Kotlin 协程之Channel 的高阶应用

前言
了解了 Channel 的基础概念和基本使用 后,我们再来看一看 Channel 的特性以及高阶应用。
Channel 是"热流"
热流概念
Channel 是热流(Hot Stream),具备以下特性:
-
数据的生产和消费是两套独立的流程
-
即使没有消费者,生产者也会继续生产数据
而在日常开发中常用到的 Flow 则是 冷流(Cold Stream) ,冷流只有在有订阅者时才开始产生数据。关于冷流的详细内容,在后续 Flow 相关的文章中再进行深入介绍。
代码示例:
suspend fun channelHot() {val channel = Channel<String>(Channel.BUFFERED)val sender = GlobalScope.launch {for (i in 1..5) {delay(100)channel.send(i.toString())println("\u001B[32m[生产者] 数据发送完毕: $i\u001B[0m")}}joinAll(sender)println("\u001B[36m ----结束---- \u001B[0m")
}
可以看到,虽然没有消费者,生产者也能继续发送数据。

Channel 的一对多、多对多应用模式
在上一篇 Kotlin Channel基础使用 中,我们的示例都是一对一的,即单个生产者向单个消费者发送数据。实际上,Channel 还支持实现一对多,多对一,多对多等模式
扇出模式(一对多)- 负载均衡
概念: 单个生产者发送数据,多个消费者竞争接收数据,每个数据只会被一个消费者处理。
特点:
-
每个数据只被一个消费者处理
-
消费者之间形成竞争关系
-
实现了自然的负载均衡
应用场景: 任务分发、负载均衡、并行处理
代码示例:
suspend fun singleProducerMultipleConsumers() {val channel = Channel<Int>(Channel.BUFFERED)// 单个生产者val producer = GlobalScope.launch {println("\u001B[32m[生产者] 开始生产任务...\u001B[0m")for (i in 1..10) {println("\u001B[32m[生产者] 发送任务: $i\u001B[0m")channel.send(i)delay(30) // 模拟生产时间}channel.close()println("\u001B[32m[生产者] 所有任务已发送完毕\u001B[0m")}// 多个消费者 - 每个消费者使用不同颜色val consumerColors = listOf("\u001B[34m", "\u001B[36m", "\u001B[31m") // 蓝色、青色、红色val consumers = List(3) { consumerId ->GlobalScope.launch {val color = consumerColors[consumerId]println("${color}[消费者-$consumerId] 准备接收任务...\u001B[0m")for (task in channel) {println("${color}[消费者-$consumerId] 处理任务: $task\u001B[0m")delay(300) // 模拟处理时间println("${color}[消费者-$consumerId] 任务 $task 处理完成\u001B[0m")}println("${color}[消费者-$consumerId] 没有更多任务,退出\u001B[0m")}}// 等待所有协程完成joinAll(producer, *consumers.toTypedArray())println("\u001B[36m ----结束---- \u001B[0m")
}

注意,是多个消费者 “瓜分” 数据
扇入模式(多对一)- 数据聚合
概念: 多个生产者向同一个 Channel 发送数据,单个消费者接收所有数据。
特点:
-
多个数据源汇聚到一个处理点
-
消费者按接收顺序处理所有数据
应用场景: 日志收集、数据汇总、多源数据聚合、监控指标收集
