袋鼠云产品功能更新报告14期|实时开发,效率再升级!
本期,我们更新和优化了实时开发相关功能,为您提供更高效的产品能力。以下为第14期袋鼠云产品功能更新报告,请继续阅读。
功能新增
重点新增内容
支持国际英文版
实时开发平台上线了国际英文版,适配全球国家的通用语言体系,消除语言差异带来的使用问题。
任务自定义参数支持项目级、全局参数
任务自定义参数现已支持项目级与全局参数:在任务参数设置-中映射值中将此任务发布至目标项目时会自动替换原值;同时提供变量参数,可在单个任务内使用,适用于 FlinkSQL IDE 编辑区、FlinkJar 命令行参数、实时采集脚本模式 JSON 及 PyFlink 向导模式入参,使用格式为 ${参数名};此外,项目配置中新增了项目参数管理页面,方便统一维护。
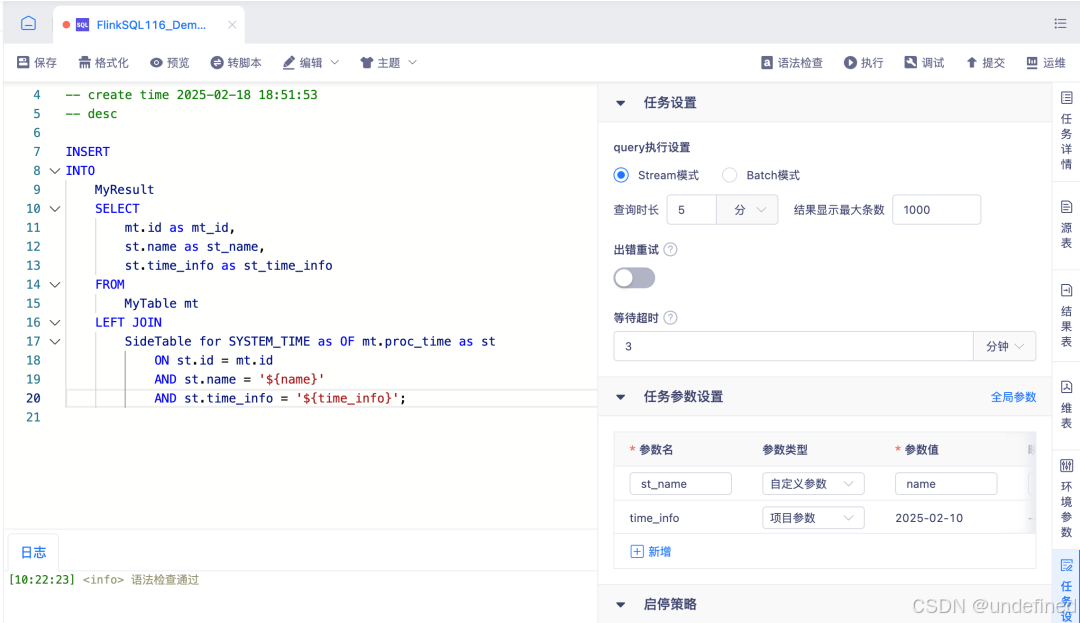
实时采集 MysqlBinlog 采集支持字段过滤
在实时 MySQL Binlog 采集中,我们新增了敏感字段过滤能力:在向导模式多表采集场景下,用户可通过高级参数 filterColumns 配置需要过滤的字段(支持表名、字段名正则匹配,格式 " filterColumns ":" tableName.columnName "),目前适用于 Flink 1.16 及以上版本的 MySQL Binlog 采集,助力用户满足安全合规需求。
