【SpringAI】快速上手,详解项目快速集成主流大模型DeepSeek,ChatGPT


🔥个人主页: 中草药
🔥专栏:【Java】登神长阶 史诗般的Java成神之路
SpringAI
Spring AI

概述
Spring AI 是 Spring 生态下的人工智能应用开发框架,旨在简化 Java/Spring 开发者对大语言模型(LLM)、向量数据库等 AI 能力的集成,核心目标是解决 “企业数据与 AI 模型的连接问题”。它继承了 Spring 生态的可移植性、模块化设计理念,让开发者能以熟悉的方式快速构建 AI 应用(如智能客服、文档问答、内容生成等)。
模型
模型旨在处理和生成信息的算法,通常模仿人类的认知功能。通过从大型数据集中学习模式和洞察,这些模型可以进行预测、生成文本、图像或其他输出,从而增强各个行业的各种应用。比如 ChatGPT、文心一言、通义千问等等。每种模型能力不同,适合的任务也不同。
可以简单理解为模型是一个 "超级加工厂", 这个工厂是经过特殊训练的,训练师给它看了海量的例子 (数据), 并告诉它该怎么做。通过看这些例子,它自己摸索出了一套规则,学会了完成某个 "特定任务". 模型就是一套学到的 "规则" 或者 "模式", 它能根据你给的东西,产生你想要的东西。
简单总结一下,在 AI 领域,模型是通过训练数据学习模式的算法集合,其核心作用是将输入转化为有意义的输出。
Spring AI的作用就是让我们在java/spring的应用之中,能非常方便地去选择不同的模型,构造和发送输入,接受并处理输出
LLM
LLM (Large Language Model), 大语言模型,也称大型语言模型,是人工智能模型中专门处理文本的一种类型,属于语言模型的范畴. LLM 的特点是规模庞大,包含数十亿的参数,在大量的文本数据上进行训练,学习语言数据中的复杂模式,旨在理解和生成人类语言。可以执行广泛的任务,包括文本总结、翻译、情感分析等.
简单介绍几种目前主流的大语言模型 (LLM) .
-
GPT-5(OpenAI)
○ 支持 128K 长上下文,在多轮复杂推理、创意写作中表现突出 -
DeepSeek R1 (深度求索)
○ 开源,专注于逻辑推理与数学求解,支持 128K 长上下文和多语言 (20 + 语言), 在科技领域表现突出 -
Qwen2.5-72B-Instruct (阿里巴巴)
○ 通义千问开源模型家族重要成员,擅长代码生成结构化数据 (如 JSON) 处理角色扮演对话等,尤其适合企业级复杂任务,支持包括中文英文法语等 29 种语言 -
Gemini 2.5 Pro (Google)
○ 多模态融合标杆,支持图像 / 代码 / 文本混合输入,适合跨模态任务 (如图文生成、技术文档解析)
提示词
提示词是用户或系统提供给大语言模型 (LLM) 的指令或文本,用于引导模型生成特定输出。可以理解为模型的输入,无论是一个单词、一个问题、一段描述,还是结构化指令,都可视为提示词.
提示词最初是为引导大语言模型 (如 GPT、Claude 等) 而设计的,但其核心逻辑 (通过结构化输入控制输出) 可泛化到许多其他场景.
