定时器设计之->分级时间轮
定时器实现方法:
1 linux 操作系统timer api,适合小批量定时。
2 编程语言级timer,适合任务调度,50个以内的定时需求。
3 红黑树,适合10万个以上、多查询&&少变更(修改、abort、delete)的定时任务。 linux文件系统中大量使用红黑树。
4 时间轮:数据模型是环形双向链表,按照expires_time排序,可以精确定位到下一次闹钟时间。 适合200以内的精确定时任务。
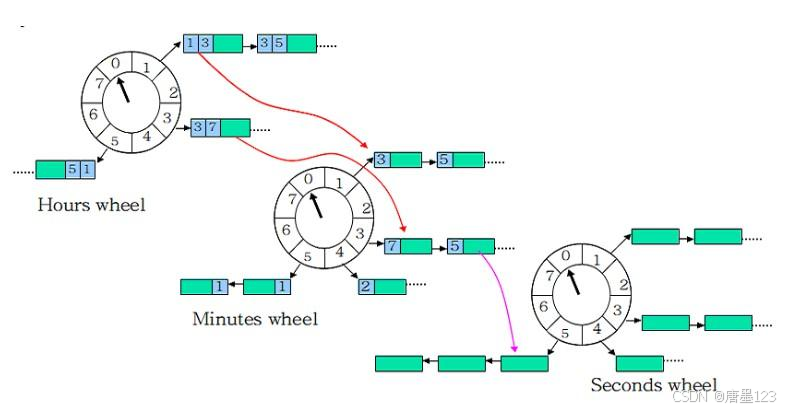
4 多级时间轮:适合1000~10w左右的设备,可以随时动态修改的场景。
分级时间轮模型:
每一级定时器轮对应一个哈希表
main.go bench源码:
package mainimport ("container/list""fmt""runtime""sync""time""github.com/shirou/gopsutil/v3/cpu""github.com/shirou/gopsutil/v3/mem"
)// Task 表示一个定时任务
type Task struct {ID string // 任务唯一标识delay time.Duration // 延迟时间callback func() // 任务回调函数aborted bool // 任务是否已取消abortChan chan struct{} // 取消信号通道
}// NewTask 创建一个新任务
func NewTask(id string, delay time.Duration, callback func()) *Task {return &Task{ID: id,delay: delay,callback: callback,abortChan: make(chan struct{}, 1),}
}// Abort 取消任务
func (t *Task) Abort() {if t.aborted {return}t.aborted = trueselect {case t.abortChan <- struct{}{}:default:}
}// TimeWheel 表示一个时间轮
type TimeWheel struct {level int // 层级 0:10ms, 1:min, 2:hour, 3:dayinterval time.Duration // 每个槽位的时间间隔slots []*list.List // 槽位,每个槽位是一个任务链表slotCount int // 槽位数量current int // 当前指针位置ticker *time.Ticker // 定时器mutex sync.Mutex // 互斥锁nextLevel *TimeWheel // 下一级时间轮quit chan struct{} // 退出信号
}// NewTimeWheel 创建一个新的时间轮
func NewTimeWheel(level int, interval time.Duration, slotCount int, nextLevel *TimeWheel) *TimeWheel {tw := &TimeWheel{level: level,interval: interval,slots: make([]*list.List, slotCount),slotCount: slotCount,current: 0,nextLevel: nextLevel,quit: make(chan struct{}),}// 初始化每个槽位的链表for i := range tw.slots {tw.slots[i] = list.New()}return tw
}// Start 启动时间轮
func (tw *TimeWheel) Start() {tw.ticker = time.NewTicker(tw.interval)go func() {for {select {case <-tw.ticker.C:tw.tick()case <-tw.quit:tw.ticker.Stop()return}}}()
}// Stop 停止时间轮
func (tw *TimeWheel) Stop() {close(tw.quit)
}// tick 处理时间轮的一次转动
func (tw *TimeWheel) tick() {tw.mutex.Lock()defer tw.mutex.Unlock()// 获取当前槽位的所有任务currentSlot := tw.slots[tw.current]for currentSlot.Len() > 0 {elem := currentSlot.Front()task := elem.Value.(*Task)currentSlot.Remove(elem)// 检查任务是否已取消if task.aborted {continue}// 如果有下一级时间轮,将任务迁移到下一级if tw.nextLevel != nil {// ********** 在此处添加时间调整代码 **********// 计算当前层级已消耗的时间(当前层级的 interval)elapsed := tw.interval// 计算剩余延迟时间(确保非负)remainingDelay := task.delay - elapsedif remainingDelay < 0 {remainingDelay = 0}// 创建新任务,携带剩余延迟时间newTask := &Task{ID: task.ID,delay: remainingDelay,callback: task.callback,aborted: task.aborted,abortChan: task.abortChan, // 共享取消通道}// 迁移新任务到下一级tw.nextLevel.AddTask(newTask)// ******************************************} else {// 没有下一级,执行任务go func(t *Task) {select {case <-t.abortChan:returndefault:t.callback()}}(task)}}// 移动指针tw.current = (tw.current + 1) % tw.slotCount
