MaxCompute MaxFrame | 分布式Python计算服务MaxFrame(完整操作版)
MaxCompute MaxFrame评测 | 分布式Python计算服务MaxFrame(完整操作版)
- 前言
- MaxCompute MaxFrame
- 服务开通
- 开通 MaxCompute 服务
- 开通 DataWorks 服务
- 资源准备
- 创建 DataWorks 工作空间
- 创建 MaxCompute 项目
- 创建MaxCompute数据源
- 绑定数据源或集群
- 创建MaxCompute节点
- 在DataWorks中使用MaxFrame
- 分布式Pandas 处理
- 总的来说
前言
在当今数字化迅猛发展的时代,数据信息的保存与数据分析对企业的决策和工作方向具有极为重要的指导价值。通过企业数据分析,企业能够精准统计出自身的成本投入、经营收益以及利润等重要数据。这些数据犹如企业运营的“晴雨表”,为企业后续的决策提供了坚实可靠的依据,助力企业在市场竞争中优化经营策略,从而实现更大的价值创造。
今天我们要讲的正是可以帮助企业实现数据保存于数据分析的一款分布式计算框架MaxCompute MaxFrame,那么什么是MaxCompute MaxFrame?
MaxCompute MaxFrame
在开始测评之前,先了解一下什么是MaxCompute MaxFrame?
以下是来自官网的介绍:【MaxFrame是由阿里云自研的分布式计算框架,支持Python编程接口、兼容Pandas接口且自动进行分布式计算。您可利用MaxCompute的海量计算资源及数据进行大规模数据处理、可视化数据探索分析以及科学计算、ML/AI开发等工作。】关于MaxCompute MaxFrame 的更多内容你可以直接在官网中详细了解,包括产品优势、产品功能、应用场景等,这里我主要是测评 MaxCompute MaxFrame 的操作体验,因此对于 MaxCompute MaxFrame 的详细介绍大家可以移步官网:https://www.aliyun.com/product/bigdata/odps/maxframe

MaxCompute MaxFrame,那么下面就开始今天的操作吧。
服务开通
