AWK文本处理工具
AWK文本处理工具的理论与实战全指南
- 前言:为什么需要掌握AWK?
- 一、AWK基础:是什么?为什么叫AWK?
- 1.1 AWK的本质与定位
- 1.2 AWK的起源与版本
- 二、AWK的工作原理与流程
- 2.1 核心处理逻辑:逐行扫描+字段拆分
- 2.2 工作流程的三要素:模式、动作与执行阶段
- 三、AWK核心语法详解
- 3.1 命令格式与调用方式
- 3.2 内置变量:预定义的“工具箱”
- 四、实战案例:从基础到进阶
- 4.1 基础案例:字段提取与简单过滤
- 4.2 进阶案例:统计与条件判断
- 4.3 高级功能:BEGIN/END、流程控制与数组
- 五、总结:AWK vs 其他文本工具
- 结语:从“会用”到“精通”的下一步
前言:为什么需要掌握AWK?
在Linux/Unix系统的日常运维、数据分析或文本处理场景中,我们经常需要面对这样的任务:从海量日志中提取关键信息(如统计访问量最高的IP)、清洗格式混乱的数据(如按特定分隔符拆分字段)、生成结构化报表(如汇总用户行为数据)。这些需求看似简单,但若用基础的grep(仅能过滤行)或sed(擅长行内编辑)直接处理,往往会陷入“能实现但效率低”“能提取但难格式化”的困境。
此时,AWK(Aho, Weinberger, Kernighan)——这款诞生于1970年代、由三位计算机科学家命名的文本处理语言,便成为了高效解决复杂文本问题的利器。它不仅是Linux系统的“常驻工具”(几乎所有发行版预装),更是处理结构化文本(如日志、CSV、配置文件)的“专业选手”:既能逐行扫描文本,又能按字段拆分数据;既能通过简单的条件判断过滤目标行,又能用内置函数与流程控制实现复杂计算;既能独立运行脚本,也能通过管道与其他命令(如grep、sed)无缝协作。
本文将从理论基础到实战案例,带你完整掌握AWK的核心语法、工作原理及高频应用场景,让你从“会用AWK”进阶到“精通AWK”,真正将其转化为生产力工具。
一、AWK基础:是什么?为什么叫AWK?
1.1 AWK的本质与定位
AWK是一种专为文本处理设计的解释型编程语言,同时也是行处理软件(类似sed,但更侧重字段级操作)。它的核心功能是:逐行读取文本,按指定分隔符拆分字段,根据条件匹配目标行,最后对字段执行格式化输出或计算。
与grep(仅过滤行)、sed(侧重行内编辑)不同,AWK的优势在于:
- 字段级操作:默认以空格/Tab为分隔符拆分每行为多个字段(如
$1、$2…),支持自定义分隔符; - 结构化处理:通过内置变量(如
NR行号、NF字段数)和逻辑控制(如if、for循环),实现复杂的数据筛选与聚合; - 格式化输出:灵活控制打印内容的格式(如字段间隔、对齐方式),适合生成报表。
1.2 AWK的起源与版本
AWK的名字来源于三位创始人的姓氏首字母:
- Alfred Aho(算法专家,参与设计正则表达式引擎)
- Peter Weinberger(贝尔实验室科学家,专注数据处理)
- Brian Kernighan(《C程序设计语言》作者,参与语言设计)
经过多年发展,AWK衍生出多个版本,主流的包括:
- AWK:贝尔实验室原始版本(功能基础);
- NAWK(New AWK):AT&T实验室的升级版(性能优化);
- GAWK(GNU AWK):GNU/Linux生态的标准实现(兼容AWK/NAWK,功能最全,本文聚焦此版本)。
在Linux系统中,通常通过awk命令调用GAWK(本质是软链接):
[root@benet22 opt]# which awk # 查看awk路径
/usr/bin/awk
[root@benet22 opt]# ls -l /usr/bin/awk # 确认是gawk的软链接
lrwxrwxrwx. 1 root root 4 8月 19 2022 /usr/bin/awk -> gawk

二、AWK的工作原理与流程
2.1 核心处理逻辑:逐行扫描+字段拆分
AWK的处理流程可以概括为:逐行读取输入文本(文件/管道/标准输入)→ 按分隔符拆分每行为多个字段 → 根据条件(模式)判断是否执行动作 → 对匹配的行执行指定操作(如打印字段、计算数值)。
关键特性:
- 默认分隔符:空格或Tab(可通过
FS内置变量修改); - 隐含循环:每匹配一次条件,对应的动作(
{commands})就会执行一次; - 无匹配默认输出:若未定义条件(模式),则默认处理所有行(类似条件为“始终为真”);
- 支持逻辑与数学运算:可用
&&(与)、||(或)、!(非)组合条件,支持+(加)、-(减)、*(乘)、/(除)、%(取余)、**或^(幂)等运算符。
2.2 工作流程的三要素:模式、动作与执行阶段
任何AWK语句均由**模式(Pattern)和动作(Action)**组成,二者共同决定“何时触发操作”。完整语法结构如下:
awk [选项] 'BEGIN{初始化代码} pattern{动作代码} END{收尾代码}' 文件1 文件2...
