Linux基本工具(yum、vim、gcc、Makefile、git、gdb)
Linux软件包管理器yum
Linux不同的发行版都有不同的包管理器,用于下载、安装、删除软件,就像不同品牌的手机都有不同的应用市场一样,CentOS7的包管理器为yum,KALI的包管理器为apt......
搜索
若想列出所有可下载软件,可以用下面指令
yum list但直接使用该指令会被刷屏,如果想一页一页查看,可以再加上more/less这样的命令
yum list | more也可以利用管道模糊查询出想要的软件列表
yum list | grep [软件名]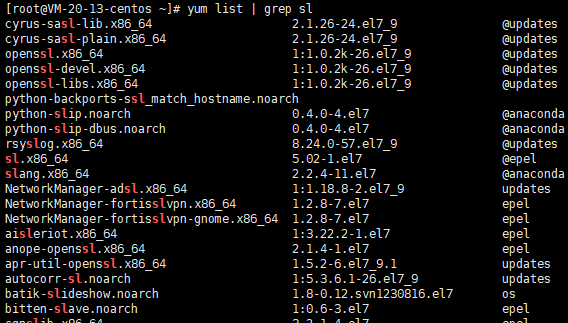
当然,yum本身也有自己的搜索指令
yum search [软件名]它会在列举出软件名的同时显示该软件的说明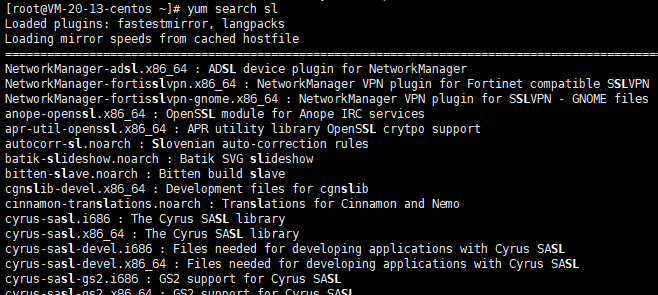
安装
若要安装软件,可以用yum Install命令
yum install [软件名]如果是普通用户,前面还需要加sudo
这样安装时会先提示你是否安装
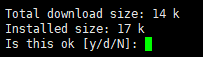
如果不想被提示,可以在install后加上-y
yum install -y [软件名]卸载
若想卸载已安装软件,可以用yum remove命令
yum remove [软件名]如果是普通用户,还是需要加sudo
上面命令卸载时会再次让你确认是否卸载
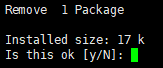
和安装时一样,如果不想被提示,可以在remove后加上-y
yum remove -y [软件名]注意:文件名部分不必写全名,例如yum list中有一个软件叫做sl.x86_64,那么软件名部分直接输sl即可(当然,全称也可以)
yum源配置
我们如果要用yum安装一个软件,是需要连接到远端服务器中下载的,如果读者用的是虚拟机中的Linux,包管理器的源可能是外网的链接,由于不可抗力原因会下载的非常慢甚至直接连不上,但如果读者用的是国内厂商的云服务器(例如腾讯云、阿里云、百度云、华为云等等),包管理器的源都是对应厂商的镜像链接,如何查看呢?
yum源在/etc/yum.repos.d/中,我们可以先进入该目录
[root@VM-20-13-centos ~]# cd /etc/yum.repos.d/
[root@VM-20-13-centos yum.repos.d]# ls
CentOS-Base.repo CentOS-Epel.repo可以看到,我的yum源只有两个,分别是基础源和扩展源
此时我们以基础源为例,打开后,是这样的内容
[extras]
gpgcheck=1
gpgkey=http://mirrors.tencentyun.com/centos-vault/RPM-GPG-KEY-CentOS-7
enabled=1
baseurl=http://mirrors.tencentyun.com/centos-vault/7.9.2009/extras/$basearch/
name=Qcloud centos extras - $basearch
[os]
gpgcheck=1
gpgkey=http://mirrors.tencentyun.com/centos-vault/RPM-GPG-KEY-CentOS-7
enabled=1
baseurl=http://mirrors.tencentyun.com/centos-vault/7.9.2009/os/$basearch/
name=Qcloud centos os - $basearch
[updates]
gpgcheck=1
gpgkey=http://mirrors.tencentyun.com/centos-vault/RPM-GPG-KEY-CentOS-7
enabled=1
baseurl=http://mirrors.tencentyun.com/centos-vault/7.9.2009/updates/$basearch/
name=Qcloud centos updates - $basearch由于编者的云服务器是腾讯云的,自然链接也是腾讯云镜像的地址
基础源可以被称为官方软件集合,在这里面的软件都经过考验的稳定、实用的软件。那么正在经受考验或者只是图一乐的软件都在哪呢?答案是在扩展源中,即非官方软件集合。
因此非官方软件集就相当于官方软件集的储备池。
Linux编辑器vim
在这之前,大家可能用的都是nano,那么为什么现在要学习vim而不继续用nano呢?