比如多模态系统的混合输入,当大模型处理图像、音频时,自然语言提示词需与其他模态数据协同输入,输入设计草图 + 文字,提示词为: "生成网页前端代码"
从工程视角来看,提示词分为用户提示词和系统提示词
| 类型 | 定义 | 核心功能 | 示例 |
|---|---|---|---|
| 用户提示词 | 由终端用户直接输入,触发单次任务 | 传达即时需求(如提问、创作指令) | 用户输入:"总结这篇论文的核心观点" |
| 系统提示词 | 由开发者预设,嵌入系统后端 | 定义模型角色、行为规范、知识边界 | 预设:"你是一名严谨的学术助手,回答需引用权威文献 |
Tokens(词原)
Tokens 是 LLM 处理文本时的最小语义单位,用于将文本拆解为模型可理解的离散单元。词元通过分词器将文本拆分而来,不同模型的分词规则不同,同一个词在不同模型中可能被拆分成不同词元。
模型的上下文窗口 (如 128K) 实际是词元数量限制,API 收费通常按词元数计费 (词元 = 金钱),词元数越多,计算耗时和内存占用越高。所以在使用时,应尽量避免冗余词 (如请,谢谢)
接入deepseek
环境要求:
JDK:最低要求-JDK 17+(Spring Boot 3.x 的强制要求)
Spring Boot:最低要求 Spring Boot 3.2+ (Spring AI 1.0.0 起强制依赖)推荐:3.4.x(最新稳定版)3.3.x(部分旧项目兼容方案)
API获取
DeepSeek 开放平台
这是deepseek开放平台,可以在这里获取API key

pom
<dependencyManagement><dependencies><dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-bom</artifactId><version>1.0.0-M6</version><type>pom</type><scope>import</scope></dependency></dependencies></dependencyManagement><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-openai-spring-boot-starter</artifactId></dependency></dependencies>yml
spring:application:name: spring-ai-moduleai:openai:api-key: sk-ae299ca6f4c9431ab4f3d0dd40b682f7base-url: https://api.deepseek.comchat:options:model: deepseek-chattemperature: 0.7 #用于控制生成补全内容的多样性,值越好,输出越随机Controller
@RestController
@RequestMapping("/ds")
public class DeepSeekController {@Autowiredprivate OpenAiChatModel model;@RequestMapping("/chat")public String chat(String message) {return model.call(message);}
}
测试结果

接入ChatGPT
环境准备和Controller上述DeepSeek一致(DeepSeek去兼容了openai)
OpenAI Platform
注册账号
yml
spring:application:name: spring-ai-moduleai:openai:api-key: your-key
base-url默认就是https://api.openai.com
注意
本地开发时,即使配置了代理,也有可能无法让整个系统全局代理,为此启动类加上如下代码,配置代理ip与port
System.setProperty("http.proxyHost","127.0.0.1");
System.setProperty("https.proxyHost","127.0.0.1");
System.setProperty("http.proxyPort","7890");
System.setProperty("https.proxyPort","7890");测试
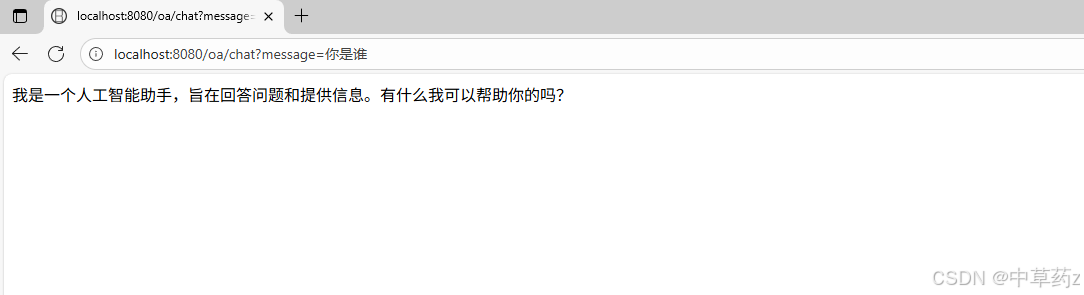
接入成功
SpringAI+SiliconFlow(推荐-有免费赠额)
硅基流动 SiliconFlow
