【Big Data】Presto db 一种语言、一个接口搭建可靠、高效数据湖仓
PrestoDB是由Facebook开发的开源分布式SQL查询引擎,专为解决海量数据(从GB到PB级别)的实时交互式分析问题而设计。它采用MPP(大规模并行处理)架构,通过协调器节点和工作节点协同工作,将复杂的SQL查询转化为分布式计算任务,实现低延迟的查询响应(通常为秒级到分钟级)。与Hive/MapReduce相比,PrestoDB在性能上提升了10倍以上,能够满足分析师、数据科学家和工程师对快速数据查询的需求 。PrestoDB的核心优势在于其原生支持ANSI SQL标准、跨数据源查询能力、基于内存的流水线处理架构以及灵活的资源扩展能力,使其成为大数据分析领域的关键工具。
1. 什么是 Presto?
Presto 是一款开源的分布式 SQL 查询引擎,核心定位是 “针对海量数据的低延迟交互式查询”,注意:它不是数据库,不负责存储数据,而是通过连接多种数据源(如 HDFS、Hive、MySQL、Kafka 等),实现跨数据源的统一 SQL 查询。
关键认知点:
- 无存储依赖:Presto 本身不存储任何数据,所有数据均来自外部数据源,查询时直接从数据源读取数据并计算;
- SQL 兼容性:完全兼容 ANSI SQL 标准,支持复杂查询(如 JOIN、子查询、窗口函数),开发人员无需学习新语法;
- 场景定位:主打 “交互式查询”,适用于数据分析、报表生成、Ad-hoc 查询等需要低延迟(秒级到分钟级)的场景,而非高并发写入场景;
- 数据源广度:支持超过 30 种数据源,包括关系型数据库(MySQL、PostgreSQL)、大数据存储(Hive、Hudi、Iceberg)、消息队列(Kafka)、对象存储(S3、OSS)等。
2. Presto 的诞生背景:解决大数据查询的 “延迟痛点”
Presto 的诞生,源于 Facebook(现 Meta)在 2012 年面临的大数据查询困境,我们从 “痛点 - 需求 - 解决方案” 三个维度拆解:
2.1 当时的行业痛点
2012 年前后,大数据领域已形成以 Hadoop 为核心的生态,但数据查询工具存在明显短板:
- Hive 查询延迟极高:Hive 基于 MapReduce 计算框架,适合离线批处理,但一次简单查询可能需要几分钟甚至几小时,无法满足交互式分析需求;
- 传统 MPP 数据库局限:如 Teradata、Greenplum 等,虽支持低延迟查询,但扩展性差(难以应对 PB 级数据),且无法跨多种数据源查询;
