目标检测定位损失函数:Smooth L1 loss 、IOU loss及其变体
Smooth L1 Loss
概述
Smooth L1 Loss(平滑 L1 损失),是一个在回归任务,特别是计算机视觉中的目标检测领域(如 Faster R-CNN, SSD)非常核心的损失函数。
xxx 表示模型的预测值,yyy 表示真实值,z=x−yz = x - yz=x−y 表示预测值与真实值之间的差异。常用的 L1 loss、L2 Loss 和 smooth L1 loss 定义分别为
L1 loss(MAE):
LL1(x,y)=∣x−y∣=∣z∣L_{L1}(x,y) = |x - y| = |z|LL1(x,y)=∣x−y∣=∣z∣
L2 loss(MSE):
LL2(x,y)=0.5(x−y)2=0.5z2L_{L2}(x,y) = 0.5(x - y)^2 =0.5z^2LL2(x,y)=0.5(x−y)2=0.5z2
Smooth L1 Loss:
LsmoothL1(x,y)={0.5(x−y)2=0.5z2,if ∣x−y∣<1∣x−y∣−0.5=∣z∣−0.5,otherwiseL_{smoothL1}(x,y)=\begin{cases} 0.5(x-y)^2 = 0.5z^2, & \text{if } |x-y|<1 \\|x-y|-0.5= |z|-0.5, & \text{otherwise} \end{cases}LsmoothL1(x,y)={0.5(x−y)2=0.5z2,∣x−y∣−0.5=∣z∣−0.5,if ∣x−y∣<1otherwise
函数坐标图如下:横轴为z,纵坐标为损失loss

- L1 loss 在零点处不可导(梯度不连续),且收敛速度较慢。L1 loss 对 zzz的导数为常数,在训练后期,误差值zzz很小时,如果 learning rate 不变,损失函数会在稳定值附近波动,很难收敛到更高的精度。
- L2 loss 当预测值与真实值差距很大时,由于平方项的存在,损失值会变得非常大,梯度也很大,容易导致训练不稳定(梯度爆炸)
- Smooth L1 Loss 的设计目的就是为了避开了 L1 loss 和 L2 loss 的缺点。它在误差较小的区域使用像 L2 loss这样的二次函数,保证梯度平滑且逐渐减小;而在误差较大的区域使用像 L1 loss这样的线性函数,限制梯度的大小,从而对异常值不那么敏感。
Smooth L1 Loss 的梯度函数是:
ddzsmoothL1={z,if ∣z∣<1+1或−1,otherwise\frac{d}{dz} {smoothL1}=\begin{cases} z, & \text{if } |z|<1 \\+1 或-1, & \text{otherwise} \end{cases}dzdsmoothL1={z,+1或−1,if ∣z∣<1otherwise
- 小误差∣z∣<1|z|<1∣z∣<1时,即当预测值接近真实值时,梯度很小,参数更新幅度小,有利于模型收敛和精细化。且梯度是连续变化的,训练过程非常稳定。
- 大误差∣z∣≥1|z| \geq 1∣z∣≥1时,即使预测结果非常离谱,梯度也不会爆炸(不会像L2 loss那样变化巨大),避免了因个别异常样本而导致训练过程剧烈波动,增强了训练的鲁棒性。
目标检测中的应用
在目标检测中,网络需要预测目标边界框(Bounding Box)的精确坐标(中心点 x, y,宽 w, 高 h)。这是一个典型的回归任务。
- 如果使用 L2 Loss,当某个坐标的预测初值离真实值很远时,会产生巨大的损失和梯度,这会主导整个训练过程,使得模型难以收敛到好的结果。
- Smooth L1 Loss 对初值不准的预测框更加宽容,提供了稳定且有限的梯度,使得模型能够逐步修正框的位置,而不是被异常值带偏。Faster R-CNN 和 SSD 等经典模型都使用了 Smooth L1 Loss 作为边界框回归的损失函数。
