构建AI智能体:十六、构建本地化AI应用:基于ModelScope与向量数据库的文本向量化
将文本转换为向量(文本嵌入)是自然语言处理中的核心任务,有许多大模型可以完成这项工作。上一篇文章《构建AI智能体:十五、超越关键词搜索:向量数据库如何解锁语义理解新纪元》我们是通过阿里云的api调用的text-embedding-v4模型,同样还有很多其他轻量级的模型可以很好的完成这个任务,我们今天找两个结合前期讲到的本地化部署来尝试一下。
一、核心组件回顾
-
ModelScope(魔搭):阿里云推出的模型即共享平台,定位为中国版的“Hugging Face”,优势是丰富的预训练中文模型、国内下载速度快、阿里达摩院支持
-
向量:在AI和机器学习领域,向量是一组数字的有序列表,可以表示任何数据对象(如一段文字、一张图片)在高维空间中的位置。
-
嵌入(Embedding):通过AI模型(如BERT、CNN、CLIP等)将非结构化数据转换为向量的过程,称为“嵌入”。这个转换过程捕获了数据的深层语义特征。
-
向量数据库:是一种专门用于存储、索引和查询高维向量的数据库。它的核心功能是执行近似最近邻(ANN)搜索,即快速找到与查询向量最相似的向量集合。
二、从文本到向量检索的完整流程
-
核心步骤分解:
-
文本预处理
-
本地嵌入模型加载与推理
-
向量生成与规范化
-
向量存储与索引构建
-
查询处理与相似性搜索
-
三、句子嵌入模型介绍
1. paraphrase-MiniLM-L6-v2模型
paraphrase-MiniLM-L6-v2 是 SentenceTransformers 库中一个非常受欢迎且高效的句子嵌入模型。它的名字可以拆解来看:
-
paraphrase: 意味着它在“释义”(paraphrase)任务上进行了优化训练。即,它非常擅长判断两个句子是否语义相同但表述不同。
-
MiniLM: 指其基于 MiniLM 架构。这是一种通过知识蒸馏技术,将大型语言模型(如 BERT、RoBERTa)的知识压缩到更小模型中的方法。它保留了老师模型的大部分性能,但体积更小、速度更快。
-
L6: 代表这个模型有 6 层(Layer)。作为对比,原始的 bert-base 模型有 12 层。层数减少是模型变轻量的主要原因之一。
-
v2: 代表版本号。
核心特点
-
轻量且高效:
-
参数量: 约 22.7 million(2270万)个参数。
-
体积: 模型文件大约 90 MB。
-
速度: 由于其小巧的尺寸,它在 CPU 和 GPU 上都能进行非常快速的推理(编码句子为向量),非常适合对延迟敏感的应用。
-
-
高质量的语义表示:
-
尽管模型很小,但得益于 MiniLM 蒸馏技术,它在语义相似度任务上的表现非常出色,甚至可以媲美一些更大的模型(如基于 BERT-base 的模型)。
-
它生成的句子向量能够很好地捕获句子的核心语义信息。
-
-
通用性强:虽然是为“释义”任务优化的,但其生成的通用句子向量在多种下游任务中都有良好表现,例如:
-
语义搜索(Semantic Search)
-
信息检索(Information Retrieval)
-
聚类(Clustering)
-
文本分类(Text Classification)的特征输入
-
重复数据删除(Deduplication)
-
-
输出维度:
-
它将任何长度的文本转换为一个固定大小的 384 维的浮点数向量。
-
2. all-MiniLM-L6-v2 模型
all-MiniLM-L6-v2 是 SentenceTransformers 库中的一个通用文本嵌入模型。它的名字是其核心特征的缩写:
-