}// AddTask 添加任务到时间轮
func (tw *TimeWheel) AddTask(task *Task) {if task.aborted {return}tw.mutex.Lock()defer tw.mutex.Unlock()// 计算任务应该放在哪个槽位delayMs := int(task.delay / time.Millisecond)intervalMs := int(tw.interval / time.Millisecond)// 如果延迟时间小于当前时间轮的总范围,直接添加到当前时间轮if task.delay <= time.Duration(tw.slotCount)*tw.interval {slot := (tw.current + delayMs/intervalMs) % tw.slotCounttw.slots[slot].PushBack(task)return}// 否则添加到下一级时间轮if tw.nextLevel != nil {tw.nextLevel.AddTask(task)}
}// RemoveTask 从时间轮中移除任务
func (tw *TimeWheel) RemoveTask(taskID string) bool {tw.mutex.Lock()defer tw.mutex.Unlock()// 在当前时间轮的所有槽位中查找并移除任务for _, slot := range tw.slots {for elem := slot.Front(); elem != nil; elem = elem.Next() {task := elem.Value.(*Task)if task.ID == taskID {slot.Remove(elem)task.Abort()return true}}}// 如果有下一级时间轮,继续在那里查找if tw.nextLevel != nil {return tw.nextLevel.RemoveTask(taskID)}return false
}// 创建四级时间轮
func NewFourLevelTimeWheel() *TimeWheel {// 10ms级时间轮:10ms精度,100个槽位,覆盖1秒ms10Wheel := NewTimeWheel(0, 10*time.Millisecond, 100, nil)// 分钟级时间轮:1分钟精度,60个槽位,覆盖1小时minuteWheel := NewTimeWheel(1, time.Minute, 60, ms10Wheel)// 小时级时间轮:1小时精度,24个槽位,覆盖1天hourWheel := NewTimeWheel(2, time.Hour, 24, minuteWheel)// 天级时间轮:1天精度,31个槽位,覆盖31天dayWheel := NewTimeWheel(3, 24*time.Hour, 31, hourWheel)return dayWheel
}// 性能统计结构
type PerformanceStats struct {StartTime time.TimeEndTime time.TimeCPUUsage []float64MemoryUsageMB []float64GoRoutineCount []intMaxCPUUsage float64MaxMemoryUsage float64MaxGoRoutineCount intAvgCPUUsage float64AvgMemoryUsage float64AvgGoRoutineCount float64
}// 开始性能监控
func startPerformanceMonitoring(stats *PerformanceStats, stopChan chan struct{}) {stats.StartTime = time.Now()// 每100ms采集一次数据ticker := time.NewTicker(100 * time.Millisecond)defer ticker.Stop()for {select {case <-ticker.C:// 获取CPU使用率cpuPercent, err := cpu.Percent(0, false)if err == nil && len(cpuPercent) > 0 {stats.CPUUsage = append(stats.CPUUsage, cpuPercent[0])if cpuPercent[0] > stats.MaxCPUUsage {stats.MaxCPUUsage = cpuPercent[0]}}// 获取内存使用率memInfo, err := mem.VirtualMemory()if err == nil {memUsageMB := memInfo.Used / 1024 / 1024 // 转换为MBstats.MemoryUsageMB = append(stats.MemoryUsageMB, float64(memUsageMB))if float64(memUsageMB) > stats.MaxMemoryUsage {stats.MaxMemoryUsage = float64(memUsageMB)}}// 获取goroutine数量goroutineCount := runtime.NumGoroutine()stats.GoRoutineCount = append(stats.GoRoutineCount, goroutineCount)if goroutineCount > stats.MaxGoRoutineCount {stats.MaxGoRoutineCount = goroutineCount}case <-stopChan:// 计算平均值stats.EndTime = time.Now()if len(stats.CPUUsage) > 0 {var totalCPU float64for _, usage := range stats.CPUUsage {totalCPU += usage}stats.AvgCPUUsage = totalCPU / float64(len(stats.CPUUsage))}if len(stats.MemoryUsageMB) > 0 {var totalMem float64for _, usage := range stats.MemoryUsageMB {totalMem += usage}stats.AvgMemoryUsage = totalMem / float64(len(stats.MemoryUsageMB))}if len(stats.GoRoutineCount) > 0 {var totalGoroutine intfor _, count := range stats.GoRoutineCount {totalGoroutine += count}stats.AvgGoRoutineCount = float64(totalGoroutine) / float64(len(stats.GoRoutineCount))}return}}
}// 打印性能统计结果
func printPerformanceStats(stats *PerformanceStats) {fmt.Println("\n===== 性能统计结果 =====")fmt.Printf("测试时长: %v\n", stats.EndTime.Sub(stats.StartTime))fmt.Printf("CPU使用率 - 平均: %.2f%%, 最高: %.2f%%\n", stats.AvgCPUUsage, stats.MaxCPUUsage)fmt.Printf("内存使用 - 平均: %.2f MB, 最高: %.2f MB\n", stats.AvgMemoryUsage, stats.MaxMemoryUsage)fmt.Printf("Goroutine数量 - 平均: %.2f, 最高: %d\n", stats.AvgGoRoutineCount, stats.MaxGoRoutineCount)fmt.Println("========================")
}// 压力测试函数
func stressTest() {// 创建四级时间轮tw := NewFourLevelTimeWheel()tw.Start()defer tw.Stop()const taskCount = 50000tasks := make([]*Task, taskCount)startTime := time.Now()// 初始化性能统计stats := &PerformanceStats{}stopChan := make(chan struct{})go startPerformanceMonitoring(stats, stopChan)// 添加20000个任务,时间进行缩放(实际时间 = 指定时间 / 1000)fmt.Printf("添加 %d 个任务...\n", taskCount)for i := 0; i < taskCount; i++ {// 任务延迟在0-10秒之间均匀分布delay := time.Duration(i%1000) * time.Millisecond * 10taskID := fmt.Sprintf("task-%d", i)// 每100个任务中取消一个,测试abort功能if i%100 == 0 {tasks[i] = NewTask(taskID, delay, func() {// 被取消的任务不应该执行fmt.Printf("错误: 已取消的任务 %s 被执行了\n", taskID)})tw.AddTask(tasks[i])tasks[i].Abort() // 立即取消} else {tasks[i] = NewTask(taskID, delay, func() {// 正常任务执行,不输出日志以避免影响性能测试})tw.AddTask(tasks[i])}}addTime := time.Since(startTime)fmt.Printf("添加 %d 个任务耗时: %v\n", taskCount, addTime)fmt.Println("等待所有任务执行完成...")// 等待最长任务执行完成(10秒)time.Sleep(15 * time.Second)// 停止性能监控并打印结果close(stopChan)time.Sleep(100 * time.Millisecond) // 等待监控线程完成printPerformanceStats(stats)// 统计任务处理时间totalTime := time.Since(startTime)fmt.Printf("总耗时: %v\n", totalTime)fmt.Printf("平均每个任务处理时间: %v\n", totalTime/time.Duration(taskCount))
}func main() {// 打印初始系统信息fmt.Printf("初始Goroutine数量: %d\n", runtime.NumGoroutine())fmt.Printf("CPU核心数量: %d\n", runtime.NumCPU())memInfo, _ := mem.VirtualMemory()fmt.Printf("初始内存使用: %.2f MB\n", float64(memInfo.Used)/1024/1024)stressTest()
}
golang demo测试结果:
root@iZwz99zhkxxl5h6ecbm2xwZ:~/work/timer-loop-golang# go mod init tt
root@iZwz99zhkxxl5h6ecbm2xwZ:~/work/timer-loop-golang# go build
root@iZwz99zhkxxl5h6ecbm2xwZ:~/work/timer-loop-golang# ./tt
初始Goroutine数量: 1
CPU核心数量: 2
初始内存使用: 552.64 MB
添加 50000 个任务...
