从零到一,在GitHub上构建你的专属知识大脑:一个模块化RAG系统的开源实现
大家好!
如果你一直关注 AI 领域,一定听说过检索增强生成(Retrieval-Augmented Generation,RAG)。它的理念简单却强大:与其让大语言模型只靠“脑内”静态知识,不如直接给它你的文档,让它基于真实材料回答提问。
用 LangChain 或 LlamaIndex 几行代码就能跑一个 RAG 小 demo,但真正落地到企业场景——面对杂乱 PDF、刁钻提问、极高准确率要求——我才发现“朴素实现”根本不够看。
于是我决定从零搭建一套真正鲁棒、可投产的企业级 RAG 系统。我不想再做玩具,而是要做一把知识发现的“瑞士军刀”。今天,我就带你拆解它的架构、关键决策及其背后的原因。
完整项目已开源,开箱即用:
RAG_Mini
“朴素 RAG” 的三大硬伤
朴素 RAG 通常长这样:
- 加载文档
- 无脑按 1000 字符切块
- 向量化后扔进向量库
- 按向量相似度取 top-k
- 把 chunk 塞进 prompt 让 LLM 回答
简单场景还凑合,一旦进到企业环境,立马露馅:
- 硬切块破坏上下文
1000 字符一刀切,可能把关键定义或表格拦腰斩断,语义全毁。 - 纯向量搜索并非万能
产品代号、缩写、精确关键词,向量空间不一定能捕捉。 - “Lost in the Middle” 现象
一次塞给模型几十段文本,真正重要的信息反而被淹没,导致幻觉。
我的解法:多阶段、精准导向的架构