其中:
- BEGIN块(可选):在读取任何数据行之前执行,通常用于初始化变量(如设置分隔符、打印表头);
- 主体块(必选):对每一行输入数据执行匹配与操作(若未写模式,默认匹配所有行);
- END块(可选):在所有行处理完成后执行,常用于输出统计结果(如汇总总数、平均值)。
执行流程可简化为三步:
- 读(Read):从文件/管道/标准输入读取一行,存入内存;
- 执行(Execute):根据当前行的内容,判断是否匹配模式,若匹配则执行对应动作;
- 重复(Repeat):持续读取下一行,直到文件结束。
三、AWK核心语法详解
3.1 命令格式与调用方式
AWK支持两种使用方式:
- 直接命令行输入:适合简单任务(如快速提取字段);
awk '模式或条件 {操作}' 文件1 文件2... - 通过脚本文件调用:适合复杂逻辑(将脚本写入文件,用
-f指定);awk -f 脚本文件 文件1 文件2...
3.2 内置变量:预定义的“工具箱”
AWK提供了一系列内置变量,无需声明即可直接使用,用于控制分隔符、获取行/字段信息等。常用变量如下:
| 变量名 | 作用 | 示例说明 |
|---|---|---|
$0 | 当前处理的整行内容 | print $0 输出整行 |
$1, $2, … | 当前行的第1、2…个字段(列) | print $1 输出第一个字段 |
NF | 当前行的字段总数(列数) | print NF 输出当前行有多少列 |
NR | 当前处理的行号(全局计数,从1开始) | print NR 输出当前是第几行 |
FNR | 当前文件内的行号(多文件时独立计数) | 处理多个文件时,每个文件的行号单独统计 |
FS | 输入字段分隔符(默认空格/Tab) | awk -F':' 或 BEGIN{FS=":"} 指定冒号为分隔符 |