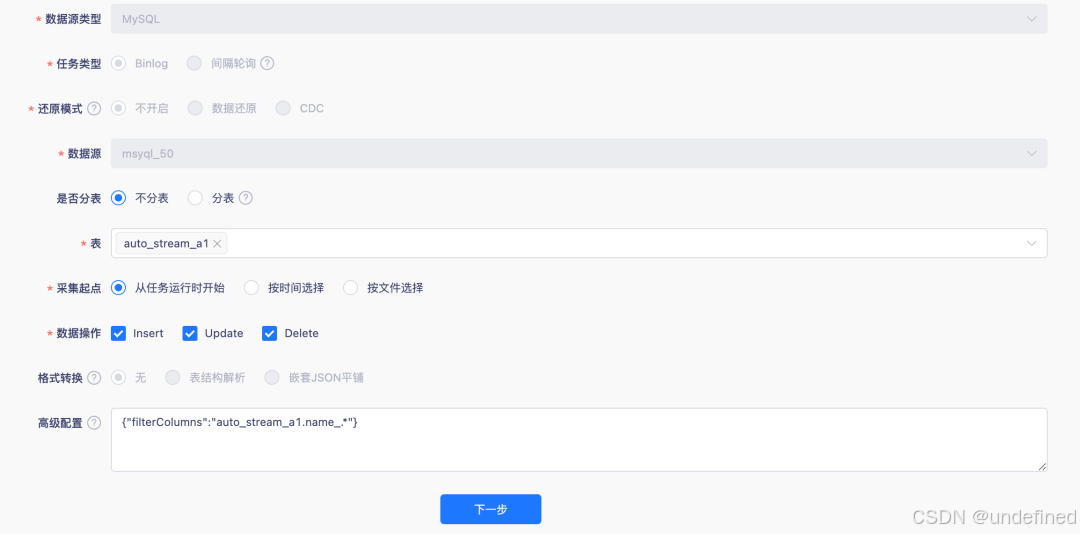
实时采集脚本模式支持 FlinkCDC Yaml 格式
实时采集支持 FlinkCDC Yaml 格式,适用于 Flink 1.16 及以上版本,并支持自定义参数使用,方便用户直接以原生脚本方式运行代码。
FlinkSQL 向导模式 Kafka 源表支持选择可用元数据
在 FlinkSQL 向导模式(支持 1.12 、1.16 版本),使用 Kafka 源表时现已支持在 With 中选择可用的 Kafka 元数据参数。针对 JSON、OGG-JSON、AVRO、CSV、RAW、Debezium-JSON ,用户可将可用的 Kafka Metadata 配置为运行 SQL 的字段,提升建表灵活性。
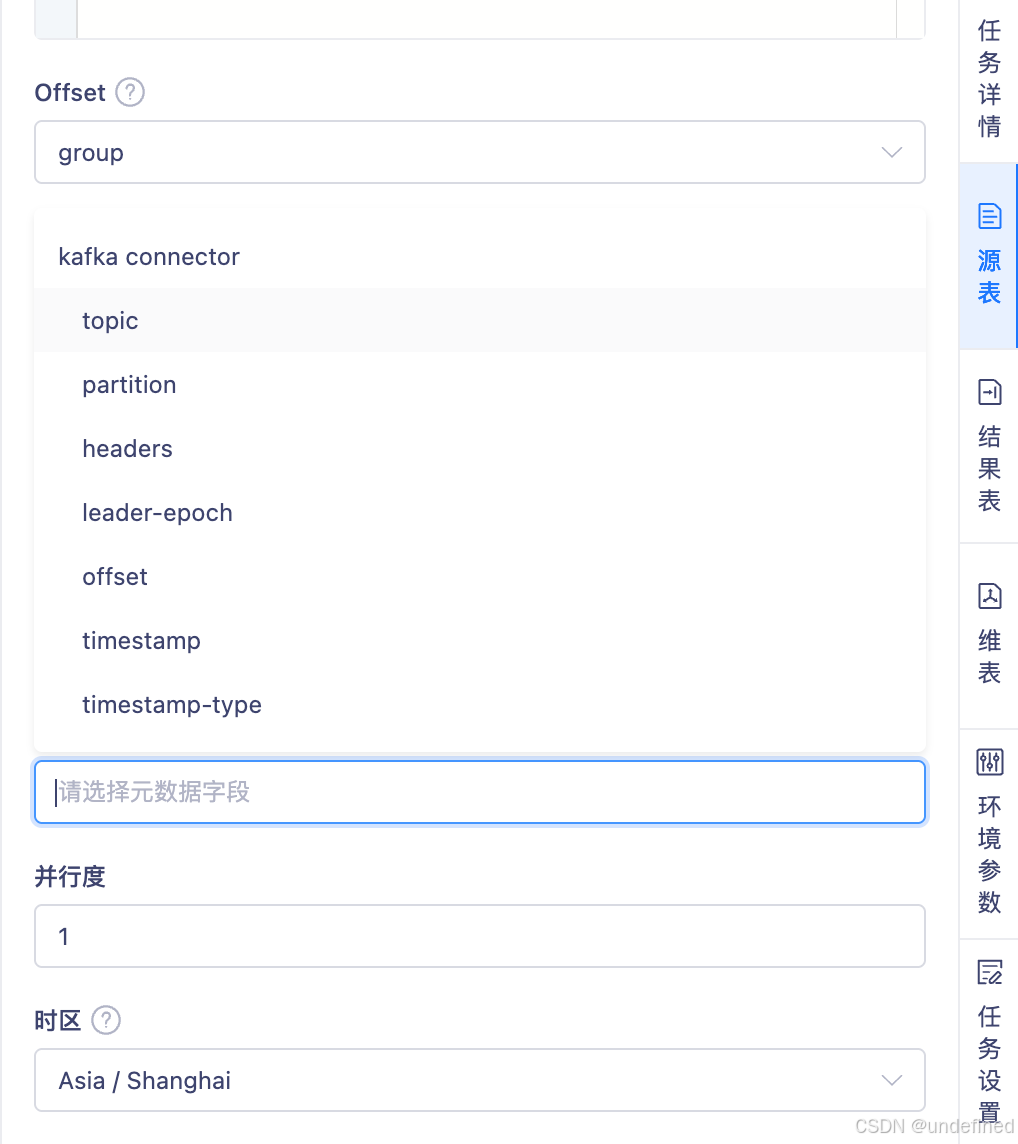
运维管理中告警规则支持对应多个告警指标
运维管理告警能力进一步优化:现在支持单个告警配置多个告警指标,对相似告警可统一处理,减少重复配置工作;同时支持在同一维度下设置多条触发规则,只要满足任意一条即可触发告警,帮助用户更高效地进行运维监控。
元数据管理 HiveMetaStore 支持 Hive3.1 适配