Smooth L1 Loss 完美地权衡了训练的稳定性(对抗异常值)和收敛的有效性(小误差时梯度精细),使其成为需要高精度回归任务(如目标检测)的理想选择。
函数接口
在 PyTorch 中,Smooth L1 Loss 通过 nn.SmoothL1Loss 类实现
torch.nn.SmoothL1Loss(size_average=None,reduce=None,reduction='mean',beta=1.0
)
- reduction (str, optional): 指定损失的聚合方式,可选 ‘none’、‘mean’(默认值)或 ‘sum’。
- beta (float, optional): 一个超参数,指定从二次函数切换到线性函数的阈值。默认值为 1.0,即上面公式中的切换点。修改 beta 可以调整损失函数对“大误差”和“小误差”的定义。
import torch
import torch.nn as nn# 创建损失函数
# reduction='mean':计算所有元素损失的平均值
smooth_l1_loss = nn.SmoothL1Loss(reduction='mean')# 假设预测值和真实值
# 例如:预测了4个边界框的偏移量
predictions = torch.tensor([1.6, 0.2, -2.0, 0.8])
targets = torch.tensor([1.0, 0.0, -1.0, 1.0])# 计算损失
loss = smooth_l1_loss(predictions, targets)
print(loss)# 手动计算验证:
# x = predictions - targets = [0.6, 0.2, -1.0, -0.2]
# |x| = [0.6, 0.2, -1.0, 0.2] -> 全部小于beta(1.0),所以都用 0.5*x^2
# loss = (0.5*0.6^2 + 0.5*0.2^2 + 0.5*(-1.0)^2 + 0.5*(-0.2)^2) / 4
# = (0.18 + 0.02 + 0.5 + 0.02) / 4
# = 0.72 / 4 = 0.18
IOU loss
概述
在目标检测中,最常用的评估模型好坏的指标就是 IOU。它衡量的是预测边界框(Bounding Box)与真实边界框之间的重叠程度。
传统的L1 loss,L2 loss,Smooth L1 loss存在如下问题:
- 通过优化边界框的坐标(x, y, w, h)来间接优化IOU,但坐标误差最小并不总是等同于 IOU 最大化,这样就导致了不一致性。
- 通过4个点回归坐标框的方式是假设 4个坐标点是相互独立的,没有考虑其相关性,而实际上 4个坐标点具有一定的相关性。
- 基于 L1 和 L2 距离的 loss 不具有尺度不变性
IOU Loss 的解决方案:既然最终评估标准是 IOU,那就直接使用 IOU 作为损失函数来指导模型的优化方向。使模型的训练目标(损失最小化)
和最终的评估目标(IOU 最大化) 实现统一。
IOU loss的计算
对于两个区域(通常是预测框 B_pred 和真实框 B_gt)
IOU计算如下:
IOU=Area of OverlapArea of Union=Bpred∩BgtBpred∪Bgt\text{IOU} = \frac{\text{Area of Overlap}}{\text{Area of Union}} = \frac{B_{pred} \cap B_{gt}}{B_{pred} \cup B_{gt}}IOU=Area of UnionArea of Overlap=Bpred∪BgtBpred∩Bgt
IOU 的取值范围是 [0, 1]:1表示两个框完全重合;0表示两个框没有交集
IOU loss 就是将IOU 转化为损失。损失越低越好,IOU越高越好,所以IOU loss如下计算:
LIOU=1−IOU\mathcal{L}_{IOU} = 1 - IOULIOU=1−IOU
IOU = 1(完美预测)时,损失为 0。IOU = 0(毫无交集)时,损失为 1