suspend fun multipleProducersSingleConsumer() {// 创建一个共享的Channel,用于接收来自多个生产者的数据val sharedChannel = Channel<String>(capacity = 10)// 启动多个生产者协程 val producerColors = listOf("\u001B[32m", "\u001B[33m", "\u001B[35m") // 绿色、黄色、洋红色val producers = List(3) { producerId ->GlobalScope.launch {val color = producerColors[producerId]repeat(5) { messageId ->val message = "Producer-$producerId: Message-$messageId"println("${color}[生产者$producerId] 发送: $message\u001B[0m")sharedChannel.send(message)delay(Random.nextLong(100, 500)) // 随机延迟模拟不同的生产速度}println("${color}[生产者$producerId] 完成发送\u001B[0m")}}// 启动单个消费者协程val consumer = GlobalScope.launch {var receivedCount = 0for (message in sharedChannel) {delay(200)println("\u001B[34m[消费者] 处理: $message 完毕\u001B[0m")receivedCount++}println("\u001B[34m[消费者] 完成接收,共处理 $receivedCount 条消息\u001B[0m")}// 等待所有生产者完成producers.joinAll()println("\u001B[36m所有生产者已完成\u001B[0m")// 关闭Channel,这样消费者的for循环才能正常结束sharedChannel.close()// 等待消费者完成consumer.join()println("\u001B[36m ----结束---- \u001B[0m")
}

多对多模式 - 高并发处理
概念: 多个生产者和多个消费者同时工作,结合了扇出和扇入的特点。
特点:
-
具备负载均衡能力(多消费者竞争)
-
支持高并发数据生产(多生产者)
-
通过缓冲区优化资源使用
-
适合处理大量并发任务
应用场景: 消息队列系统、任务分发系统、高并发数据处理
suspend fun multipleProducersMultipleConsumers() {// 创建一个共享的Channelval sharedChannel = Channel<String>(capacity = 5)val producerColors = listOf("\u001B[32m", "\u001B[33m") // 绿色、黄色val producers = List(2) { producerId ->GlobalScope.launch {val color = producerColors[producerId]repeat(8) { messageId ->val message = "Producer-$producerId: Task-$messageId"println("${color}[生产者$producerId] 发送任务: $message\u001B[0m")sharedChannel.send(message)delay(Random.nextLong(200, 600))}println("${color}[生产者$producerId] 完成任务发送\u001B[0m")}}// 启动多个消费者协程 val consumerColors = listOf("\u001B[34m", "\u001B[36m", "\u001B[31m") // 蓝色、青色、红色val consumers = List(3) { consumerId ->GlobalScope.launch {val color = consumerColors[consumerId]var processedCount = 0try {for (message in sharedChannel) {println("${color}[消费者$consumerId] 处理任务: $message\u001B[0m")delay(Random.nextLong(300, 800)) // 模拟任务处理时间processedCount++println("${color}[消费者$consumerId] 完成任务: $message\u001B[0m")}} catch (e: ClosedReceiveChannelException) {println("${color}[消费者$consumerId] Channel已关闭,共处理 $processedCount 个任务\u001B[0m")}}}// 等待所有生产者完成producers.joinAll()println("\u001B[36m所有生产者已完成,正在关闭Channel...\u001B[0m")// 关闭ChannelsharedChannel.close()// 等待所有消费者完成consumers.joinAll()println("\u001B[36m ----结束---- \u001B[0m")
