HarvardX TinyML小笔记2(番外3:数据工程)
课程链接:Course | edX
数据工程其实就是做数据集,这东西没有太多技术含量,但是可以说是决定ML成败的关键一环。毕竟有80%的时间耗费都是在高质量的数据集上。
数据决定模型上限,算法与工程仅决定逼近上限的程度。
整体步骤大概就是确定需求,收集,提炼,维持。流程倒是不难理解,首先明确需要什么样的数据集,然后用多种方式去收集,之后对数据处理验证,最后保管数据。
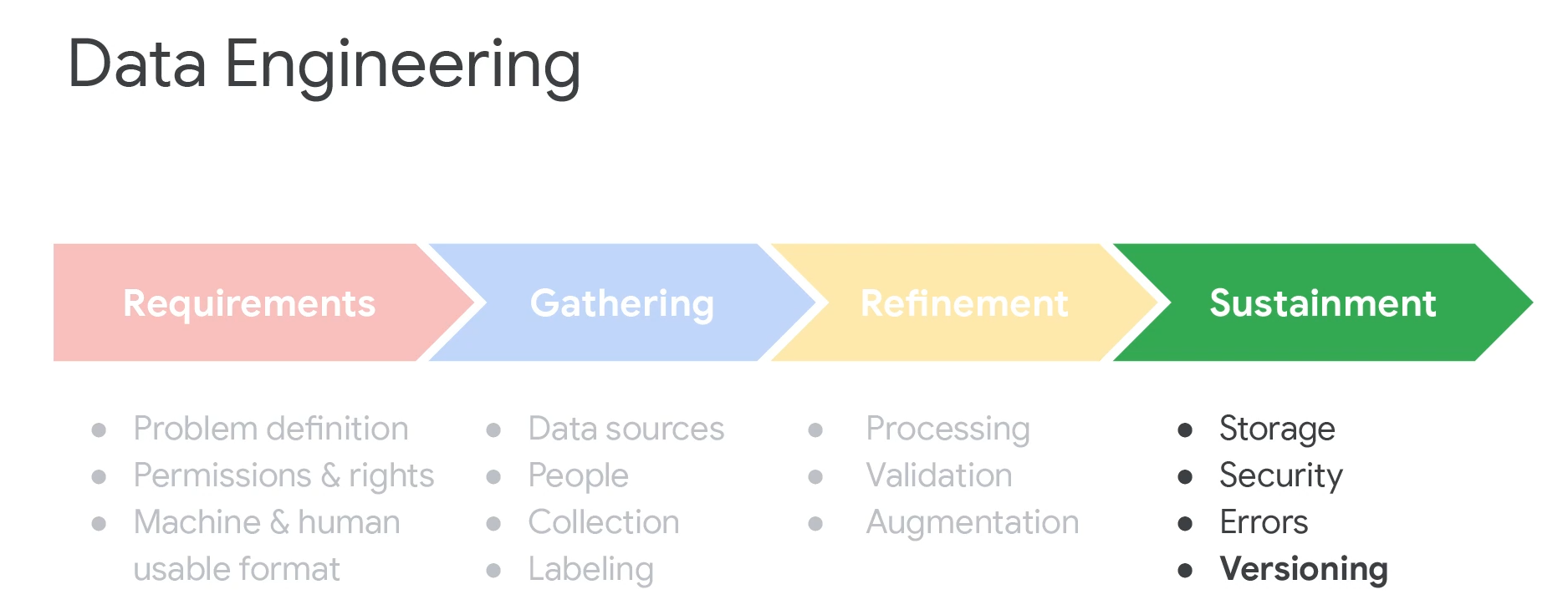