- 多源数据查询繁琐:企业数据分散在 Hive、MySQL、HBase 等不同存储中,若要跨源查询,需先通过 ETL 将数据同步到统一存储,流程复杂且实时性差。
2.2 Facebook 的核心需求
Facebook 内部有大量分析师需要对 PB 级用户数据(如社交行为、广告数据)进行实时分析,需要一款工具满足:
- 支持 PB 级数据查询;
- 延迟控制在秒级到分钟级;
- 兼容 SQL,降低分析师学习成本;
- 能连接 Hive、HBase 等多种内部数据源。
2.3 Presto 的诞生与发展
- 2012 年:Facebook 内部启动 Presto 项目,由 Eric Hwang、Dain Sundstrom 等工程师主导开发;
- 2013 年:Presto 在 Facebook 内部落地,支持每天超过 3000 名分析师的查询需求,单查询可处理 PB 级数据,延迟降至秒级;
- 2013 年 11 月:Facebook 开源 Presto,吸引 Netflix、Airbnb、Twitter 等企业参与贡献;
- 2019 年:Presto 社区分裂为两大分支 ——Presto SQL(后更名为 Trino)和 PrestoDB,两者核心架构一致,功能略有差异(后续对比部分会提及);
- 至今:Presto 已成为大数据生态中 “低延迟查询” 的核心工具,广泛应用于互联网、金融、电商等领域。

3. Presto 的架构设计:分布式查询的 “协同逻辑”
Presto 采用 “主从架构”,核心组件包括 Coordinator(协调器)、Worker(工作节点)、Discovery Service(服务发现),以及连接不同数据源的 Connector(连接器)。整体架构简洁高效,我们逐一拆解:
3.1 核心组件及作用
| 组件 | 作用 |
| Coordinator | 集群 “大脑”:负责接收查询请求、解析 SQL、生成执行计划、分配任务给 Worker、汇总结果 |
| Worker | 集群 “手脚”:负责执行 Coordinator 分配的任务(如数据读取、过滤、聚合、JOIN)、返回中间结果 |
| Discovery Service | 服务注册与发现:Worker 启动后向其注册,Coordinator 通过它获取集群中可用的 Worker 列表(通常集成在 Coordinator 中,无需单独部署) |
| Connector | 数据源连接器:Presto 通过 Connector 与外部数据源交互,每个 Connector 对应一种数据源(如 Hive Connector、MySQL Connector),负责将 SQL 逻辑转换为数据源的读写操作 |