}
对比
| 应用模式 | 生产者 | 消费者 | 数据流向 | 特点 | 应用场景 |
|---|---|---|---|---|---|
| 扇出模式 | 1个 | 多个 | 一对多 | 自动负载均衡,任务并行处理 | 工作队列、任务分发、并行计算 |
| 扇入模式 | 多个 | 1个 | 多对一 | 数据聚合,统一处理点 | 日志收集、数据汇总、监控指标聚合 |
| 多对多模式 | 多个 | 多个 | 多对多 | 最大化并发能力,结合扇出扇入优势 | 消息队列、高并发数据处理、分布式系统 |
Select 表达式
Select 概念与特性
Select 可以同时等待多个挂起操作,并处理最先完成的那个操作,在处理多个不确定耗时的异步任务时非常有用。
特性:
-
非阻塞选择:同时监听多个 Channel
-
竞争机制:处理最先到达的结果
Select 基本使用
suspend fun selectFastestResponse() {// 创建多个Channel模拟不同的数据源val apiChannel = Channel<String>()val databaseChannel = Channel<String>()val cacheChannel = Channel<String>()println("\u001B[36m[系统] 启动多数据源查询竞争...\u001B[0m")// 模拟API调用GlobalScope.launch {delay(Random.nextLong(500, 1500))val result = "API响应: 用户数据已获取"println("\u001B[33m[API任务] 完成查询: $result\u001B[0m")apiChannel.send(result)}// 模拟数据库查询GlobalScope.launch {delay(Random.nextLong(800, 2000))val result = "数据库响应: 查询结果已返回"println("\u001B[31m[数据库任务] 完成查询: $result\u001B[0m")databaseChannel.send(result)}// 模拟缓存查询GlobalScope.launch {delay(Random.nextLong(100, 800))val result = "缓存响应: 缓存命中,数据已返回"println("\u001B[32m[缓存任务] 完成查询: $result\u001B[0m")cacheChannel.send(result)}// 使用select选择最快的响应val startTime = System.currentTimeMillis()val fastestResult = select<String> {apiChannel.onReceive { result ->println("\u001B[33m[获胜者] API最快响应!\u001B[0m")result}databaseChannel.onReceive { result ->println("\u001B[31m[获胜者] 数据库最快响应!\u001B[0m")result}cacheChannel.onReceive { result ->println("\u001B[32m[获胜者] 缓存最快响应!\u001B[0m")result}}val endTime = System.currentTimeMillis()println("\u001B[36m[结果] 最快响应: $fastestResult\u001B[0m")println("\u001B[36m[性能] 响应时间: ${endTime - startTime}ms\u001B[0m")// 关闭所有ChannelapiChannel.close()databaseChannel.close()cacheChannel.close()println("\u001B[36m ----结束---- \u001B[0m")
}

Select 取消机制优化
在实际生产环境中,我们通常希望在获得最快响应后立即取消其他任务,以节省系统资源:
suspend fun selectFastestResponseWithCancel() {// 创建三个不同任务的channelval apiChannel = Channel<String>()val databaseChannel = Channel<String>()val cacheChannel = Channel<String>()println("\u001B[36m[系统] 开始执行多个异步任务,选择最快响应并取消其他任务...\u001B[0m")// 模拟API调用任务val apiTask = GlobalScope.launch {try {val responseTime = Random.nextLong(300, 1200) // 随机响应时间println("\u001B[33m[API任务] 开始调用远程API,预计耗时: ${responseTime}ms\u001B[0m")delay(responseTime)val result = "API响应数据: {userId: 456, name: 'Alice'}"apiChannel.send(result)println("\u001B[33m[API任务] 调用完成,耗时: ${responseTime}ms\u001B[0m")} catch (e: CancellationException) {println("\u001B[33m[API任务] 任务被取消\u001B[0m")throw e}}// 模拟数据库查询任务val databaseTask = GlobalScope.launch {try {val queryTime = Random.nextLong(400, 1000) // 随机查询时间println("\u001B[31m[数据库任务] 开始查询数据库,预计耗时: ${queryTime}ms\u001B[0m")delay(queryTime)val result = "数据库查询结果: {userId: 456, name: 'Alice', email: 'alice@example.com'}"databaseChannel.send(result)println("\u001B[31m[数据库任务] 查询完成,耗时: ${queryTime}ms\u001B[0m")} catch (e: CancellationException) {println("\u001B[31m[数据库任务] 任务被取消\u001B[0m")throw e}}// 模拟缓存查询任务val cacheTask = GlobalScope.launch {try {val cacheTime = Random.nextLong(100, 400) // 随机缓存访问时间println("\u001B[32m[缓存任务] 开始查询缓存,预计耗时: ${cacheTime}ms\u001B[0m")delay(cacheTime)val result = "缓存数据: {userId: 888, name: '喻志强', cached: true}"cacheChannel.send(result)println("\u001B[32m[缓存任务] 查询完成,耗时: ${cacheTime}ms\u001B[0m")} catch (e: CancellationException) {println("\u001B[32m[缓存任务] 任务被取消\u001B[0m")throw e}}// 使用select表达式选择最快响应的任务val startTime = System.currentTimeMillis()val result = select<String> {apiChannel.onReceive { data ->val elapsedTime = System.currentTimeMillis() - startTimeprintln("\u001B[36m[系统] API任务最先响应!耗时: ${elapsedTime}ms\u001B[0m")println("\u001B[36m[系统] 获取到数据: $data\u001B[0m")data}databaseChannel.onReceive { data ->val elapsedTime = System.currentTimeMillis() - startTimeprintln("\u001B[36m[系统] 数据库任务最先响应!耗时: ${elapsedTime}ms\u001B[0m")println("\u001B[36m[系统] 获取到数据: $data\u001B[0m")data}cacheChannel.onReceive { data ->val elapsedTime = System.currentTimeMillis() - startTimeprintln("\u001B[36m[系统] 缓存任务最先响应!