后端是模块化 Python,前端是清爽的 Gradio UI。真正的魔法在数据管道:
加载 → 分层语义拆分 → 混合索引 → 检索 → 重排序 → 生成
1. 更聪明的数据切块:分层语义拆分
我实现了一个两层 HierarchicalSemanticSplitter:
- 父块(Parent Chunks):先按语义边界(如段落
\n\n)切成较大的重叠块(约 800 token),保留完整章节语境。 - 子块(Child Chunks):再把每个父块切成更小粒度(约 250 token)。
为什么有效?
子块负责精准匹配,被嵌入并用于首轮检索;找到最佳子块后,再拉回其对应的父块作为 LLM 的完整上下文。既保证搜索精度,又保证语境丰富。
2. 不把鸡蛋放一个篮子:混合搜索
语义搜索很香,但不是银弹。我搞了套混合检索:
- 稠密检索(FAISS):理解查询含义,适合“我们上季度主要成果是什么”这类开放问题。
- 稀疏检索(BM25):经典关键词搜索,擅长抓“Project Phoenix”、“AX-2025” 这类精确词。
HybridVectorStore 并行跑两条检索,再用加权分数(alpha)融合结果。无论用户问“什么意思”还是“给我某编号的表格”,系统都能稳稳命中。
3. 去伪存真:重排序(Reranker)
混合搜索给出 20 来个候选父块,但谁才是最 relevant 的?我加了一道重排序:
用 Cross-Encoder 模型对“查询+文档”成对打分。不同于首轮双塔式编码,Cross-Encoder 同时看查询和全文,能做更深度的相关性判断。
这一步计算量大,但效果炸裂:充当最后质量闸口,把噪声挡在门外,显著降低幻觉、提升答案准确度。
4. 拒绝漫长等待:打字机般的流式输出
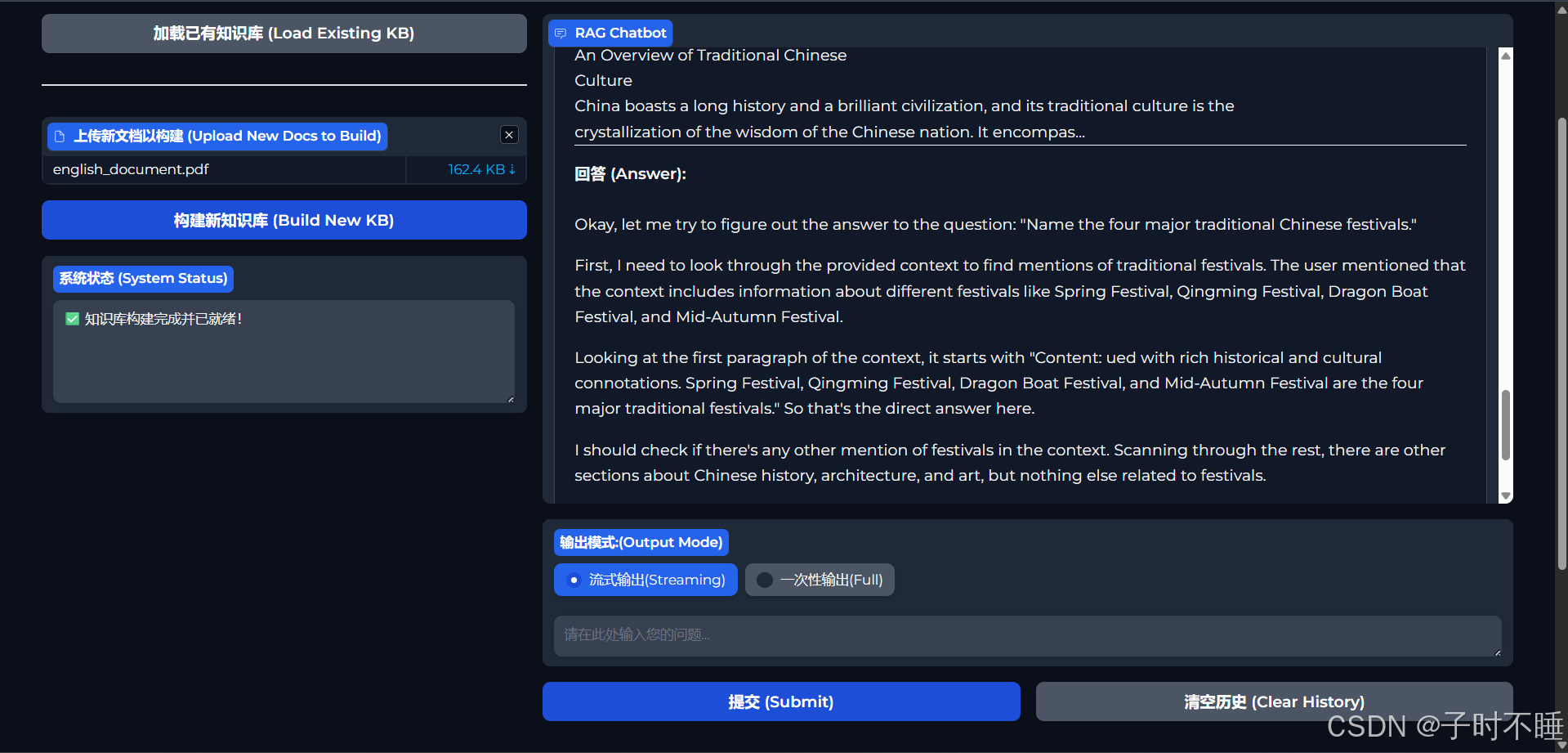
一个好的交互体验至关重要。没有什么比点击“发送”后,盯着一个旋转的加载图标长达10秒更糟糕的了。本项目深度集成了流式输出(Streaming)功能。当你提问后,答案会像打字机一样逐字或逐词地呈现在你面前,极大地降低了等待焦虑,让交互变得流畅自然。
一个用户友好的界面,把上述能力打包上桌
所有后端逻辑通过 Gradio 提供服务:
- 新建知识库:上传 PDF / TXT,实时进度条显示处理与索引过程。
- 加载已有知识库:索引落盘,秒级加载,直接开聊。
- 流式回答:LLM token-by-token 回传,打字机效果肉眼可见。
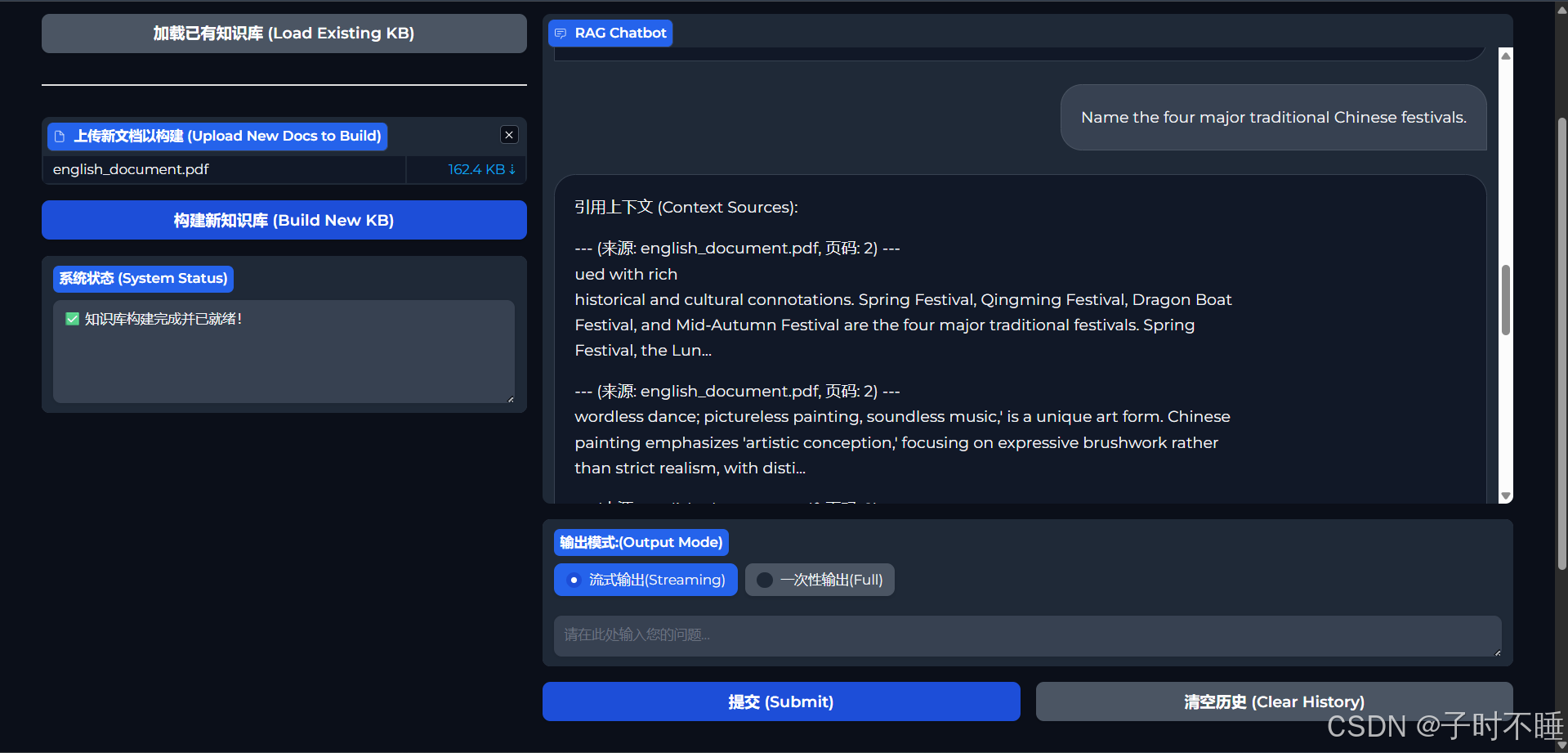
- 来源透明:每个答案都附带完整原文,用户一键核验。
立即上手!
如果你想从玩具 demo 进阶到能扛企业级需求的系统,这份开源项目就是最佳蓝图。代码干净、模块化,README 也写了保姆级教程。
🚀 GitHub 仓库: RAG_Mini和Tiny_RAG
欢迎试用!遇到问题直接提 issue,有新点子也欢迎 PR。如果觉得有用,记得给个 ⭐!
感谢阅读,祝你玩得开心,码得尽兴!