在开始测试 MaxCompute MaxFrame 的功能前,首先需要开通 MaxCompute和DataWorks 服务。
开通 MaxCompute 服务
对于全新的、此前未开通过MaxCompute的阿里云账号,阿里云在部分地域提供了免费的MaxCompute资源包,您可以先申请免费资源包体验试用,体验地址:https://free.aliyun.com/ 在免费试用页面输入你想要试用的服务,比如输入 MaxCompute
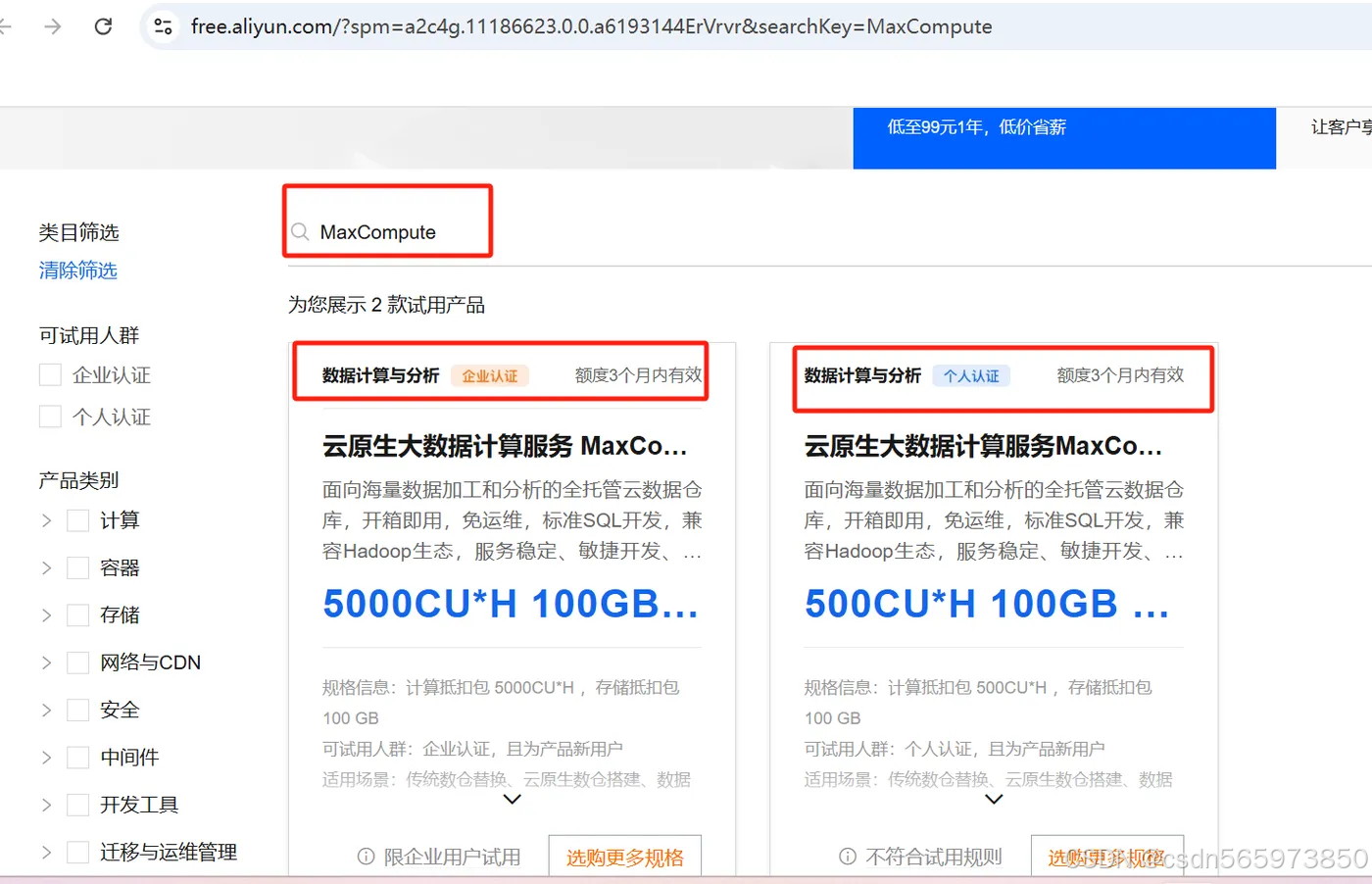
如果你的阿里云账号没有免费试用资格,那么你只能通过 阿里云MaxCompute产品首页 :https://www.aliyun.com/product/maxcompute 单击【立即购买】,选择【按量付费标准版】开通MaxCompute服务
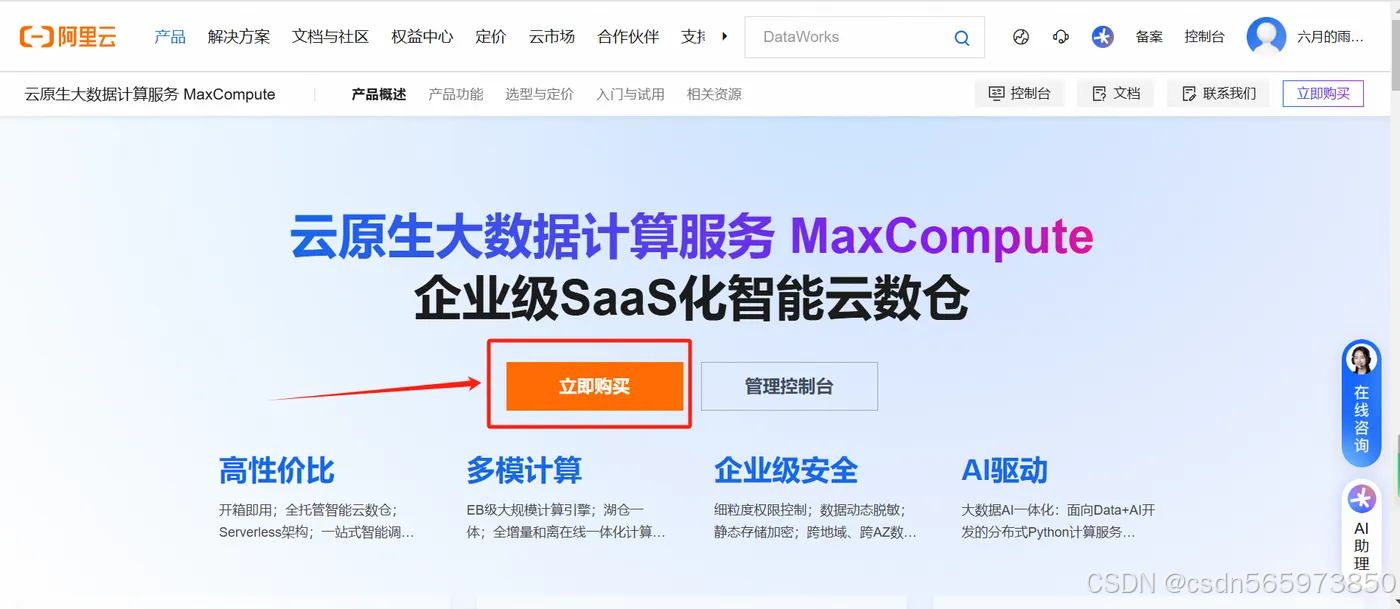
这里我的账号在当前北京地域下已经开通过 MaxCompute 服务,因此这里才有这个提示,正常情况下的话你直接开通即可
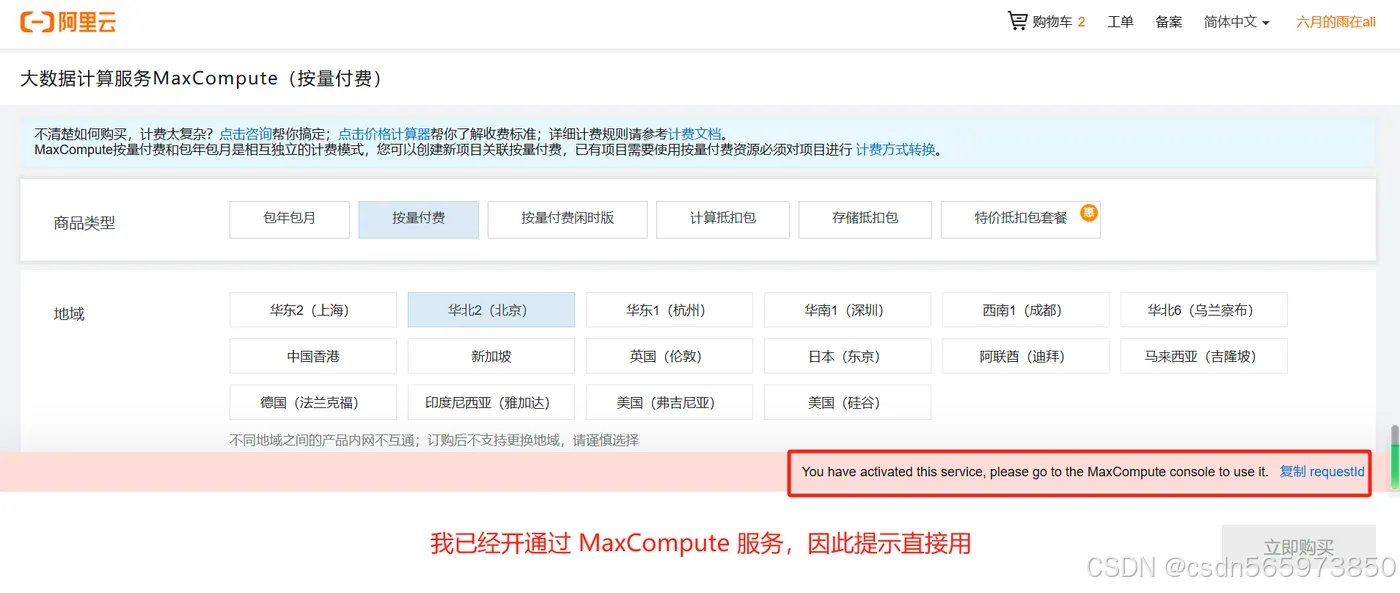
开通完 MaxCompute 服务之后,我们还需要开通 DataWorks 服务。
开通 DataWorks 服务
同样的,对于全新的、此前未开通过DataWorks 的阿里云账号,阿里云在部分地域提供了免费的DataWorks资源包,您可以先申请免费资源包体验试用。免费试用地址同上,在免费试用界面输入 DataWorks 可以查看试用资格
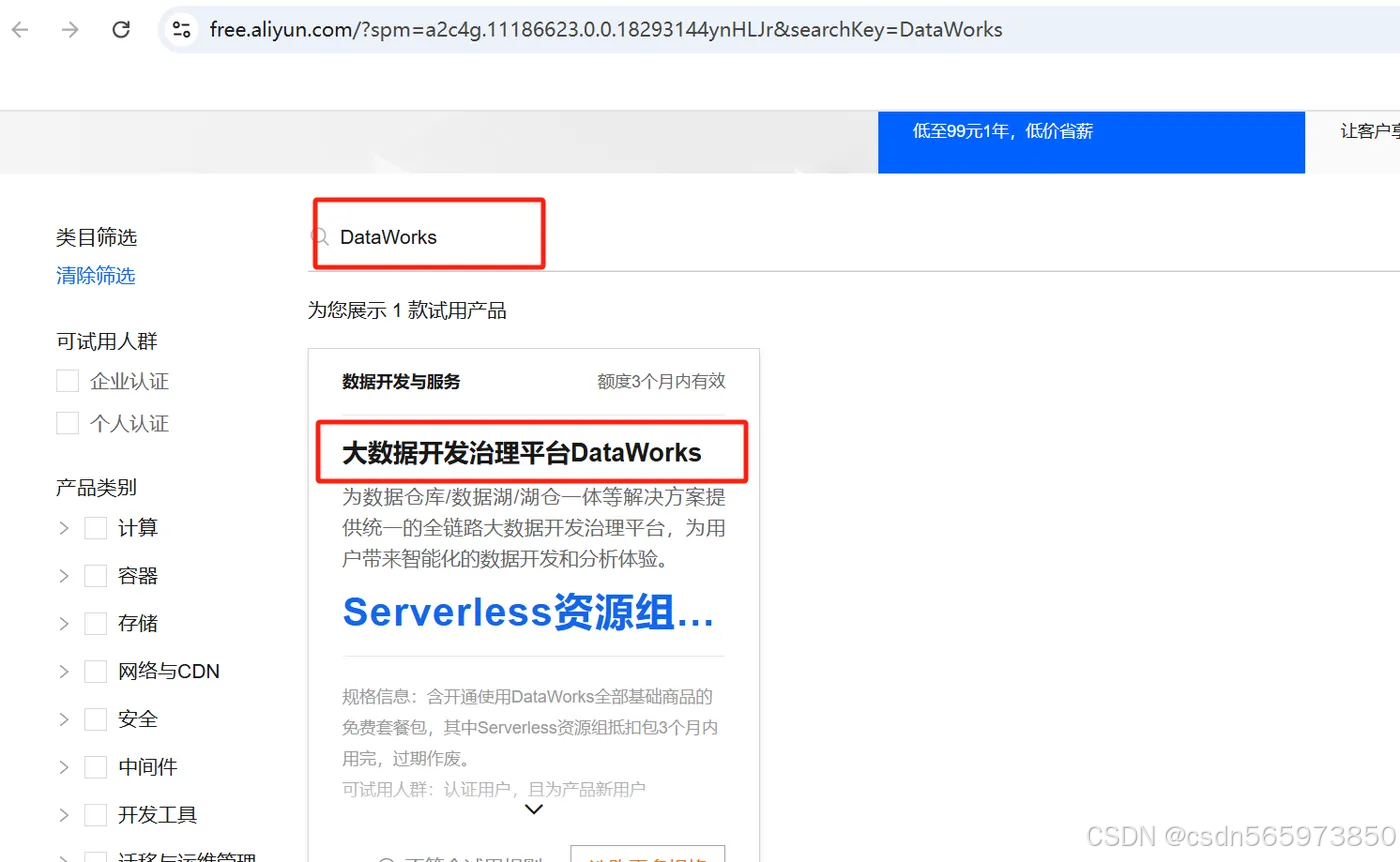
如果你的阿里云账号没有试用资格的话,你可以到 DataWorks 官网,官网地址: https://www.aliyun.com/product/bigdata/ide
点击【立即购买】选择需要开通 DataWorks 服务的地域以及 【按量付费】计费方式后开通即可,这里我已经开通过按量付费了
资源准备完成之后,下面就开始创建资源用于后面的操作。
资源准备
在我们开通了MaxCompute和DataWorks 服务 之后,下面我们就可以创建资源了,下面按照步骤创建资源内容。
创建 DataWorks 工作空间
