做 DevOps 还在被动救火?这篇让你把监控玩成 “运维加速器”!
做 DevOps 的你,是不是也常被这些糟心事绊住脚?
大促高峰 APP 加载卡成 “PPT”,团队围着屏幕查了 1.5 小时,才发现是 CDN 节点带宽跑满,这段时间订单流失率直接涨了 15%;凌晨 3 点服务器突然崩溃,运维被电话叫醒后,在 5 个监控工具间反复切换,花 2 小时才定位到是内存泄漏,用户投诉早就刷满了客服后台;明明买了不少云资源,却不知道哪些在 “躺平”,每月账单超预算,优化时又怕误删关键资源……
其实这些问题的根源,都藏在 “监控” 里。如今 CI/CD、自动化测试、IaC(基础设施即代码)成了 DevOps 的 “流量明星”,但真正能打通运维闭环的 “监控”,却常被当成 “后台配角”。可事实是:没有靠谱的 DevOps 监控,再完善的流程也会 “掉链子”—— 系统出问题看不见、故障定位慢半拍、资源浪费抓不住,最后 DevOps 的 “敏捷”“高效” 全成了空谈。
先搞懂:DevOps 监控不是 “看 uptime” 那么简单
很多人觉得 “监控” 就是看服务器有没有宕机、网络通不通 —— 这是传统监控的老思路,早跟不上现在的 IT 环境了。现在企业的架构里,既有物理服务器、虚拟机,又有 Docker 容器、K8s 集群,还有 AWS、Azure 这些云服务,混合环境下 “只看 uptime”,跟 “闭着眼睛走路” 没区别。
真正的 DevOps 监控,是一套 “全链路可观测” 体系:持续收集软件开发、基础设施、应用性能、用户体验的所有数据,通过分析和可视化,给开发、运维、测试甚至安全团队搭起 “反馈 loop”。它要覆盖的远不止 “系统活没活”,而是 6 个核心维度:
- 「系统健康」:底层服务器、容器、网络的 CPU、内存、磁盘 I/O 这些资源用得怎么样,有没有瓶颈;
- 「部署流水线」:代码构建成功率、测试通过率、部署耗时多少,有没有卡在某个环节;
- 「应用性能」:API 响应快不快、有没有报错、用户发起的交易能不能顺畅走完流程;
- 「业务指标」:支付成功率、订单转化率这些跟业务挂钩的数据,会不会受系统性能影响;
- 「用户体验」:北京用户打开 APP 要 2 秒,广州用户要 5 秒?页面加载到一半卡住了?这些 “用户真实感受” 得抓得到;
- 「安全态势」:有没有未授权的访问尝试、系统有没有已知漏洞、日志里有没有异常操作痕迹。
简单说,DevOps 监控要做到 “知其然,更知其所以然”—— 知道哪里出了问题,为什么出问题,甚至提前知道 “可能要出问题”,这才是它跟传统监控的本质区别。
为什么说 DevOps 监控是 “运维加速器”?6 个核心价值太实在
可能有人会问:我已经有了 API 监控、日志工具,还要专门搞 DevOps 监控吗?答案是 “必须要”—— 因为零散的工具解决不了 “全链路问题”,而 DevOps 监控能帮你搞定 6 件 “省钱、省时间、降风险” 的事:
主动防故障:把问题掐灭在 “萌芽期”
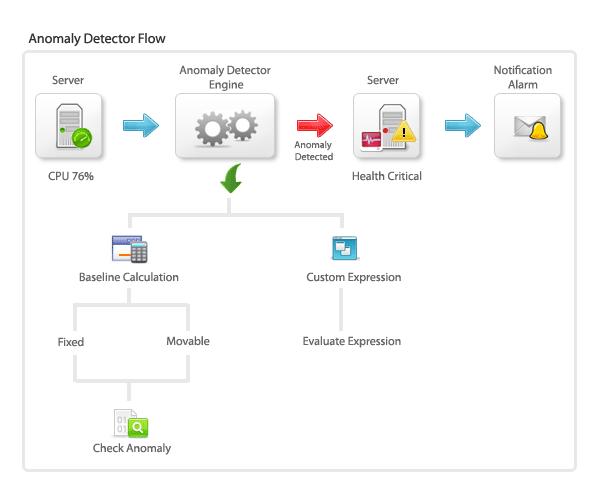
复杂系统里,很多故障不是 “突然发生” 的,而是 “慢慢恶化” 的 —— 比如内存泄漏是一点点涨起来的,数据库查询效率是逐渐变慢的。DevOps 监控就像 “运维预警雷达”,能抓出这些 “细微异常”:
- 内存使用率连续 10 分钟涨了 5%,马上告警;
- 某条数据库查询耗时从 50ms 升到 200ms,自动标记;
- 容器突然重启 2 次,立刻触发检查;
- API 响应时间突然从 300ms 飙到 1 秒,实时推送提醒。
有了这些预警,团队不用等用户投诉,就能在问题升级前解决。就像某电商团队用了监控后,发现某次大促前 API latency 有上涨趋势,提前扩容了服务器,避免了去年 “支付卡顿” 的悲剧。
2. 缩短 MTTD/MTTR:故障响应快一倍
做运维的都懂,故障处理的 “黄金时间” 就那几分钟。传统模式下,MTTD(平均检测时间)可能要 2 小时,MTTR(平均恢复时间)要 1.5 小时;但有了 DevOps 监控,这两个时间能砍半:
「MTTD 缩短」:不用人工轮询,监控系统实时盯数据,问题发生 5 分钟内就能告警;
「MTTR 缩短」:监控能自动关联数据 —— 比如发现 APP 卡顿,立刻显示是 “CDN 节点故障→导致静态资源加载慢”,不用再查日志、问开发,直接定位根源。
某金融客户用监控后,MTTR 从 120 分钟降到 15 分钟,一年少损失了近百万的停机成本。