这里先来介绍一下,硅基流动(SiliconFlow)是北京硅基流动科技有限公司旗下的 AI 基础设施品牌,这是一个一站式大模型云服务平台,集成了 Qwen、DeepSeek、Llama3 等主流开源模型,提供从模型训练、微调到推理部署的全链路服务。用户可通过 API 调用快速接入模型,例如文本生成、图像生成、视频生成等多模态任务,日均调用量已突破千亿 Token。平台还支持企业级模型微调与托管,帮助开发者实现 “Token 自由”(即低成本、高弹性的模型使用)。
简而言之,其核心定位是大模型时代的 AI 基础设施层(AI Infra),是高性能的国产AI模型平台
SpringAI+硅基流动
Spring AI 是一个用于 AI 工程的应用框架。其目标是将可移植性和模块化设计等 Spring 生态系统设计原则应用于 AI 领域,并推广使用 POJO 作为应用程序的构建块到 AI 领域。
在讲实操前,先明确这对组合的核心价值 ——SpringAI 解决 “标准化”,硅基流动解决 “中间件能力”,二者互补刚好破解传统集成的 3 大痛点:
| 传统大模型集成痛点 | SpringAI 的解决方式 | 硅基流动的补充价值 |
| 多模型接口不统一,适配成本高 | 提供标准化Model接口,封装不同模型的调用逻辑,切换模型无需改业务代码 | 内置主流大模型(GPT、文心、通义等)的适配能力,SpringAI 只需对接硅基流动,无需逐个对接模型厂商 |
| 配置繁琐,环境依赖复杂 | 基于 Spring Boot 自动配置,简化参数配置 | 提供统一的 API 密钥、模型版本管理,支持本地调试 / 云端部署无缝切换 |
| 生产级需求难满足(限流、重试、监控) | 依赖 Spring 生态的重试、缓存组件,但需手动集成 | 原生支持请求限流、失败重试、调用日志监控,无需额外开发 |
环境准备
JDK 17+(Spring AI 0.8+ 最低要求)
Spring Boot 3.2+(建议用最新稳定版)
硅基流动账号
硅基流动用户系统,统一登录 SSO
大家可以自行官网注册,也可以通过我的邀请链接和邀请码注册,这样可以在原先的基础上额外赠送7块钱额度,这是我的邀请码:gvYC1Tje
获取API Key(需要充值)
注意不要泄漏你的API Key
快速上手
在pom.xml中引入 Spring AI 核心依赖(Spring AI 已官方兼容硅基流动,无需自定义适配)
<dependencyManagement><dependencies><dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-bom</artifactId><version>1.0.0-M6</version><type>pom</type><scope>import</scope></dependency></dependencies></dependencyManagement><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><version>3.5.4</version><scope>test</scope></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId><version>3.5.4</version></dependency><dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-openai-spring-boot-starter</artifactId></dependency></dependencies>配置文件
spring:application:name: spring-ai-siliconcloudai:openai:api-key: your-keybase-url: https://api.siliconflow.cn/
创建Controller
如果要在初始化ChatClient中确定模型,注意要写全称
@RestController
@RequestMapping("sf")
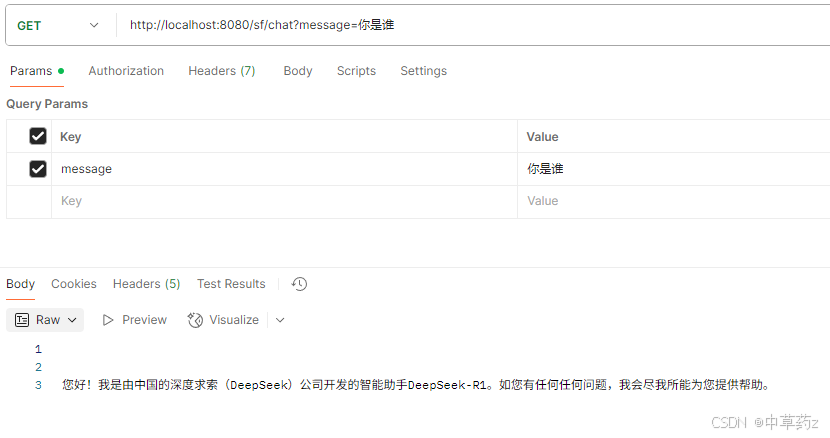
