AI 云驱动产业智能化跃迁
本文整理自 2025 年 8 月 28 日百度云智大会 - 技术与产品主论坛,百度集团副总裁侯震宇的主题演讲《 AI 云驱动产业智能化跃迁》。
8 月 28 日沈抖博士的《智能,生成无限可能》主题演讲为我们分享了智能体经济的崛起,发布了新一代 AI 云基础设施,包括百舸 5.0、千帆 4.0 等新产品,也介绍了 AI Agents 在千行百业成功落地的案例,相信大家对我们正在进入的智能时代也都充满着期待。
在本次的技术与产品主论坛,我们将进一步分享百度智能云如何帮助大家打通大模型技术到商业落地的最后一公里,把握住智能时代的机遇。
AI 产业的发展离不开底层 AI 基础设施的支撑,同时也对其提出了更高的要求,AI 基础设施也在持续进化。接下来我将分享一下 AI 云如何释放大模型价值、如何驱动千行百业实现产业智能化跃迁。
过去 3 年,我们见证了人工智能的快速发展,从最初的模型探索,到如今与各行业、应用场景的深度融合,大模型正处在一个临界点,即将迎来价值的全面释放。
在应用层面,我们看到 AI 正在经历一次角色的跃迁。之前,大模型更多是Copilot,以对话的交流方式辅助人类完成工作;而现在,它在向真正的 AI Agent 进化,将具备自主决策能力,能够高质量完成复杂任务。这极大地拓展了 AI 的应用边界和价值。
在训练范式上,我们看到后训练方法中强化学习正在兴起,占据越来越重要的角色。它不仅提升了模型的交互效果和推理能力,也让 AI 更好地贴合实际使用场景。
在模型结构方面,主流基础大模型也从稠密模型,演进到 MoE 稀疏模型。稀疏化架构显著的提升了智能密度、效率和性价比,为 AI 更大的规模化应用奠定了基础。
这种转变背后有三大趋势:
第一,从训练主导到应用深化。未来 AI 应用和推理需求将超过训练,AI 真正的价值释放来自于应用。
第二,从快速响应到深度思考。大模型从面向对话交流的快速响应需求中脱离出来,更复杂的任务、更长的上下文和更深刻的用户理解,要求深度思考成为大模型必备的能力,以及衡量效果的标准。
第三,从规模为王到效能优先。随着 Transformer 架构的规模边际效用下降,AI 基础设施正从追求更大的规模转变为追求更好的效率和效果,提高算力效能的种种技术正在加速创新,成为新的竞争焦点。
总的来说,大模型正从聊天陪伴走向解决各类场景需求的应用,我们正站在价值爆发的前夜,谁能把握住 AI 应用的最佳实践和基础设施效能优化的机遇,谁就能在未来 AI 的新格局中脱颖而出。

面对应用深化、强化学习兴起和 MoE 稀疏化的趋势变化,如何真正释放大模型的潜力和价值成为关键问题。
我们认为当前时代 AI 价值的关键词是:Al Agents、开源、多模态、效价比、重构、场景落地、自主可控。为了更好的支撑这些关键要素,百度百舸 AI 计算平台 5.0 从算力、训推和应用层面做了系统性的迭代升级:
从芯片、超节点到 AIDC 全面的自主可控算力。
针对强化学习、MoE 等训推新范式的加速器。
直面产业场景的数据工程、领域模型适配、全链路加速。
百舸 5.0 为 AI 落地提供了全栈式支撑,致力于让 AI 深入每一个产业场景,实现真正的价值落地。

下面我将具体介绍百舸 5.0 在上述方向的重点工作和取得的一些成绩。在算力层面,昆仑芯 P800 和算力超节点是扎实的基础。
先谈谈国产芯,相信很多人都对国产芯在大模型下,能不能大规模跑得动、用起来方不方便、以及成本能否降下来抱有疑问。
我很高兴的告诉大家,百度昆仑芯 P800 已经完成了大规模集群的实践验证,我们在国内率先实现了自研 3.2 万卡集群的点亮和规模化应用,有效训练效率超过 98%。这意味着客户可以用国产芯以更低的成本和更短的研发周期,提供更快、更好、更省的模型。
其次是推理加速。P800 通过架构创新,让单卡的吞吐能力提升了 4 倍,并把百万 tokens 的推理成本降到了几块钱。这对高并发的场景来说,意味着跑得快、跑得稳、跑得起。
最后,在生态易用方面,P800 广泛兼容国内外主流的大模型、框架和算子库,大幅降低了额外的适配成本。
以上研发成果在众多行业客户的实际业务中完成了应用落地和价值验证。

正如之前所提到的,发展万亿参数规模的 MoE 模型已经成为了行业普遍趋势,MoE 模型在训练、微调乃至大规模并行推理方面,对底层算力极致吞吐产生了更高的要求。我们针对性的推出了昆仑芯超节点,让每一份算力都发挥到极致。
从这张图上可以看到,昆仑芯超节点是全栈自研的创新型高密度节点实例,大幅提升了单位机柜的算力密度和推理吞吐。对客户而言,这意味着更快的推理响应、更低的能耗占比,真正做到同样的算力投资,带来更高的业务产出。
此外,通信往往成为大模型训练和推理的瓶颈,而昆仑芯超节点通过百度自研技术实现了节点间高带宽、低时延的全互联通信。这成为 MoE 模型训练、推理真正的加速器。
在对算力的极致追求中,稳定性特别关键,昆仑超节点还提供全域智能运维。客户不用被运维拖累,可以把主要精力放在模型创新和 AI 应用落地上。