all: 意味着它是一个通用模型,旨在对各种类型的文本和任务都能产生高质量的向量表示,而不仅仅是为某个特定任务(如释义)优化的。
-
其他属性同上
核心特点:
-
轻量级与高性能的完美平衡
-
参数量: 约 22.7 million(2270万)。
-
体积: 模型文件仅约 90 MB。非常易于下载、存储和部署。
-
速度: 在 CPU 和 GPU 上都能进行极快的推理(编码)。这对于需要实时或批量处理大量文本的应用(如搜索、推荐)至关重要。
-
性能: 尽管模型很小,但得益于高效的蒸馏技术,它在许多标准基准测试中的表现可以媲美甚至超越一些更大的模型(如原始的 BERT-base)。
-
-
通用性强,它被训练用于捕捉句子的通用语义信息,因此在多种下游任务中都有良好表现,包括:
-
语义搜索: 找到与查询语句语义最相关的文档。
-
文本聚类: 将语义相似的句子或文档自动分组。
-
信息检索: 增强传统关键词搜索的能力。
-
文本分类与语义相似度计算: 作为机器学习模型的输入特征。
-
检索增强生成: 为 LLM 从知识库中检索相关上下文。
-
-
输出标准化
-
它将任何长度的文本转换为一个固定大小的 384 维的浮点数向量。这个维度在存储效率和处理速度之间取得了很好的平衡。
-
四、详细示例
1. 加载本地大模型的起因
今天在加载嵌入模型时,提示了异常OSError: We couldn't connect to 'https://huggingface.co' to load this file,大模型无法下载,提示是要从huggingface中下载模型,由于网络限制无法下载,于是考虑ModelScope中是否也可以找到此模型
运行代码:
from sentence_transformers import SentenceTransformer
# 1. 准备示例文档
documents = ["这是一个测试文档","我喜欢大模型做任务",
]
# 2. 加载嵌入模型(将文本转换为向量)
model = SentenceTransformer('paraphrase-MiniLM-L6-v2')
# 3. 生成文档向量
document_embeddings = model.encode(documents)
print(document_embeddings)提示异常:
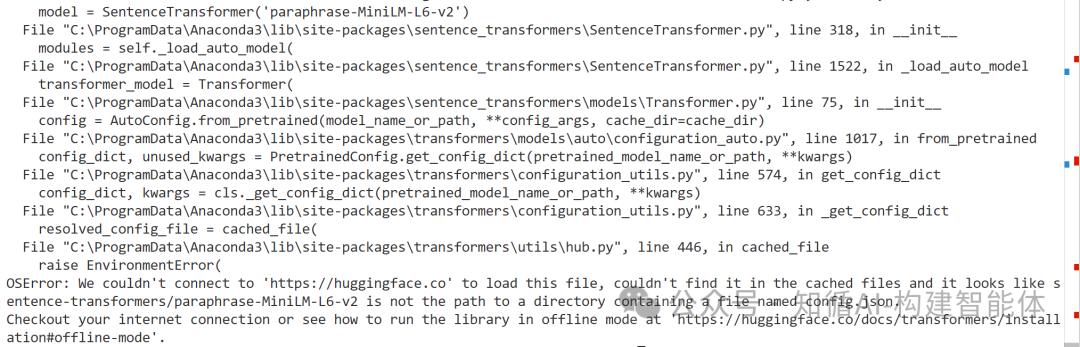
基于此,做其他方式的考虑,从ModelScope来加载模型!
2. 使用 sentence-transformers 库调用模型示例
参考代码:
from sentence_transformers import SentenceTransformer
from sklearn.metrics.pairwise import cosine_similarity
# 1. 加载模型(首次运行时会自动从Hugging Face Hub下载)
# model = SentenceTransformer('all-MiniLM-L6-v2')
# 此处我们配置为从本地路径加载
model = SentenceTransformer('D:/modelscope/hub/models/sentence-transformers/all-MiniLM-L6-v2')
# 2. 准备句子
sentences = ["The weather is nice today!","It's so sunny outside.","Dogs are great companions.","Cats are independent pets."