public class DeepSeekController {private final ChatClient chatClient;public DeepSeekController(ChatClient.Builder builder) {this.chatClient = builder.defaultSystem("你是一个专业的智能助手,回答需简洁准确").defaultOptions(OpenAiChatOptions.builder()//可以写在yml文件.model("Pro/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B").build()).build();}@GetMapping("/chat")public String chat(@RequestParam(name = "message") String message) {// 使用prompt()方法替代call(),通过UserMessage传递用户输入ChatResponse response = chatClient.prompt().messages(new UserMessage(message)).call().chatResponse();// 提取并返回模型的回答内容return response.getResult().getOutput().getText();}
}
测试结果
ChatClient
ChatClient是 Spring AI 提供的高层客户端,它封装了ChatModel,提供了更简洁、更符合 Spring 风格的 API,旨在降低开发者的使用门槛。它提供了与AI模型通信的Fluent API,它支持同步和反应式的编程模型。
Controller
@RestController
@RequestMapping("/cc")
public class ChatClientController {private final ChatClient chatClient;public ChatClientController(ChatClient.Builder chatClientBuilder) {this.chatClient = chatClientBuilder.build();}@GetMapping("/ai")public String generation(String userInput) {return this.chatClient.prompt()//用户输入 .user(userInput).call().content();}
}
角色预设
public ChatClientController(ChatClient.Builder chatClientBuilder) {this.chatClient = chatClientBuilder.defaultSystem("你是一名资深的Java后端开发工程师,名字叫牛牛").build();}角色预设前后


结构化输出
通过Entity()方法将模型输出转为自定义实体,确保输出格式满足Json
借助jdk16里的record来便捷实现
record QuestionList(String topic, List<String> questionList) {}@RequestMapping("/entity")
public String entity(String userInput) {QuestionList entity = chatClient.prompt().user(String.format("请帮我找到学习%s算法的leetcode的题目", userInput)).call().entity(QuestionList.class);return entity.toString();
}
实现流式输出
为了优化体验,可以采用流式输出的方式进行优化(类似于deepseek,豆包的形式)
大模型流式输出(Streaming Output)最适合逐步生成内容而非一次性返回完整结果的场景。Spring AI 使用 ChatClient 的 stream () 方法生成 Flux<String> 流,适用于需要持续拉取客户输入的 AI 场景
@RequestMapping(value = "/stream",produces = "text/html;charset=utf-8")public Flux<String> stream(String userInput) {return this.chatClient.prompt().user(userInput).stream().content();}注意设置页面编码,否则有可能会输出乱码
日志打印
Advisors
Spring AI 中的 Advisors 是介于用户请求与 AI 模型之间的中间件组件,它的核心功能就是对请求进行拦截过滤和增强。帮助我们在 API 调用前后解决各种问题,例如调用前参数如何构建,调用后结果如何处理。