因为vim比nano功能更丰富,还有强大的代码编辑功能,并且插件生态丰富,支持复杂文本操作。相比之下,nano只是更适合新手操作
vim是一个多模式编辑器,有10几种不同模式,不过最主要的模式只有3个:命令模式、插入模式、底行模式
命令模式
首先,当我们vim [文件名]进入vim时,就是命令模式,此时只能对文件内容进行浏览、删除字符、复制粘贴、撤销等命令或更换其他模式。
光标移动:
h --> 光标向左移动、j --> 光标向下移动、k --> 光标向上移动、l --> 光标向右移动
gg --> 跳到当前光标所在位置的文件第一行、G --> 跳到当前光标所在位置的文件最后一行、nG --> n为行号,代表跳转光标到指定行
0 --> 行首、^ --> 移动到本行第一个非空字符、$ --> 行尾
w --> 移到下一个单词开头、b --> 移到上一个单词开头
删除操作:
x --> 删除光标所在字符(向后删除)、nx --> n为数字,删除从光标所在字符开始的往后n个字符;X --> 删除光标所在的前一个字符(向前删除)、nX --> n为数字,删除从光标所在的前一个字符开始的往前n个字符
dd --> 删除当前行、ndd --> n为行数,删除从光标行开始往下数的n行
dw --> 删除一个单词、ndw --> n为数字,删除从光标开始处的n个单词
cw --> 删除当前光标往后的一个单词,并进入插入模式、cnw --> n为单词数,删除当前光标往后的n个单词
复制,剪贴与粘贴:
yy --> 复制当前行、nyy --> n为行数,复制从当前行开始往下数的n行;p --> 粘贴(在光标当前行的下一行插入)、np --> n为数字,粘贴n次内容
在删除操作中,无论是删除字符还是删除一行,都相当于剪贴操作,此时再按p粘贴,就可以把剪贴的内容粘贴出来(在光标后插入)
撤销与重做:
u --> 撤销上一次操作、Ctrl + r --> 重做上一次撤销
文本编辑:
~ --> 可以切换当前光标所示字符的大小写,一直按住可以向后切换
rx --> x为字符,可以将当前光标处字符替换成x
模式切换
在命令模式下,输入R即可进入替换(replace)模式,在替换模式下,相当于windows下按下了insert键,可以实行批量化替换
在命令模式下,输入i即可进入插入(insert)模式、输入a,光标往后移一位再进入插入(insert)模式、输入o,在当前行下方新建一行,并且光标移到该新建行,再进入插入(insert)模式。在插入模式下,可以像windows下的记事本一样编辑文本
底行模式
在命令模式下,输入:(冒号)即可进入底行模式。底行模式常用于保存、退出、查找、替换等操作。在底行模式下输入wq(write quit,代表写入并退出)即可保存退出vim,输入x也可以保存并退出。但如果在文件没有被修改的情况下,输入x就不会更新文件修改时间,而wq会更新
set nu --> 显示行号、set nonu --> 关闭行号
vs [文件名] --> 分屏、Ctrl + ww --> 光标跨屏(将光标从一个屏幕跳转到另一个屏幕上)
![命令] --> 在底行中执行linux命令、[vim内部命令]! --> 强制执行vim内部命令
%s/[当前字符串]/[要替换的字符串]/g --> g代表global(全局),表示替换字符串
在除了命令模式的任何模式下,按下Esc即可退出该模式,返回到命令模式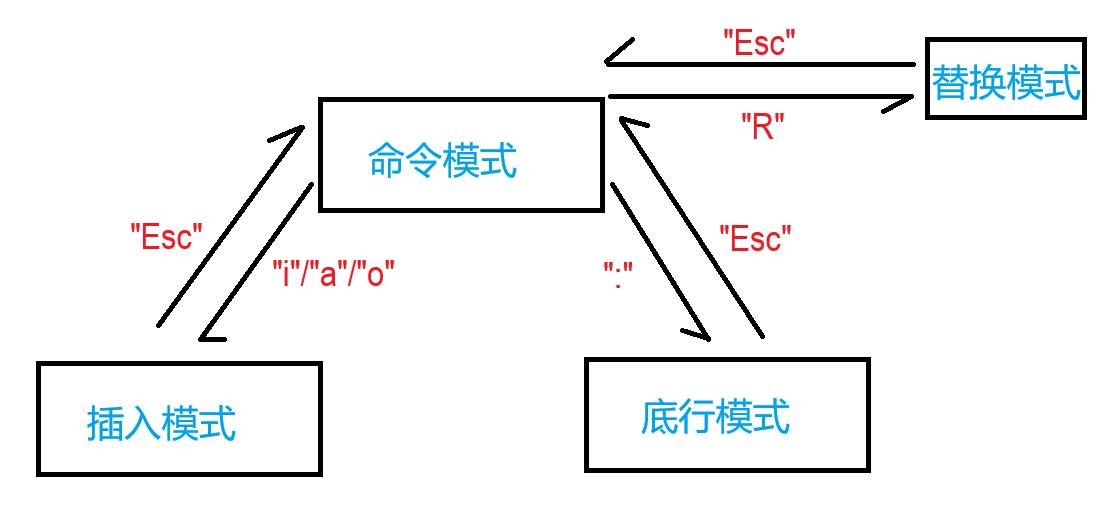
vim配置
在/etc/下有一个名为vimrc的文件,它是属于所有用户的公共vim配置文件,即在这里面的配置会对所有用户生效。而在每个用户的家目录下,也可以建立私有的配置文件,命名为:".vimrc",在这里面可以加许多配置选项,例如:
syntax on # 设置语法高亮
set nu # 显示行号
set shiftwidth=4 # 设置缩进的空格数为4而自己一行一行配置的时间成本太大,光编者自己的配置文件就有400多行...

