QT之双缓冲 (QMutex/QWaitCondition)——读写分离
QT之QWaitCondition降低cpu占用率,从忙等待到高效同步_qwaitcondition 作用-CSDN博客文章浏览阅读630次,点赞25次,收藏28次。QWaitCondition降低cpu占用率,从忙等待到高效同步_qwaitcondition 作用https://blog.csdn.net/yanchenyu365/article/details/150526447
上一篇,用QWaitCondition降低了cpu占用,它已经能满足大部分频率不高的场景,但也有缺点只有一个缓冲区,生产者写时需要加锁,消费者读时也需要加锁,因为读写是互斥的,乙方占用时间大时就会影响另一方,所以不能高频并发,折中方案就是双缓冲。
注意:永远不存在性能非常强,cpu占用又非常低,资源平衡需要根据场景取舍;
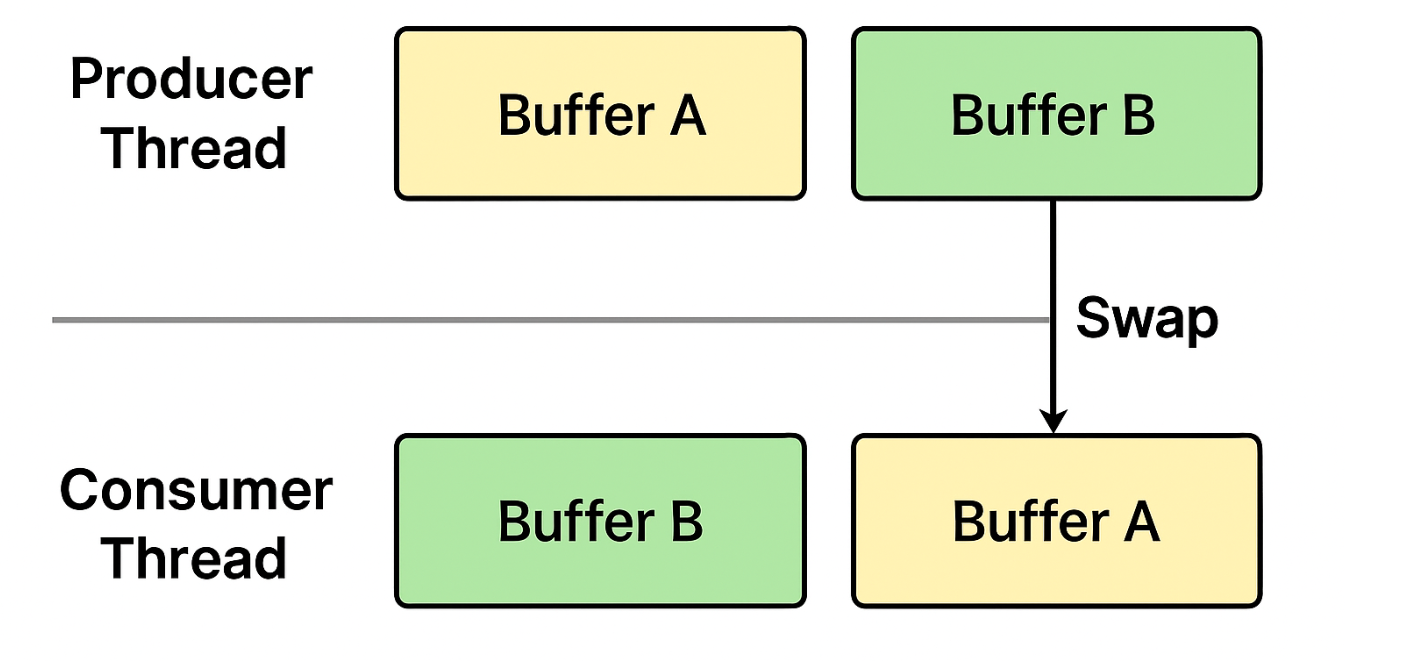
一、双缓冲 (QMutex + QWaitCondition)概念
-
工作机制
两个缓冲区:一个供写,一个供读。
写完交换指针后再唤醒消费者。
消费者总是拿到一份完整的数据,读写冲突大幅减少。 -
性能提升
-
锁的持有时间显著缩短(只在交换时加锁)。
-
生产者和消费者基本可以并行工作(一个在写 A,一个在读 B)。
-
适合 中高频数据,如 GUI 绘图、数据采集。
-
-
开销
-
互斥锁 + 条件变量依然存在,但大部分时间生产者和消费者互不干扰。
-
相比单缓冲,性能提升可达数倍(尤其在数据量大、处理耗时差不多时)。
-
二、代码示例
#include <QCoreApplication>
#include <QThread>
#include <QMutex>
#include <QWaitCondition>
#include <QVector>
#include <QDebug>class DoubleBuffer {
public:DoubleBuffer(int size = 10) {buffer[0].resize(size);buffer[1].resize(size);}void write(const QVector<int>& data) {QMutexLocker locker(&mutex);buffer[writeIndex] = data;swapPending = true;cond.wakeOne(); // 通知消费者}QVector<int> read() {QMutexLocker locker(&mutex);while (!swapPending) {cond.wait(&mutex); // 等待生产者通知}std::swap(readIndex, writeIndex);swapPending = false;return buffer[readIndex];}private:QVector<int> buffer[2];int writeIndex = 0;int readIndex = 1;bool swapPending = false;QMutex mutex;QWaitCondition cond;
};// ----------------- 生产者线程 -----------------
class Producer : public QThread {Q_OBJECT
public:Producer(DoubleBuffer* buf) : buffer(buf) {}protected:void run() override {int counter = 0;while (counter < 5) {QVector<int> data;for (int i = 0; i < 5; i++) {data.append(counter * 10 + i);}qDebug() << "Producer writes:" << data;buffer->write(data);counter++;msleep(500);}}
private:DoubleBuffer* buffer;
};// ----------------- 消费者线程 -----------------
class Consumer : public QThread {Q_OBJECT
public:Consumer(DoubleBuffer* buf) : buffer(buf) {}protected:void run() override {for (int i = 0; i < 5; i++) {QVector<int> data = buffer->read();qDebug() << "Consumer reads:" << data;msleep(800); // 模拟处理时间}}
private:DoubleBuffer* buffer;
};// ----------------- 主函数 -----------------
int main(int argc, char *argv[])
{QCoreApplication a(argc, argv);DoubleBuffer buffer;Producer producer(&buffer);Consumer consumer(&buffer);producer.start();consumer.start();producer.wait();consumer.wait();return 0;
}
生产者:生成数据并写入缓冲区,写完通知消费者。
消费者:等待通知后交换缓冲区,读取新数据并处理。
因为用的是双缓冲,消费者拿到的是一份完整的数据,不会和生产者冲突。
通过合理使用双缓冲机制,可以构建出既高效又稳定的多线程应用,在保证数据一致性的同时最大化系统吞吐量,选择合适的并发模式是构建高性能应用的关键!
三、注意
双缓冲适合 一生产者一消费者 的模型。
如果有多个生产者或多个消费者,可能需要 环形缓冲区(ring buffer) 或 无锁队列 来扩展