目前 AI 算力的应用主要还是集中在训练和推理两个大的场景上,这两个场景都呈现出新的发展特点。强化学习对模型能力跃迁至关重要,PD 分离式推理也正成为新一代计算范式的核心。
面对这一趋势,百度百舸致力于为客户提供领先的强化学习框架和高性能 PD 推理组件——包括智能调度系统、推理加速引擎和分布式 KV Cache 服务等,帮助大家在 AI 加速的新时代中保持竞争力。
在强化学习框架中,我们通过系统级协同设计,实现了各个模块的无缝配合、全程高吞吐运行,可支持 30,000+ 并发沙箱环境,极大加快了迭代和实验效率。同时,依托百度百舸 AIAK 训推加速技术,系统吞吐提升了 2 到 9 倍,显著加速了大模型和智能体的进化过程。
在推理服务方面,我们重新设计了调度系统、加速引擎与 KVCache 系统,在万卡集群规模上实现了吞吐大幅提升与首 Token 延迟显著下降。
调度系统通过「资源 - 流量 - 模型」三级协调调度,达成了集群全局的极致均衡。
推理引擎针对各类应用场景优化实现了吞吐最大化,并借助混合并行策略有效优化了不同长度请求的响应延迟。同时,我们将通信与调度开销隐藏在计算过程中,充分释放 GPU 计算效能。
分布式 KV Cache 实时感知集群全局状态,实现缓存智能管理。通过高速传输技术支持不同节点内及节点间的数据传输,并结合异步调度机制,实现了 Prefill 与 Decode 阶段间 KV Cache 的高效流动,让计算和存储精准协同,杜绝冗余计算,快速生成内容。
最终,在万卡集群中, 系统吞吐提升 50%,TTFT 降低至 0.5 秒。

AI 云基础设施的持续进化,最终还是要能更好地支撑上层应用场景。接下来,我们聚焦一个能让 AI 真正走出屏幕、进入物理世界的关键场景——具身智能。作为 Physical AI 落地的核心赛道,具身智能此时正处于「百舸争流时刻」:谁能最快搭建模型、最快验证仿真、最快完成落地,谁就能抢占先机。
百度百舸正好契合这种「快」的需求,我们提供行业领先的模型加速能力、一站式全链路服务,以及开箱即用的全栈工具链,让客户在竞速中抢占先机。
目前,百度百舸已经服务了包括北京人形等一批具身智能先锋企业,正和客户一起加速将一个个具身智能产品推向市场。
百度希望与更多具身智能企业和生态伙伴一起,共同驱动 AI 真正走进物理世界,共同迎接 Physical AI 时代的到来。

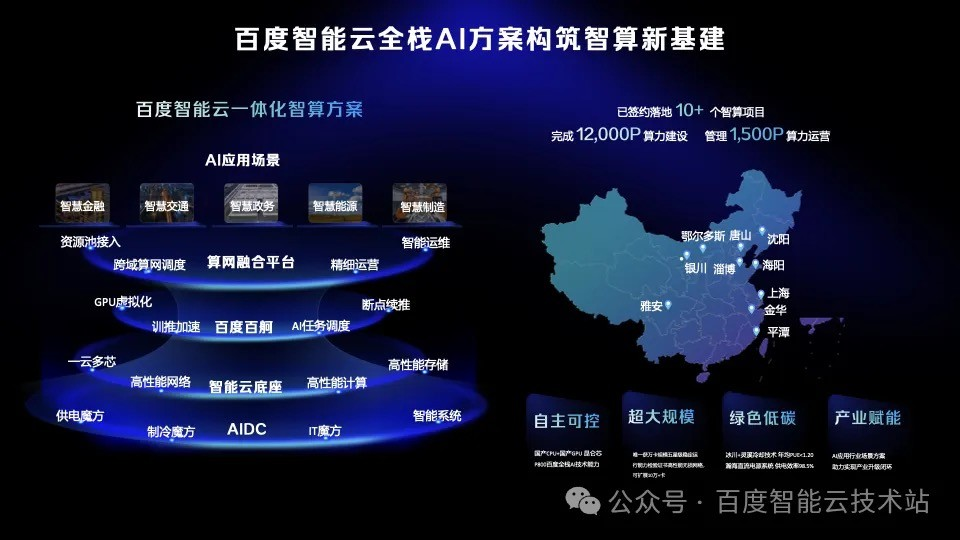
具身智能只是众多应用场景之一,为了更好支持 AI 走进各行各业,百度也提供一整套高度通用的全栈 AI 智算方案,以支撑不同场景的需求。我们的方案有四大特点:自主可控、超大规模、绿色低碳和产业赋能。
目前,我们建管运一体化方案已经在全国落地多个智算中心项目,完成了 12,000P 算力建设,并实现管理运营 1,500P 算力,在 IDC 智算专业服务市场中排名全国第二。
历史的车轮,总是沿着技术的轨道滚滚向前。我们曾见证蒸汽时代的力量,电气时代的光明,信息时代的互联。而今天,我们正站在一个更为波澜壮阔的历史起点上——智能时代,它已不再是未来的序曲,而是当下正在发生的、势不可挡的主旋律!
它正以超越想象的速度,重塑着我们熟悉的每一个产业,每一条赛道,每一种可能。
前路浩荡,万物智能。在这条充满光荣与梦想的征途上,百度智能云愿做大家最值得信赖的同行者。我们将以领先的技术、开放的平台、融合的生态,与各位携手并肩,共同探索未知,共同迎接挑战,共同定义未来!
让我们汇聚智慧的星河,驱动这场伟大的时代跃迁,共赴产业智变的新时代!谢谢大家!