好在有大佬开源出了一个vim配置工具,可以一键配置完成vim的cpp环境
项目地址:
VimForCpp: 快速将vim打造成c++ IDE![]() https://gitee.com/HGtz2222/VimForCpp只需要在自己用户家目录下执行下面这条指令
https://gitee.com/HGtz2222/VimForCpp只需要在自己用户家目录下执行下面这条指令
curl -sLf https://gitee.com/HGtz2222/VimForCpp/raw/master/install.sh -o ./install.sh && bash ./install.sh就可以自动为该用户配置vim(需要输入root用户密码)
Linux编译器gcc/g++
我们都知道,从一个C/CPP源文件到可执行程序,需要执行四步:
预处理:头文件展开,去注释,宏替换,条件编译等
编译:把C/CPP文件变成汇编文件
汇编:把汇编文件变成二进制文件
链接:把你写的代码和C/CPP标准库中的代码链接起来
直接gcc [源文件名] 即可直接获得默认可执行文件名a.out,如果不想该可执行文件名字固定,也可以在后面加上-o [生成文件名],-o表示指定形成的文件名,但也可以一步步处理
ps:gcc/g++后面跟的文件必须有后缀.c,否则不会认
gcc [源文件名] # 可执行文件名直接为a.out
gcc [源文件名] -o [生成文件名] # 可执行文件名为对应名字gcc还提供了宏定义选项 -D ,-D后直接加要定义的宏,和在源文件内用#define的效果相同
gcc [源文件名] -D[宏名称]=[值]
gcc [源文件名] -D[宏名称]//默认值为1-U选项可以取消某个宏,和在源文件内用#undef效果相同
gcc [源文件名] -U[宏名称]若想要预处理、编译、汇编、链接一步步来,可以用下面几个命令
gcc -E [.c源文件] [-o [预处理文件名]] # -E代表将该文件预处理完后就停下来
gcc -S [.c源文件/.i预处理文件] [-o [汇编文件名]] # -S代表将该文件编译完后就停下来
gcc -c [.c源文件/.i预处理文件/.s汇编文件] [-o [目标文件名]] # -c代表将该文件汇编完后就停下来
gcc [.c源文件/.i预处理文件/.s汇编文件/.o目标文件] [-o [可执行文件名]] # 代表将该文件链接完,即可执行程序gcc选项从预处理到编译到汇编分别为ESc,而后缀文件名分别是iso
gcc默认编译C源文件,g++默认编译CPP源文件,可以将g++理解为gcc的一个子命令,是专门为编译CPP文件实现的,g++默认也可以编译C源文件,但gcc默认不能编译CPP源文件(会找不到c++动态库)
注意:gcc的一些选项,例如-o、-D、-U位置不是固定的,加在哪里都可以
动态链接和静态链接
链接分为动态链接和静态链接
动态链接是在运行时加载所需要的库(共享库),可执行文件中仅包含对动态库的引用
因此通过动态链接出来的可执行程序较小——占用硬盘空间较小,那么遇到该程序需要加载到内存的情况时——占用内存空间较小,并且在通过网络下载时,所需要的流量也较小,速度也快
但上面说过,动态链接只有对动态库的引用,因此也依赖于动态库,如果机器上没有对应的动态库,就会运行失败
优点:占用硬盘、内存空间小,通过网络下载时所需流量少,速度快;多个程序可以共享同一份动态库代码,减少内存和磁盘占用
缺点:依赖外部库,机器上必须有对应的动态库
静态链接是在编译时直接将所有依赖的库(静态库)直接合并到最终的可执行程序中
因此通过静态链接出来的可执行程序较大——占用硬盘空间较大,同样的,占用内存和下载时所需流量也较大
但由于可执行程序中直接包含所依赖的库,即使机器上没有对应的库文件也可以运行
优点:不依赖于外部库、启动速度快
缺点:占用硬盘、内存空间大,通过网络下载时所需流量大,速度慢
动态链接用的是动态库(也叫共享库),而静态链接用的是静态库。
在Linux下,动态库的格式为:libXXXX.so
静态库的格式为:libXXXX.a
(在Windows下,动态库后缀为.dll,静态库后缀为.lib)
其中,XXXX代表库的名字
例如,我们可以通过 file [文件名] 命令来查看该文件的各种信息
当我们file一下用gcc编译完的可执行文件时,就会出现下面信息
test.out: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), dynamically linked (uses shared libs), for GNU/Linux 2.6.32, BuildID[sha1]=9fc19efe5a60448b3a2d19e1e150f7b77d65993a, not stripped从左往右看,test.out代表文件名
ELF代表该文件为二进制文件
64-bit代表该文件为64位架构
LSB代表该文件为小端序(大端序为MSB)
executable代表该文件是可执行程序,而非目标文件(.o)或共享库(.so)(因为目标文件和共享库文件等也是ELF文件)
x86-64代表该文件架构为x86_64
version 1 (SYSV)这里不作解释
dynamically linked (use shared libs)代表该程序是动态链接的(运行时依赖共享库)。那么我们怎么看它动态链接的哪一个库呢?可以用 ldd [文件名] 命令,来查看可执行文件或动态库所依赖的动态链接库
linux-vdso.so.1 => (0x00007ffe8b72f000)libc.so.6 => /lib64/libc.so.6 (0x00007f9100635000)/lib64/ld-linux-x86-64.so.2 (0x00007f9100a03000)可以看到,第二行中,有一个libc.so.6,而它是一个链接文件(相当于Windows的快捷方式),真正的库文件是"=>"右边的文件,即/lib64目录下的libc.so.6文件,也就是C动态库。这也表名gcc编译时默认用的是动态链接
动态库说完了,还有静态库呢?
如果我们想让gcc编译出的可执行程序是静态链接的,需要在最后加上 -static 参数
gcc [.c/.i/.s/.o文件] [-o [可执行文件名]] -static如果之前没有安装过静态库,大概率会报下面的错
/usr/bin/ld: cannot find -lc
collect2: error: ld returned 1 exit status这代表我们还没有安装C静态库,安装可以用下面命令:
sudo yum install -y glibc-static如果是root用户,就把sudo去掉
此时再加 -static 就可以静态链接了
现在再file一下生成出的可执行文件
test.out: ELF 64-bit LSB executable, x86-64, version 1 (GNU/Linux), statically linked, for GNU/Linux 2.6.32, BuildID[sha1]=7cd92dd71613a6bad6eea55cc7d520b28e98e9d7, not stripped可以看到,原本的dynamically linked (use shared libs)变成了statically linked,即静态链接。
看一下动态链接和静态链接出来的程序的大小差距(单位是字节)
-rwxrwxr-x 1 valexi valexi 8360 Aug 18 10:14 test_dynamic.out
-rwxrwxr-x 1 valexi valexi 861288 Aug 18 10:06 test_static.out
动态链接出来的可执行程序约为8KB,而静态链接出来的可执行程序约为841KB,差距非常大
再用 ldd 查看一下可执行文件或动态库所依赖的动态链接库,会给出下面报错
not a dynamic executable意思为:“不是动态可执行文件”
安装好的C静态库为/lib64/libc.a
![]()
为什么静态链接需要额外下载静态库,而动态链接就不用下载动态库?