OFS | 输出字段分隔符(默认空格) | BEGIN{OFS="\t"} 设置输出字段用Tab分隔 |
ORS | 输出记录分隔符(默认换行符) | BEGIN{ORS=","} 设置行间用逗号连接 |
RS | 输入行分隔符(默认换行符) | BEGIN{RS=":"} 指定冒号为行分隔符(非标准用法) |
FILENAME | 当前正在处理的文件名 | 多文件输入时标识来源 |
示例(查看内置变量效果):
# 提取/etc/passwd中包含"root"的行,并打印第1列和第6列(用户名和家目录)
awk -F':' '/root/{print $1, $6}' /etc/passwd
# 输出:root /root operator /root# 打印每行的字段数(NF)和行号(NR)
awk -F':' '{print "第", NR, "行有", NF, "个字段"}' /etc/passwd | head -3
# 输出示例:第 1 行有 7 个字段 第 2 行有 7 个字段 第 3 行有 7 个字段


四、实战案例:从基础到进阶
4.1 基础案例:字段提取与简单过滤
场景1:打印文件内容(无条件处理所有行)
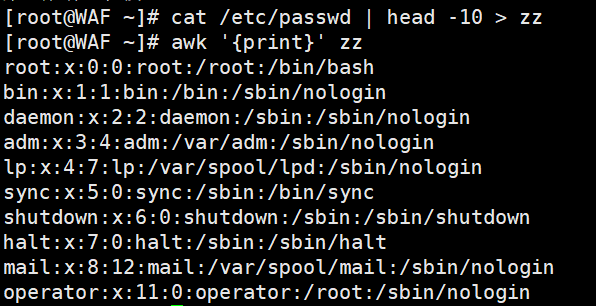
# 提取/etc/passwd前10行,用awk打印每一行(默认$0)
cat /etc/passwd | head -10 > zz
awk '{print}' zz # 等同于 cat zz
场景2:自定义分隔符提取特定字段
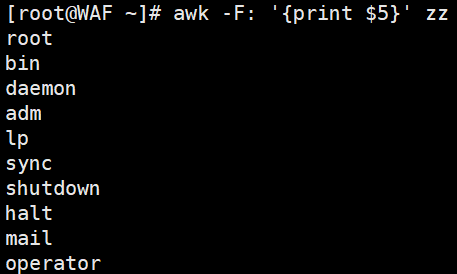
# 用冒号(:)分隔/etc/passwd,打印第5列(用户描述信息)
awk -F':' '{print $5}' zz