Spring AI 中的 Advisors 是基于 AOP 思想实现的,在具体实现上进行了领域适配。其设计核心借鉴了 Spring AOP 的拦截机制,各个 Advisors 以链式结构运行,序列中的各个 Advisor 都有机会对传入的请求和传出的响应进行处理。这种链式处理机制确保了每个 Advisor 可以在请求和响应流程中 插入自己的逻辑,从而实现更灵活和可定制的功能。
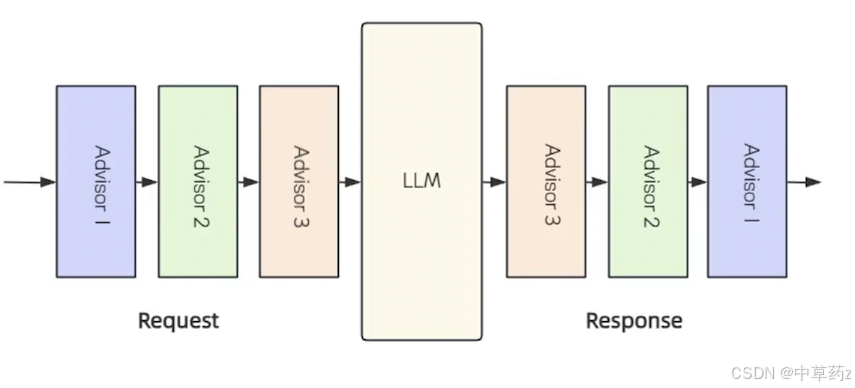
应用场景
- 敏感词过滤
- 建立聊天历史
- 对话上下文管理
SimpleLoggerAdvisor
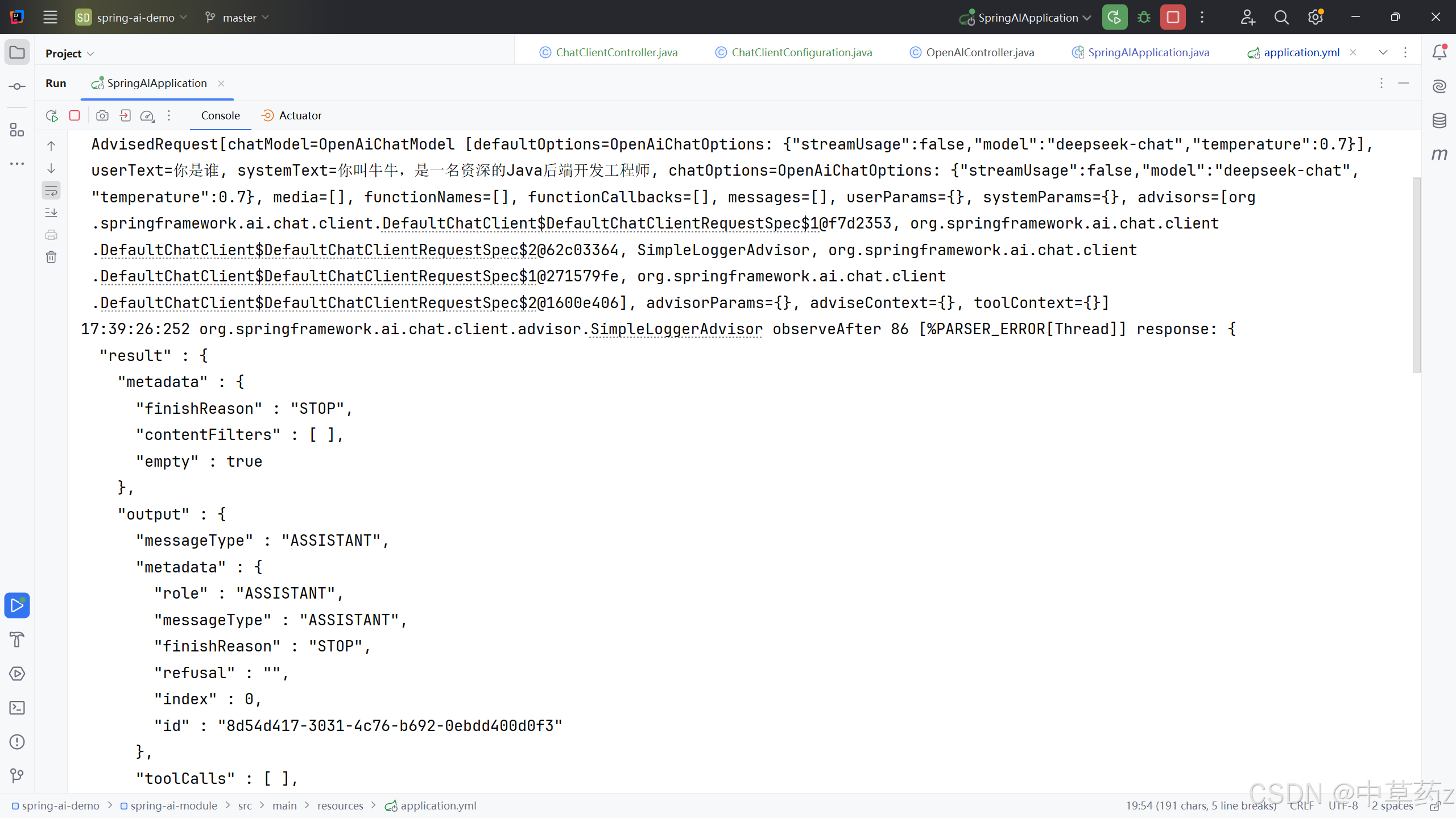
添加这个advisor,来实现日志打印
@Configuration
public class ChatClientConfiguration {@Beanpublic ChatClient chatClient(ChatClient.Builder chatClientBuilder) {return chatClientBuilder.defaultSystem("你叫牛牛,是一名资深的Java后端开发工程师").defaultAdvisors(new SimpleLoggerAdvisor()).build();}
}
yml
logging:pattern:console: '%d{HH:mm:ss:SSS} %c %M %L [%Thread] %m%n'file: '%d{HH:mm:ss:SSS} %c %M %L [%Thread] %m%n'level:org.springframework.ai.chat.client.advisor: debug实现效果
与ChatModel的区别
ChatClient 和 ChatModel 是 Spring AI 框架提供的与大语言模型(LLM)交互的两大核心接口,但二者设计理念和适用场景不太一样。
-
ChatModel 是 Spring AI 框架中的底层接口,直接与具体的大语言模型(如通义千问、OpenAI)交互,提供基础的
call和stream方法。开发者需手动处理提示词组、参数配置和响应解析等细节,在使用上相对更加灵活。 -
ChatClient 对 ChatModel 进行了封装,相比 ChatModel 原子类 API,ChatClient 屏蔽了与 AI 大模型交互的复杂性,自动集成 提示词管理、响应格式化、结构化输出映射 等能力,大幅提高开发效率。
ChatModel 示例代码(手动处理交互)
ChatResponse response = openAiChatModel.call(new Prompt(message));
return response.getResult().getOutput().getText();
ChatClient 示例代码(封装后简化交互)
Recipe recipe = this.chatClient.prompt()// 用户输入的信息(提示词组装).user(String.format("请帮我生成%s的食谱", userInput))// 发起大模型请求.call()// 响应映射为 Recipe 实体类(结构化输出).entity(Recipe.class);| 维度 | ChatModel | ChatClient |
|---|---|---|
| 交互方式 | 手动构建 Prompt,解析响应 | 链式 API,自动封装请求与响应 |
| 结构化输出 | 手动解析文本 | 支持 .entity(Class) 自动映射 POJO |
| 扩展能力 | 依赖外部组件 | 内置 Advisor 机制,提供更高级功能(如上下文记忆、RAG 等) |
| 适合场景 | 适合精细控制模型参数的场景(如模型实验、参数调优) | 适合快速构建 AI 服务(如带记忆的客服系统) |
流式编程
SSE协议
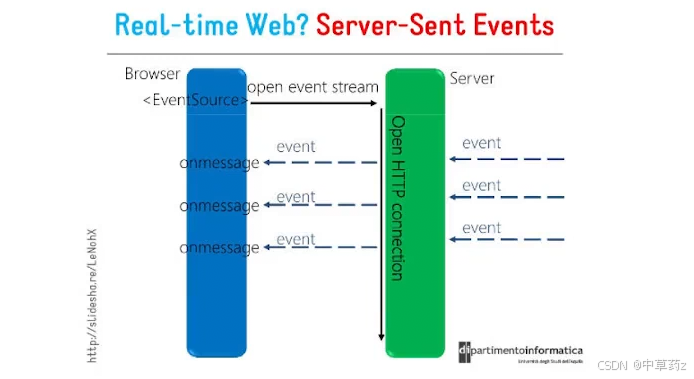
HTTP 协议本身设计为无状态的请求 - 响应模式,严格来说,是无法做到服务器主动推送消息到客户端,但通过 Server-Sent Events(服务器发送事件,简称 SSE)技术可实现流式传输,允许服务器主动向浏览器推送数据流。
也就是说,服务器向客户端声明,接下来要发送的是流消息 (streaming),这时客户端不会关闭连接,会一直等待服务器发送过来的新的数据流。
SSE(Server-Sent Events)是一种基于 HTTP 的轻量级实时通信协议,浏览器通过内置的 EventSource API 接收并处理这些实时事件。
核心特点
-