如果我们ldd几个基本命令,会发现它们都是动态链接的,其中还有C动态库,这是因为Linux大部分指令都是用C/C++写的
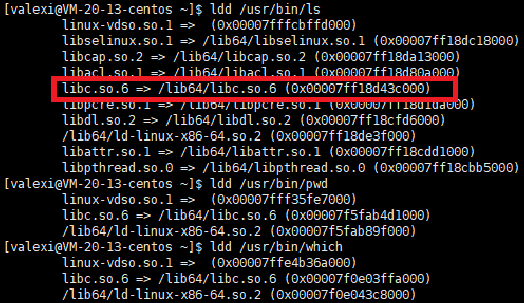
也正因如此,系统中必须包含动态库(Windows下也是一样)
C++也是如此,由于系统会自带C++的动态库,所以直接编译时不会有问题,但如果要指定静态链接,也会出现找不到静态库的问题,所以还需要再安装C++的静态库:
sudo yum install -y libstdc++-static
ps:如果系统中只有静态库,那么gcc在链接时默认会用静态库链接
Release/Debug
gcc默认编译生成的可执行文件是Release版,若想设置为Debug版,需加上-g选项
gcc [.c/.i/.s/.o文件] [-o [可执行文件名]] -g它们两者区别在于Debug版比Release版多了调试信息。如何验证?
readelf 命令用于查看和分析ELF文件(Linux可执行文件格式),其中-S选项可以显示节头信息
用它查看Release版和Debug版的可执行文件
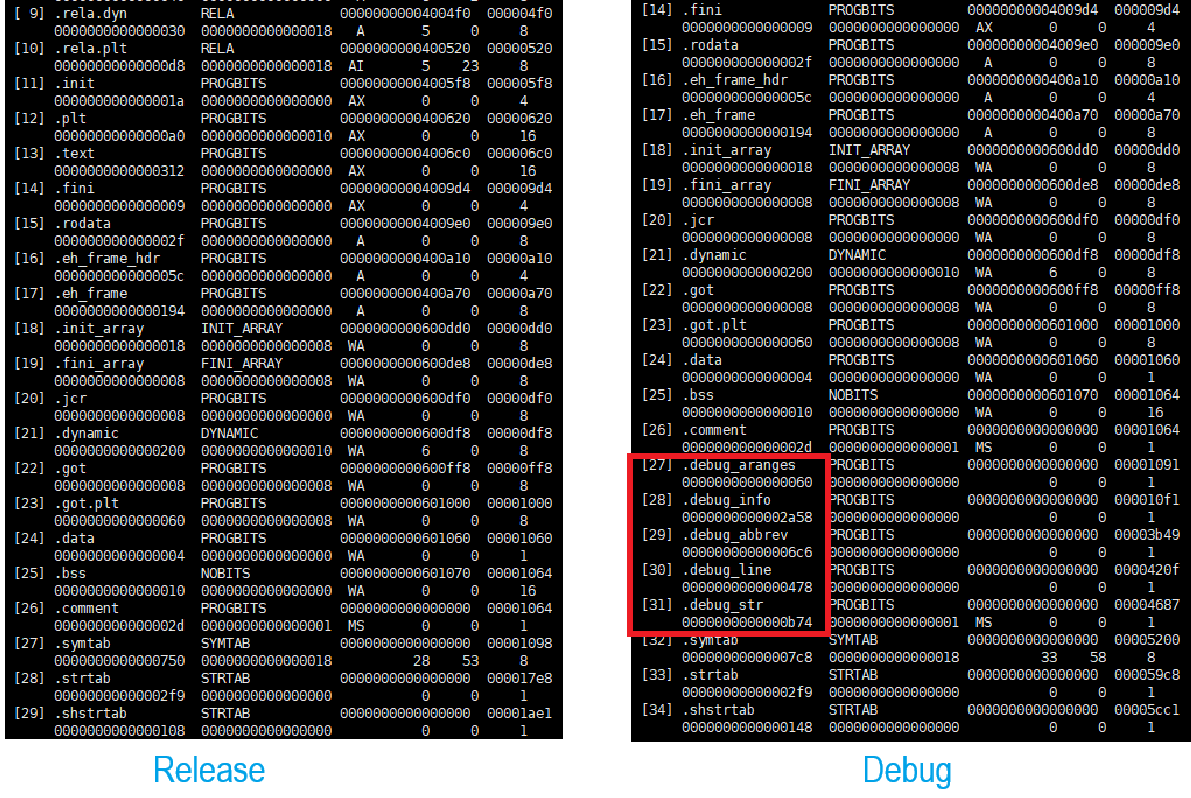
可以看到,Debug版的可执行文件比Release多了5个有关调试的分区
因此Debug版要比Release版大
Linux项目自动化构建工具make/Makefile
在Windows下写项目,拿Visual Studio来举例,在有多个.h和.c/cpp文件时,开发者只需点击"生成解决方案"或"启动调试"按钮,VS就可以处理各个文件的编译链接
而在Linux下,则需要靠我们自己完成,于是就有了一键完成该功能的工具——make/Makefile
makefile是文件,make是命令
要理解标题的话,首先,makefile/Makefile是我们需要创建的文件(m大小写都可以,后面会说区别),当我们写好要编译的源文件并创建出Makefile文件时
[valexi@VM-20-13-centos mk]$ ls
makefile test.cpp此时我们就可以进入Makefile定义构建规则
vim makefileMakefile内部要写的是依赖关系和依赖方法。
test.out:test.cppg++ test.cpp -o test.out在这两行代码中,第一行就是依赖关系,第二行就是依赖方法
依赖关系:依赖关系由三部分组成:[目标文件/名称]:[依赖文件列表],对于上面例子来说,就是test.out依赖于test.cpp(test.out是通过test.cpp实现的)
依赖关系写完后,下一行必须以 tab键 起手,否则会报错。再写你这个依赖关系要执行的指令,即依赖方法。我这里就是通过test.cpp生成可执行文件test.out,这两行一起就是一条规则
保存并退出后,此时我们再 make 一下,就会默认先寻找当前目录的Makefile,再寻找当前目录的makefile(也就是说,Makefile和makefile唯一的区别就是优先级的问题,Makefile的优先级比makefile高,建议在标准项目中优先使用Makefile),如果找到,就执行该文件内的规则
[valexi@VM-20-13-centos mk]$ make
g++ test.cpp -o test.out
此时就自动帮我们生成出了test.out文件
当我们想要清理项目时,也可以写一个规则:
test.out:test.cppg++ test.cpp -o test.outclean:rm -f test.out 在第二个规则中,clean是一个目标名称,但它并不需要任何依赖文件,因此依赖文件那里就为空。第二行同样以tab起手,执行删除命令
但默认make是找到Makefile/makefile文件后,执行从上往下的第一个规则的依赖方法,如果想执行其他规则,就要在make后面加上对应的目标文件名
现在我们想执行clean规则,就要 make clean
[valexi@VM-20-13-centos mk]$ make clean
rm -f test.out就会自动执行对应规则里的依赖方法
.PHONY
但一般来说都会在clean规则的上面加上 .PHONY:clean
test.out:test.cppg++ test.cpp -o test.out.PHONY:clean
clean:rm -f test.out.PHONY用于声明伪目标,什么意思呢?