添加 50000 个任务耗时: 30.635781ms
等待所有任务执行完成...===== 性能统计结果 =====
测试时长: 15.030804421s
CPU使用率 - 平均: 1.42%, 最高: 23.81%
内存使用 - 平均: 519.15 MB, 最高: 552.00 MB
Goroutine数量 - 平均: 3.00, 最高: 3
========================
总耗时: 15.13130464s
平均每个任务处理时间: 302.626µs
root@iZwz99zhkxxl5h6ecbm2xwZ:~/work/timer-loop-golang#
main.py
import time
import threading
import queue
import psutil
import os
from collections import deque
from dataclasses import dataclass
from typing import Callable, List, Dict, Optional@dataclass
class Task:task_id: strdelay: float # 延迟时间,单位:秒callback: Callable[[], None]aborted: bool = Falseabort_event: threading.Event = threading.Event()def abort(self):self.aborted = Trueself.abort_event.set()class TimeWheel:def __init__(self, level: int, interval: float, slot_count: int, next_level: Optional['TimeWheel'] = None):self.level = levelself.interval = interval # 每个槽位的时间间隔,单位:秒self.slot_count = slot_countself.slots = [deque() for _ in range(slot_count)]self.current = 0self.next_level = next_levelself.running = Falseself.thread = Noneself.lock = threading.Lock()self.quit_event = threading.Event()def start(self):self.running = Trueself.thread = threading.Thread(target=self._run, daemon=True)self.thread.start()def stop(self):self.running = Falseself.quit_event.set()if self.thread:self.thread.join()# 递归停止下一级时间轮if self.next_level:self.next_level.stop()def _run(self):while self.running:# 等待一个时间间隔或退出信号start_time = time.time()self.quit_event.wait(self.interval)if not self.running:breakwith self.lock:# 处理当前槽位的所有任务current_slot = self.slots[self.current]while current_slot:task = current_slot.popleft()if task.aborted:continue# 如果有下一级时间轮,迁移任务if self.next_level:self.next_level.add_task(task)else:# 没有下一级,执行任务threading.Thread(target=self._execute_task, args=(task,), daemon=True).start()# 移动指针self.current = (self.current + 1) % self.slot_countdef _execute_task(self, task: Task):# 检查任务是否已取消if task.aborted:return# 等待任务延迟时间(仅适用于最底层时间轮)if not task.abort_event.wait(task.delay):task.callback()def add_task(self, task: Task):if task.aborted:returnwith self.lock:total_range = self.interval * self.slot_count# 如果延迟时间小于当前时间轮的总范围,直接添加if task.delay <= total_range:slot = int((self.current + task.delay / self.interval) % self.slot_count)self.slots[slot].append(task)else:# 否则添加到上一级时间轮if self.next_level:# 调整延迟时间,只保留上一级时间轮需要的部分adjusted_task = Task(task_id=task.task_id,delay=task.delay,callback=task.callback)adjusted_task.abort_event = task.abort_eventadjusted_task.aborted = task.abortedself.next_level.add_task(adjusted_task)def remove_task(self, task_id: str) -> bool:with self.lock:# 在当前时间轮查找并移除任务for slot in self.slots:for i in range(len(slot)):if slot[i].task_id == task_id:task = slot.pop(i)task.abort()return True# 递归查找下一级时间轮if self.next_level:return self.next_level.remove_task(task_id)return Falsedef create_four_level_timewheel() -> TimeWheel:# 10ms级时间轮:0.01秒精度,100个槽位,覆盖1秒ms10_wheel = TimeWheel(0, 0.01, 100, None)# 分钟级时间轮:60秒精度,60个槽位,覆盖1小时minute_wheel = TimeWheel(1, 60, 60, ms10_wheel)# 小时级时间轮:3600秒精度,24个槽位,覆盖1天hour_wheel = TimeWheel(2, 3600, 24, minute_wheel)# 天级时间轮:86400秒精度,31个槽位,覆盖31天day_wheel = TimeWheel(3, 86400, 31, hour_wheel)return day_wheelclass PerformanceMonitor:def __init__(self):self.start_time = Noneself.end_time = Noneself.cpu_usage = []self.memory_usage = []self.thread_count = []self.monitor_thread = Noneself.running = Falseself.process = psutil.Process(os.getpid())def start(self):self.start_time = time.time()self.running = Trueself.monitor_thread = threading.Thread(target=self._monitor, daemon=True)self.monitor_thread.start()def _monitor(self):while self.running:# 记录CPU使用率self.cpu_usage.append(self.process.cpu_percent(interval=0.1))# 记录内存使用(MB)mem_info = self.process.memory_info()self.memory_usage.append(mem_info.rss / (1024 * 1024))# 记录线程数量self.thread_count.append(len(self.process.threads()))time.sleep(0.1)def stop(self):self.running = Falseself.end_time = time.time()if self.monitor_thread:self.monitor_thread.join()def get_stats(self):if not self.cpu_usage or not self.memory_usage:return {}# 计算统计数据avg_cpu = sum(self.cpu_usage) / len(self.cpu_usage)max_cpu = max(self.cpu_usage)avg_memory = sum(self.memory_usage) / len(self.memory_usage)max_memory = max(self.memory_usage)avg_threads = sum(self.thread_count) / len(self.thread_count)max_threads = max(self.thread_count)duration = self.end_time - self.start_timereturn {"duration": duration,"avg_cpu": avg_cpu,"max_cpu": max_cpu,"avg_memory": avg_memory,"max_memory": max_memory,"avg_threads": avg_threads,"max_threads": max_threads}def stress_test():# 创建四级时间轮timewheel = create_four_level_timewheel()timewheel.start()# 初始化性能监控monitor = PerformanceMonitor()monitor.start()task_count = 50000tasks = []start_time = time.time()print(f"添加 {task_count} 个任务...")for i in range(task_count):# 任务延迟在0-10秒之间(实际时间缩放)delay = (i % 1000) * 0.01 # 0-10秒task_id = f"task-{i}"# 每100个任务中取消一个if i % 100 == 0:def create_callback(tid):def callback():print(f"错误: 已取消的任务 {tid} 被执行了")return callbacktask = Task(task_id, delay, create_callback(task_id))tasks.append(task)timewheel.add_task(task)task.abort() # 立即取消else:def create_callback(tid):def callback():# 正常任务执行,不输出日志passreturn callbacktask = Task(task_id, delay, create_callback(task_id))tasks.append(task)timewheel.add_task(task)add_time = time.time() - start_timeprint(f"添加 {task_count} 个任务耗时: {add_time:.2f} 秒")print("等待所有任务执行完成...")# 等待最长任务执行完成time.sleep(15)# 停止监控和时间轮monitor.stop()timewheel.stop()# 打印性能统计stats = monitor.get_stats()print("\n===== 性能统计结果 =====")print(f"测试时长: {stats['duration']:.2f} 秒")print(f"CPU使用率 - 平均: {stats['avg_cpu']:.2f}%, 最高: {stats['max_cpu']:.2f}%")print(f"内存使用 - 平均: {stats['avg_memory']:.2f} MB, 最高: {stats['max_memory']:.2f} MB")print(f"线程数量 - 平均: {stats['avg_threads']:.2f}, 最高: {stats['max_threads']}")print("========================")total_time = time.time() - start_timeprint(f"总耗时: {total_time:.2f} 秒")print(f"平均每个任务处理时间: {total_time / task_count * 1000:.2f} 毫秒")if __name__ == "__main__":# 打印初始系统信息process = psutil.Process(os.getpid())print(f"初始线程数量: {len(process.threads())}")print(f"CPU核心数量: {psutil.cpu_count(logical=False)}")mem_info = process.memory_info()print(f"初始内存使用: {mem_info.rss / (1024 * 1024):.2f} MB")stress_test()
python demo测试结果:
root@iZwz99zhkxxl5h6ecbm2xwZ:~/work/timer-loop-py# python3 main.py
初始线程数量: 1
CPU核心数量: 1
初始内存使用: 14.01 MB
添加 50000 个任务...
添加 50000 个任务耗时: 0.13 秒
等待所有任务执行完成...===== 性能统计结果 =====
测试时长: 15.15 秒
CPU使用率 - 平均: 1.68%, 最高: 107.50%
内存使用 - 平均: 34.16 MB, 最高: 34.16 MB
线程数量 - 平均: 3.00, 最高: 3
========================
总耗时: 15.29 秒
平均每个任务处理时间: 0.31 毫秒
root@iZwz99zhkxxl5h6ecbm2xwZ:~/work/timer-loop-py#