完成元数据管理 Catalog 对 HiveMetaStore 的 Hive 3.1 版本适配,支持 Flink 1.16,并在数据源中心新增 HiveMetaStore 3.x 类型。该版本可在 Hadoop 3.x 集群中运行,支持认证方式开启 Kerberos 和非开启 Kerberos 的情况,同时支持 Hive 3.x 下的 Paimon 湖格式,为用户带来更完善的湖仓一体化体验。
底层元数据库适配达梦(DM)
-
通过将底层元数据库全面适配至国产达梦(DM)数据库,助力企业在关键数字基础设施领域的自主可控。
其他新增内容
-
元数据管理支持控制台 Sftp 使用 RSA 认证方式
-
FLinkSQL 支持 hyperbase 9.0 作为维表和结果表适配
-
FLinkSQL 支持 keybyte 9.0 作为维表和结果表适配
-
FLinkSQL 结果表支持 KingBaseESV8R6
-
FLinkSQL 结果表支持 OushuDB 外部表写入
功能优化
重点功能优化说明
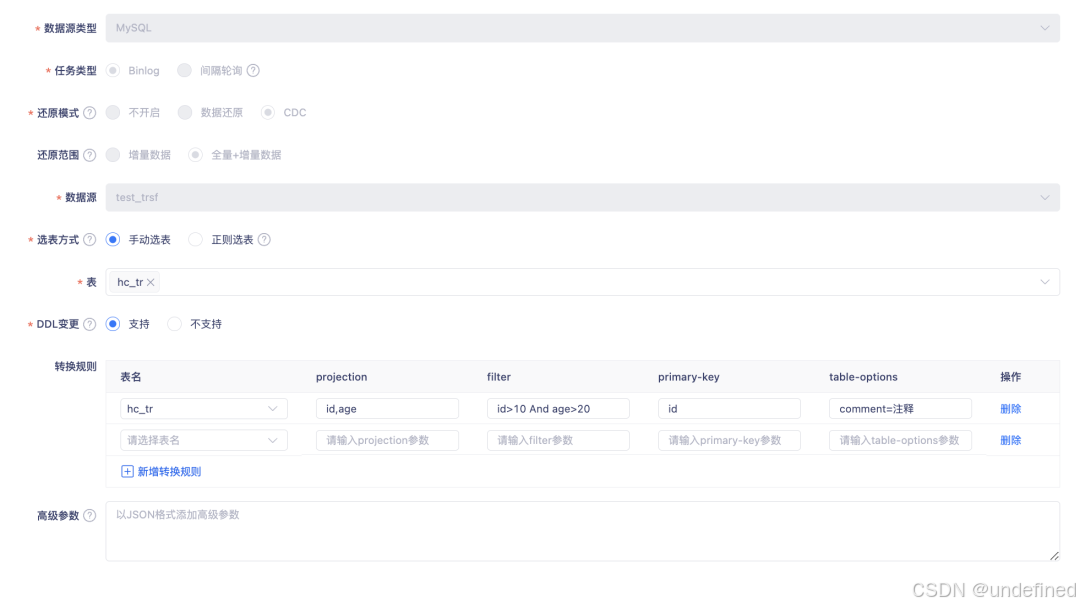
实时采集 FLinkCDC 优化支持 Transformer 转换规则