]
# 3. 编码句子,生成向量
embeddings = model.encode(sentences)
print(f"向量形状: {embeddings.shape}") # 输出: (4, 384)
# 4. 计算相似度(例如,计算第1句与所有句子的相似度)
similarities = cosine_similarity([embeddings[0]], embeddings)
print(f"相似度分数: {similarities}")输出结果:
向量形状: (4, 384)
相似度分数: [[0.9999999 0.5719301 0.16580734 0.00947747]]3. 模型先下载后加载,再执行向量化操作
先判断本地是否存在模型是否存在,存在就直接加载,不存在则通过modelscope下载到本地,然后生成文档向量,创建FAISS索引,进行查找,最后返回结果;

代码示例:
import os
from sentence_transformers import SentenceTransformer
from modelscope import snapshot_download
from pathlib import Path
import faiss
# 1. 准备示例文档
documents = ["猫是一种常见的宠物,喜欢抓老鼠","我喜欢写代码","狗是人类最好的朋友,忠诚可爱","Python是一种流行的编程语言,简单易学","人工智能正在改变世界,机器学习是其中重要部分","太阳系有八大行星,地球是其中之一"
]
def load_model(model_name='damo/nlp_corom_sentence-embedding_chinese-base', local_path=None):"""加载SentenceTransformer模型,优先使用ModelScope模型参数:model_name: ModelScope模型名称或本地路径local_path: 可选的本地模型路径"""try:if local_path and os.path.exists(local_path):# 从本地路径加载模型print(f"从本地路径加载模型: {local_path}")model = SentenceTransformer(local_path+"/"+model_name)else:# 从ModelScope加载模型(会自动下载如果不存在)print(f"加载ModelScope模型: {model_name}")print("如果本地没有缓存,将自动从ModelScope下载...")# 使用ModelScope下载模型到缓存目录model_dir = snapshot_download(model_name)print(f"模型已下载到: {model_dir}")# 从下载的目录加载模型model = SentenceTransformer(model_dir)print("模型加载成功!")return modelexcept Exception as e:print(f"模型加载失败: {e}")return None
def download_model_to_path(model_name, save_path):"""将ModelScope模型下载到指定路径参数:model_name: ModelScope模型名称save_path: 保存路径"""try:# 确保保存目录存在Path(save_path).mkdir(parents=True, exist_ok=True)# 使用ModelScope下载模型到指定路径print(f"下载ModelScope模型 {model_name} 到 {save_path}")model_dir = snapshot_download(model_name, cache_dir=save_path)# 加载模型model = SentenceTransformer(model_dir)print("模型下载并保存成功!")return modelexcept Exception as e:print(f"模型下载失败: {e}")return None
