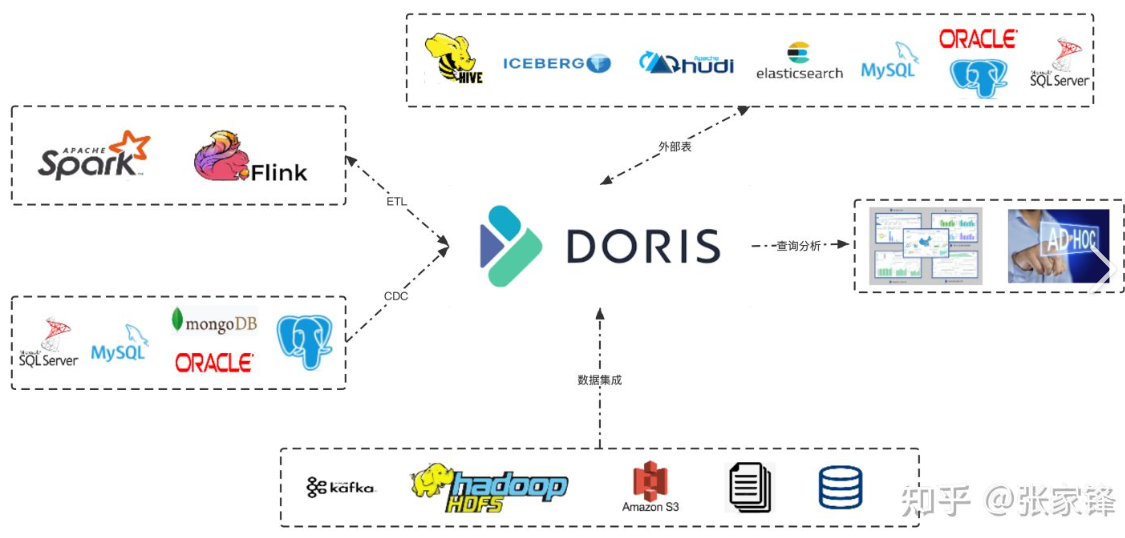
好的,我们来全面、系统地了解一下大数据框架 Apache Doris。
Apache Doris(之前也叫百度 Palo)是一个基于 MPP(大规模并行处理)架构的高性能、实时的分析型数据库。它主要面向在线分析处理(OLAP)场景,能够以亚秒级的响应时间对海量数据进行多维分析和即席查询。
一、Doris 的核心定位与特点
Doris 的设计目标是为用户提供一个单一、统一的分析数据库,以替代传统复杂的“Hadoop + 多个组件(如 Hive, HBase, Presto/Trino, Kylin)”的大数据技术栈。其核心特点包括:
-
极致的性能:
-
基于 MPP 架构,并行计算,充分利用集群资源。
-
列式存储,高效压缩,减少 I/O 开销。
-
预聚合(物化视图),对于常用聚合查询,速度极快。
-
向量化执行引擎,充分利用 CPU 缓存和指令集。
-
-
易用性与便利性:
-
兼容 MySQL 协议:用户可以使用标准的 SQL 和常见的 MySQL 客户端(如 mysql cli, JDBC, ODBC)直接连接 Doris,学习成本极低。
-
简化架构:系统只有两个核心组件:Frontend (FE) 和 Backend (BE),部署和运维非常简单。
-
支持标准 SQL:支持 ANSI SQL 2003 标准,包括丰富的函数、窗口函数、CTE(公共表表达式)等。
-
-
实时分析:
-
支持实时数据导入,可以通过多种方式(如 Stream Load, Routine Load, Insert)将数据毫秒级到分钟级地导入 Doris,并立即用于分析。
-
支持更新(Unique 模型)和删除操作,可实现“读时更新”或“写时更新”,满足实时数仓中对数据更新的需求。
-
-
高可用性与可扩展性:
-
采用分布式架构,FE 和 BE 都可以水平扩展。
-
多 FE 副本通过类 Raft 协议实现元数据的高可用和一致性。
-
数据多副本存储,自动恢复,保证数据可靠性。
-
二、核心架构:FE 与 BE
Doris 的架构非常简洁,主要由两类进程组成:
| 组件 | 角色 | 功能 |
|---|---|---|
| Frontend (FE) | 管理节点 | 1. 元数据管理:存储和维护表结构、分区、副本等信息。 2. 查询协调:接收客户端请求,解析 SQL,生成查询计划,并将计划分发到 BE 执行,然后聚合结果。 3. 集群管理:管理 BE 节点的上下线。 |
| Backend (BE) | 计算与存储节点 | 1. 数据存储:负责存储表中的数据(按列存储)。 2. 查询执行:执行 FE 下发的查询计划片段,进行本地计算。 3. 数据复制:保证数据的多副本一致性。 |
工作流程:
-
用户通过 MySQL 客户端向 FE 发送 SQL 请求。
-
FE 解析 SQL,进行元数据校验、权限验证、查询优化,生成分布式执行计划。
-
FE 将执行计划分发给相关的多个 BE 节点。
-
每个 BE 节点并行执行本地计算(扫描数据、过滤、聚合等)。
-
BE 将中间结果返回给 FE(或直接由某个 BE 进行结果汇聚)。
-
FE 将最终结果返回给客户端。
这种架构分离了管理职责和计算存储职责,清晰且易于扩展。
三、数据模型与表设计
Doris 提供了灵活的数据模型,在表创建时通过 DUPLICATE KEY、UNIQUE KEY、AGGREGATE KEY 来定义,以适应不同场景。
| 模型 | 关键字 | 适用场景 | 说明 |
|---|---|---|---|