实时采集 FlinkCDC 现已支持 Transformer 转换规则,在 Flink 1.16 版本下可对表字段进行 projection、filter、primary-key、table-options 等级别的灵活转换。
FLinkSQL 支持 FLinkCDC 数据源可视化 Oralce
FlinkSQL 支持对 FlinkCDC Oracle 数据源的可视化支持,适用于 Flink 1.16 版本,用户可在向导模式下直接配置 Oracle-CDC。
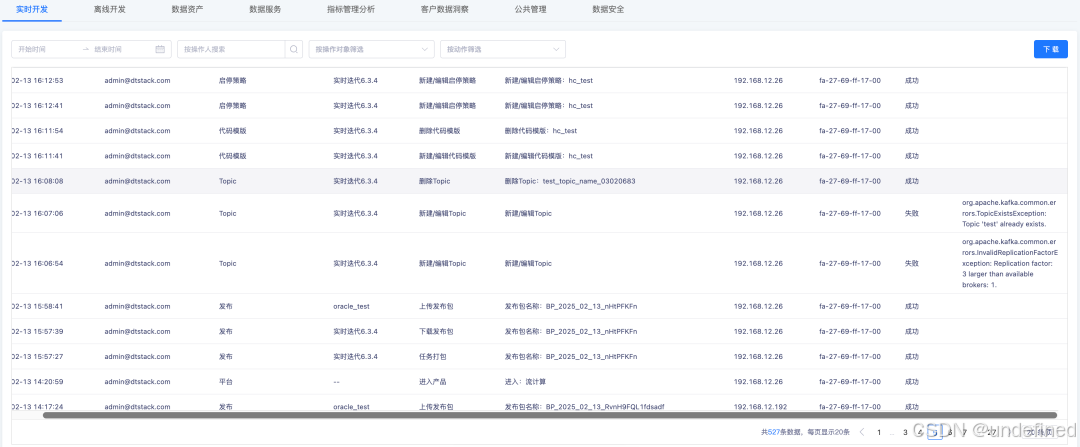
实时开发平台操作记录至安全审计平台
实时开发平台完成一系列内部优化:新增操作记录同步至安全审计平台,并在列表中支持展示操作结果、失败原因及操作对象筛选;同时整理并整合历史动作,优化操作对象匹配与搜索条件;此外,还修复了数据预览连接信息显示和页面字符超长展示等问题,整体执行与审计体验更完善。
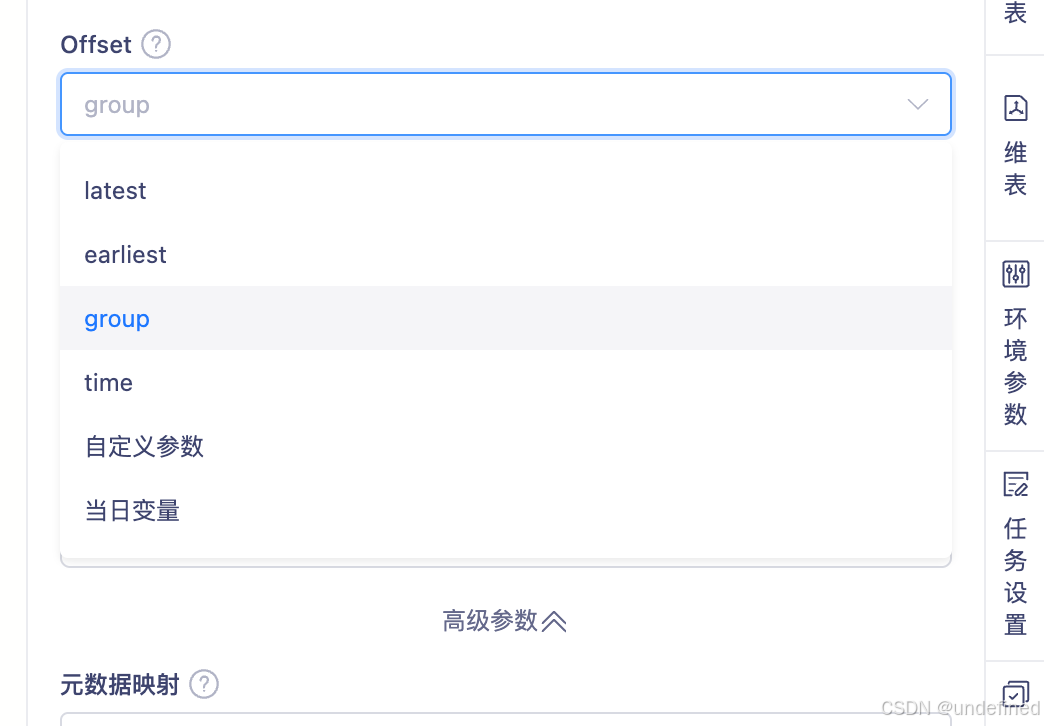
FLinkSQL 向导模式源表 Kafka 配置 offset 支持选择 group-offsets
FlinkSQL 向导模式在配置 Kafka 源表 offset 时,现已支持选择 group-offsets,适用于 Flink 1.12 与 1.16 版本;当未输入 group.id 时,系统会自动设置默认值,使用更便捷。