耗时: ${elapsedTime}ms\u001B[0m")println("\u001B[36m[系统] 获取到数据: $data\u001B[0m")data}}println("\u001B[36m[系统] 选择最快响应完成,使用结果: $result\u001B[0m")// 主动取消其他正在执行的任务println("\u001B[36m[系统] 开始取消其他未完成的任务...\u001B[0m")if (apiTask.isActive) {println("\u001B[36m[系统] 正在取消API任务...\u001B[0m")apiTask.cancel()}if (databaseTask.isActive) {println("\u001B[36m[系统] 正在取消数据库任务...\u001B[0m")databaseTask.cancel()}if (cacheTask.isActive) {println("\u001B[36m[系统] 正在取消缓存任务...\u001B[0m")cacheTask.cancel()}// 关闭channelsapiChannel.close()databaseChannel.close()cacheChannel.close()println("\u001B[36m ----结束---- \u001B[0m")
}

Select 超时处理机制
在某些场景中,我们需要为异步操作设置超时限制,避免无限等待影响系统性能。Select 表达式结合 withTimeoutOrNull可以优雅地实现超时控制机制。
关键点:
- 时间控制:通过
withTimeoutOrNull设置最大等待时间 - 优雅降级:超时时返回 null,可以实现降级策略
- 资源清理:超时后自动取消所有未完成的任务
- 用户体验:避免用户长时间等待,提供及时反馈
suspend fun selectWithTimeout() {// 创建三个不同任务的channelval apiChannel = Channel<String>()val databaseChannel = Channel<String>()val cacheChannel = Channel<String>()println("\u001B[36m[系统] 启动带超时控制的多任务查询(超时时间: 100毫秒)...\u001B[0m")println("\u001B[36m[系统] 实际应用场景:Web API响应、数据库查询、缓存查询等\u001B[0m")// 模拟API调用任务(可能较慢)val apiTask = GlobalScope.launch {try {val responseTime = Random.nextLong(800, 2000) // 可能超时的响应时间println("\u001B[33m[API任务] 开始调用远程API,预计耗时: ${responseTime}ms\u001B[0m")delay(responseTime)val result = "API响应: {userId: 789, name: 'Bob', source: 'remote'}"apiChannel.send(result)println("\u001B[33m[API任务] 调用完成,耗时: ${responseTime}ms\u001B[0m")} catch (e: CancellationException) {println("\u001B[33m[API任务] 任务被取消(超时处理)\u001B[0m")throw e}}// 模拟数据库查询任务(可能较慢)val databaseTask = GlobalScope.launch {try {val queryTime = Random.nextLong(600, 1800) // 可能超时的查询时间println("\u001B[31m[数据库任务] 开始查询数据库,预计耗时: ${queryTime}ms\u001B[0m")delay(queryTime)val result = "数据库响应: {userId: 789, name: 'Bob', email: 'bob@example.com', source: 'database'}"databaseChannel.send(result)println("\u001B[31m[数据库任务] 查询完成,耗时: ${queryTime}ms\u001B[0m")} catch (e: CancellationException) {println("\u001B[31m[数据库任务] 任务被取消(超时处理)\u001B[0m")throw e}}// 模拟缓存查询任务(通常较快)val