3. 优化资源:不花 “冤枉钱”
很多企业的云资源利用率只有 30%-40%—— 有的服务器 CPU 常年低于 20%,有的容器闲置半个月,却一直在扣费。DevOps 监控能帮你 “摸清资源底细”:
识别 “闲置资源”:比如某台虚拟机 3 个月没跑核心服务,标记后回收;
自动扩缩容:流量高峰时自动加服务器,低谷时缩容,避免 “高峰不够用,低谷浪费”;
云实例 rightsizing:根据实际负载选合适的实例类型,不用再 “为了保险买高配”。
某制造业企业用监控优化后,服务器利用率从 35% 升到 65%,一年少花了 40 万云费用。
4. 稳住性能:守住 SLO 底线
现在用户对 “慢” 的容忍度越来越低 ——APP 加载超过 3 秒就会流失 40% 用户。DevOps 监控能帮你 “盯紧性能细节”:
慢查询优化:找出耗时超 1 秒的数据库查询,比如某条 SQL 没加索引,优化后响应快 10 倍;
代码回滚定位:新版本上线后性能下降,监控对比 “上线前后数据”,立刻发现是某段代码有问题;
SLO 跟踪:比如承诺 “支付服务可用性 99.99%”,监控实时计算达标率,快不达标时提前调整。
某外卖平台用监控后,APP 加载时间从 2.8 秒降到 1.2 秒,用户留存率涨了 8%。
5. 打破团队墙:开发运维不 “甩锅”
DevOps 的核心是 “协作”,但传统模式下,开发说 “运维没配好环境”,运维说 “开发代码有 bug”,吵半天没结果。DevOps 监控能提供 “统一数据视角”:
开发能看到 “代码部署后,API 延迟涨了多少”;
运维能看到 “服务器资源够不够,是不是开发部署的容器太多”;
测试能看到 “新版本的错误率有没有超阈值”。
数据说话,不用再靠 “猜” 和 “吵”,协作效率自然高。
6. 持续改进:让 DevOps 闭环转起来
DevOps 不是 “做完就完”,而是 “迭代优化”。监控能提供 “反馈数据”:
新版本上线后,对比 “旧版本” 的性能 —— 比如错误率从 0.5% 升到 1.2%,说明有问题,下次迭代要改;
新功能上线后,看 “用户行为”—— 比如某功能点击后加载慢,导致使用率低,优先优化;
把这些数据放进 “sprint 规划”,让开发知道 “下次该重点改什么”。
选对工具很关键!Applications Manager 帮你搞定 “全栈监控”
搞 DevOps 监控,最怕 “工具堆砌”—— 用 A 工具看服务器,B 工具看 APM,C 工具看日志,查个问题要切 3 个平台,反而更麻烦。而APM,就是为 “全栈监控” 设计的,能帮你 “一个工具搞定所有”。
它的核心优势,就是 “覆盖全、够智能、易协作”,正好解决前面说的所有痛点:
统一监控:一个控制台盯所有
不用再切换工具了!APM 能整合 “基础设施、APM、EUM、日志、CI/CD” 的所有数据,呈现在一个仪表盘上:
- 服务器监控:看 “服务器 CPU” 的同时,能看到 “关联的 API 响应时间”;
- 容器监控:查 “容器故障” 时,能直接调对应的 “应用日志”;
- 数据监控:开发、运维、测试都用同一个平台,数据不用再 “导出分享”。
某互联网客户说,用了之后 “不用再开 5 个浏览器标签页,效率高了一倍”。

