大模型应用开发笔记(了解篇)
一 ⼤型语⾔模型(LLM)理论简介
①何为大模型:LLM 通常指包含数百亿(或更多)参数的语⾔模型,它们在海量的⽂本数据上进⾏训练,从⽽获得对语⾔深层次的理解。⽬前,国外的知名 LLM 有 GPT-
3.5、GPT-4、PaLM、Claude 和 LLaMA 等,国内的有⽂⼼⼀⾔、讯⻜星⽕、通义千问、ChatGLM、百川等。
②以下是几个常见的大模型:
(1)闭源的大模型
GPT系列:GPT 模型的基本原则是通过语⾔建模将世界知识压缩到仅解码器 (decoder-only) 的 Transformer 模型中,这样它就可以恢复(或记忆)世界知识的语义——OpenAI 发布了基于 GPT模型(GPT-3.5 和 GPT-4) 的会话应⽤ ChatGPT——GPT-4将⽂本输⼊扩展到多模态信号,GPT-4 ⽐ GPT-3.5 解决复杂任务的能⼒更强,在许多评估任务上表现出较⼤的性能提升。
Claude 系列:由 OpenAI 离职⼈员创建的 Anthropic 公司开发的闭源语⾔⼤模型。
PaLM 系列: Google 开发。其初始版本于 2022 年 4 ⽉ 发布,并在 2023 年 3 ⽉公开了 API。
⽂⼼⼀⾔:基现已更新到 4.0 版本。更进⼀步划分,⽂⼼⼤模型包括 NLP ⼤模型、CV ⼤模型、跨模态⼤模型、⽣物计算⼤模型、⾏业⼤模型。中⽂能⼒相对来说⾮常不错的闭源模型。
讯⻜星⽕认知⼤模型:科⼤讯⻜发布的语⾔⼤模型,⽀持多种⾃然语⾔处理任务。
(2)开源 LLM
LLaMA 系列模型:是Meta 开源的⼀组参数规模 从 7B 到 70B 的基础语⾔模型。LlaMa 于 2023 年 2 ⽉ 发布,并于 2023 年 7 ⽉ 发布了 LlaMa2 模型。它们都是在数万亿个字符上训练的,展示了如何仅使⽤公开可⽤的数据集来训练最先进的模型。