cacheTask = GlobalScope.launch {try {val cacheTime = Random.nextLong(200, 1200) // 缓存访问时间println("\u001B[32m[缓存任务] 开始查询缓存,预计耗时: ${cacheTime}ms\u001B[0m")delay(cacheTime)val result = "缓存响应: {userId: 666, name: 'XeonYu', cached: true, source: 'cache'}"cacheChannel.send(result)println("\u001B[32m[缓存任务] 查询完成,耗时: ${cacheTime}ms\u001B[0m")} catch (e: CancellationException) {println("\u001B[32m[缓存任务] 任务被取消(超时处理)\u001B[0m")throw e}}// 使用withTimeoutOrNull实现超时控制val startTime = System.currentTimeMillis()val result = withTimeoutOrNull(100) { //设置超时时间select<String> {apiChannel.onReceive { data ->val elapsedTime = System.currentTimeMillis() - startTimeprintln("\u001B[36m[系统] API任务响应成功!耗时: ${elapsedTime}ms\u001B[0m")data}databaseChannel.onReceive { data ->val elapsedTime = System.currentTimeMillis() - startTimeprintln("\u001B[36m[系统] 数据库任务响应成功!耗时: ${elapsedTime}ms\u001B[0m")data}cacheChannel.onReceive { data ->val elapsedTime = System.currentTimeMillis() - startTimeprintln("\u001B[36m[系统] 缓存任务响应成功!耗时: ${elapsedTime}ms\u001B[0m")data}}}val totalTime = System.currentTimeMillis() - startTime// 处理超时情况if (result != null) {println("\u001B[36m[系统] 获取到数据: $result\u001B[0m")println("\u001B[36m[系统] 总响应时间: ${totalTime}ms(在超时限制内)\u001B[0m")} else {println("\u001B[36m[系统] 所有任务均超时,启用降级策略\u001B[0m")println("\u001B[36m[系统] 返回默认数据: {userId: 000, name: 'Unknown', source: 'default'}\u001B[0m")}// 取消所有未完成的任务println("\u001B[36m[系统] 清理资源,取消未完成的任务...\u001B[0m")apiTask.cancel()databaseTask.cancel()cacheTask.cancel()// 关闭channelsapiChannel.close()databaseChannel.close()cacheChannel.close()println("\u001B[36m ----结束---- \u001B[0m")
}

把超时时间设置为 1 秒再看看执行结果

CoroutineScope.produce & CoroutineScope.actor
除了直接通过顶层函数 Channel() 创建通道,Kotlin 还提供了 produce 和 actor 两个构建器函数。
为什么需要 produce 和 actor?
核心原因在于返回值类型的差异。
返回值类型对比
1. Channel() 函数
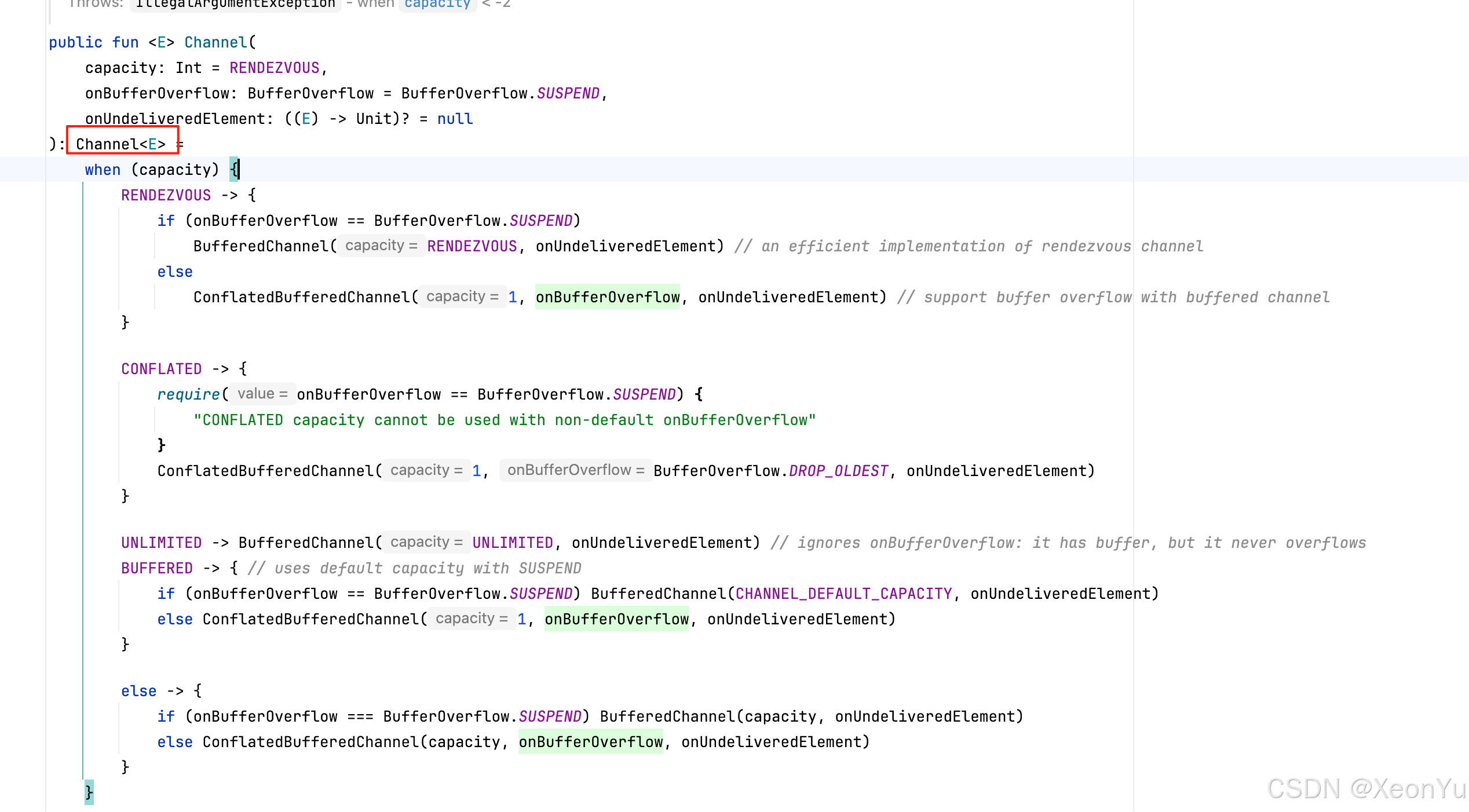
Channel() 函数返回 Channel<E> 类型的一个实例

Channel 继承了 SendChannel<E> 和 ReceiveChannel<E> 接口,既可发送又可接收。
2. produce 构建器

produce 返回 ReceiveChannel<E>,只能接收数据。
3. actor 构建器

actor 返回 SendChannel<E>,只能发送数据。