2. 全栈可观测:从代码到云都能盯
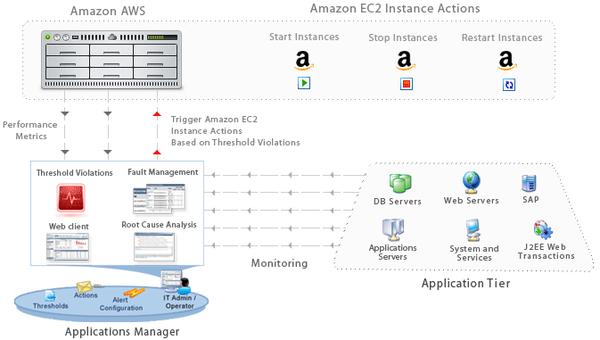
不管你是物理机、虚拟机,还是 Docker、K8s,不管是 AWS、Azure,还是自建数据库,APM 都能覆盖:
「APM 深度监控」:不只是看 API 延迟,还能到 “代码级”—— 比如某段 Java 代码耗时超久,定位到是 “循环逻辑有问题”;
「基础设施监控」:VM、容器、网络、磁盘的 CPU、内存、I/O 实时盯,比如 K8s 的 Pod 状态、节点资源;
「云监控」:支持 AWS、Azure、GCP,能看 “云服务性能”(比如 S3 存储响应时间),还能算 “云成本”,避免超预算;
「数据库监控」:MySQL、Oracle、MongoDB 都能盯,比如 “慢查询 TOP10”“缓存命中率”,优化数据库性能。

3. DevOps 专属:告警 + 自动化更省心
它不是 “冷冰冰的监控工具”,而是 “DevOps 协作伙伴”:
智能告警:不用设固定阈值,机器学习会分析 “历史数据”—— 比如大促时 CPU 峰值高,阈值会自动调,避免 “无效告警轰炸”;
自动化修复:比如 CPU 超 90% 时,自动重启服务;配置变更前,自动备份旧配置,不怕改崩;
Webhook 集成:能跟 Jenkins、Slack、企业微信联动 —— 比如 CI/CD 流水线失败,立刻发 Slack 告警;故障修复后,自动通知产品经理。

4. 部署后验证:新版本不 “掉链子”
新版本上线最怕 “性能崩”,APM 能帮你 “做验证”:
自动对比 “上线前后数据”:比如上线后错误率涨了 3 倍,立刻告警;
回滚触发:如果性能不达标,自动触发回滚,不用人工操作,避免影响用户。
某电商客户用这个功能后,新版本 “性能翻车” 的次数从一年 5 次降到 0 次。
5. 容器监控:云原生时代不慌
现在很多企业在推 K8s、Docker,容器监控是个难点。APM 能帮你 “盯紧容器细节”:
Kubernetes 监控:看集群健康度、Pod 状态、节点资源,比如某 Pod 频繁重启,立刻显示是 “内存不足”;
Docker 监控:跟踪容器从创建到终止的全生命周期,看 CPU、内存、网络 I/O,比如某容器磁盘满了,提前清理。

最后说句实在话:DevOps 监控不是 “成本”,是 “投资”
很多人觉得 “监控要花钱,能省则省”,但其实它是 “省钱的工具”:
短期:一年能省 30 万 + 的人力成本、云成本、停机成本;
长期:帮你建立 “主动运维” 体系,不用再被故障牵着走;
业务价值:性能稳了、用户体验好了,自然能带来更多收入。
APM 现在还能免费试用 30 天,全功能开放 —— 不管你是刚做 DevOps 的小团队,还是有混合云架构的大企业,都能用来搭起 “全栈监控体系”。
评论区聊聊:你在 DevOps 监控中遇到过最头疼的问题是什么?是工具太多还是告警太杂?一起交流解决方案~