1.避免与实际文件冲突
如果目标名称与当前目录中的文件名相同,make会认为该目标已经存在,从而跳过执行。拿上面代码举例,如果没有 .PHONY:clean 这一行,我们当前目录中正好有一个名为clean的文件,当我们再 make clean 时,make就会认为clean目标已经是最新的,直接跳过命令
[valexi@VM-20-13-centos mk]$ make clean
make: `clean' is up to date.此时只要声明clean是伪目标,就可以解决这个问题
2.强制每次执行命令
再者,将一个目标声明为伪目标后,也代表着会强制执行每次命令。例如,当我make过一次,已经通过make命令生成出一个可执行文件,并且源文件也没有改动时,再make一下就会提示你该文件是最新的,也会跳过命令(如果你不会出现,这是由于你的目标文件名和生成出的可执行文件名不一样,make只会拿该规则的目标文件名来判断是否已经存在可执行文件)
[valexi@VM-20-13-centos mk]$ make
g++ test.cpp -o test.out
[valexi@VM-20-13-centos mk]$ make
make: `test.out' is up to date.但如果该规则也被修饰为伪目标,make就不会检查依赖文件是否更新了
那么make是怎么知道现在的目标文件是不是最新的呢?
stat [文件名] 用于显示文件或文件系统的详细信息,包括时间
[valexi@VM-20-13-centos mk]$ stat test.outFile: ‘test.out’Size: 8968 Blocks: 24 IO Block: 4096 regular file
Device: fd01h/64769d Inode: 917801 Links: 1
Access: (0775/-rwxrwxr-x) Uid: ( 1001/ valexi) Gid: ( 1001/ valexi)
Access: 2025-08-19 16:07:10.467572056 +0800
Modify: 2025-08-19 16:07:09.238579599 +0800
Change: 2025-08-19 16:07:09.238579599 +0800Birth: -
可以看到一个文件的时间有三个:Access、Modify、Change
而其中Modify就是文件内容修改的时间,每次文件内容被修改,这个时间都会更新。
在通过make命令构建项目时,相对应生成出来的可执行文件也有Modify日期,make就是通过比较源文件和可执行文件的Modify日期,若可执行文件的Modify日期比源文件要新,就代表源文件肯定没有被更改过,此时就无需再重复编译生成
3.提高构建效率
如果目标不是伪目标,make会检查目标文件是否存在以及源文件是否有改动(其实就是检查依赖文件是否更新)。而对于伪目标,make直接执行命令,无需文件检查,节省时间
因此,所有非文件目标都应声明为伪目标。特定想强制每次执行命令的目标文件也声明为伪目标
Makefile的推导规则
在上面Makefile文件中,我们的依赖关系写的是 test.out:test.cpp ,意思是test.out是依赖于test.c实现的,但更准确一点,test.out是依赖于test.o(目标文件)实现的,而test.o是依赖于test.s实现的,而test.s是依赖于test.i实现的,根据前面gcc/g++所学到的知识,我们就可以让规则更完善:
test.out:test.og++ test.o -o test.out
test.o:test.sg++ -c test.s -o test.o
test.s:test.ig++ -S test.i -o test.s
test.i:test.cppg++ -E test.cpp -o test.i .PHONY:clean
clean: rm -f test.out test.o test.s test.i此时我们再 make 一下
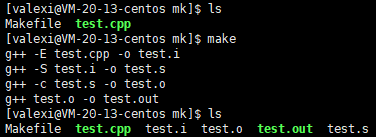
会发现它将预处理、编译、汇编、链接所产生的预处理文件,汇编文件,目标文件,可执行文件都生成出来了,并且执行的顺序和Makefile中的顺序是相反的
上面我们说过,make的默认行为是执行Makefile/makefile中从上到下第一条规则的依赖方法。
以上面的代码举例子,当找到第一条规则之后,发现它的依赖文件找不到(即test.o),那么它会先去找有没有该依赖文件的依赖关系(即找test.o的依赖关系),当我们找到test.o的依赖关系之后,发现它的依赖文件test.s也没有,那么它会先去找有没有test.s的依赖关系,以此类推
当找到test.cpp时,会先执行test.i的依赖方法,之后test.s的依赖文件就有了,再执行test.s的依赖方法,以此类推...