收集数据集的时候要注意开源协议,分析能不能使用。

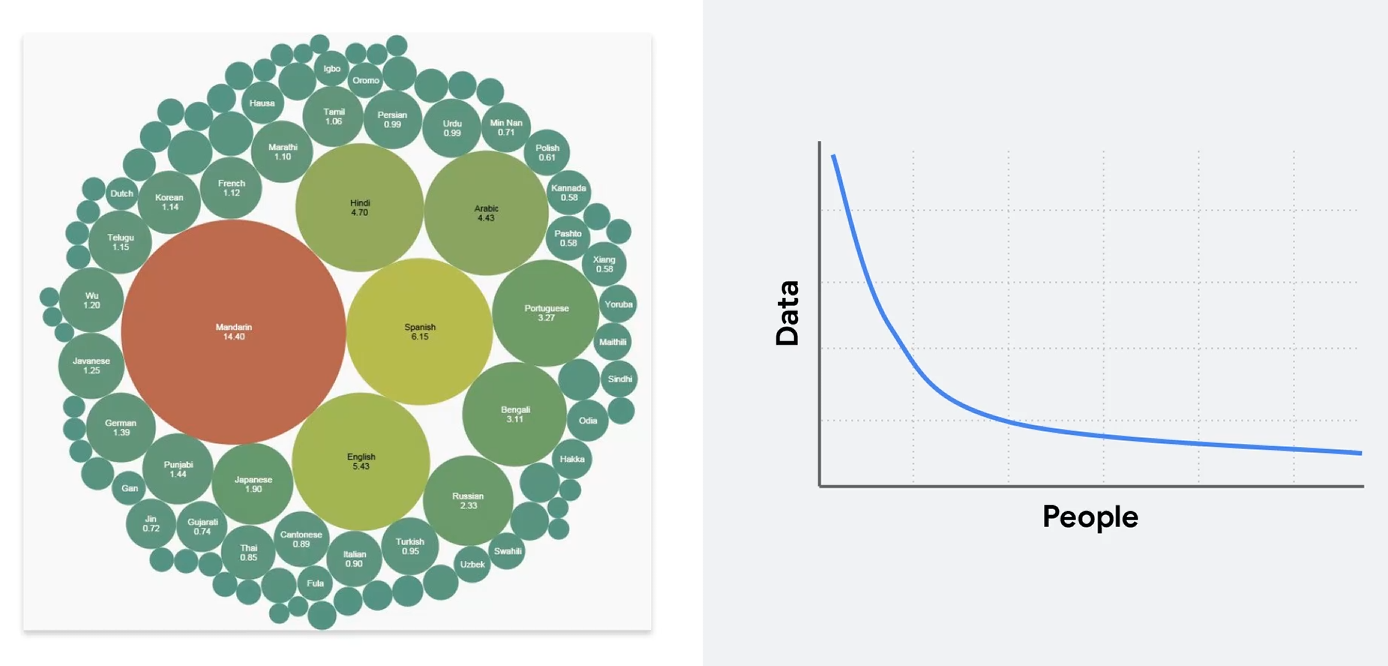
数据来源的四种方式:传感器,众包,产品用户,付费用户。

总之好数据集的创建很麻烦。。。

列了几个可以直接用的数据集,Common Voice,COCO,ImageNet等等。后面有机会再看吧。

简单介绍了一下Google的Speech Commands。
Speech Commands
https://arxiv.org/pdf/1804.03209.pdf
- What are Speech Commands?
- What was People’s motivation behind building Speech Commands?
- How is Keyword Spotting different from traditional speech recognition models?
- What are the important metrics in speech recognition for KWS?
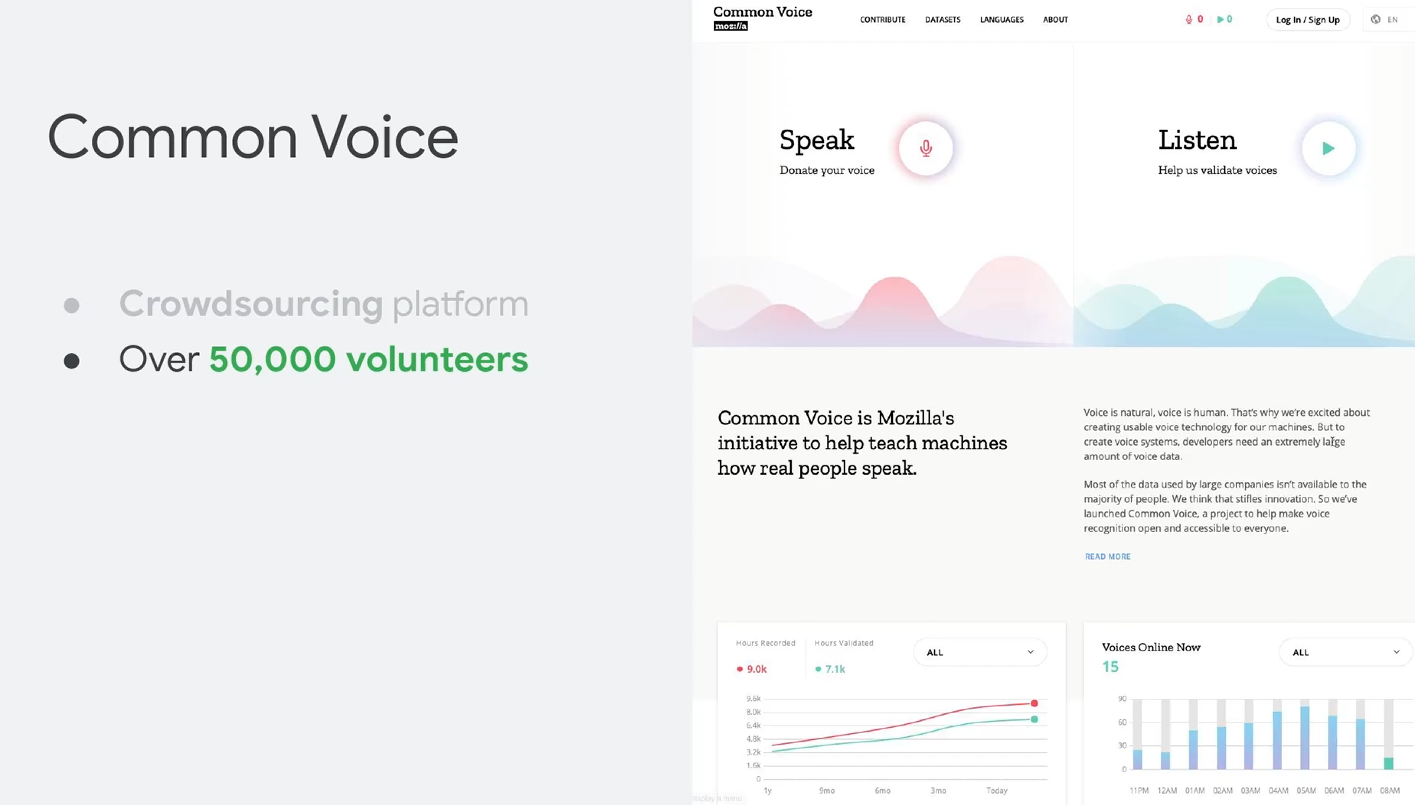
之后介绍了一个Web的语音收集平台,Common Voice,都是白嫖很多自愿者。。。
主页:https://commonvoice.mozilla.org/
然后说了下如何复用已有的数据集。