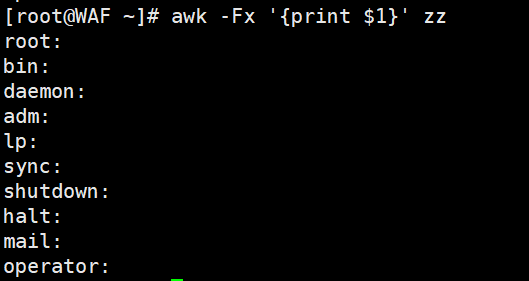
# 用"x"作为分隔符(演示自定义分隔符)
awk -Fx '{print $1}' /etc/passwd # 提取第一个"x"前的内容
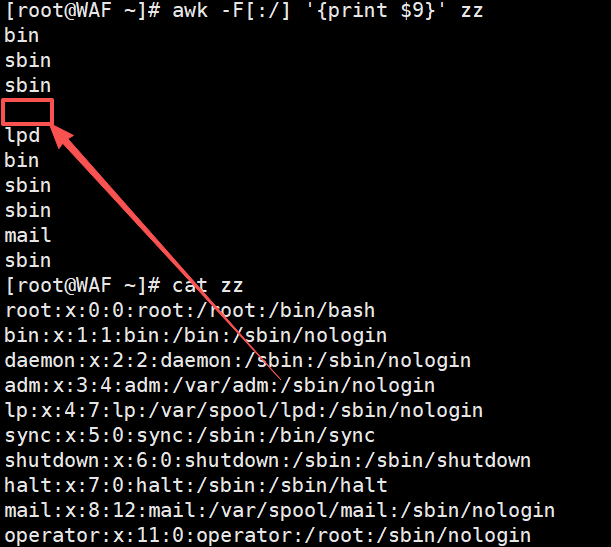
# 多分隔符示例(匹配冒号或斜杠)
awk -F'[:/]' '{print $9}' zz # 提取第一个冒号或斜杠分隔的第9个字段
场景3:格式化输出(控制字段间隔)
# 用制表符(Tab)分隔第1列和第2列
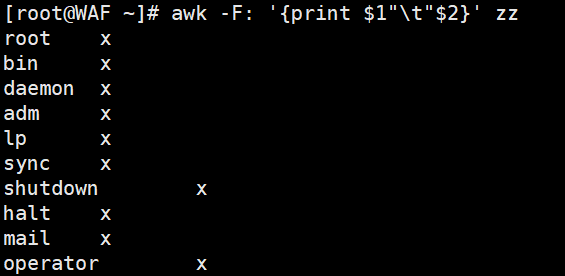
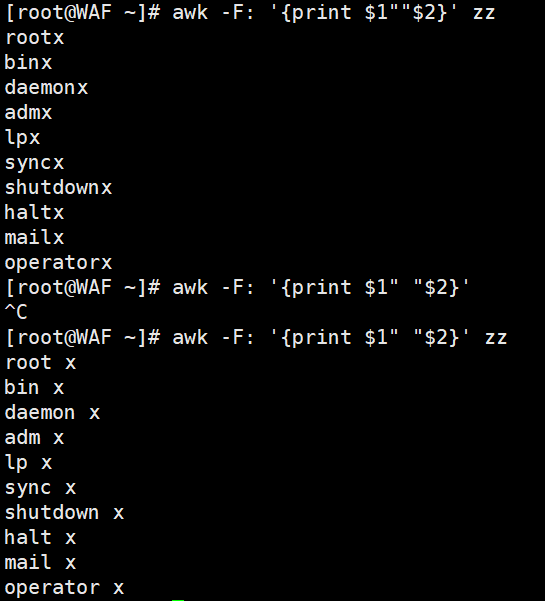
awk -F':' '{print $1 "\t" $2}' /etc/passwd
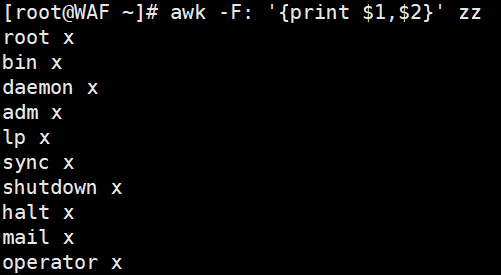
# 用空格分隔(逗号需加引号,否则被视为变量)
awk -F':' '{print $1, $2}' zz # 逗号自动转换为OFS(默认空格)
awk -F':' '{print $1""$2}' zz # 无引号时,$1和$2被视为变量拼接
4.2 进阶案例:统计与条件判断
场景1:统计行数与总字段数
# 打印文件总行数(END块在最后执行)
awk -F':' '{print NR}' /etc/passwd | tail -1 # 最后一行的NR即总行数
awk -F':' 'END{print NR}' /etc/passwd # 直接输出总行数(更高效)
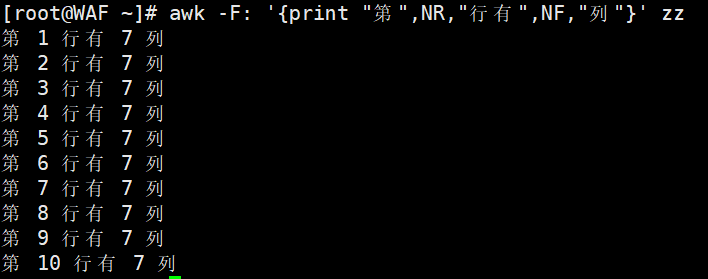