和栈很像,都是后进先出
Linux小程序——进度条
以我们现在的知识,就可以做一个Linux最基础的程序了
sleep & fflush
首先来看下面代码:
#include <iostream>
#include <stdio.h>
#include <unistd.h>//在Linux系统中,sleep函数包含在<unistd.h>中,而在Windows系统中,sleep函数包含在<windows.h>中
using namespace std;
int main()
{printf("Hello World\n");sleep(2);//让当前进程或线程暂停2秒 return 0;
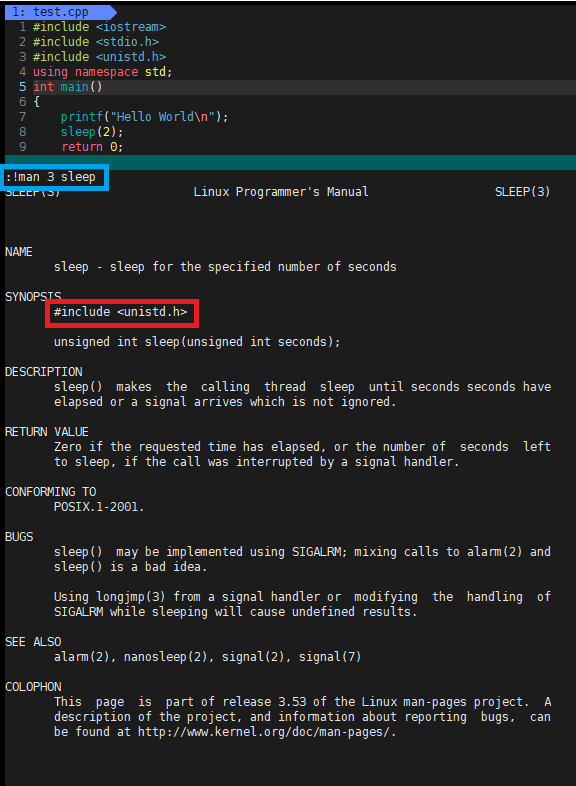
} 如果不知道sleep函数在哪个头文件或者不知道sleep的作用,可以用以前学过的知识:
①shift + : 进入底行模式
②输入 ! 代表在底行模式下执行后面命令
③再继续输入man 3 sleep,按下Enter键。man是查找指令、函数的指令,3代表在第3章(也就是C库函数章)查询
现在我们执行一下编译好的程序
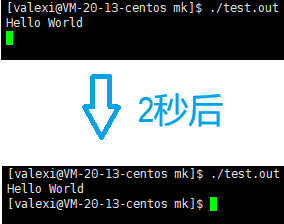
输出Hello World后,就会先暂停两秒,再结束
但当我们把printf中的\n去掉后,再运行就变成了这样
#include <iostream>
#include <stdio.h>
#include <unistd.h>//在Linux系统中,sleep函数包含在<unistd.h>中,而在Windows系统中,sleep函数包含在<windows.h>中
using namespace std;
int main()
{printf("Hello World");sleep(2);//让当前进程或线程暂停2秒 return 0;
} 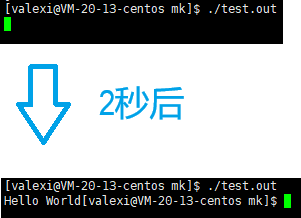
这次在暂停时没有输出Hello World
这是因为当执行到sleep(3)时,Hello World还在缓冲区(buffer)中,如果我们想让它立即显示,可以用fflush函数,它用来刷新由 FILE 流管理的缓冲区(例如stdout、stdin、文件等)。而printf就是打印到stdout流中,所以我们只要fflush(stdout)一下,就可以刷新该流缓冲区,从而立即显示到屏幕上
#include <iostream>
#include <stdio.h>
#include <unistd.h>//在Linux系统中,sleep函数包含在<unistd.h>中,而在Windows系统中,sleep函数包含在<windows.h>中
using namespace std;
int main()
{printf("Hello World");fflush(stdout);刷新输出流缓冲区sleep(2);//让当前进程或线程暂停2秒 return 0;
} 但我们一开始的代码为什么加\n就可以显示呢?
这是因为stdout(标准输出)通常使用行缓冲(Line Bufering)模式,只有在确保当前行被输出完后才会在屏幕显示,而\n就可以保证这一条件
\r & \n
\n的标准定义是换行符,指将光标从当前行移到下一行,并不会回到下一行的行首
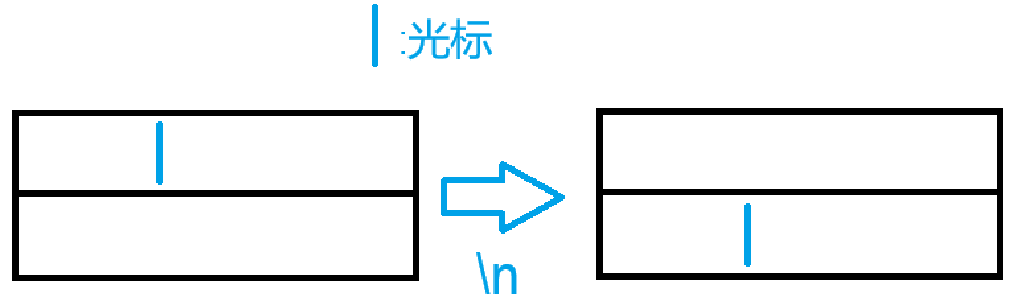
\r的标准定义是回车符,指将光标移动到当前行的行首
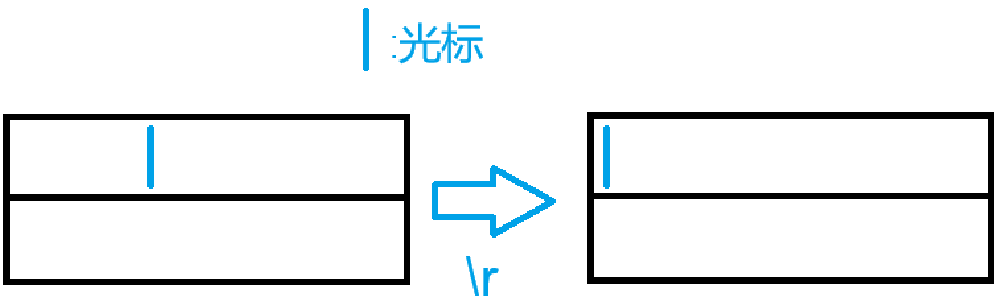
之所以我们在终端中运行\n的效果是将光标移动到下一行的行首,是因为Linux、Windows等都会将\n视作\r\n处理
如果我们在一行中已经输出了字符,回车\r回车后,再输出字符时,就会将之前的字符覆盖掉
倒计时小程序
那么现在就能写一个倒计时小程序
#include <iostream>
#include <stdio.h>
#include <unistd.h>//fflush函数所在的库
using namespace std;
int main()
{for(int i = 9;i >= 0; i--){printf("剩余时间:%d\r",i); fflush(stdout);//刷新输出流,使printf立即显示到屏幕上sleep(1);//暂停1秒}return 0;
}
但现在还有个小问题:如果我将i的初始值改为10,那i等于9时,只会覆盖第一个字符(即1),而0还在原位不动。为了解决这个问题,我们可以将%d改为%2d,意为每次输入两个字符(也可以改为%-2d,左对齐,个人认为更舒服一点)
#include <iostream>
#include <stdio.h>
#include <unistd.h>//fflush函数所在的库
using namespace std;
int main()
{for(int i = 9;i >= 0; i--){printf("剩余时间:%-2d\r",i); fflush(stdout);//刷新输出流,使printf立即显示到屏幕上sleep(1);//暂停1秒}return 0;
}
进度条小程序
有了前面知识的铺垫,就可以写出进度条了(这里以多文件项目的方式写)
首先我们 touch 出对应的文件
[valexi@VM-20-13-centos mk]$ ls