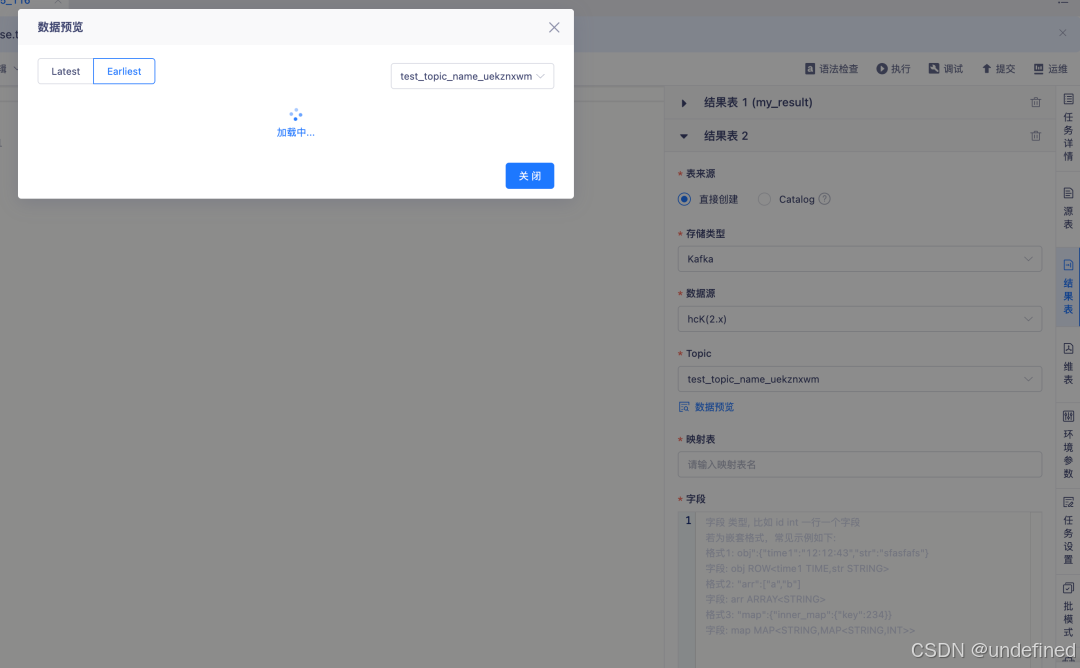
优化参数模版提示及数据预览功能
参数模板与数据预览功能优化:更新了参数模板提示语,并在 FlinkSQL 数据开发中扩展了数据预览能力,现已支持更多数据源,包括 PostgreSQL、KingbaseES、Impala、ClickHouse、TiDB、Kudu、MongoDB 以及 Kafka(结果表),让调试与验证更高效。
实时采集适配引擎已完成的数据源插件
实时采集优化支持引擎适配的数据源插件,在 Flink 1.16 版本下支持 TiDB、OceanBase(MySQL、Oracle 模式)及 PostgreSQL 的间隔轮询采集,进一步完善数据源接入能力。
底层 Engine-plguins 提交流程状态优化
-
内部对 Engine-plguins 提交流程状态优化,解决客户在提交任务的时候在资源不足,网络波动,hdfs 负载过高等场景下会出现状态游离的场景。
-
-
修复场景hdfs负载过高,网络波动导致任务上传 jar 包时间过长超过调度超时时间导致任务游离。
-
修复场景资源不足导致 perjob 任务被提交到 yarn 上之后由于集群没有资源拉起jm 导致任务导致 submit 接口没有返回从而超时。导致任务游离。
-