# 打印每行的列数(NF)
awk -F':' '{print "第", NR, "行有", NF, "列"}' zz

场景2:模糊匹配(正则表达式)
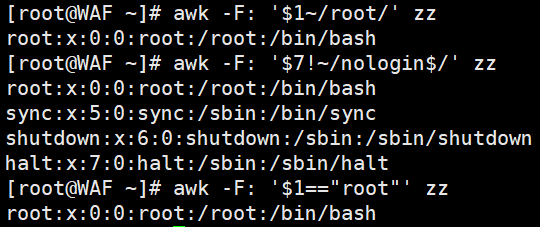
# 匹配第1列包含"root"的行(~表示“包含”)
awk -F':' '$1 ~ /root/' /etc/passwd
# 匹配第7列不以"nologin"结尾的行(!~表示“不包含”)
awk -F':' '$7 !~ /nologin$/' /etc/passwd
# 精确匹配第1列为"root"的行(==严格等于)
awk -F':' '$1 == "root"' /etc/passwd
场景3:数值与逻辑运算
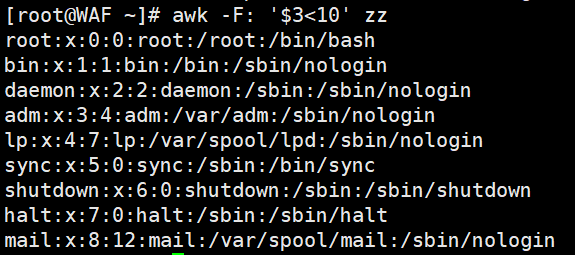
# 打印第3列(用户ID)小于10的行
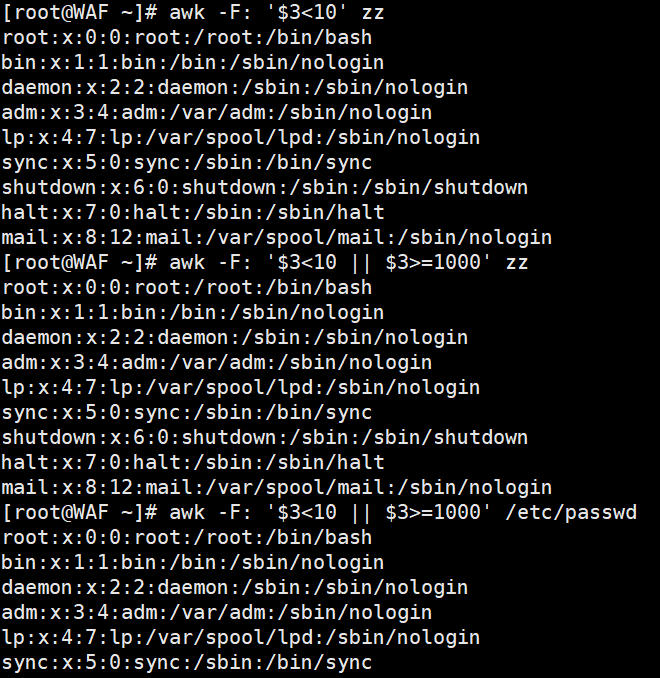
awk -F':' '$3 < 10' /etc/passwd
# 组合条件:第3列小于10 或 第3列大于等于1000(普通用户UID通常≥1000)
awk -F':' '$3 < 10 || $3 >= 1000' /etc/passwd
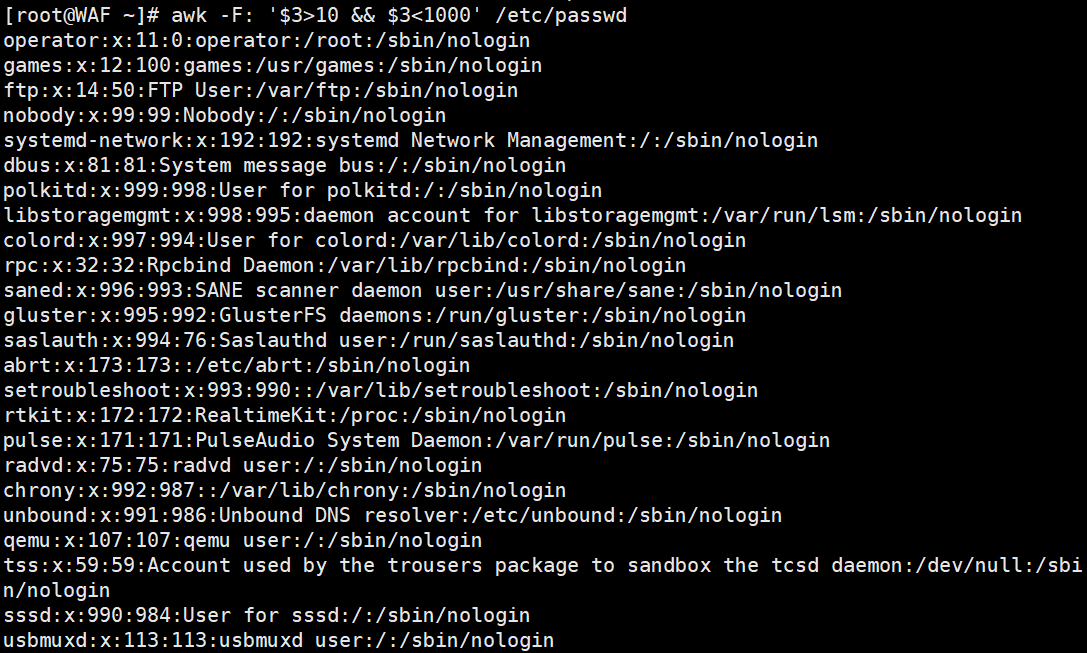
# 逻辑与:第3列大于10 且 小于1000(系统用户范围)
awk -F':' '$3 > 10 && $3 < 1000' /etc/passwd
场景4:生产环境实用案例(网卡IP与磁盘空间)
# 提取ens33网卡的IP地址(匹配"netmask"行,打印第2个字段)
ifconfig ens33 | awk '/netmask/{print "本机IP是:", $2}'