基于 HTTP 协议
复用标准 HTTP/HTTPS 协议,无需额外端口或协议,兼容性好且易于部署。 -
单向通信机制
SSE 仅支持服务器向客户端的单向数据推送,客户端通过普通 HTTP 请求建立连接后,服务器可持续发送数据流,但客户端无法通过同一连接向服务器发送数据。 -
自动重连机制
支持断线重连,连接中断时,浏览器会自动尝试重新连接(支持retry字段指定重连间隔)。 -
自定义消息类型
客户端发起请求后,服务器保持连接开放,响应头设置Content-Type: text/event-stream,标识为事件流格式,持续推送事件流。
数据格式
服务端向浏览器发送 SSE 数据,需要设置必要的 HTTP 头信息:
Content-Type: text/event-stream;charset=utf-8
Connection: keep-alive 每一次发送的消息,由若干个message组成,每个message之间由 \n\n 分隔,每个message内部由若干行组成,每一行都是如下格式:
代码块
[field]: value\n
Field 可取值说明
data[必需]:数据内容event[非必需]:表示自定义的事件类型,默认是message事件id[非必需]:数据标识符,相当于每一条数据的编号retry[非必需]:指定浏览器重新发起连接的时间间隔
除此之外,还可以有 冒号 : 开头的行,表示注释。
示例代码块(Plain Text)
event: foo\n
data: a foo event\n\n data: an unnamed event\n\n event: end\n
data: a bar event\n\n Spring中实现
spring4.2开始已经支持了SSE,从Spring 5开始我们可以使用WebFlux更优雅地去实现SSE协议,Flux是实现 WebFlux 的核心API,他的核心流程是
创建flux流->处理数据->订阅数据
测试demo
public class FluxDemoTest {public static void main(String[] args) throws InterruptedException {Flux<String> flux = Flux.just("Hello", "World","good").delayElements(Duration.ofSeconds(1));flux.map(s->s.toUpperCase()).map(s->s+".").subscribe(System.out::println);//防止程序提前终止Thread.sleep(5000);}
}
比如发送时间
@RequestMapping(value = "/stream", produces = MediaType.TEXT_EVENT_STREAM_VALUE)public Flux<String> stream(){return Flux.interval(Duration.ofSeconds(1)).map(s->new Date().toString());}常用 API
创建Flux
| 方法名称 | 功能说明 | 示例代码 |
|---|---|---|
just(T... data) | 直接传入多个元素创建 Flux,元素会被依次发射 | Flux.just("a", "b", "c") |
fromIterable(Iterable<? extends T> it) | 从集合(如 List、Set)创建 Flux | Flux.fromIterable(Arrays.asList(1, 2, 3)) |
fromArray(T[] array) | 从数组创建 Flux | Flux.fromArray(new Integer[]{1, 2, 3}) |
empty() | 创建空 Flux,直接发射完成信号(onComplete) | Flux.empty() |
error(Throwable e) | 创建直接发射错误信号(onError)的 Flux | Flux.error(new RuntimeException("出错了")) |
interval(Duration period) | 周期性发射从 0 开始的递增整数(异步非阻塞) | Flux.interval(Duration.ofSeconds(1)) |
处理数据
| 方法名称 | 功能说明 | 示例代码 |
|---|---|---|
subscribe() | 简单订阅,忽略所有元素、错误和完成信号 | flux.subscribe() |