# 示例使用
if __name__ == "__main__":# 设置一些常用的中文模型选项model_options = {"base": "sentence-transformers/paraphrase-MiniLM-L6-v2"}# 2. 加载嵌入模型(将文本转换为向量)# 方式1: 直接加载基础中文模型(自动下载或使用缓存)# print("=== 方式1: 直接加载中文模型 ===")# model1 = load_model(model_options["base"])# if model1:# # 测试模型# embeddings = model1.encode(["这是一个测试句子"])# print(f"生成的向量维度: {embeddings.shape}")# 方式2: 下载到指定路径print("\n=== 方式2: 下载模型到指定路径 ===")model_path = "D:\modelscope\hub\models"model2 = download_model_to_path(model_options["base"], model_path)# 方式3: 从本地路径加载print("\n=== 方式3: 从本地路径加载模型 ===")model3 = load_model(model_name=model_options["base"],local_path=model_path)# # 测试其他模型# print("\n=== 测试小型中文模型 ===")# small_model = load_model(model_options["base"])if model3: # 3. 生成文档向量 document_embeddings = model3.encode(documents)# 4. 创建FAISS索引dimension = document_embeddings.shape[1]index = faiss.IndexFlatL2(dimension)index.add(document_embeddings.astype('float32'))# 5. 查询处理def search_similar_documents(query, k=5):# 将查询转换为向量query_embedding = model3.encode([query])# 搜索最相似的文档distances, indices = index.search(query_embedding.astype('float32'), k)# 返回结果results = []for i, idx in enumerate(indices[0]):results.append({"document": documents[idx],"similarity": 1 - distances[0][i] / 10 # 简单转换为相似度分数})return results# 测试查询query = "我喜欢编程"results = search_similar_documents(query)print("查询:", query)for result in results:print(f"相似文档: {result['document']} (相似度: {result['similarity']:.2f})")print(f"模型生成的向量维度: {document_embeddings.shape}")初次模型加载过程:
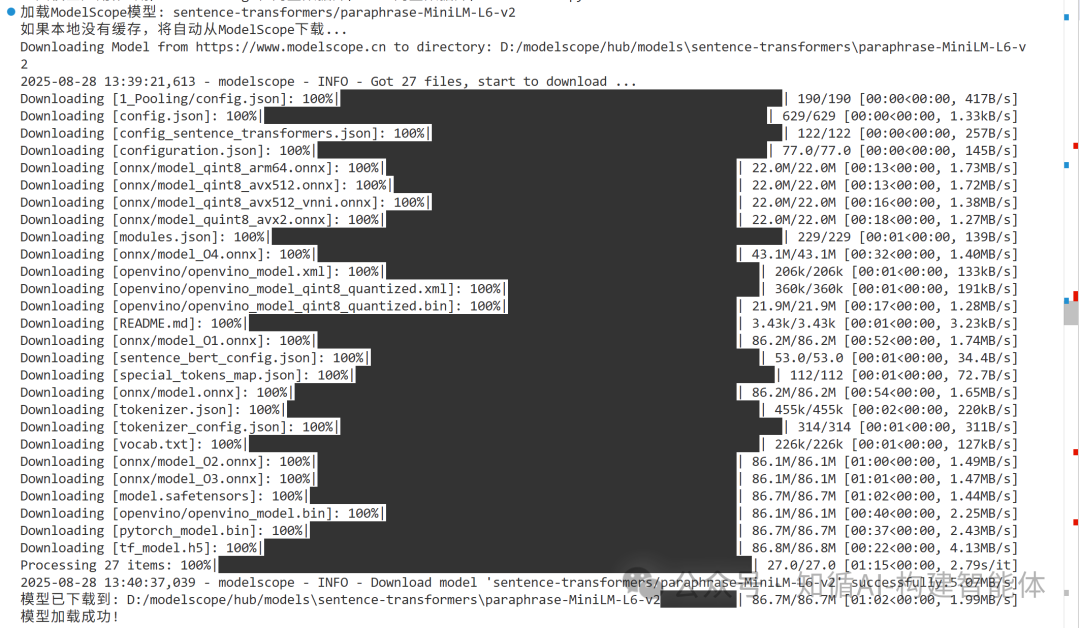
模型的本地化:
执行结果:
=== 方式2: 下载模型到指定路径 ===
下载ModelScope模型 sentence-transformers/paraphrase-MiniLM-L6-v2 到 D:\modelscope\hub\models
Downloading Model from https://www.modelscope.cn to directory: D:\modelscope\hub\models\sentence-transformers\paraphrase-MiniLM-L6-v2
模型下载并保存成功!