| Catalog | 数据源 “命名空间”:每个 Catalog 对应一个 Connector,用于区分不同数据源(如hive_catalog对应 Hive 数据源,mysql_catalog对应 MySQL 数据源),查询时需指定 Catalog(如SELECT * FROM hive_catalog.db.table) |
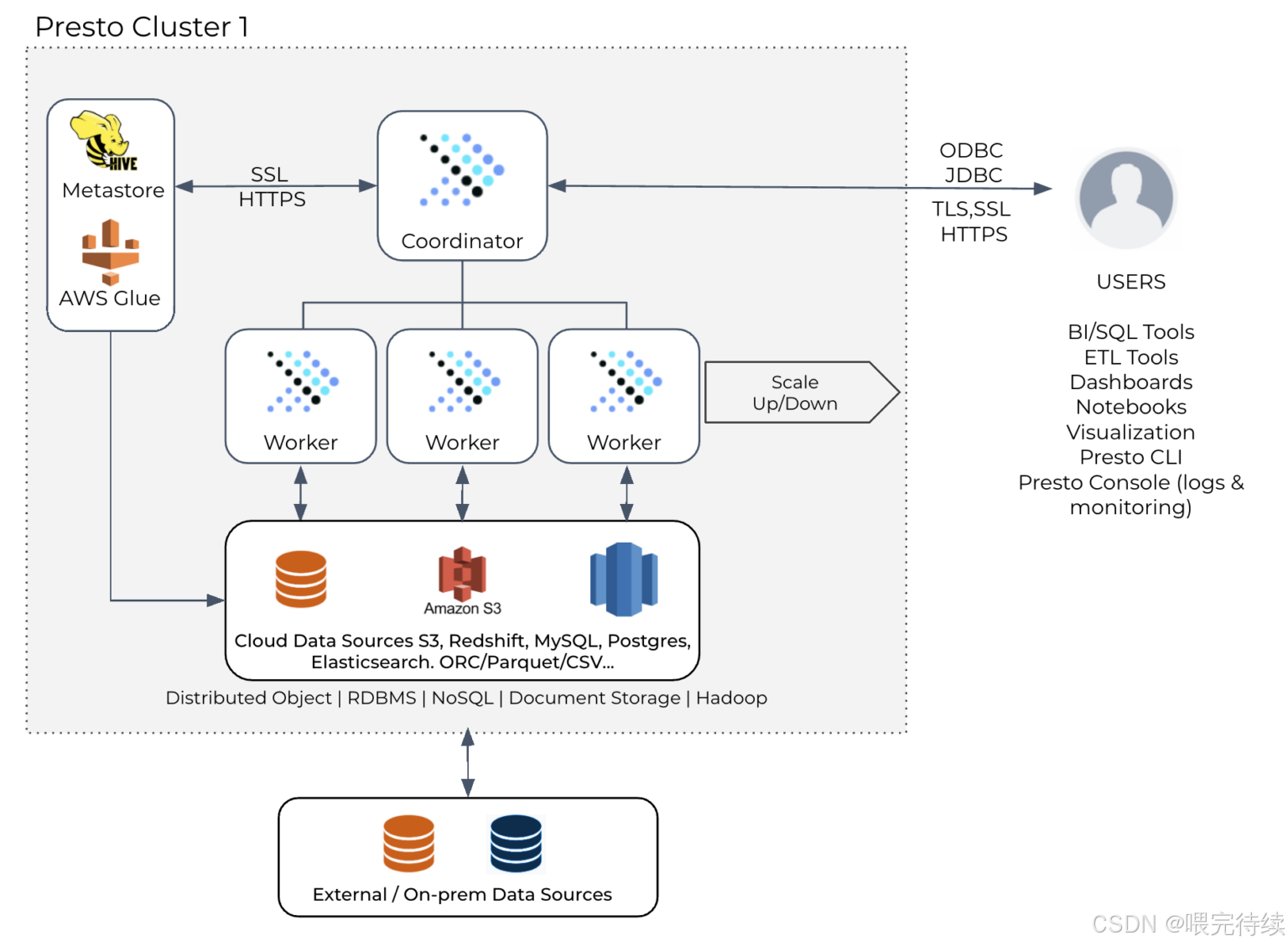
3.2 查询执行流程(以 “查询 Hive 中的用户订单数据” 为例)
- 查询提交:用户通过 CLI、JDBC/ODBC 或 BI 工具(如 Tableau)向 Coordinator 提交 SQL(如SELECT user_id, sum(amount) FROM hive_catalog.orders.db WHERE date = '2025-08-28' GROUP BY user_id);
- SQL 解析与验证:Coordinator 的 Parser 组件将 SQL 解析为抽象语法树(AST),Validator 组件验证 SQL 语法、表结构、权限是否合法;
- 执行计划生成:Planner 组件将 AST 转换为逻辑执行计划(Logical Plan),再通过 Optimizer(优化器)优化(如谓词下推、列裁剪、Join 重排序),生成物理执行计划(Physical Plan);
- 任务拆分与分配:Coordinator 将物理执行计划拆分为多个 “Task”(任务),并根据 Worker 的负载情况,将 Task 分配给不同的 Worker;
- 数据读取与计算:Worker 接收到 Task 后,通过 Hive Connector 读取 HDFS 中orders.db表的2025-08-28分区数据,执行过滤(WHERE date = ...)、聚合(sum(amount))等操作,生成中间结果;
- 结果汇总与返回:Worker 将中间结果返回给 Coordinator,Coordinator 汇总所有 Worker 的结果,最终返回给用户。
3.3 核心设计亮点
- 全内存计算:Presto 的中间结果不落地(不写入磁盘),全程在内存中流转,大幅降低 IO 延迟(这是其低延迟的核心原因);
- 流水线执行:Task 执行采用流水线模式,Worker 在处理部分数据后立即将中间结果返回,无需等待所有数据处理完成,进一步缩短延迟;
- 动态分区裁剪:查询时仅读取符合条件的分区数据(如上述例子中仅读取2025-08-28分区),减少数据扫描量;