subscribe(Consumer<? super T> onNext) | 处理正常发射的元素,忽略错误和完成信号 | flux.subscribe(i -> System.out.println("接收:" + i)) |
subscribe(Consumer<? super T> onNext, Consumer<? super Throwable> onError) | 处理元素和错误信号 | flux.subscribe(i -> System.out.println(i), e -> e.printStackTrace()) |
subscribe(Consumer<? super T> onNext, Consumer<? super Throwable> onError, Runnable onComplete) | 处理元素、错误和完成信号 | flux.subscribe(i -> System.out.println(i), e -> {}, () -> System.out.println("处理完成")) |
filter(Predicate<? super T> predicate) | 保留满足条件的元素 | Flux.just(1,2,3,4).filter(i -> i%2 == 0)(结果:2,4) |
take(long n) | 只保留前n个元素 | Flux.just(1,2,3,4).take(2)(结果:1,2) |
skip(long n) | 跳过前n个元素,保留剩余元素 | Flux.just(1,2,3,4).skip(2)(结果:3,4) |
distinct() | 去除重复元素(基于equals判断) | Flux.just(1,2,2,3).distinct()(结果:1,2,3) |
merge(Publisher<? extends T>... sources) | 并行合并多个 Flux,元素按实际发射时间顺序输出(可能交错) | Flux.merge(flux1, flux2)(flux1:1,2;flux2:3,4,可能结果:3,1,4,2) |
concat(Publisher<? extends T>... sources) | 串行合并多个 Flux,前一个完成后再处理下一个(顺序严格) | Flux.concat(flux1, flux2)(flux1:1,2;flux2:3,4,结果:1,2,3,4) |
zip(Publisher<? extends T1> s1, Publisher<? extends T2> s2, BiFunction<T1,T2,R> combinator) | 按位置一一配对多个 Flux 的元素(如拉链),任一 Flux 完成则整体完成 | Flux.zip(fluxA, fluxB, (a,b) -> a+b)(fluxA:"a","b";fluxB:1,2,结果:"a1","b2") |
订阅操作
| 方法名称 | 功能说明 | 示例代码 |
|---|---|---|
subscribe() | 简单订阅,忽略所有元素、错误和完成信号 | flux.subscribe() |
subscribe(Consumer<? super T> onNext) | 处理正常发射的元素,忽略错误和完成信号 | flux.subscribe(i -> System.out.println("接收:" + i)) |
subscribe(Consumer<? super T> onNext, Consumer<? super Throwable> onError) | 处理元素和错误信号 | flux.subscribe(i -> System.out.println(i), e -> e.printStackTrace()) |
subscribe(Consumer<? super T> onNext, Consumer<? super Throwable> onError, Runnable onComplete) | 处理元素、错误和完成信号 | flux.subscribe(i -> System.out.println(i), e -> {}, () -> System.out.println("处理完成")) |
有些人担心人工智能的出现会令人类感到自卑,但任何有头脑的人单是观察花朵就应该能感到自己的渺小。 ——艾伦凯
🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀
以上,就是本期的全部内容啦,若有错误疏忽希望各位大佬及时指出💐
制作不易,希望能对各位提供微小的帮助,可否留下你免费的赞呢🌸