优点:
- 尺度不变性:IOU 是一个比值,它只关心重叠区域的比例,而不关心框的绝对大小。这意味着它对大小不同的目标物是公平的。
- 与评估指标一致:直接优化 IOU 使得模型训练过程更直接地对最终的评价指标负责。
缺点:
- 最核心问题是无法处理不相交的情况。如果两个框没有交集,则 IOU = 0,损失恒为 1。此时梯度为 0,无法为模型提供如何移动预测框以与真实框相交的梯度信息,导致模型无法学习。
- 无法区分不同方式的重合不良。IOUIOUIOU值不能反映两个框是如何相交的,即使两个框的 IOUIOUIOU值是相同的,其相交方式也可能很不一样。只要 IOU 相同,损失就是相同的。
def calculate_iou(box1, box2):"""计算两个框的IoUArgs:box1: (tensor) [x1, y1, x2, y2]box2: (tensor) [x1, y1, x2, y2]Returns:iou: (tensor) scalar"""# 计算交集区域的坐标x1 = torch.max(box1[0], box2[0])y1 = torch.max(box1[1], box2[1])x2 = torch.min(box1[2], box2[2])y2 = torch.min(box1[3], box2[3])# 计算交集面积intersection_area = torch.clamp(x2 - x1, min=0) * torch.clamp(y2 - y1, min=0)# 计算各自面积box1_area = (box1[2] - box1[0]) * (box1[3] - box1[1])box2_area = (box2[2] - box2[0]) * (box2[3] - box2[1])# 计算并集面积union_area = box1_area + box2_area - intersection_area# 避免除零iou = intersection_area / (union_area + 1e-6)return ioudef iou_loss(pred_boxes, target_boxes):"""计算IoU LossArgs:pred_boxes: (tensor) [N, 4] (x1, y1, x2, y2)target_boxes: (tensor) [N, 4] (x1, y1, x2, y2)Returns:loss: (tensor) scalar"""ious = torch.stack([calculate_iou(pred, tgt) for pred, tgt in zip(pred_boxes, target_boxes)])loss = 1 - iousreturn loss.mean() # 使用mean reduction# 使用示例
preds = torch.tensor([[100, 100, 200, 200], [50, 50, 150, 150]], dtype=torch.float32)
targets = torch.tensor([[110, 110, 210, 210], [60, 60, 160, 160]], dtype=torch.float32)loss = iou_loss(preds, targets)
print(f"IoU Loss: {loss}")
IOU loss的变体
为解决IOU loss 的缺陷,在原始IOU 基础上提出了一系列先进的变体。如GIOU,DIOU,CIOU等等。
通常以IOU为基础的变体IOU loss可以定义为
L=1−IoU+R(B,Bgt)L =1- IoU + R(B, B_{gt})L=1−IoU+R(B,Bgt)
其中:
- BBB : 表示预测框
- BgtB_{gt}Bgt :表示目标框
- R(B,Bgt)R(B, B_{gt})R(B,Bgt) : 表示预测框 BBB 和 目标框 BgtB_{gt}Bgt 的惩罚项