=== 方式3: 从本地路径加载模型 ===
从本地路径加载模型: D:\modelscope\hub\models
查询: 我喜欢编程
相似文档: 我喜欢写代码 (相似度: 0.71)
相似文档: 猫是一种常见的宠物,喜欢抓老鼠 (相似度: -2.62)
相似文档: 狗是人类最好的朋友,忠诚可爱 (相似度: -2.66)
相似文档: 人工智能正在改变世界,机器学习是其中重要部分 (相似度: -3.01)
相似文档: 太阳系有八大行星,地球是其中之一 (相似度: -3.06)
模型生成的向量维度: (6, 384)4. 完整版的FAISS 和 all-MiniLM-L6-v2 模型构建文本相似性搜索系统
步骤:
1. 安装必要的库:sentence-transformers和faiss-cpu(或faiss-gpu)
2. 加载模型
3. 准备示例文本数据
4. 将文本转换为向量
5. 构建FAISS索引
6. 进行相似性搜索
7. 输出结果
参考代码:
import numpy as np
import faiss
from sentence_transformers import SentenceTransformer
from typing import List, Dict, Tuple
import time
class FAISSTextSearch:def __init__(self, model_name: str = 'all-MiniLM-L6-v2'):"""初始化FAISS文本搜索系统参数:model_name: 使用的句子转换模型名称"""self.model_name = model_nameself.model = Noneself.index = Noneself.documents = [] # 存储原始文档self.dimension = 384 # all-MiniLM-L6-v2 输出384维向量def load_model(self):"""加载句子转换模型"""print(f"加载模型: {self.model_name}")self.model = SentenceTransformer(self.model_name)print("模型加载完成!")def create_index(self):"""创建FAISS索引"""# 使用内积(点积)作为相似度度量,因为all-MiniLM-L6-v2输出归一化向量# 对于归一化向量,内积等价于余弦相似度self.index = faiss.IndexFlatIP(self.dimension)print("FAISS索引创建完成!")def add_documents(self, documents: List[str]):"""添加文档到索引参数:documents: 文档列表"""if not self.model:self.load_model()if not self.index:self.create_index()print("生成文档向量...")# 将文档转换为向量embeddings = self.model.encode(documents, show_progress_bar=True)# 添加到索引self.index.add(embeddings.astype('float32'))# 保存原始文档self.documents.extend(documents)print(f"已添加 {len(documents)} 个文档到索引")def search(self, query: str, k: int = 5) -> List[Tuple[str, float]]:"""搜索与查询最相似的文档参数:query: 查询文本k: 返回最相似结果的数量返回:包含(文档, 相似度得分)的元组列表"""if not self.model or not self.index:raise ValueError("请先加载模型并创建索引")# 将查询转换为向量query_embedding = self.model.encode([query])# 在索引中搜索distances, indices = self.index.search(query_embedding.astype('float32'), k)# 处理结果results = []for i, idx in enumerate(indices[0]):if idx >= 0 and idx < len(self.documents): # 确保索引有效# 对于IndexFlatIP,距离实际上是相似度得分(值越大越相似)similarity_score = distances[0][i]results.append((self.documents[idx], similarity_score))return resultsdef save_index(self, filepath: str):"""保存FAISS索引到文件"""if self.index:faiss.write_index(self.index, filepath)print(f"索引已保存到: {filepath}")def load_index(self, filepath: str):"""从文件加载FAISS索引"""self.index = faiss.read_index(filepath)print(f"索引已从 {filepath} 加载")
def main():# 初始化文本搜索系统text_search = FAISSTextSearch()# 示例文档集 - 在实际应用中,您可以从文件或数据库中加载documents = ["狗是人类最好的朋友,忠诚可爱","猫是独立的宠物,喜欢抓老鼠","Python是一种流行的编程语言,简单易学","人工智能正在改变世界,机器学习是其中重要部分","太阳系有八大行星,地球是其中之一","深度学习是机器学习的一个分支,使用神经网络","自然语言处理使计算机能够理解和生成人类语言","计算机视觉让机器能够理解和分析图像和视频","大数据技术帮助我们从海量数据中提取有价值的信息","云计算提供了按需访问计算资源的能力"]# 添加文档到索引text_search.add_documents(documents)# 示例查询queries = ["编程语言","宠物动物","人工智能技术"]# 执行搜索并显示结果for query in queries:print(f"\n查询: '{query}'")print("-" * 50)start_time = time.time()results = text_search.search(query, k=3)search_time = time.time() - start_timefor i, (doc, score) in enumerate(results):print(f"{i+1}. {doc} (相似度: {score:.4f})")print(f"搜索耗时: {search_time:.4f}秒")# 保存索引以便后续使用text_search.save_index("faiss_index.bin")# 演示如何加载已保存的索引print("\n" + "="*50)print("演示加载已保存的索引")print("="*50)new_search = FAISSTextSearch()new_search.load_model()new_search.load_index("faiss_index.bin")# 添加相同的文档列表以保持索引与文档的映射new_search.documents = documents# 使用加载的索引进行搜索query = "机器学习"results = new_search.search(query, k=2)print(f"\n查询: '{query}'")for i, (doc, score) in enumerate(results):print(f"{i+1}. {doc} (相似度: {score:.4f})")
if __name__ == "__main__":main()本地模型展示:
输出结果:
加载模型: all-MiniLM-L6-v2
Downloading Model from https://www.modelscope.cn to directory: D:/modelscope/hub/models\sentence-transformers\all-MiniLM-L6-v2
模型加载完成!