Channel 三层接口架构
Channel 接口的设计非常巧妙,采用了三层接口分离结合泛型逆变和协变的设计:
// 发送端接口 - 逆变泛型,只能发送 E 或其子类型
public interface SendChannel<in E>// 接收端接口 - 协变泛型,只能接收 E 或其父类型
public interface ReceiveChannel<out E>// 双向通道接口 - 不变泛型,既能发送又能接收 E
public interface Channel<E> : SendChannel<E>, ReceiveChannel<E>
好处:
-
接口隔离原则(ISP):发送和接收功能完全分离,避免接口污染
-
类型安全保障:通过协变和逆变确保数据流向的类型安全
-
职责清晰分离:不同角色只需关注相关接口,降低复杂度
实际应用场景
在架构设计中,当你需要向团队提供 API 时,往往希望限制调用者的操作权限,如果直接暴露 Channel 类型,调用者可以同时进行发送和接收操作,这可能违背你的设计意图,因为你没办法控制调用者的行为,通过返回受限的接口类型,就可以 精确控制调用者的操作范围
produce 构建器示例
当你希望调用者只能接收数据时:
// 架构开发者:使用produce构建器封装数据流处理逻辑
fun createDataStream(): ReceiveChannel<String> {println("\u001B[35m[架构层] 使用produce构建器封装复杂的数据处理逻辑\u001B[0m")return GlobalScope.produce(capacity = 3) {// 架构层复杂逻辑:数据获取、转换、验证等repeat(5) { batch ->// 模拟复杂的数据处理流程val rawData = "raw_data_$batch"val processedData = "DataBatch-$batch: [validated, transformed, enriched]"println("\u001B[35m[架构层] 处理原始数据: $rawData -> $processedData\u001B[0m")send(processedData) // 只有架构层可以发送数据delay(200)}// produce自动管理资源清理println("\u001B[35m[架构层] produce自动清理内部资源\u001B[0m")}
}suspend fun produceBuilderExample() {// 业务开发者:获得受限的ReceiveChannel接口val dataStream: ReceiveChannel<String> = createDataStream()println("\u001B[34m[业务开发者] 获得ReceiveChannel,只能接收数据\u001B[0m")// 业务开发者只能进行接收操作println("\u001B[34m[业务层] 开始处理数据流\u001B[0m")for (data in dataStream) {println("\u001B[34m[业务层] 接收并处理: $data\u001B[0m")delay(100)}
}
actor 构建器示例
当你希望调用者只能发送数据时
// 使用actor构建器封装数据处理逻辑
fun createDataProcessor(): SendChannel<String> {println("\u001B[35m[架构层] 使用actor构建器封装数据处理管道\u001B[0m")return GlobalScope.actor(capacity = 5) {// 架构层复杂逻辑:数据接收、验证、存储等var processedCount = 0for (rawData in channel) { // actor内部可以接收数据processedCount++// 模拟复杂的数据处理流程val validatedData = "Validated: $rawData"val transformedData = "Transformed: $validatedData"val storedData = "Stored: $transformedData [ID: $processedCount]"println("\u001B[35m[架构层] 处理数据管道: $rawData -> $storedData\u001B[0m")delay(150) // 模拟处理时间// 这里可以进行数据库存储、文件写入等操作println("\u001B[35m[架构层] 数据处理完成: $storedData\u001B[0m")}// actor自动管理资源清理println("\u001B[35m[架构层] actor自动清理内部资源,共处理 $processedCount 条数据\u001B[0m")}