# 统计根分区可用空间(df -h的第4列)
df -h | awk 'NR==2{print "可用空间:", $4}'

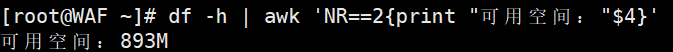
4.3 高级功能:BEGIN/END、流程控制与数组
场景1:BEGIN/END块的实际应用(表头与汇总)
# 统计以/bin/bash结尾的用户数量,并打印匹配行(BEGIN初始化计数器,END输出总数)
awk -F':' 'BEGIN{x=0} $7 ~ /\/bin\/bash$/{x++; print x, $0} END{print "总共有", x, "个bash用户"}' /etc/passwd
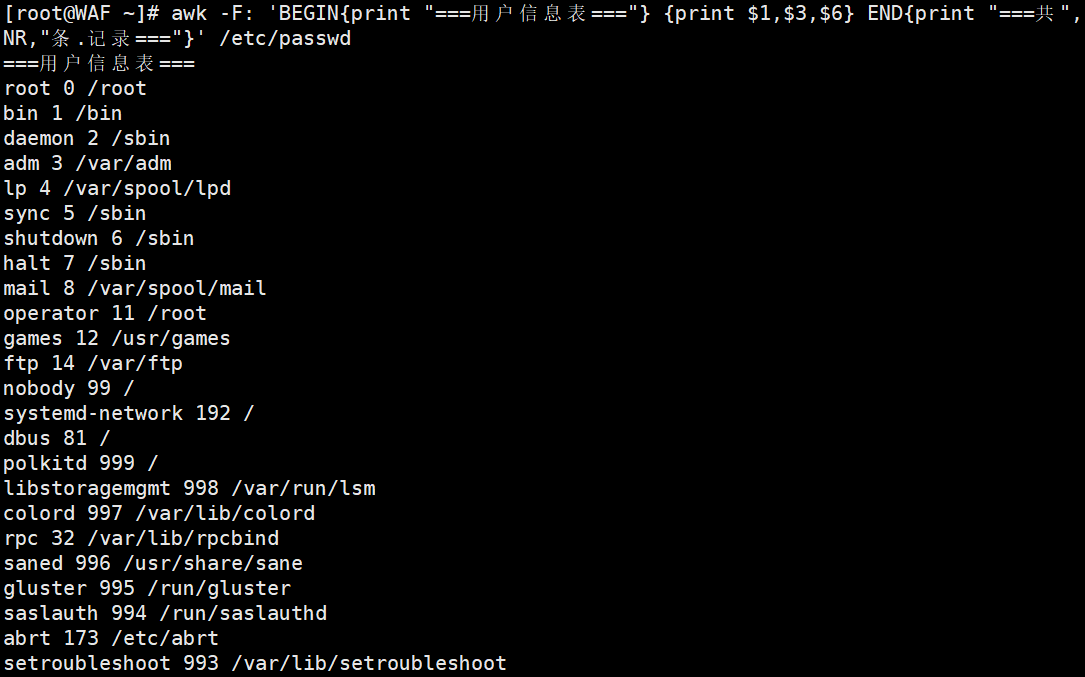
# 打印表头+数据+总结(模拟报表生成)
awk 'BEGIN{print "=== 用户信息报表 ==="} {print $1, $3, $6} END{print "=== 共", NR, "条记录 ==="}' /etc/passwd

场景2:AWK的流程控制(if语句)
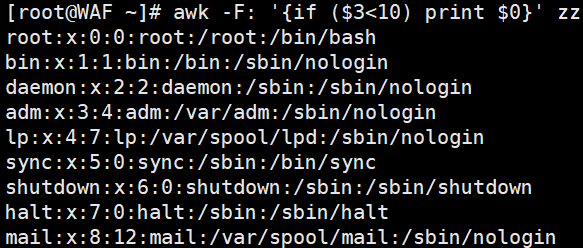
# 单分支:第3列小于10的行打印整行
awk -F':' '{if($3 < 10) print $0}' /etc/passwd
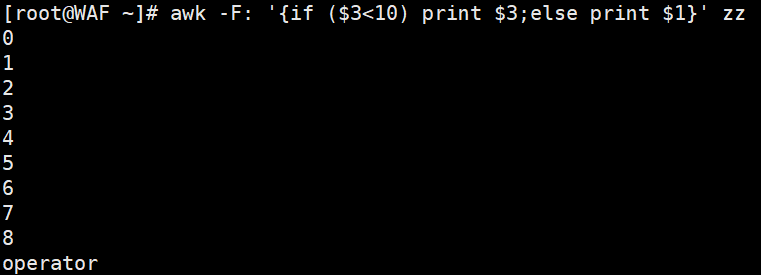
# 双分支:第3列小于10打印第3列,否则打印第1列
awk -F':' '{if($3 < 10) print $3; else print $1}' /etc/passwd
场景3:数组与循环(统计IP访问量)