- Connector 解耦:通过 Connector 机制,新增数据源只需开发对应的 Connector,无需修改 Presto 核心代码,扩展性极强。
4. Presto 解决了什么问题?
结合其诞生背景和架构设计,Presto 的核心价值在于解决了大数据领域的三大核心问题:
4.1 解决 “海量数据查询延迟高” 的问题
- 传统 Hive 基于 MapReduce,需多次磁盘 IO(如 Map 输出写入磁盘、Reduce 读取磁盘数据),延迟高;
- Presto 通过全内存计算 + 流水线执行,避免磁盘 IO,将 PB 级数据的查询延迟从 “小时级” 降至 “秒级 / 分钟级”,满足交互式分析需求。
4.2 解决 “多源数据联邦查询” 的问题
- 企业数据通常分散在 Hive(离线数据)、MySQL(业务数据)、Kafka(实时数据)等多种存储中,传统方案需通过 ETL 同步数据到统一存储,流程繁琐且实时性差;
- Presto 通过Connector+Ccatalog机制,支持直接跨数据源查询(如SELECT a.user_id, b.order_id FROM mysql_catalog.user.db a JOIN hive_catalog.orders.db b ON a.user_id = b.user_id),无需 ETL,实时性大幅提升。
4.3 解决 “SQL 兼容性与学习成本” 的问题
- 部分大数据查询工具(如 Spark SQL 早期版本、HBase Shell)对 SQL 支持不完整,开发人员需学习新语法;
- Presto 完全兼容 ANSI SQL,支持复杂查询语法(如窗口函数ROW_NUMBER()、数组操作UNNEST()),开发人员可直接复用现有 SQL 技能,降低学习成本。
5. Presto 的关键特性
除了上述解决的问题,Presto 还有以下核心特性,使其在同类工具中脱颖而出:
5.1 高性能低延迟
- 全内存计算:中间结果不落地,减少磁盘 IO 开销;
- 向量化执行:将数据按批次(而非单行)处理,充分利用 CPU 缓存,提升计算效率;
- 动态过滤:在 Join 操作中,通过 “小表过滤大表”,提前过滤掉不需要的数据,减少数据传输量。
5.2 强大的数据源兼容性
- 支持 30 + 数据源,包括:
- 大数据存储:Hive、Hudi、Iceberg、Delta Lake、HBase;
- 关系型数据库:MySQL、PostgreSQL、Oracle、SQL Server;
- 消息队列:Kafka、Pulsar;
- 对象存储:S3、OSS、GCS;
- 其他:Elasticsearch、Redis、MongoDB。
5.3 高扩展性
- 水平扩展:通过增加 Worker 节点,可线性提升集群的计算能力,支持 PB 级数据查询;
- 弹性伸缩:可结合 Kubernetes 实现 Worker 节点的动态扩缩容,适应业务流量波动。
5.4 企业级特性
- 权限控制:支持基于 Role 的访问控制(RBAC),可细粒度控制用户对 Catalog、Schema、Table 的查询权限;
- 监控告警:集成 Prometheus、Grafana,可监控集群负载、查询延迟、任务成功率等指标;
- 查询优化:内置强大的查询优化器,支持谓词下推、列裁剪、Join 重排序、子查询优化等,提升查询效率。
5.5 实时与离线场景兼顾
- 离线场景:通过 Hive Connector 查询 HDFS 中的离线数据;
- 实时场景:通过 Kafka Connector 直接查询 Kafka 中的流数据(支持按时间范围、偏移量过滤),实现近实时分析。
6. Presto 与同类产品对比