登录DataWorks控制台 ,在控制台顶部菜单栏切换所需地域,单击左侧导航栏的【工作空间】,进入工作空间列表页面,点击【创建工作空间】,这里我已经创建好了工作空间 User_dataworks
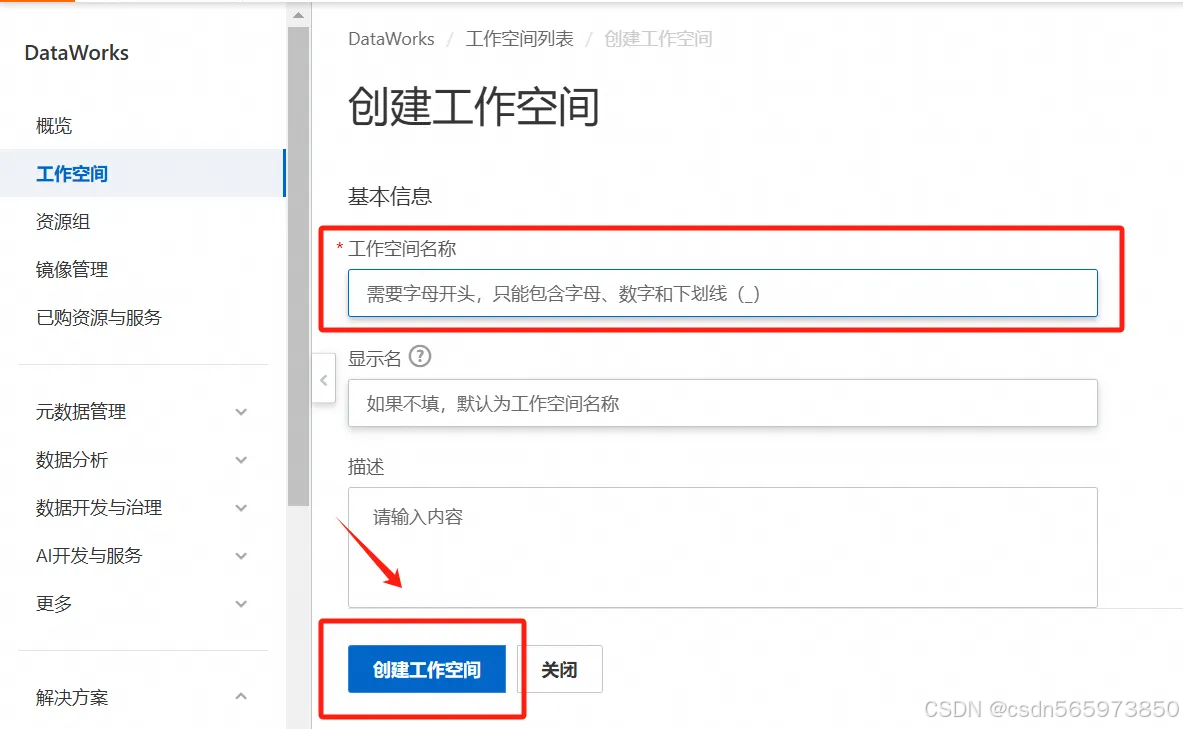
输入工作空间名称,定义工作空间模式,即工作空间的生产环境和开发环境是否隔离等参数,根据实际情况选择即可
创建 MaxCompute 项目
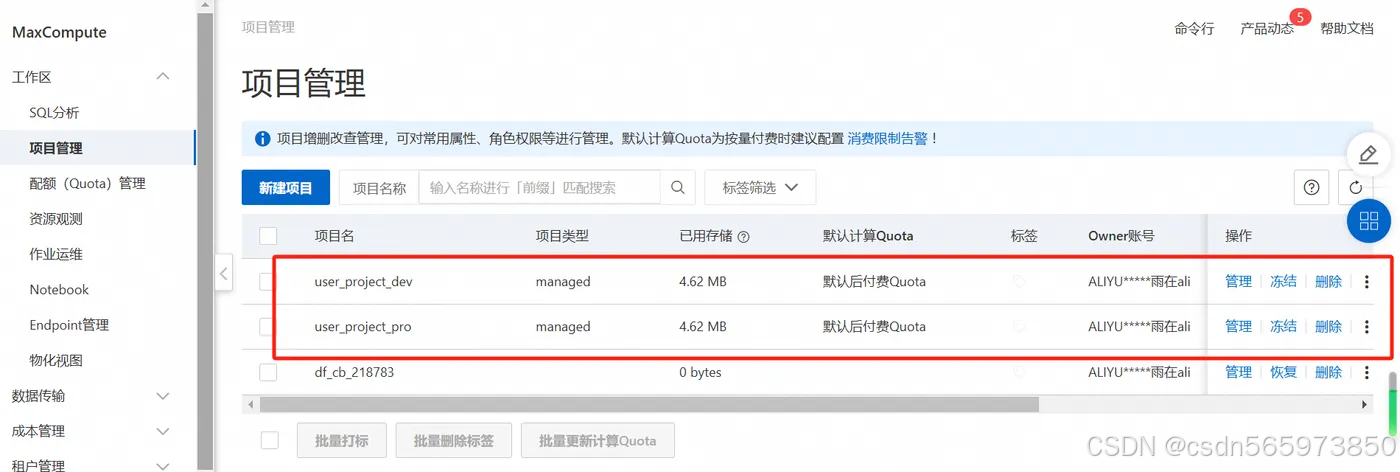
登录MaxCompute控制台,在左上角选择地域,选择左侧菜单【项目管理】,点击【新建项目】,这里为了区分后面的测试和生产环境,需要创建两个 MaxCompute 项目空间,这里我已经创建好了
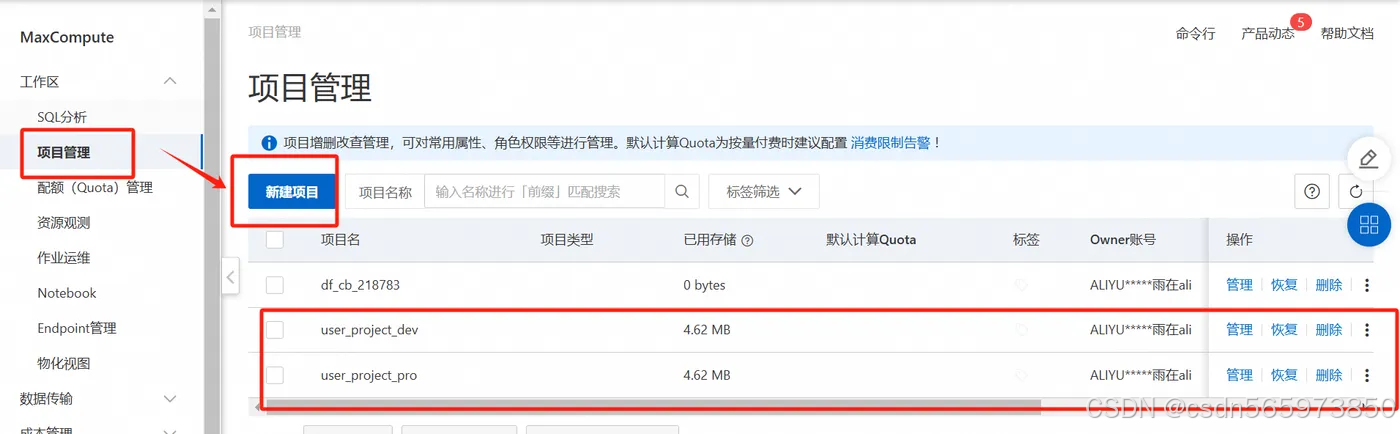
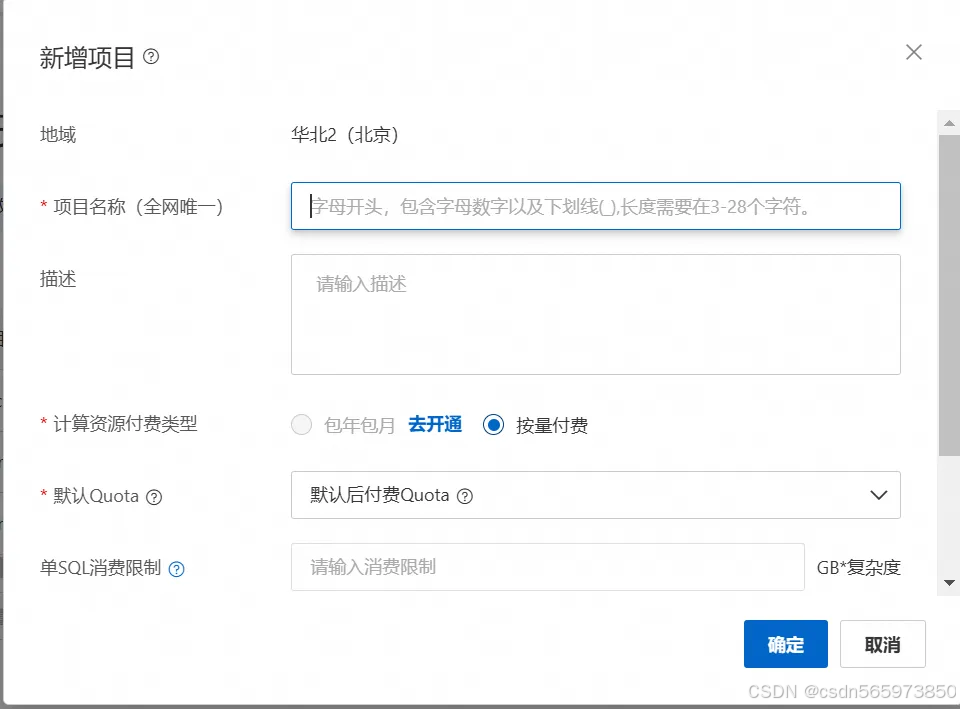
在 MaxCompute 新增项目页面,需要输入项目名称,选择 计算资源付费类型、默认Quota 等信息后,点击确定即可完成 MaxCompute 创建。
创建MaxCompute数据源
完成上述操作之后,回到 DataWorks控制台 ,在 DataWorks 控制台 选择查看 【工作空间】列表页面,点击工作空间名称,进入工作空间详情页面,在工作空间详情页面点击【数据源】-【数据源列表】可以看到这里我已经创建成功的数据源
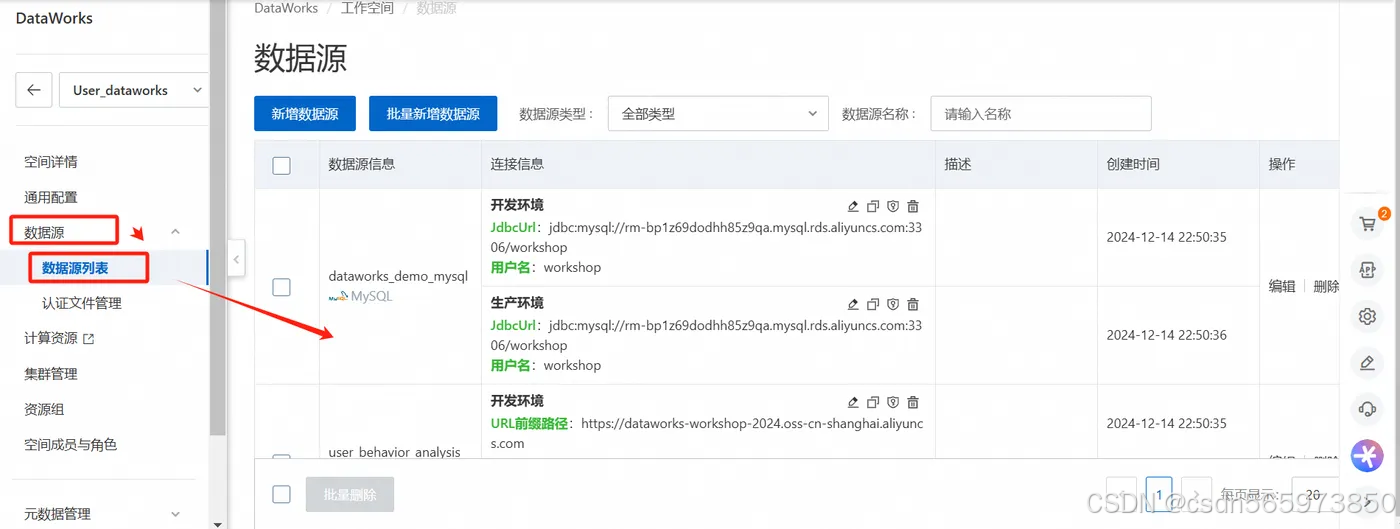
点击【新增数据源】,选择 MaxCompute,根据界面指引创建数据源
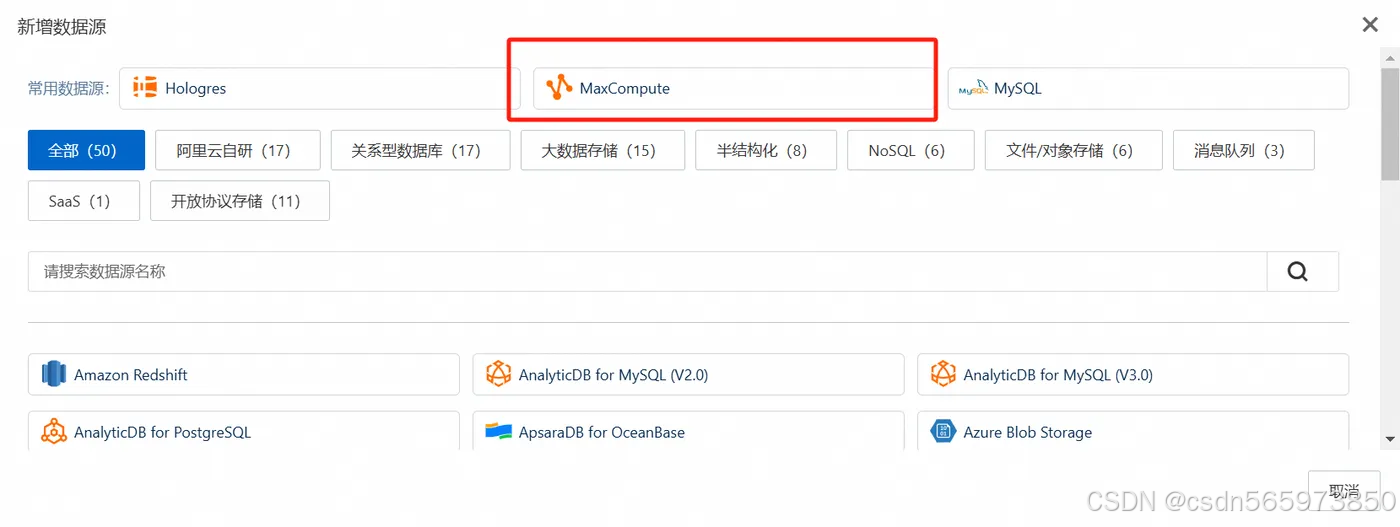
选择 MaxCompute 在新增 MaxCompute 数据源页面,我们需要输入 数据源名称 ,所属云账号、地域等信息,可以选择我们刚才创建好的 MaxCompute项目名称
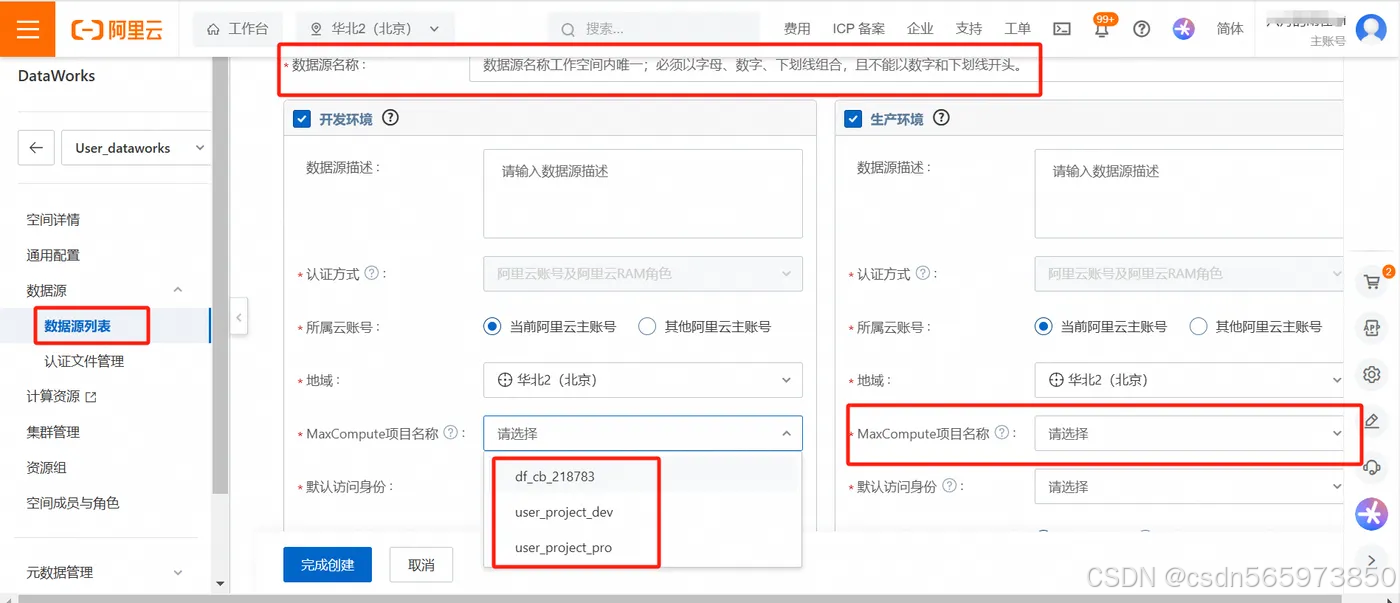
点击【完成创建】之后,创建完成MaxCompute 数据源,就可以返回【数据源列表】查看已经创建好的数据源信息了。
绑定数据源或集群
等待MaxCompute 数据源创建成功之后, 登录DataWorks控制台,切换至目标地域后,单击左侧导航栏的【数据开发与治理】 - 【数据开发】,在下拉框中选择对应工作空间后单击【进入数据开发】