FAISS索引创建完成!
生成文档向量...
Batches: 100%|█████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 17.61it/s]
已添加 10 个文档到索引
查询: '编程语言'
--------------------------------------------------
1. 猫是独立的宠物,喜欢抓老鼠 (相似度: 0.5080)
2. 云计算提供了按需访问计算资源的能力 (相似度: 0.4739)
3. 计算机视觉让机器能够理解和分析图像和视频 (相似度: 0.4547)
搜索耗时: 0.0071秒
查询: '宠物动物'
--------------------------------------------------
1. 猫是独立的宠物,喜欢抓老鼠 (相似度: 0.5080)
2. 云计算提供了按需访问计算资源的能力 (相似度: 0.4739)
3. 计算机视觉让机器能够理解和分析图像和视频 (相似度: 0.4547)
搜索耗时: 0.0120秒
查询: '人工智能技术'
--------------------------------------------------
1. 人工智能正在改变世界,机器学习是其中重要部分 (相似度: 0.7607)
2. 狗是人类最好的朋友,忠诚可爱 (相似度: 0.6547)
3. 猫是独立的宠物,喜欢抓老鼠 (相似度: 0.5278)
搜索耗时: 0.0100秒
索引已保存到: faiss_index.bin
==================================================
演示加载已保存的索引
==================================================
加载模型: all-MiniLM-L6-v2
Downloading Model from https://www.modelscope.cn to directory: D:/modelscope/hub/models\sentence-transformers\all-MiniLM-L6-v2
模型加载完成!
索引已从 faiss_index.bin 加载
查询: '机器学习'
1. 深度学习是机器学习的一个分支,使用神经网络 (相似度: 0.6921)
2. 人工智能正在改变世界,机器学习是其中重要部分 (相似度: 0.5984)这个示例展示了如何使用 FAISS 和 all-MiniLM-L6-v2 构建一个高效的文本相似性搜索系统。关键点包括:
-
使用 all-MiniLM-L6-v2 将文本转换为高质量的向量表示
-
使用 FAISS 创建高效的向量索引,支持快速相似性搜索
-
实现完整的文档添加、搜索和索引持久化功能
这个系统可以轻松扩展到处理数千甚至数百万个文档,适用于构建搜索引擎、推荐系统、文档去重等多种应用场景。
五、总结
今天是一个综合的应用扩展,整个流程结合了ModelScope的模型管理能力和FAISS的高效向量检索能力,为文本相似性搜索提供了一个完整的本地化解决方案,snapshot_download 函数是ModelScope的核心,model.encode() 是 sentence-transformers 库的标准化接口,无论模型来源是Hugging Face还是ModelScope,用法一致,降低了学习成本,扩展了整个思维体系,成长是个循序渐进的过程,需要推陈纳新,也需要举一反三。