在大数据查询领域,Presto 的主要竞品包括 Hive、Spark SQL、Impala、Trino(Presto 分支),我们从核心维度对比:
| 产品 | 核心框架 | 延迟级别 | 适用场景 | 优势 | 劣势 |
| Presto | 自研分布式框架 | 秒级 - 分钟级 | 交互式查询、Ad-hoc 分析 | 低延迟、多源联邦查询、SQL 兼容 | 内存占用高、不支持批处理调度 |
| Hive | MapReduce/Tez | 分钟级 - 小时级 | 离线批处理、ETL | 稳定、支持海量数据批处理 | 延迟高、不适合交互式查询 |
| Spark SQL | Spark 引擎 | 分钟级 | 批处理 + 交互式查询 | 功能全面(批处理 + 流处理)、生态完善 | 延迟比 Presto 高(基于 JVM,启动开销大) |
| Impala | 自研 MPP 架构 | 秒级 - 分钟级 | 交互式查询(Hadoop 生态) | 低延迟、与 Hadoop 生态兼容性好 | 数据源支持少(主要支持 Hive/HBase)、社区活跃度低 |
| Trino | 基于 Presto 分支 | 秒级 - 分钟级 | 交互式查询、多源联邦查询 | 社区活跃、新特性迭代快 | 与 Presto 兼容性存在差异(部分配置不通用) |
关键结论:
- 若需低延迟交互式查询 + 多源联邦:优先选 Presto/Trino;
- 若需离线批处理 + ETL:优先选 Hive/Spark SQL;
- 若仅在Hadoop 生态内查询:Impala 可作为备选,但需接受数据源局限;
- 若需批处理 + 交互式查询兼顾:Spark SQL 更合适(但延迟比 Presto 高)。
7. Presto 的使用方法
接下来,我们以 “PrestoDB 0.280 版本” 为例,讲解从部署到查询的完整流程,面向开发人员提供实操步骤:
7.1 环境准备
- 操作系统:Linux(CentOS 7+/Ubuntu 18.04+);
- JDK:11(Presto 0.268 + 要求 JDK 11,之前版本支持 JDK 8);
- 集群规划:至少 1 个 Coordinator 节点 + 1 个 Worker 节点(生产环境建议 3+Worker 节点);
- 依赖:无(无需 Hadoop 集群,但若查询 Hive 需确保能访问 Hive Metastore 和 HDFS)。
7.2 部署步骤(以单机 Coordinator + 单机 Worker 为例)
步骤 1:下载 Presto 安装包
从 Presto 官网(https://prestodb.io/download.html)下载最新版本的安装包,如presto-server-0.280.tar.gz,解压到/opt/presto目录:
tar -zxvf presto-server-0.280.tar.gz -C /opt/
mv /opt/presto-server-0.280 /opt/presto步骤 2:创建配置文件
Presto 的配置文件需放在/opt/presto/etc目录下,需创建以下文件:
1.节点配置(node.properties):每个节点(Coordinator/Worker)需单独配置,指定节点角色;
- Coordinator 节点配置:
node.environment=production # 环境名,所有节点需一致
node.id=coordinator-1 # 节点唯一ID
node.data-dir=/opt/presto/data # 数据存储目录(用于存储日志、临时文件)- Worker 节点配置:
node.environment=production
node.id=worker-1