GIOU loss
即使两个框不相交,也需要提供一个梯度方向。GIOU 在 IOU 的基础上引入了一个最小封闭矩形框 C(能够同时包含预测框和真实框的最小矩形),它不仅考虑了边界框之间的重叠程度,还考虑了bboxes 之间的位置和尺寸。
GIoU=IoU−C−(A∪B)∣C∣GIoU = IoU - \frac{C - (A \cup B)}{|C|}GIoU=IoU−∣C∣C−(A∪B) ,其中,C 是 A 和 B 的外接矩形框面积
GIoULoss=1−GIoUG{IoU Loss} = 1- GIoUGIoULoss=1−GIoU ,
即 :
LGIoU=1−IoU+C−(A∪B)∣C∣L_{GIoU} = 1 - IoU + \frac{C - (A \cup B)}{|C|}LGIoU=1−IoU+∣C∣C−(A∪B)
其中:
0≤=IoU<=10≤= IoU <=10≤=IoU<=1
0<=C−(A∪B)C<10 <= \frac{C - (A \cup B)}{C} <10<=CC−(A∪B)<1
- 当 A 和 B 完全重合时:
IoU=1, C−(A∪B)C=0IoU = 1, \; \frac{C - (A \cup B)}{C} =0IoU=1,CC−(A∪B)=0 →\rightarrow→ GIoU=1,GIoU_Loss=0GIoU = 1, GIoU\_Loss=0GIoU=1,GIoU_Loss=0 - 当 A,B 完全不重叠时( A,B 距离无穷远的时候):
IoU=0,C−(A∪B)C趋近于1IoU=0,\frac{C - (A \cup B)}{C}趋近于 1IoU=0,CC−(A∪B)趋近于1 →\rightarrow→ GIoU=−1,GIoU_Loss=2GIoU = -1, GIoU\_Loss=2GIoU=−1,GIoU_Loss=2
优点:
解决了不相交时梯度为 0 的问题。即使不相交,模型也会学习朝着最小封闭框 C 的中心移动预测框,以减小附加项,从而促使两个框先发生交集。
GIOU 是 IOU 的一个下界,GIOU≤IOU\text{GIOU} \leq \text{IOU}GIOU≤IOU。
缺点:
当两个框包含(如一个框在另一个框内部)时,GIOU 会退化成 IOU,此时提供的移动方向仍然比较模糊。
DIOU loss
DIOU loss 直接最小化两个框中心点之间的距离。这样可以为模型的优化提供一个非常明确且高效的方向。
DIOU loss的计算公式如下:
LDIoU=1−IoU+ρ2(b,bgt)c2
L_{DIoU} = 1 - IoU + \frac{\rho^2(b, b_{gt})}{c^2}
LDIoU=1−IoU+c2ρ2(b,bgt)
其中:
ρ(b,bgt)\rho(b, b_{gt})ρ(b,bgt) 表示预测框与真实框中心点之间的欧式距离。
b,bgtb, b_{gt}b,bgt 分别表示预测框的中心点,真实框的中心点。
ccc 表示真实框与预测框的最小外接矩形框的对角线长度。
优点:
- 具有尺度不变性 : 由于ρ2(b,bgt)c2\frac{\rho ^2(b, b_{gt})}{c^2}c2ρ2(b,bgt)是一个相对度量,不直接依赖于框的具体宽度和高度,所以在不同尺度下仍能保持一致的度量标准,这种尺度不变性有助于提高检测的准确性和鲁棒性。
- 当两个框完全重合时,LIoU=LGIoU=LDIoU=0L_{IoU} = L_{GIoU} = L_{DIoU} = 0LIoU=LGIoU=LDIoU=0
- 当两个框不相交时,DIoU Loss 可以直接优化 2个框之间的距离,比 GIoU Loss 收敛速度更快
- 对于两个框包含的情况,DIoU Loss 可以收敛的很快,而 GIoU Loss此时退化为IoU Loss收敛速度较慢
缺点:
DIoU 能够直接最小化预测框和真实框的中心点距离加速收敛,但是未考虑到高宽比。