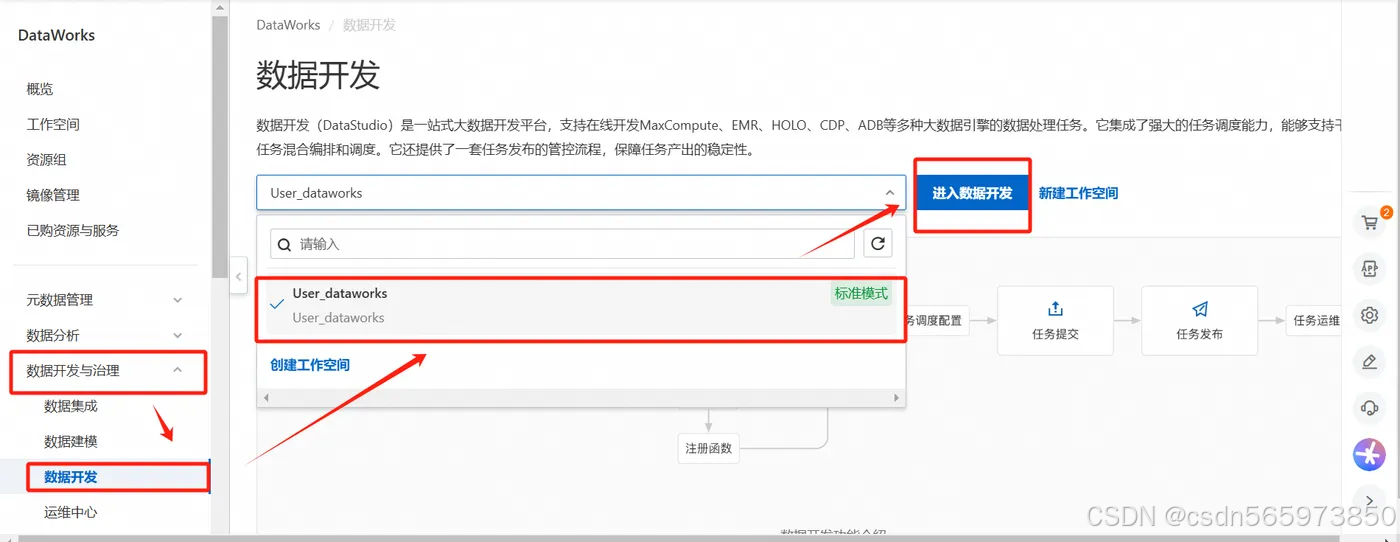
在左侧导航栏单击【数据源】,进入数据源或集群绑定页面,您可通过名称搜索找到目标数据源或集群进行绑定操作。绑定后,便可基于数据源的连接信息读取该数据源的数据,进行相关开发操作。如果你找不到具体的 数据源 绑定操作入口,又不想去按照官方文档说的那样去个人设置里面找,这里可以直接点击 绑定 进入到绑定页面,在绑定页面选择资源绑定,这里我已经绑定过了
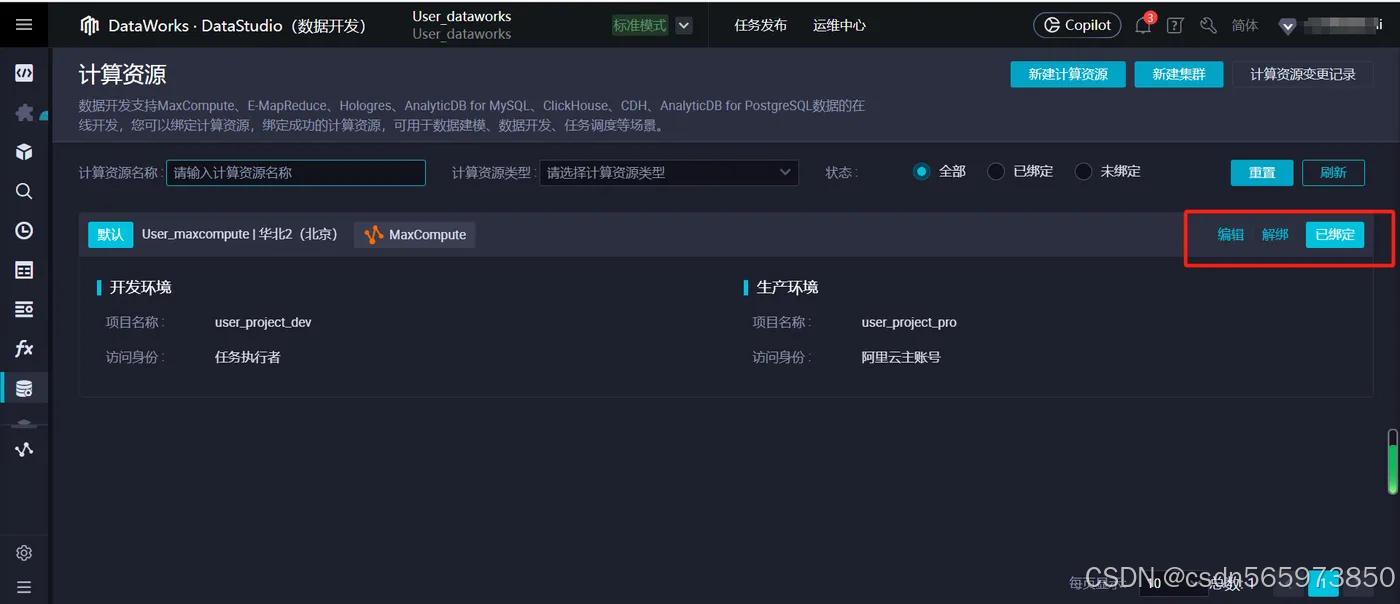
在开发 PyODPS 3 任务之前,先来简单说一下PyODPS 3 任务。 DataWorks为我们提供PyODPS 3节点,我们可以在该节点中直接使用Python代码编写MaxCompute作业,并进行作业的周期性调度。开始之前需要先创建一个 PyODPS 3节点。
创建MaxCompute节点
登录DataWorks控制台,切换至目标地域后,单击左侧导航栏的【数据开发与治理】 > 【数据开发】,在下拉框中选择对应工作空间后单击【进入数据开发】,在 数据开发页面选择【新建】>【MaxCompute】 > 【PyODPS 3 】
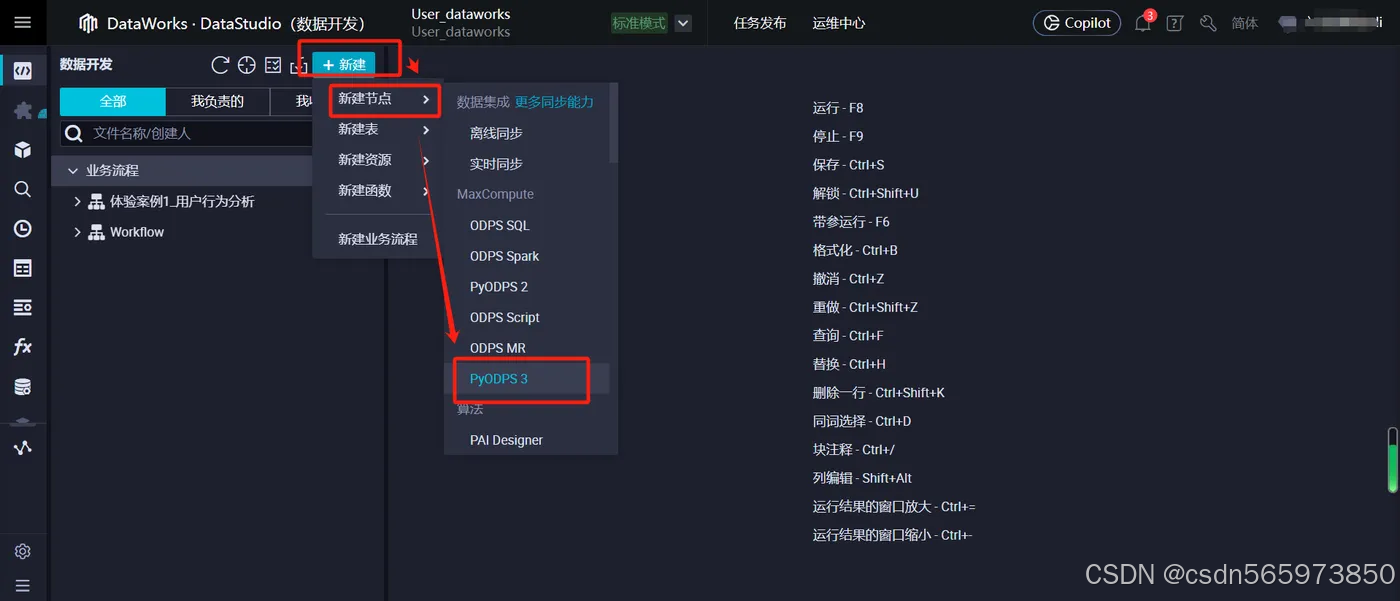
在弹框中配置节点的名称,选择路径,完成后单击确认,完成MaxCompute节点创建操作,后续您即可在节点中进行对应MaxCompute任务开发与配置
节点创建成功之后,可以在数据开发页面看到节点信息
以上的资源准备好了之后,我们就可以使用DataWorks的PyODPS 3节点开发和运行MaxFrame作业。
在DataWorks中使用MaxFrame
在开始使用MaxFrame之前,先来简单介绍一下。 DataWorks为MaxCompute项目提供任务调度能力,且已在PyODPS 3节点内置了MaxFrame,我们可直接使用DataWorks的PyODPS 3节点开发和运行MaxFrame作业。PyODPS 3内置了MaxCompute用户和项目信息,因此我们可以直接创建MaxFrame会话,复制代码放入创建的 PyODPS 3节点 的 命令操作台