node.data-dir=/opt/presto/data2.JVM 配置(jvm.config):指定 JVM 参数,建议 Coordinator 分配 4G 内存,Worker 分配
8G + 内存;
-server
-Xmx8G # 堆内存大小,Worker节点建议设为物理内存的50%-70%
-XX:+UseG1GC
-XX:G1HeapRegionSize=32M
-XX:+UseGCOverheadLimit
-XX:+ExplicitGCInvokesConcurrent
-XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=/opt/presto/logs/heapdump.hprof3.配置属性(config.properties):指定节点角色(Coordinator/Worker)及端口;
- Coordinator 节点配置:
coordinator=true # 是否为Coordinator节点
node-scheduler.include-coordinator=false # Coordinator是否参与计算(生产环境建议设为false,避免影响协调功能)
http-server.http.port=8080 # HTTP端口(用于Web UI和JDBC/ODBC连接)
query.max-memory=4GB # 单个查询最大内存
query.max-memory-per-node=1GB # 单个节点为单个查询分配的最大内存
discovery-server.enabled=true # 启用内置的Discovery Service
discovery.uri=http://coordinator-ip:8080 # Coordinator的地址(Worker需通过此地址注册)- Worker 节点配置:
coordinator=false # 不是Coordinator节点
http-server.http.port=8080
query.max-memory=4GB
query.max-memory-per-node=1GB
discovery.uri=http://coordinator-ip:8080 # 指向Coordinator的地址,用于注册4.数据源配置(Catalog 配置):在/opt/presto/etc/catalog目录下创建数据源配置文件,以 Hive 为例(hive.properties):
coordinator=false # 不是Coordinator节点
http-server.http.port=8080
query.max-memory=4GB
query.max-memory-per-node=1GB
discovery.uri=http://coordinator-ip:8080 # 指向Coordinator的地址,用于注册步骤 3:启动集群
1.启动 Coordinator 节点:
/opt/presto/bin/launcher start2.启动 Worker 节点:
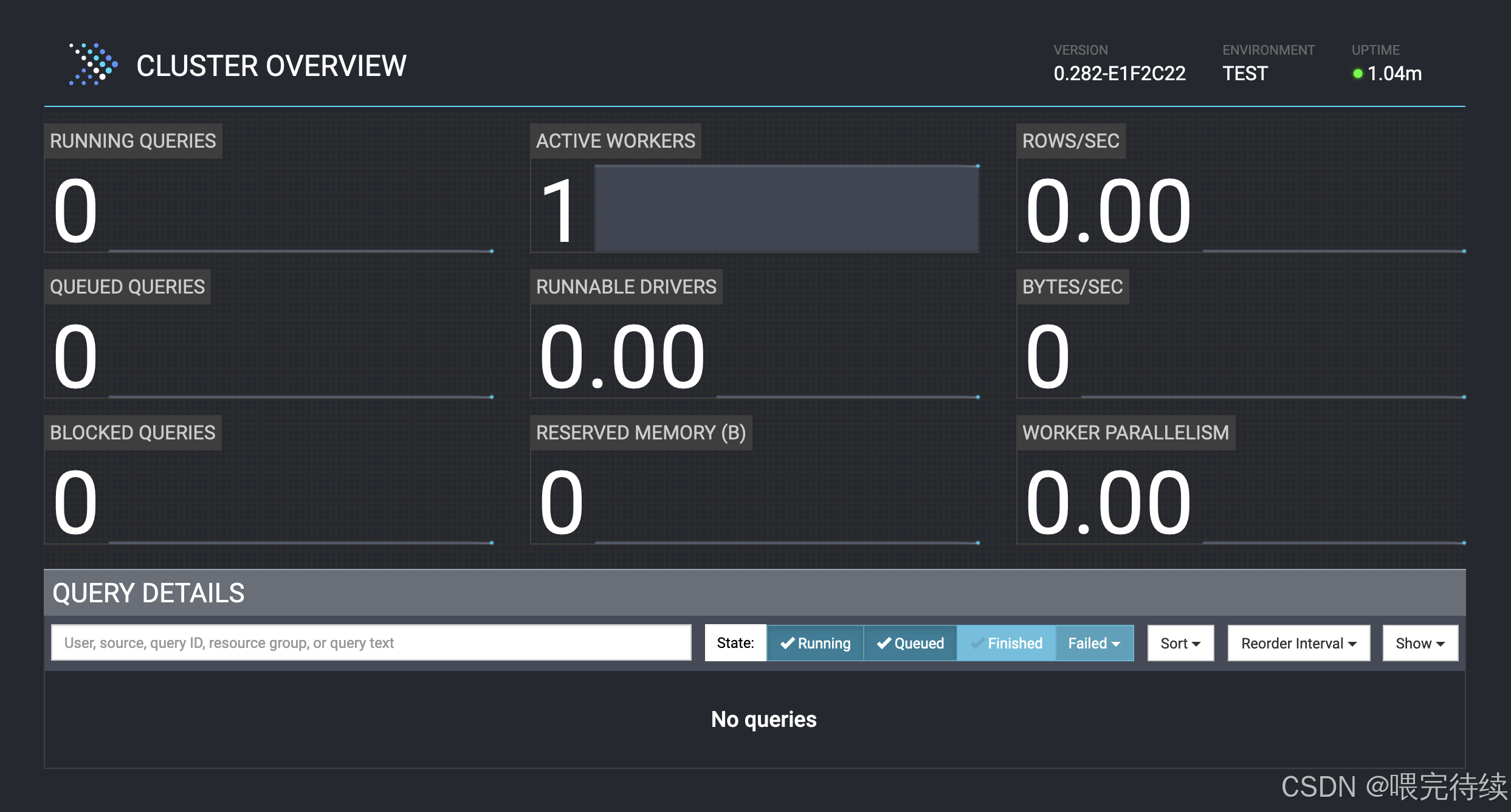
/opt/presto/bin/launcher start3.验证启动:访问 Coordinator 的 Web UI(http://coordinator-ip:8080),在 “Cluster” 页面可看到 Worker 节点已注册。
7.3 基本查询操作(使用 Presto CLI)
步骤 1:下载 Presto CLI
从 Presto 官网下载 CLI 工具(presto-cli-0.280-executable.jar),重命名为presto并赋予执行权限:
mv presto-cli-0.280-executable.jar presto