main.cpp Makefile process.cpp process.h这其中,main.cpp是主文件(main函数所在的文件),process.cpp是进度条函数所在的文件,process.h是进度条函数声明所在的文件
我们将Makefile文件写好
ProcessOn:process.cpp main.cppg++ process.cpp main.cpp -o ProcessOn
PHONY:clean
clean:rm -f ProcessOn g++里没有带process.h,因为该头文件就在当前目录,因此可以自己找到
main.cpp:
#include "process.h" using namespace std;
int main()
{ ProcessOn(); return 0;
} process.h:
#pragma once
//#define S_NUM 0//进度条的默认样式
#include <iostream>
#include <stdio.h>
#include <unistd.h>//usleep所在的库
extern void ProcessOn();//外部声明该函数这里S_NUM宏注释掉,是为了方便在Makefile中用-D选项加入宏
ProcessOn:process.cpp main.cppg++ process.cpp main.cpp -o ProcessOn -DS_NUM=0
PHONY:clean
clean:rm -f ProcessOn process.cpp:
#include "process.h" void ProcessOn() { char style[5] = {'#','>','-','%','$'};//进度条样式 char lable[7] = {'\\','-','/','|','\\','-','|'}; char process[101] = {0};//进度条 for(int cnt = 0; cnt <= 100; cnt++) { process[cnt] = style[S_NUM];//可以选择样式,STYLE默认为0 printf("[%-100s]%3d%%[%c]\r",process,cnt,lable[cnt%7]); fflush(stdout);//刷新标准输出,使得printf的内容立刻显示到终端上 usleep(40000);//单位为微秒的对该进程或线程暂停 } putchar('\n');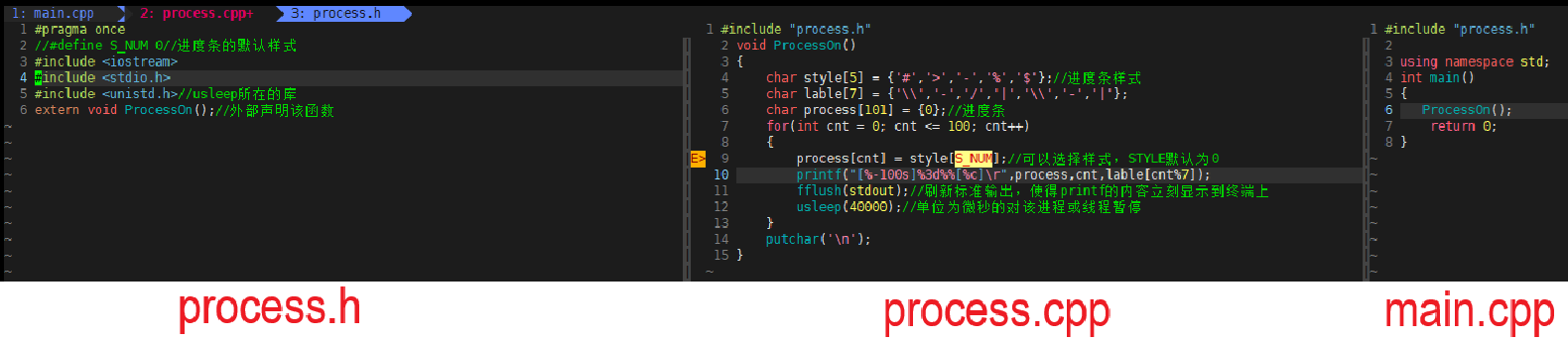
运行效果:
[valexi@VM-20-13-centos mk]$ ./ProcessOn
[#####################################################################################################]100%[/]在这基础上还可以给字体和背景加些颜色
C/C++的printf是可以通过ANSI转移序列或Windows API给字体加颜色的,格式如下:
printf("\033[字背景颜色;字体颜色m字符串\033[特殊效果m");字背景颜色:
40: 黑色 41: 红色 42: 绿色 43: 黄色
44: 蓝色 45: 紫色 46: 青色 47: 白色字体颜色:
30: 黑色 31: 红色 32: 绿色 33: 黄色
34: 蓝色 35: 紫色 36: 青色 37: 白色特殊效果(其他属性):
0: 重置所有属性
1: 加粗/高亮 2: 暗淡 4: 下划线 5: 闪烁 7: 反色 8: 隐藏给字体加上颜色后的process.cpp:
#include "process.h" void ProcessOn() { char style[5] = {'#','>','-','%','$'};//进度条样式 char lable[7] = {'\\','-','/','|','\\','-','|'}; char process[101] = {0};//进度条 for(int cnt = 0; cnt <= 100; cnt++) { process[cnt] = style[S_NUM];//可以选择样式,STYLE默认为0 printf("\033[30;47m[%-100s]%3d%%[%c]\r\033[0m",process,cnt,lable[cnt%7]);//白底黑字 fflush(stdout);//刷新标准输出,使得printf的内容立刻显示到终端上 usleep(40000);//单位为微秒的对该进程或线程暂停 } putchar('\n'); }
运行效果:
![]()
Linux版本控制工具git
在Windows下,相信大家也都或多或少用过git(包括小乌龟),而在Linux下写的项目同样需要版本控制工具,这样的控制工具有很多,这里以git为例
一般来说云服务器都已预装了git工具,如果没有安装,可以执行下面指令
sudo yum install -y git市面上有很多基于git工具的版本管理平台,例如github、gitlab、gitee等等,由于国外的平台都有一定上手门槛,这里以gitee为例