修复场景资源不足导致 perjob 任务被提交到 yarn 上之后由于集群没有资源拉起jm导致任务导致 submit 接口没有返回,而此时客户对于当前任务进行kill操作导致任务游离。
-
其他功能优化说明
-
实时湖仓一级菜单名称变更为元数据管理;
-
数据开发任务执行按钮体验优化:在 FlinkSQL 数据开发中,任务结果页已移除“开始/停止”按钮,执行中状态仅展示停止按钮,任务停止后则展示执行按钮,操作更直观高效;
-
实时采集 PGWAL Source 现已支持将数据写入 Kafka,并兼容多种数据类型,包括 JSON、JSONB、Array、Geometry(PostGIS 经纬度)及 Enum 类型,适用于 Flink 1.16 版本,满足更丰富的数据采集需求;
-
FlinkSQL Oushu 写入内外表切换通过结果表前端配置选择项进行切换,默认使用COPY 导入方式,需在控制台配置 HDFS 参数后支持选择 HDFS 导入切换;
-
FLinkSQL 向导模式支持开启 kerberos 的 hive2 数据源;
-
Kafka 版本适配优化:在项目交付中,Kafka 0.10 与 0.11 版本区分支持,实现 Topic 管理对两版本的创建操作;
-
实时前端页面已完成整体 UI 优化与迁移,为用户带来更清晰流畅的使用体验。