chmod +x presto步骤 2:连接 Presto 集群
通过 CLI 连接到 Coordinator,指定默认 Catalog(如 Hive):
./presto --server coordinator-ip:8080 --catalog hive_catalog --schema default- --server:Coordinator 的地址和端口;
- --catalog:默认使用的 Catalog(即数据源);
- --schema:默认使用的 Schema(类似数据库中的 “库”)。
步骤 3:执行查询
1.查看当前 Catalog 下的 Schema:
SHOW SCHEMAS;2.查看指定 Schema 下的表:
SHOW TABLES FROM orders_db;3.执行查询(如统计 2025-08-28 的订单总金额):
SELECT sum(amount) AS total_amount
FROM orders_db.orders
WHERE order_date = '2025-08-28';4.跨数据源查询(如关联 MySQL 的用户表和 Hive 的订单表):
SELECT u.user_name, sum(o.amount) AS total_amount
FROM mysql_catalog.user_db.users u
JOIN hive_catalog.orders_db.orders o
ON u.user_id = o.user_id
WHERE o.order_date = '2025-08-28'
GROUP BY u.user_name;
7.4 进阶使用:性能优化建议
- 谓词下推:确保查询中的过滤条件(WHERE 子句)能传递到数据源(如 Hive 分区过滤、MySQL 索引过滤),避免全表扫描;
- 列裁剪:只查询需要的列(避免SELECT *),减少数据传输量;
- Join 优化:将小表放在 Join 的左侧(Presto 默认将左侧表作为 “驱动表”),通过/*+ JOIN_ORDER(table1, table2) */提示优化 Join 顺序;
- 内存配置:根据查询复杂度调整query.max-memory和query.max-memory-per-node,避免内存溢出;
- 分区表使用:对大表(如订单表)按时间分区,查询时指定分区,减少数据扫描量。
文末
Presto 作为一款专注于低延迟多源查询的分布式 SQL 引擎,通过 “无存储依赖 + 全内存计算 + Connector 解耦” 的设计,完美解决了大数据领域的 “查询延迟高”“多源数据难整合”“学习成本高” 三大痛点。无论是互联网企业的交互式分析,还是传统企业的跨源报表生成,Presto 都能成为核心工具。
后续我会针对 Presto 的进阶特性(如 Kafka 实时查询、Hudi/Iceberg 表格式支持、查询优化器原理)展开更深入的讲解,如果你有具体的使用场景或问题,欢迎在评论区留言!
参考资料:
- 官方文档:Presto 0.293 Documentation
技术做了多年,却总在“重复踩坑”?点我关注,陪你建立底层认知!
这里有:
📌 技术决策深度文(从选型到落地的全链路分析)
💭 开发者成长思考(职业规划/团队管理/认知升级)
🎯 行业趋势观察(AI对开发的影响/云原生下一站)
关注我,每周日与你聊“技术内外的那些事”,让你的代码之外,更有“技术眼光”。
日更专刊:
🥇 《Thinking in Java》 🌀 java、spring、微服务的序列晋升之路!
🏆 《Technology and Architecture》 🌀 大数据相关技术原理与架构,帮你构建完整知识体系!关于博主:
🌟博主GitHub
🌞博主知识星球