通义千问:阿⾥巴巴基于“通义”⼤模型研发,于 2023 年 4 ⽉ 正式发布。⽬前,已经开源了 7 种模型⼤⼩:0.5B、1.8B、4B、7B、14B 、72B 的 Dense 模型和 14B (A2.7B)的 MoE 模型;所有模型均⽀持⻓度为 32768 token 的上下⽂
GLM 系列模型:清华⼤学和智谱 AI 等合作研发的语⾔⼤模型。2023 年 3 ⽉ 发布了 ChatGLM。
Baichuan :是由百川智能开发的开源可商⽤的语⾔⼤模型。其基于Transformer 解码器架构(decoder-only)。
②LLM的涌现能⼒(emergent abilities)
区分⼤语⾔模型(LLM)与以前的预训练语⾔模型(PLM)最显著的特征之⼀是它们的 涌现能⼒ 。涌现能⼒是⼀种令⼈惊讶的能⼒,它在⼩型模型中不明显,但在⼤型模型中特别突出。类似物理学中的相变现象,涌现能⼒就像是模型性能随着规模增⼤⽽迅速提升。以下是三种核心能力:
(1)上下⽂学习(ICL):上下⽂学习能⼒是由 GPT-3 ⾸次引⼊的。这种能⼒允许语⾔模型在提供⾃然语⾔指令或多个任务示例的情况下,通过理解上下⽂并⽣成相应输出的⽅式来执⾏任务。模型不用微调,仅仅通过在输入时给它几个例子,它就能学会并执行一个新任务。
(2)指令遵循:通过使⽤⾃然语⾔描述的多任务数据进⾏微调,也就是所谓的 指令微调 。这意味着 LLM 能够根据任务指令执⾏任务,⽽⽆需事先⻅过具体示例, 通过对“指令-回复”数据进行微调,LLM变得非常听话,能直接理解并执行它从未见过的任务指令,这说明它的泛化能力极强。
下面是补充:

(3)逐步推理:⼩型语⾔模型通常难以解决涉及多个推理步骤的复杂任务,例如数学问题。然⽽,LLM 通过采⽤ 思维链(CoT, Chain of Thought) 推理策略,利⽤包含中间推理步骤的提示机制来解决这些任务,从⽽得出最终答案。据推测,这种能⼒可能是通过对代码的训练获得的。