如下图所示:红色为预测框,蓝色为真实框。三个红框的面积相同,红框与蓝框中心点重合,但是红框的长宽比不一样,三种情况下的DIoU相同,但显然中间的更拟合真实框。
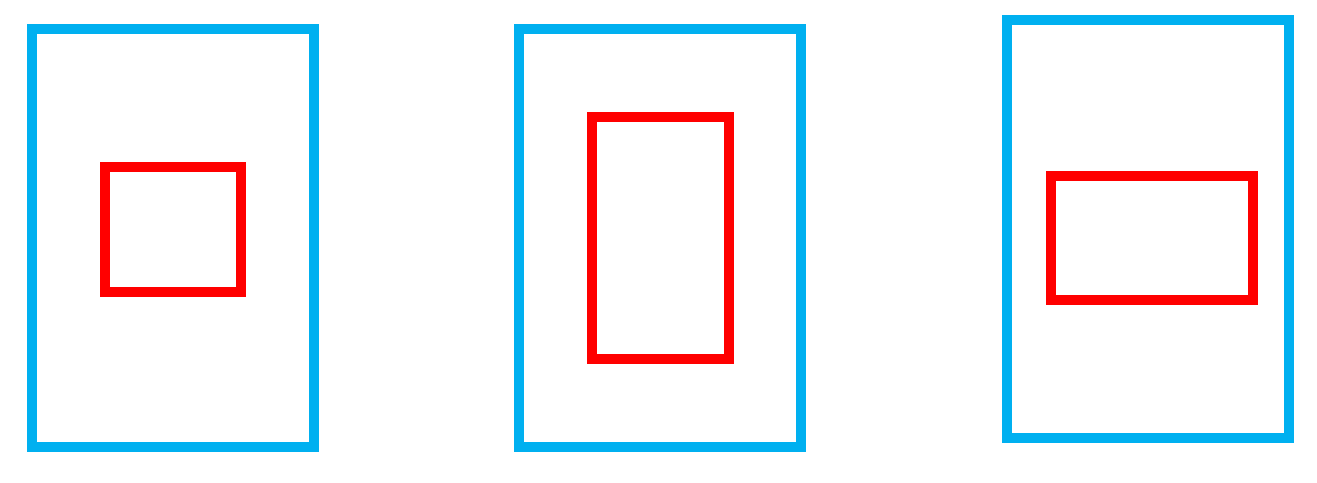
CIOU loss
由于DIOU loss忽略了宽高比的一致性,CIoU 在 DIoU 的基础上增加了一个惩罚项,同时考虑重叠面积、中心点距离和宽高比。
LCIoU=1−IoU+ρ2(b,bgt)c2+αv
L_{CIoU} = 1 - IoU + \frac{\rho^2(b, b_{gt})}{c^2} + \alpha v
LCIoU=1−IoU+c2ρ2(b,bgt)+αv
其中:
vvv 衡量长宽比一致性的参数 : v=4π2(arctanwgthgt−arctanwh)2v = \frac{4}{\pi^2}(arctan \frac{w_{gt}}{h_{gt}} - arctan \frac{w}{h})^2v=π24(arctanhgtwgt−arctanhw)2。
α\alphaα 是权重平衡因子,调整长宽比的影响 : α=v(1−IoU)+v\alpha = \frac{v}{(1-IoU)+v}α=(1−IoU)+vv。
优点:
考虑影响因素相对全面,考虑到了定位损失的三个重要的因素 : 重叠面积、中心点距离、高宽比。
缺点:
αv\alpha vαv这一项的设计,导致拖累了收敛速度。
- vvv 仅反映了高宽比的差异性,高宽比一致则v=0v=0v=0,这样的设计存在缺陷。 比如真实框的 wgt=8,hgt=4,wgthgt=2w_{gt}=8,h_{gt}=4,\frac{w_{gt}}{h_{gt}}=2wgt=8,hgt=4,hgtwgt=2 ,而预测出的 w=6,h=3,wh=2w=6,h=3, \frac{w}{h}=2w=6,h=3,hw=2 ,此时v=0v=0v=0
- vvv只反映了高宽比的差异,并没有分别反映出 wgtw_{gt}wgt和 www 之间的关系,以及 hgth_{gt}hgt 和 hhh 之间的关系,这导致其收敛方向不够明确,CIOU损失可能会向不合理的方向优化。
- vvv对 www 和 hhh 的偏导数分别如下 :
∂v∂w=8π2(arctanwgthgt−arctanwh)∗hw2+h2\frac{\partial v}{\partial w} = \frac{8}{\pi^2}(arctan \frac{w_{gt}}{h_{gt}}- arctan \frac{w}{h}) * \frac{h}{w^2+h^2}∂w∂v=π28(arctanhgtwgt−arctanhw)∗w2+h2h
∂v∂h=−8π2(arctanwgthgt−arctanwh)∗ww2+h2\frac{\partial v}{\partial h} = - \frac{8}{\pi^2}(arctan \frac{w_{gt}}{h_{gt}}- arctan \frac{w}{h}) * \frac{w}{w^2+h^2}∂h∂v=−π28(arctanhgtwgt−arctanhw)∗w2+h2w
由2个偏导数,可以得出 : ∂v∂w=−hw⋅∂v∂h\frac{\partial v}{\partial w} = -\frac{h}{w} \cdot \frac{\partial v}{\partial h}∂w∂v=−wh⋅∂h∂v ,
∂v∂w\frac{\partial v}{\partial w}∂w∂v 和 ∂v∂h\frac{\partial v}{\partial h}∂h∂v 的符号是相反的,只要 www 和 hhh 其中一个的值增加,另一个就会减小,即宽高是相互耦合的。当w<wgt 且 h<hgtw \lt w^{gt} \;\; 且 \;\;h \lt h^{gt}w<wgt且h<hgt时或者 w>wgt 且 h>hgtw \gt w^{gt} \;\; 且 \;\;h \gt h^{gt}w>wgt且h>hgt 时可能无法快速收敛。