创建仓库时,一般都会让你选择.gitignore模板,其中.gitignore是一个文件,是Git版本控制系统的一个特殊配置文件,它用来告诉Git哪些文件或目录不需要被跟踪(即不纳入版本控制),这些模板是预定义的.gitignore文件,它们会根据你选择的编程语言或框架,自动添加一些常见的忽略规则
在gitee创建好仓库后,如果想要拷贝仓库到linux下,可以用 git clone [http仓库地址] 命令
git三板斧:添加(add),提交(commit),推送(push)
git其实是最后通过推送(push)仓库目录中的.git目录,来和远端仓库的.git目录作对比,将新增或有更改的文件加进去;
git push添加(add)操作就是将本地仓库中的新增或有改动的文件添加到暂存区;
git add . # 表示将当前目录的所有文件添加进去
git add [文件名] # 也可以添加指定文件而提交(commit)操作就是将通过添加(add)操作添加到暂存区的文件通过哈希转码的方式存到.git目录中
git commit -m '[描述]' # (描述不可省略)当push完后,就可以在远端仓库中看到刚刚同步的文件了
git扩展命令
- 在git仓库中使用 git log 命令,可以查看该仓库所有的远端推送,顺序是从近到远
- 如果想要在本地仓库删除文件,最好将 rm 换成 git rm ,因为后者可以自动将删除的文件添加到暂存区,可以让git知道你删除了文件,否则还需要 git add 或 git commit -a 手动将其添加到暂存区。 git mv 也同理
- git status 用于查看当前工作目录和暂存区的状态,主要作用:显示工作目录中已修改(modified)、已新增(untracked)、被忽略(ignored)的文件;显示暂存区中的文件状态;显示当前所在分支(branch)以及与上游分支的差异;检测合并冲突
- 当远端仓库的最新如期比本地仓库要新时,我们需要先 git pull 一下,将远端仓库拉取到本地,才可以继续commit
Linux调试器gdb
在Windows环境下,拿VS举例,除了编辑和运行代码,还可以调试代码,Linux下也可以,不过是纯命令行操作
没有安装gdb的话,可以用下面指令安装
sudo yum install -y gdb若想对一个程序进行调试, gdb [可执行文件名称] 即可进入调试模式
这里就拿上面的进度条程序来测试
此时就进入gdb模式了,但当我们随便输入一些命令时,会报错
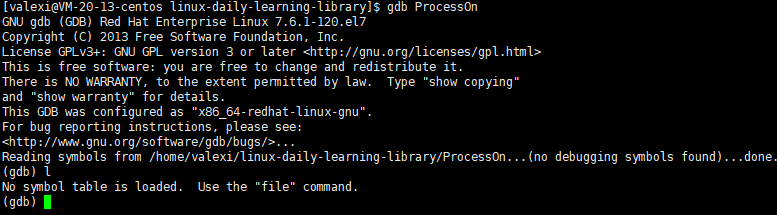
这是因为gcc默认生成的可执行文件是Release版,要想调试,必须是Debug版的程序才可以
只需在Makefile文件中稍微一改,再make就可以
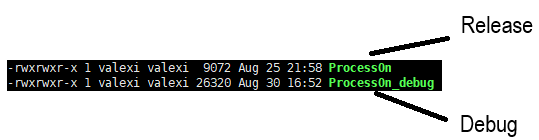
ProcessOn_debug:process.cpp main.cpp g++ process.cpp main.cpp -o ProcessOn_debug -DS_NUM=0 -g # -g表示生成Debug版
PHONY:clean
clean: rm -f ProcessOn_debug此时再进入gdb模式就可以调试了
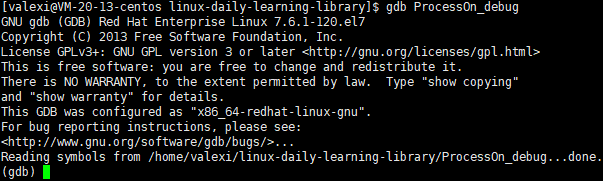
输入q可退出gdb模式
gdb命令
现在来介绍一些常用的gdb命令(简称和全名都可以用)
- l [行号] --> 全名 list ,查看代码,默认查看当前执行位置附近的10行代码,后面可以跟行号,代表查看从第N行开始的后10行,如果想继续往下查看,可以直接按Enter(gdb会记住用户的命令)
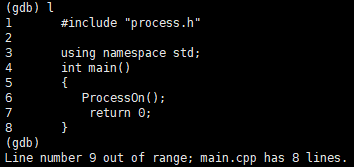
- b [行号] --> 全名 break (breakpoint的意思),打断点,后面跟数字代表要在第几行打断点
- info [查询目标] --> 用于查询程序运行时的各种信息
info b / info break / i b 可以列出所有断点;
这其中有一列是Enb,代表Enable,显示启用状态,y为启用,n为禁用
![]()
若想禁用断点,可以用 disable [断点编号] / disable breakpoints [断点编号]
启用断点就 enable [断点编号]
禁用和启用的操作相当于VS中的Ctrl + F9
info locals 可以查看当前函数的局部变量的值;
- d [断点编号] --> 全名 delete ,删除断点,需要注意的是后面跟的是断点编号而不是行号
- r --> 全名 run ,运行代码。在没有断点的情况下run就相当于直接运行该程序(可以理解成VS的F5(调试运行))。在有断点的情况下,r会直接运行到下一个断点处

- n --> 全名 next ,逐过程运行代码,相当于VS的F10
- s --> 全名 step ,逐语句运行代码,相当于VS的F11
- c --> 全名continue,跳转到下一个断点处,相当于VS的F5
- bt --> 查看调用堆栈
- finish --> 结束当前函数,暂停在调用处
- p [变量名] --> 全名 print ,可以临时查看变量的值
- display [变量名] --> 每次程序暂停时自动打印指定变量或表达式,即常显示变量
- undisplay [变量名] --> 可以取消常显示变量
- until [行号] --> 跳转到指定行
- set val [变量名] = [值] --> 可以修改变量的值