这三项能力共同构成了LLM如此强大和易用的基石:它能听懂你的指令(指令遵循),如果你愿意还可以给它几个例子让它学(上下文学习),并且对于难题它能展示出推理过程让你更信服(逐步推理)。
③LLM 的特点

④什么是Prompt
Prompt 最初是 NLP研究者为下游任务设计出来的⼀种任务专属的输⼊模板**,类似于⼀种任务(例如:分类,聚类等)会对应⼀种 Prompt**。在 ChatGPT 推出并获得⼤量应⽤之后,Prompt 开始被推⼴为给⼤模型的所有输⼊。即,我们每⼀次访问⼤模型的输⼊为⼀个 Prompt,

可以看出一个优秀的Prompt是获得好效果的一个关键,所以Prompt Engineering(提示工程) 是一门设计与优化输入文本(称为“Prompt”或“提示”)的艺术和科学,其目的是为了从大型语言模型(LLM)中更有效、更可靠地获得符合期望的输出结果。也就是说怎么向大模型更好地提问
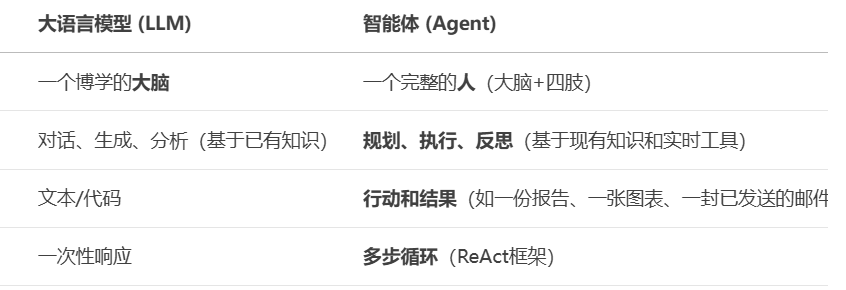
二 RAG(降低大模型出现幻觉的概率)
检索增强⽣成(RAG, Retrieval-Augmented Generation)。该架构巧妙地整合了从庞⼤知识库中检索到的相关信息,并以此为基础,指导⼤型语⾔模型⽣成更为精准的答案,从⽽显著提升了回答的准确性与深度。感觉就是ICL的升级版。RAG 是⼀个完整的系统,其⼯作流程可以简单地分为数据处理、检索、增强和⽣成四个阶段:
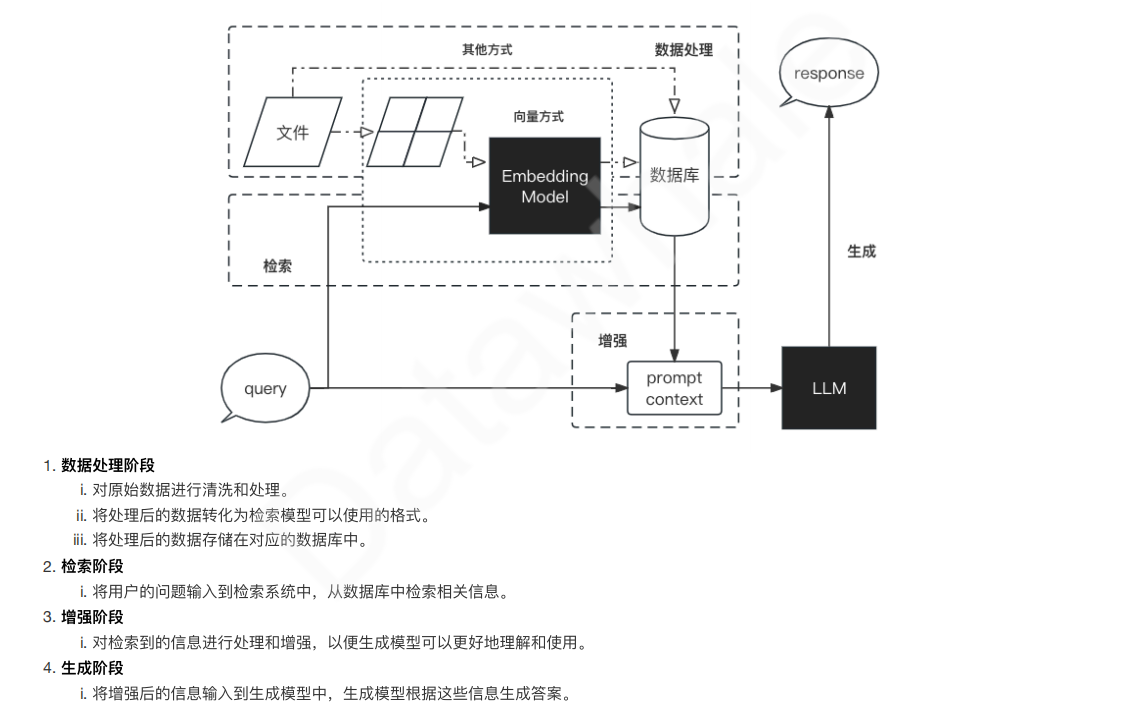
以下是一个RAG的例子:用户提出问题Query——将问题进行词嵌入以后在向量数据库里面找出语义相似的信息——把搜索出的内容和问题一起组成一个prompt——把这个prompt丢给模型生成答案
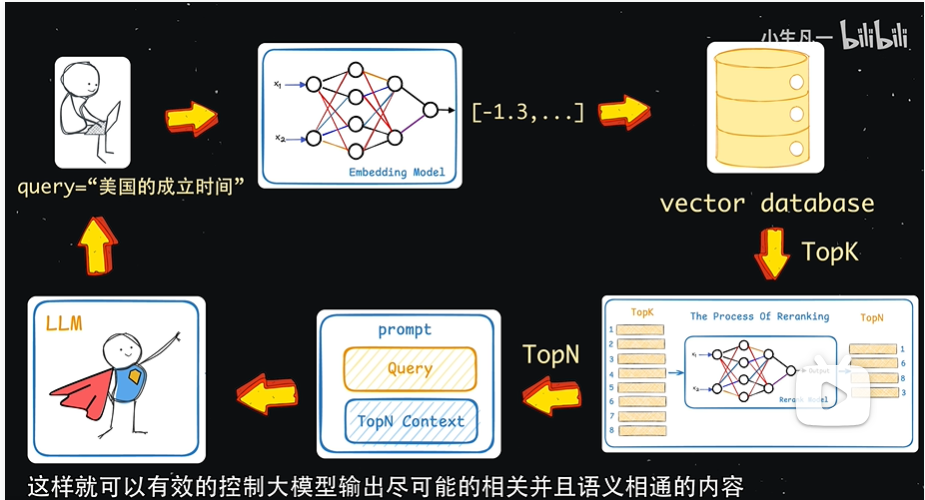
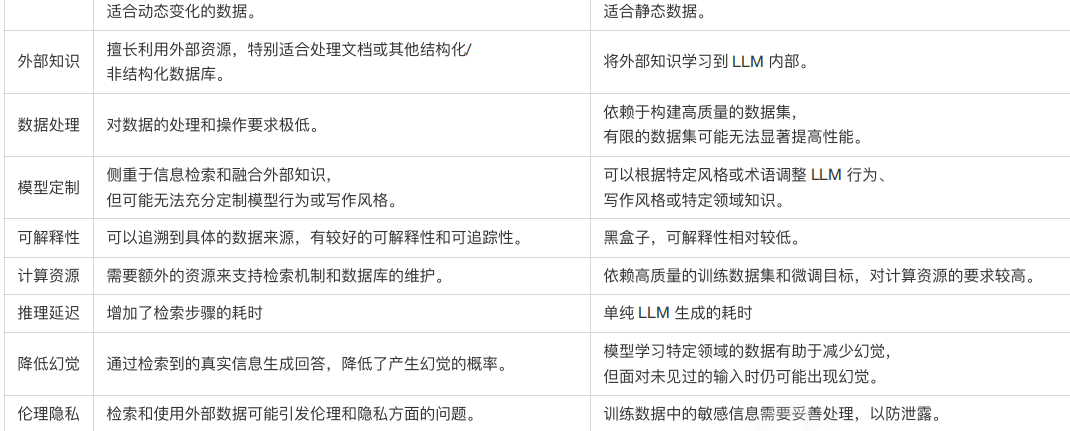