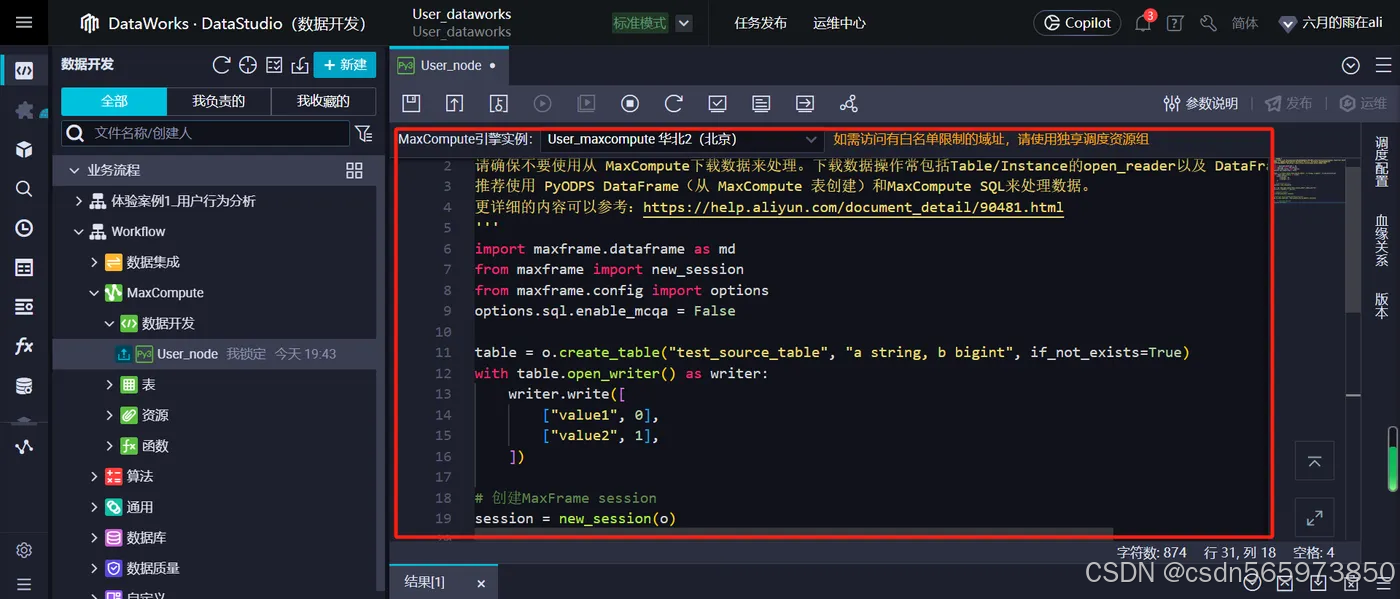
代码示例如下
import maxframe.dataframe as md
from maxframe import new_session
from maxframe.config import options
options.sql.enable_mcqa = Falsetable = o.create_table("test_source_table", "a string, b bigint", if_not_exists=True)
with table.open_writer() as writer:writer.write([["value1", 0],["value2", 1],])# 创建MaxFrame session
session = new_session(o)df = md.read_odps_table("test_source_table",index_col="b")
df["a"] = "prefix_" + df["a"]# 打印dataframe数据
print(df.execute().fetch())# MaxFrame DataFrame数据写入MaxCompute表
md.to_odps_table(df, "test_prefix_source_table").execute()# 销毁 maxframe session
session.destroy()
在数据开发页面命令控制台上侧点击【执行】按钮,执行Python代码可以看到如下的返回结果
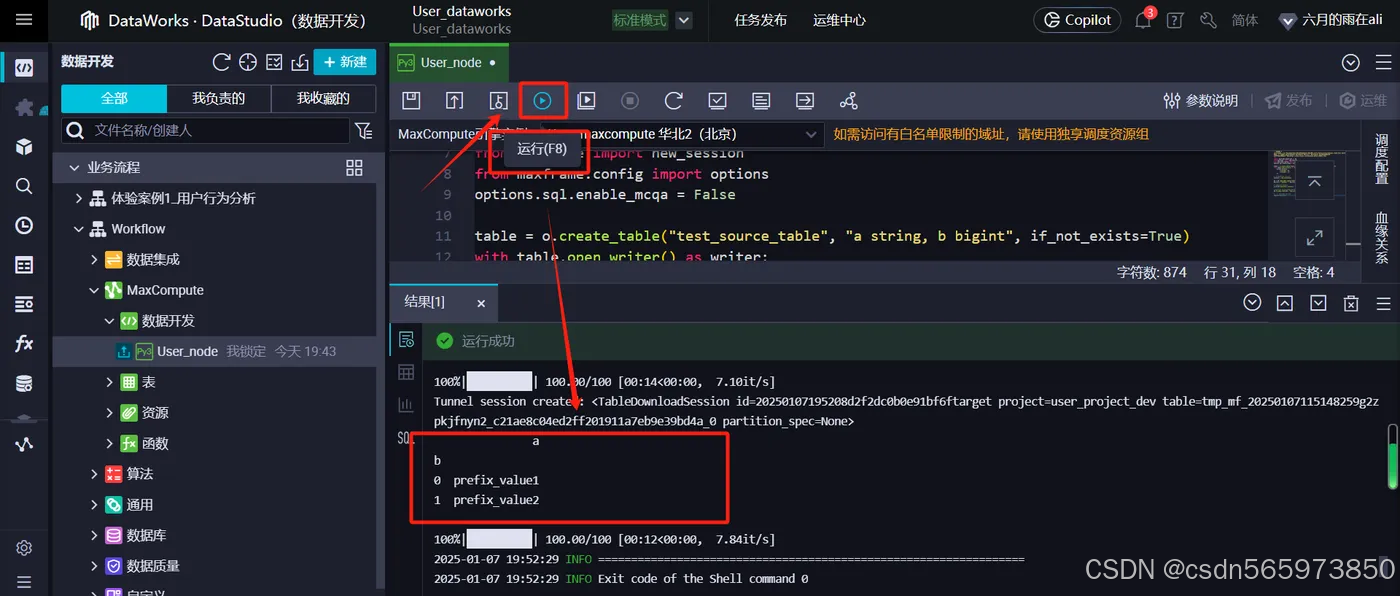
此结果表示MaxFrame安装成功,且已成功连接MaxCompute集群。在目标MaxCompute项目中运行如下SQL,查询test_prefix_source_table表的数据,新建 ODPS SQL 节点
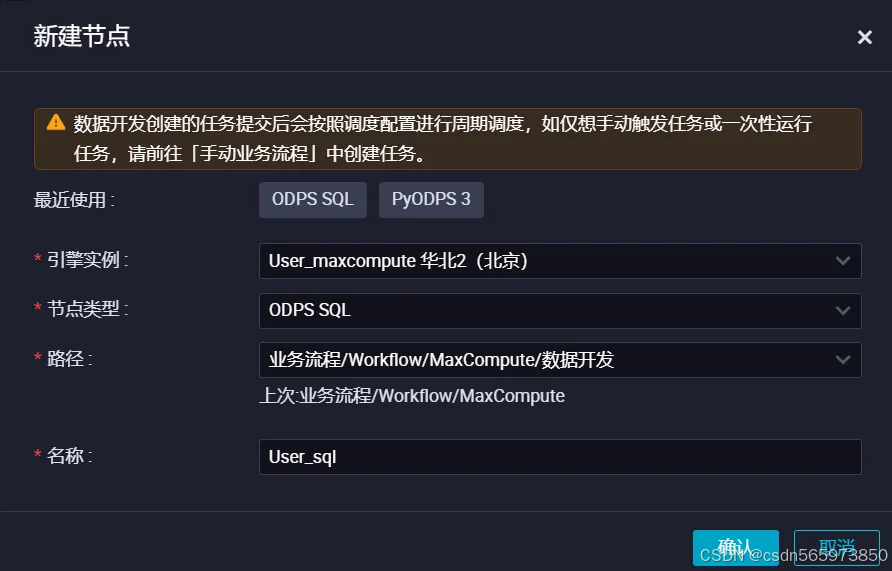
点击【确认】完成 新建 ODPS SQL 节点 新建 成功之后,在我们新建的 User_sql2 节点输入查询语句
SELECT * FROM test_prefix_source_table;