最后还是老生常谈的数码平权,消除偏见。有一说一,不管实际如何,起码美国的学校对这方面还是很重视的。确实未来AI时代,一些细小的偏见都可能对人类社会带来深远影响。
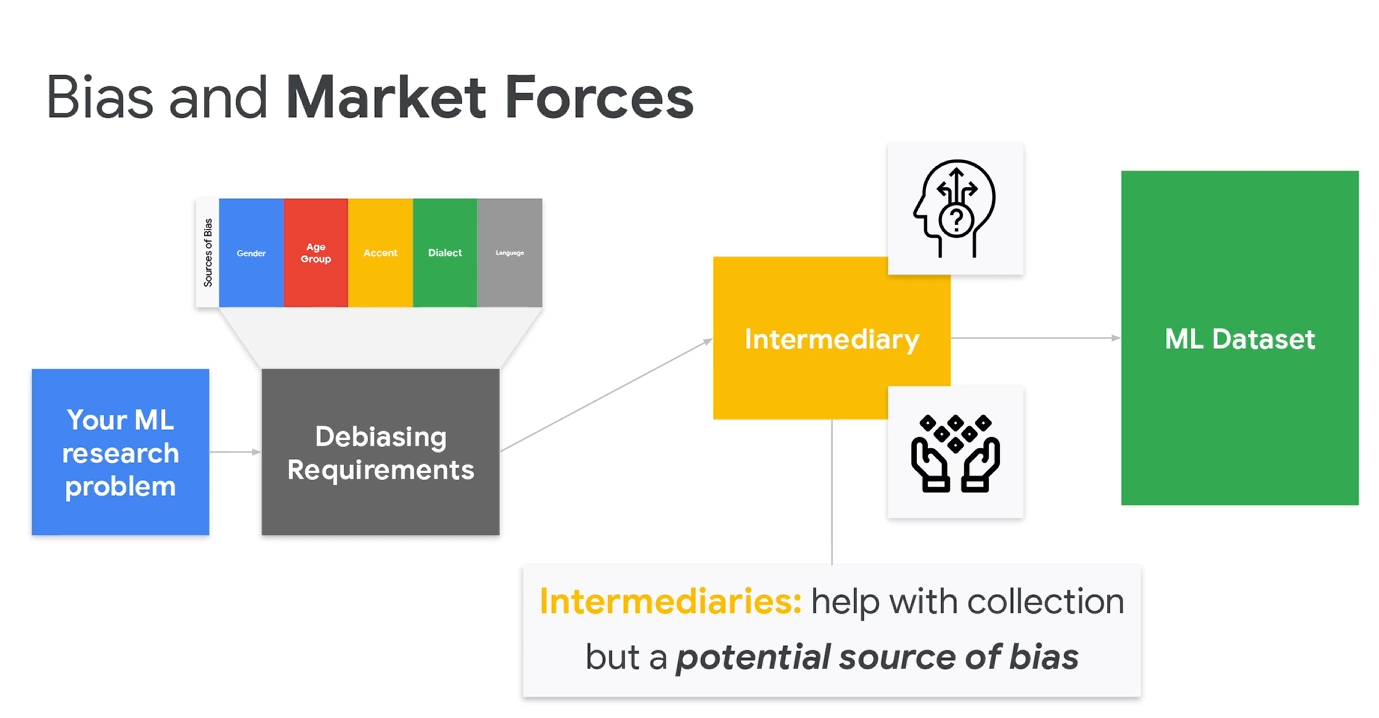

最后还是说明,如果数据集选的不好,就算在程序中训练的准确率再高,程序可能也有问题。
So just because your Colab says you've got a certain accuracy does not mean that it's actually doing its job well from a TinyML application standpoint.
最后的总结,其实看这一篇就够了:Course | edX