}suspend fun actorBuilderExample() {// 业务开发者:获得受限的SendChannel接口val dataProcessor: SendChannel<String> = createDataProcessor()println("\u001B[34m[业务开发者] 获得SendChannel,只能发送数据\u001B[0m")// 业务开发者只能进行发送操作println("\u001B[34m[业务层] 开始发送数据到处理管道\u001B[0m")repeat(6) { index ->val businessData = "BusinessData-$index: {orderId: ${1000 + index}, amount: ${(index + 1) * 100}}"println("\u001B[34m[业务层] 发送业务数据: $businessData\u001B[0m")dataProcessor.send(businessData)delay(80)}// 业务层完成数据发送后关闭通道dataProcessor.close()println("\u001B[34m[业务层] 数据发送完成,关闭通道\u001B[0m")}
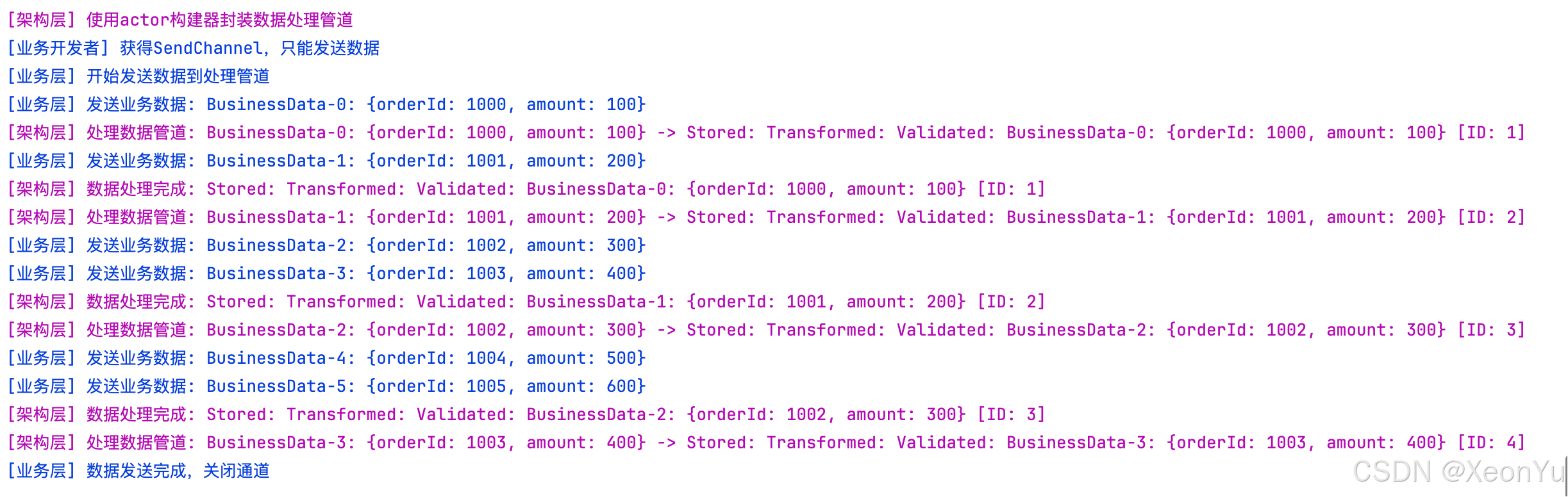
produce vs actor 对比
| 特性 | produce | actor |
|---|---|---|
| 返回类型 | ReceiveChannel<E> | SendChannel<E> |
| 外部操作 | 只能接收数据 | 只能发送数据 |
| 内部逻辑 | 生产数据并发送 | 接收数据并处理 |
| 数据流向 | 内部 → 外部 | 外部 → 内部 |
| 适用场景 | 数据生成、API 封装 | 数据处理、消息处理 |
| 接口隔离 | 隐藏生产逻辑 | 隐藏处理逻辑 |
| 类型安全 | 协变 out E | 逆变 in E |
总结
关于热流这个特性
Channel 是热流,这意味着什么?简单说就是生产者不等人。不管有没有消费者在那儿等着,生产者该干嘛干嘛,数据照样往Channel 里塞。
这个特性在实际开发中特别有用。比如你在做日志收集系统,不管有没有消费日志,日志数据肯定是持续产生的, Channel 的热流特性正好匹配到这个场景。
几种应用模式的实际体验
扇出模式(一对多):这个应用场景是比较多的,特别是在处理任务队列的时候。一个生产者疯狂塞任务,多个消费者抢着处理,天然的负载均衡。不用你写什么复杂的分发逻辑,Channel 自己就搞定了。
扇入模式(多对一):日志收集的时候经常用到。多个服务往一个 Channel 里扔日志,一个消费者统一处理。简单粗暴,但很有效。
多对多模式:这个就是前两种的结合体,适合高并发场景。不过说实话,复杂度也上去了,一般也不会用到。
Select 表达式:这个还是非常实用的,可以同时等到多个 Channel,谁先有数据就处理谁。配合超时机制,可以做很多有趣的事情。比如同时查缓存、数据库、API,谁快用谁的,其他的直接取消。
produce 和 actor 的设计思路
刚开始我也不理解为什么要搞这两个构建器,直接用 Channel() 不香吗?后来在实际项目中才体会到接口隔离的重要性。
想象一下,你给团队提供一个数据流 API,如果直接返回 Channel,别人既能往里发数据,又能从里面取数据。这不就乱套了吗?
用 produce 返回 ReceiveChannel,别人只能取数据;用 actor 返回 SendChannel,别人只能发数据。权限控制得明明白白。
这种设计在大型项目中特别有用,可以避免很多不必要的 bug。
Channel 到 Flow
学完 Channel 之后,你会发现它解决了很多并发场景的问题。但是 Channel 作为热流,有个问题就是资源消耗。即使没有消费者,生产者也在那儿工作,这在某些场景下是浪费的。
这时候就该 Flow(冷流) 出场了。Flow 只有在被订阅的时候才开始工作,更节省资源。而且 Flow 有更丰富的操作符,可以做各种数据变换。
而且 kotlin 还提供了 StaredFlow 和 StateFlow 这两个非常实用的数据流,因此,在日常开发中,我们可能更多的是选择 Flow。
掌握了 Channel,再去学 Flow 会轻松很多。因为很多概念是相通的,只是应用场景不同而已。
好了, 本篇文章就是这些,希望能帮到你。
感谢阅读,如果对你有帮助请三连(点赞、收藏、加关注)支持。有任何疑问或建议,欢迎在评论区留言讨论。如需转载,请注明出处:喻志强的博客