点击【执行】可以看到sql 查询的结果数据
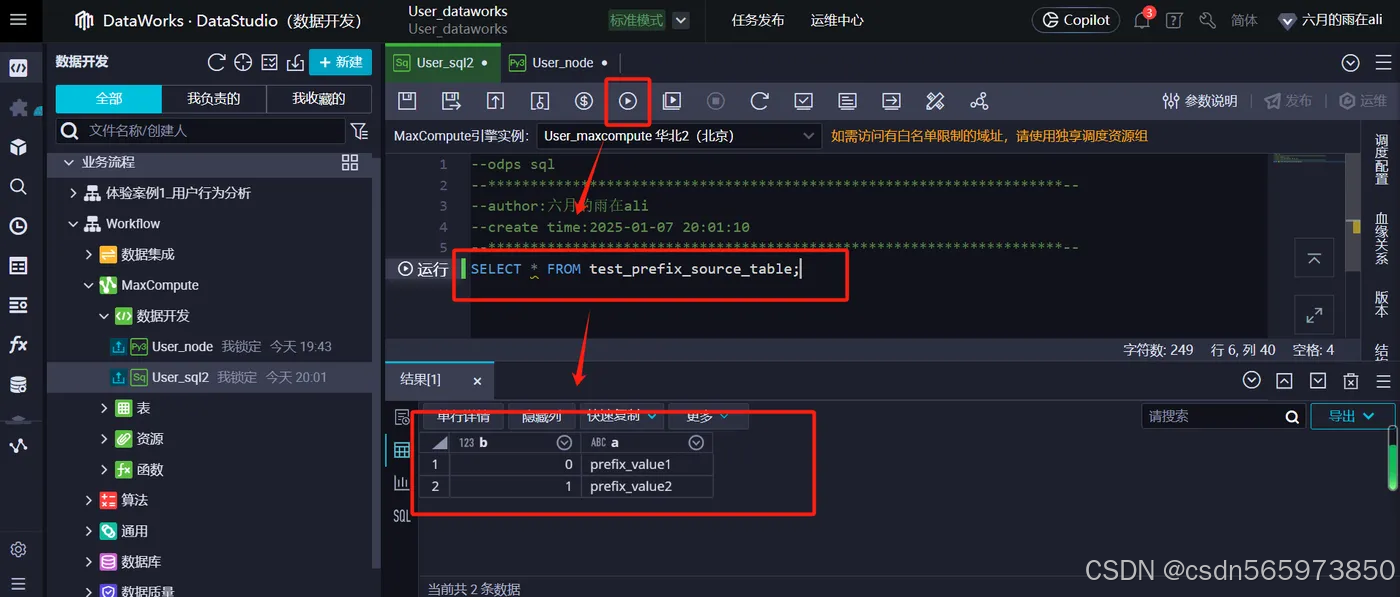
到这里就说明我们的 MaxFrame 以及所有需要的服务和资源都可以正常运行,下面来使用与Pandas相同的API来分析数据。
分布式Pandas 处理
在基于MaxFrame实现分布式Pandas处理 之前,首先需要准备一些调用过程中需要用到的ALIBABA_CLOUD_ACCESS_KEY_ID、ALIBABA_CLOUD_ACCESS_KEY_SECRET 、your-default-project、your-end-point。 这里 进入AccessKey管理页面获取AccessKey ID以及对应的AccessKey Secret
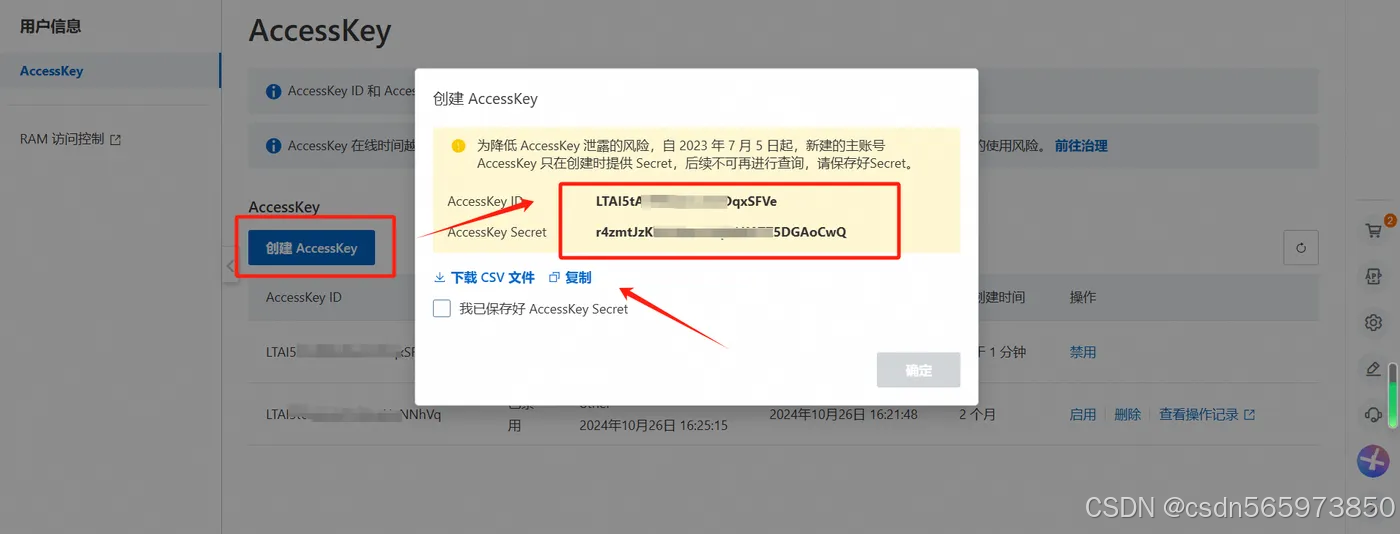
复制 后备用。登录MaxCompute控制台,在左侧导航栏选择【工作区】-【项目管理】,查看MaxCompute项目名称
在 Endpoint 页面找到当前地域对应的 Endpoint 并复制,
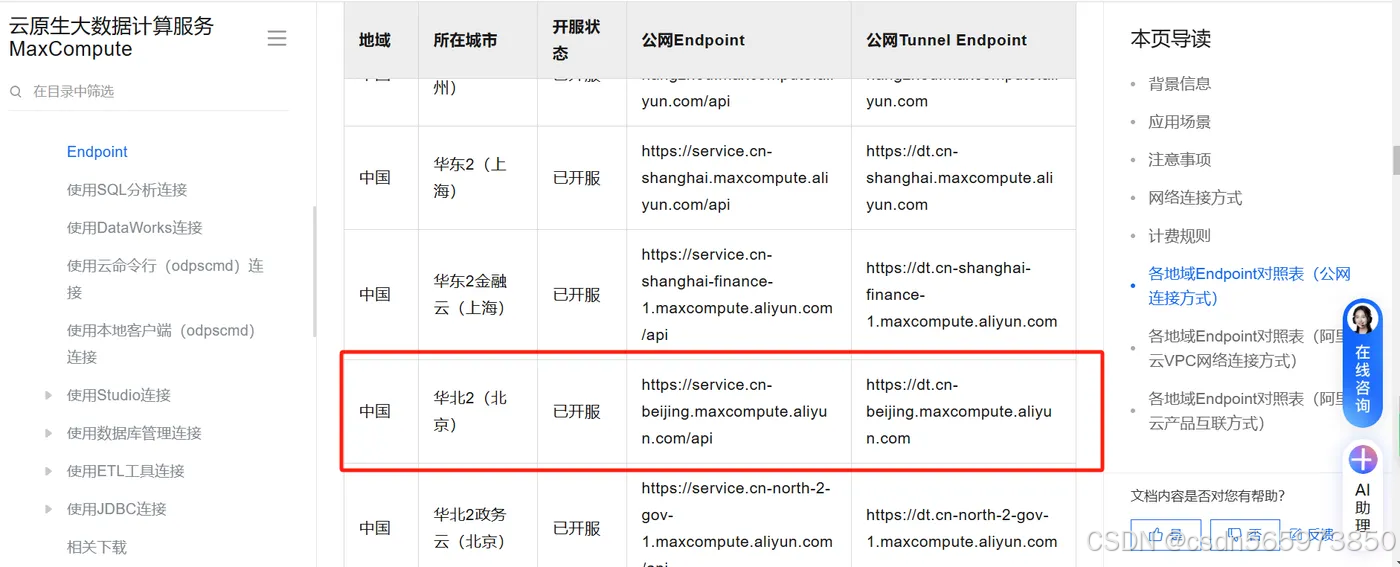
替换掉示例代码中对应的上述获取的账号信息,这里给出的是示例代码,替换后的代码这里不方便给出哈
from odps import ODPS
from maxframe.session import new_session
import maxframe.dataframe as md
import pandas as pd
import oso = ODPS(# 确保 ALIBABA_CLOUD_ACCESS_KEY_ID 环境变量设置为用户 Access Key ID,# ALIBABA_CLOUD_ACCESS_KEY_SECRET 环境变量设置为用户 Access Key Secret,# 不建议直接使用AccessKey ID和 AccessKey Secret字符串。os.getenv('ALIBABA_CLOUD_ACCESS_KEY_ID'),os.getenv('ALIBABA_CLOUD_ACCESS_KEY_SECRET'),project='your-default-project',endpoint='your-end-point',