EIOU loss
EIoU Loss 将 CIoU 中的宽高比损失项 vvv 解耦,直接拆分为分别针对宽度和高度的损失。
LEIoU=LIoU+Ldis+Lasp=1−IoU+ρ2(b,bgt)(wc)2+(hc)2+ρ2(w,wgt)(wc)2+ρ2(h,hgt)(hc)2\begin{align}
L_{EIoU} &= L_{IoU} + L_{dis} + L_{asp}\notag \\
\notag \\&= 1-IoU + \frac{\rho^2 (b,b_{gt})}{(w_c)^2+(h_c)^2} + \frac{\rho^2(w,w_{gt})}{(w_c)^2} + \frac{\rho^2(h,h_{gt})}{(h_c)^2} \notag \\
\end{align}LEIoU=LIoU+Ldis+Lasp=1−IoU+(wc)2+(hc)2ρ2(b,bgt)+(wc)2ρ2(w,wgt)+(hc)2ρ2(h,hgt)
其中:
- bbb 和 bgtb_{gt}bgt :分别表示预测框的中心点和真实框的中心点
- ρ(b,bgt)\rho (b, b_{gt})ρ(b,bgt):表示真实框与预测框中心点之间的欧式距离
- wcw_cwc 和 hch_chc:分别表示最小外接矩形框的宽度和高度
优点:
- 更直接的收敛目标:直接最小化宽度和高度的差异,为模型提供了更清晰、更直接的优化方向。
- 更快的收敛速度:由于梯度计算更直接,EIoU 通常比 CIoU 收敛得更快。
- 更高的定位精度:在许多基准测试中,EIoU 都展现出了比 CIoU 更优的边界框回归精度。
Focal-EIoU loss
Focal-EIoU Loss 的思想源于 Focal Loss(最初用于解决分类中的类别不平衡问题)。在目标检测中,也存在“样本不平衡”问题:简单样本(IOU 高的样本)和困难样本(IOU 低的样本)的数量不平衡。
问题:在一个训练批次中,大部分边界框回归样本是“简单”的(即 IoU 已经较高),只有少数是“困难”的(IoU 低)。标准的 IoU 损失对所有这些样本一视同仁,导致简单样本的损失贡献主导了总损失,模型难以集中精力去学习那些困难的、回归得不好的样本。
思路:借鉴 Focal Loss 的思路,降低简单样本的权重,让损失函数更加关注难以回归的样本。
Focal-EIoU Loss 在 EIoU Loss 的基础上增加了一个聚焦系数
LFocal−EIoU=IoUγ⋅LEIoU{L}_{Focal-EIoU} = IoU^{\gamma} \cdot {L}_{EIoU}LFocal−EIoU=IoUγ⋅LEIoU
其中:
LEIoU{L}_{EIoU}LEIoU:计算的 EIoU 损失。
γ\gammaγ:聚焦参数(通常 γ>0\gamma > 0γ>0),用于调节权重衰减的速率。
IoUγIoU^{\gamma}IoUγ:聚焦因子,IoUIoUIoU 的值在 [0, 1] 之间。
工作机制
- 对于一个困难样本(IoU → 0):IoUγ≈0IoU^{\gamma} \approx 0IoUγ≈0,但 LEIoU{L}_{EIoU}LEIoU 很大(接近 1)。最终的损失 LFocal−EIoU{L}_{Focal-EIoU}LFocal−EIoU 仍然很大,模型会重点关注这个样本。
- 对于一个简单样本(IoU → 1):IoUγ≈1IoU^{\gamma} \approx 1IoUγ≈1,但 LEIoU{L}_{EIoU}LEIoU 很小(接近 0)。最终的损失 LFocal−EIOU{L}_{Focal-EIOU}LFocal−EIOU 会变得更小,从而降低了简单样本在总损失中的权重。
优点:
- 解决回归样本不平衡:显著提升模型对困难样本的回归能力。
- 进一步提升性能:在 EIOU 的基础上,通常能获得更高的检测精度(mAP)。
- 即插即用:Focal 的思想可以迁移到其他 IOU 变体(如 Focal-CIOU)进行结合使用。