# 统计HTTP访问日志中每个客户端IP的出现次数(按IP分组计数,最后排序输出)
awk '{ip[$1]++} END{for(i in ip) print ip[i], i}' /var/log/httpd/access_log | sort -nr
# 生产脚本:检测SSH登录失败次数(/var/log/secure中统计IP失败≥3次的告警)
awk '/Failed password/{ip[$11]++} END{for(i in ip) if(ip[i]>=3) print "警告!IP", i, "失败", ip[i], "次"}' /var/log/secure



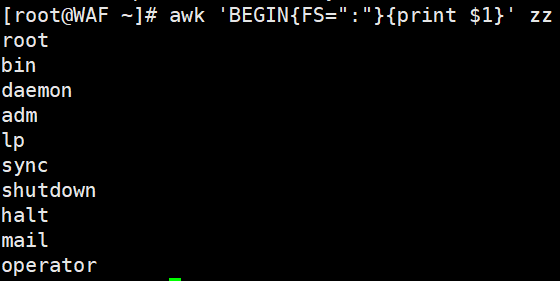
awk 'BEGIN{FS=":"}{print $1}' pass.txt #在打印之前定义字段分隔符为冒号
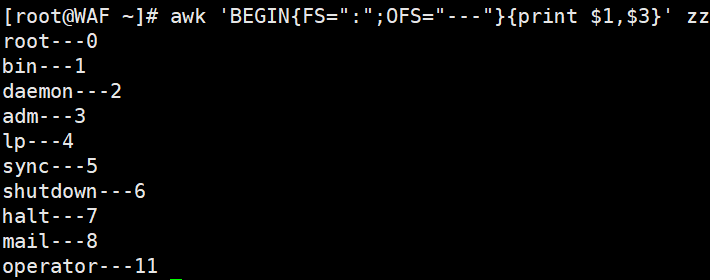
awk 'BEGIN{FS=":";OFS="---"}{print $1,$2}' pass.txt #OFS定义了输出时以什么分隔,$1$2中间要用逗号分隔,因为逗号默认被映射为OFS变量,而这个变量默认是
空格
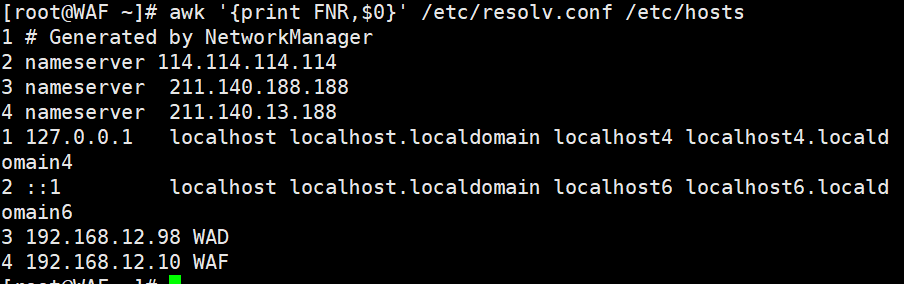
awk '{print FNR,$0}' /etc/resolv.conf /etc/hosts #可以看出FNR的行号在追加当有多个文件时
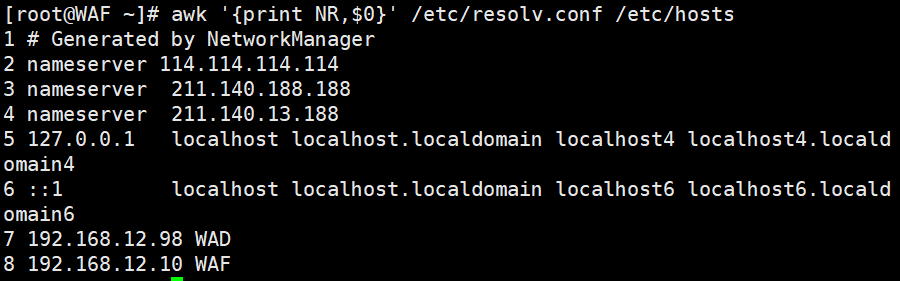
awk '{print NR,$0}' /etc/resolv.conf /etc/hosts
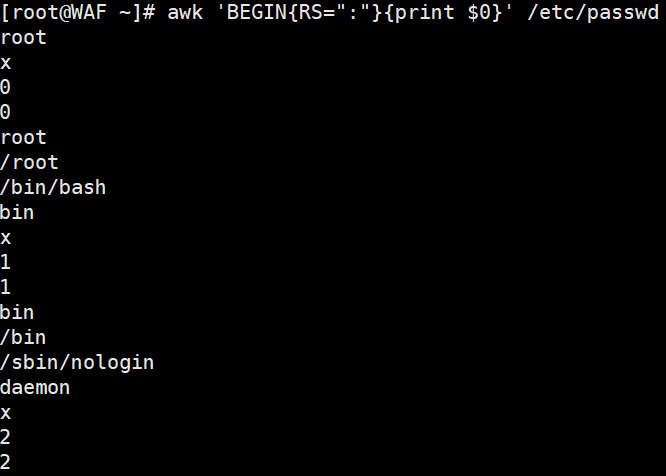