在提升⼤语⾔模型效果中,RAG 和 微调(Finetune)是两种主流的⽅法。微调是通过在特定数据集上进⼀步训练⼤语⾔模型,来提升模型在特定任务上的表现。以下是两种方法的对比:

三 LangChain
LangChain 框架是⼀个开源⼯具,充分利⽤了⼤型语⾔模型的强⼤能⼒,以便开发各种下游应⽤。它的⽬标是为各种⼤型语⾔模型应⽤提供通⽤接⼝,从⽽简化应⽤程序的开发流程。具体来说,LangChain 框架可以实现数据感知和环境互动,也就是说,它能够让语⾔模型与其他数据来源连接,并且允许语⾔模型与其所处的环境进⾏互动。
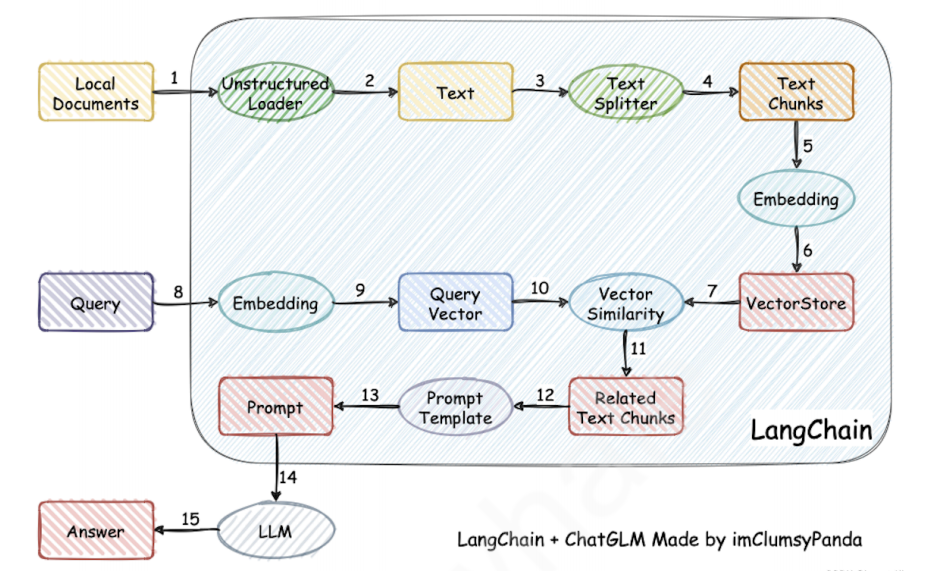
LangChain 的核⼼组件如下:
LangChian 作为⼀个⼤语⾔模型开发框架,可以将 LLM 模型(对话模型、embedding 模型等)、向量数据库、交互层 Prompt、外部知识、外部代理⼯具整
合到⼀起,进⽽可以⾃由构建 LLM 应⽤。 LangChain 主要由以下 6 个核⼼组件组成:

可以将⼤模型开发分解为以下⼏个流程:
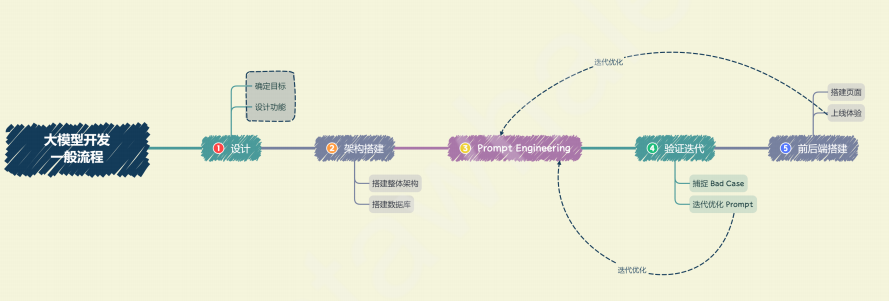
下面是对上面图的一些相关的补充:
①搭建整体架构。⽬前,绝⼤部分⼤模型应⽤都是采⽤的特定数据库 + Prompt + 通⽤⼤模型的架构。⼀般来说,我们推荐基于 LangChain 框架进⾏开发。
②搭建数据库。个性化⼤模型应⽤需要有个性化数据库进⾏⽀撑。由于⼤模型应⽤需要进⾏向量语义检索,⼀般使⽤诸如 Chroma 的向量数据库。在该步骤中,我们需要收集数据并进⾏预处理,再向量化存储到数据库中。数据预处理⼀般包括从多种格式向纯⽂本的转化
③Prompt Engineering:怎么给一个优质的Prompt,优质的 Prompt 对⼤模型能⼒具有极⼤影响,
④Agent:这个可以和强化学习的Agent做个对比,感觉差不多