| 明细模型 | DUPLICATE KEY(...) | 日志分析、用户行为分析 | 存储最原始的明细数据,即使完全重复的两行数据也会保留。适合 Ad-hoc 查询,任意维度的筛选。 |
| 聚合模型 | AGGREGATE KEY(...) | 报表、可视化 | 导入阶段就进行预聚合。例如,定义 SUM(v1), COUNT(v2),后续查询时直接取结果,极大提升查询性能。 |
| 更新模型 | UNIQUE KEY(...) | 订单状态变更、用户资料更新 | 针对需要更新的场景。相同 Key 的数据只会保留最新版本,实现了“读时更新”。 |
| 主键模型 | PRIMARY KEY(...) | 实时更新频繁的场景 | 2.0版本引入,支持高效的 UPSERT 和 DELETE 操作,提供了更极致的实时更新性能。 |
分区与分桶:
-
分区(Partitioning):通常按日期分区(如按天),便于数据管理(删除旧数据)、查询时剪枝。
-
分桶(Bucketing):在一个分区内,数据被哈希分布到多个 Tablet(数据分片)中。Tablet 是数据移动、复制和计算的最小单元。合理的分桶能保证数据均匀分布,充分利用并行计算。
四、与其他OLAP引擎的对比
| 特性 | Apache Doris | ClickHouse | Apache StarRocks | Presto/Trino |
|---|---|---|---|---|
| 架构复杂度 | 极简 (FE/BE) | 简单 | 极简 (FE/BE,由Doris分支而来) | 中等 (Coordinator/Worker) |
| 易用性 | 极高 (MySQL协议,标准SQL) | 中等(自定义SQL方言,配置复杂) | 极高(同Doris) | 高(标准SQL) |
| 实时能力 | 强(支持更新,多种导入方式) | 强(但更新能力较弱) | 极强(优化了Doris的更新模型) | 弱(依赖外部存储,如Hive, Kafka) |
| 查询性能 | 非常快(尤其多表关联) | 极快(单表查询世界领先) | 极快(在Doris基础上进一步优化) | 快(但受连接器性能影响) |
| 生态集成 | 良好(支持HDFS/S3, Hive, Iceberg等) | 一般 | 良好(同Doris,并更积极) | 极好(连接器生态丰富) |
| 适用场景 | 实时数仓、报表、Ad-hoc查询 | 单表极速分析、用户行为日志 | 对性能和实时性要求更高的场景 | 联邦查询、跨数据源分析 |
注:Apache Doris 和 StarRocks 同源,后者是前者的一个分支,并进行了大量深度优化,两者在很多方面非常相似。目前 StarRocks 在社区活跃度和性能优化上更为激进。
五、典型应用场景
-
实时数据仓库:替代传统的 T+1 数仓,实现分钟级甚至秒级的数据分析和报表呈现。
-
用户行为分析:支持对海量用户点击流、浏览记录等进行快速的多维度、即席查询。
-
日志分析与监控:替代 ELK 中的 Elasticsearch 进行更复杂的聚合查询和分析。
-
统一查询层:通过对 Hive、Iceberg、Hudi 等外部表的支持,作为统一的查询入口,简化数据架构。
总结
Apache Doris 的核心优势在于其“全能”和“易用”。它不像 ClickHouse 在单表查询上做到极致但牺牲了易用性和关联查询,也不像 Presto 只做计算引擎而需要依赖外部存储。
它提供了一个 开箱即用、性能卓越、支持实时更新、兼容MySQL协议 的一站式解决方案,特别适合希望构建实时数仓、但又希望技术栈尽可能简单、运维成本低的团队。对于从 MySQL 等传统数据库转型过来的团队来说,Doris 的学习和迁移成本非常低,是其进入大数据分析领域的一个绝佳选择。