awk 'BEGIN{RS=":"}{print $0}' /etc/passwd #RS:指定以什么为换行符,这里指定是冒号,你指定的肯定是原文里存在的字符
awk 'BEGIN{ORS=" "}{print $0}' /etc/passwd #把多行合并成一行输出,输出的时候自定义以空格分隔每行,本来默认的是回车键

五、总结:AWK vs 其他文本工具
| 工具 | 核心定位 | 优势场景 | 局限性 |
|---|---|---|---|
| grep | 文本过滤(行级匹配) | 快速查找包含特定关键词的行 | 仅能过滤行,无法处理字段或计算 |
| sed | 流编辑器(行内编辑) | 替换、删除、插入行内内容 | 不擅长字段拆分与复杂逻辑 |
| awk | 文本报告生成器(字段级处理) | 格式化输出、字段统计、复杂条件筛选 | 对非结构化文本(如纯日志块)处理较弱 |
简单来说:
- 只想找包含某个词的行?用
grep! - 想修改行里的某些内容(如替换字符串)?用
sed! - 想按列拆分数据、统计字段或生成报表?用
AWK!
结语:从“会用”到“精通”的下一步
通过本文,你已经掌握了AWK的核心逻辑(逐行处理+字段拆分)、基础语法(内置变量、模式动作)、以及从简单字段提取到复杂统计分析的实战技巧。但要真正成为AWK高手,还需要:
- 多实践:尝试用AWK解决日常运维中的文本问题(如日志分析、配置文件处理);
- 深挖内置函数:学习字符串处理(
substr、length)、数学函数(sqrt)、时间函数(strftime)等; - 结合其他工具:通过管道将
awk与grep、sort、uniq等组合,构建更强大的文本处理流水线。
AWK的魅力在于“用简单的代码解决复杂的问题”。当你能熟练用它从混乱的文本中提取关键信息、生成清晰的报表时,你会发现——原来文本处理可以如此高效而优雅!