【赵渝强老师】阿里云大数据MaxCompute的体系架构

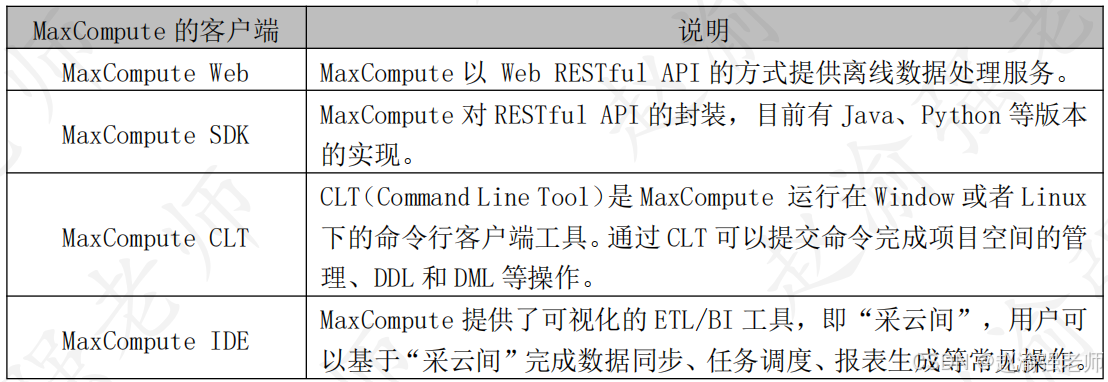
阿里云提供的大数据计算服务MaxCompute(原名ODPS,Open Data Processing Service的简称)是一种快速、完全托管的EB级数据仓库解决方案,主要用于实时性要求不高的离线计算分布式处理场景。因此,大数据计算服务MaxCompute不能用于数据的实时处理场景中。MaxCompute由四部分组成,分别是计算与存储层(MaxCompute Core)、逻辑层 (MaxCompute Server)、接入层 (MaxCompute FrontEnd)以及客户端 (MaxCompute Client)。MaxCompute的整体架构体系如下图所示。
| 视频讲解如下 |
|---|
| 【赵渝强老师】阿里云MaxCompute的体系架构 |
一、 计算与存储层(MaxCompute Core)
MaxCompute的底层存储使用的阿里云自研的分布式文件系统Pangu,它类似于Hadoop中的HDFS。基于Pangu的分布式文件系统,在MaxCompute中数据存储具有以下三个方面的特点:
- 基于MaxCompute Tables:表是MaxCompute的数据存储单元。MaxCompute中不同类型作业的操作对象(输入、输出)都是表。
- 采用Compression Strategy:MaxCompute采用列压缩存储格式,通常情况下具备5倍压缩能力。
- 数据存储可升级为AliORC:MaxCompute数据存储格式全面升级为AliORC,具备更高存储性能。
基于MaxCompute底层存储的数据,MaxCompute使用资源管理和调度系统伏羲对各种计算任务进行统一管理和调度,包括:MapReduce Job、Spark Job、SQL Job、图计算GraphX Job等等。
资源管理和调度系统伏羲,类似于Hadoop中的Yarn。它目前以管理和调度高吞吐的离线数据处理任务为主。
为了实现集群的高可用服务,在MaxCompute的体系架构中还使用了分布式协调服务女娲Nuwa。它类似于Hadoop生态圈体系中的ZooKeeper,可以使分布式集群的各个进程能够协调进行工作。

二、 逻辑层 (MaxCompute Server)
MaxCompute的逻辑层主要实现项目空间和对象的管理、命令的解析与执行逻辑、数据对象的访问控制与授权等功能。在逻辑层有Worker、Scheduler和Executor三个角色,它们各自的角色与作用如下:
- Worker(请求处理器) 处理所有客户端的请求,包括用户空间(project)管理操作、资源(resource)管理操作、作业管理等,对于SQL语句、MapReduce任务等启动伏羲任务的作业,会提交Scheduler进一步处理。
- Scheduler(调度器) 负责伏羲的调度,包括将任务分解为执行单元、对等待提交的执行单元进行排序、以及向伏羲询问执行单元的资源占用情况,并进行流量控制。
- Executor(作业执行管理器) 负责启动具体的任务执行单元,向伏羲提交任务执行单元;Executor还负责监控这些任务的运行。
在了解到了逻辑层的组成部分后,这里将进一步讨论逻辑层的处理流程:当用户提交一个MaxCompute作业请求时,接入层先进行用户认证,然后将作用请求发送给逻辑层的Worker;Worker判断是否为同步请求。如果是同步请求,则本地执行并返回;如果是异步请求,Worker会先做一些检查(如:表是否存在,版本号收费最新等等),并生成任务的ID,然后把请求进一步发送给Scheduler,并返回给客户端一个确认信息。Scheduler把作业分解成各个任务执行单元,Executor主动轮询Scheduler,获取相应的任务执行单元,提交给计算层执行,并定时将自己持有的任务执行单元的状态汇报给Scheduler。
三、 接入层 (MaxCompute FrontEnd)
简单来说,接入层的主要作用就是用于接收客户端的访问请求,并通过阿里云账号服务器对客户端请求中的签名信息进行验证,从而实现对客户端的控制。接入层提供的功能包括:HTTP服务、Cache缓存、Load Balance负载均衡、用户认证和服务层面的访问控制功能。下图很好的说明了接入层的作用。
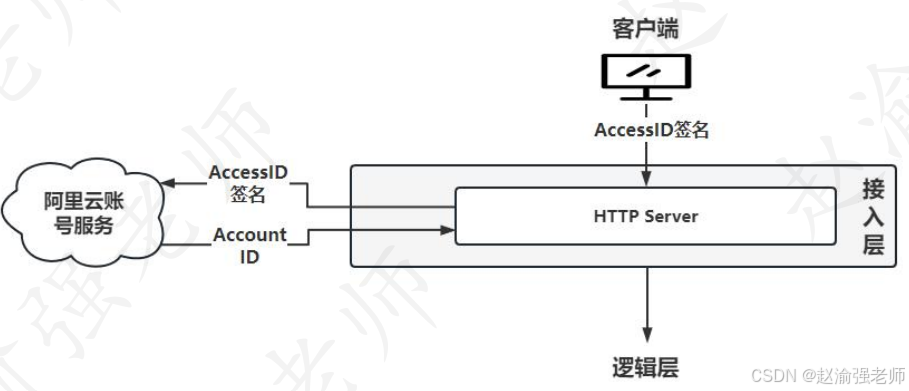
上图中的AccountID和AccessID有什么区别呢?一个AccountID可以对应多个AccessID和AccessKey,用户的权限数据都是和AccountID对应的。也就是说,假设某个用户被授权访问某个MaxCompute服务,而该用户有多对AccessID和AccessKey,则可以使用任何一对AccessID和AccessKey来访问MaxCompute服务。一个AccountID对应多个AccessID这个是从云计算的安全角度考虑的。比如:一个用户可以访问5个项目空间,每个项目空间可以通过不同的AccessID和AccessKey来访问。这样假设怀疑泄露第一个项目空间的AccessID和AccessKey,则可以删除该项目空间的AccessID和AccessKey,而不用修改其他项目空间的访问方式。
四、 客户端 (MaxCompute Client)
MaxCompute的客户端有四种不同的形式,分别是MaxCompute Web、MaxCompute SDK、MaxCompute CLT和MaxCompute IDE。下表说明了每种客户端的主要特征。