)data_sets = [{"table_name": "product","table_schema" : "index bigint, product_id bigint, product_name string, current_price bigint","source_type": "records","records" : [[1, 100, 'Nokia', 1000],[2, 200, 'Apple', 5000],[3, 300, 'Samsung', 9000]],
},
{"table_name" : "sales","table_schema" : "index bigint, sale_id bigint, product_id bigint, user_id bigint, year bigint, quantity bigint, price bigint","source_type": "records","records" : [[1, 1, 100, 101, 2008, 10, 5000],[2, 2, 300, 101, 2009, 7, 4000],[3, 4, 100, 102, 2011, 9, 4000],[4, 5, 200, 102, 2013, 6, 6000],[5, 8, 300, 102, 2015, 10, 9000],[6, 9, 100, 102, 2015, 6, 2000]],"lifecycle": 5
}]def prepare_data(o: ODPS, data_sets, suffix="", drop_if_exists=False):for index, data in enumerate(data_sets):table_name = data.get("table_name")table_schema = data.get("table_schema")source_type = data.get("source_type")if not table_name or not table_schema or not source_type:raise ValueError(f"Dataset at index {index} is missing one or more required keys: 'table_name', 'table_schema', or 'source_type'.")lifecycle = data.get("lifecycle", 5)table_name += suffixprint(f"Processing {table_name}...")if drop_if_exists:print(f"Deleting {table_name}...")o.delete_table(table_name, if_exists=True)o.create_table(name=table_name, table_schema=table_schema, lifecycle=lifecycle, if_not_exists=True)if source_type == "local_file":file_path = data.get("file")if not file_path:raise ValueError(f"Dataset at index {index} with source_type 'local_file' is missing the 'file' key.")sep = data.get("sep", ",")pd_df = pd.read_csv(file_path, sep=sep)ODPSDataFrame(pd_df).persist(table_name, drop_table=True)elif source_type == 'records':records = data.get("records")if not records:raise ValueError(f"Dataset at index {index} with source_type 'records' is missing the 'records' key.")with o.get_table(table_name).open_writer() as writer:writer.write(records)else:raise ValueError(f"Unknown data set source_type: {source_type}")print(f"Processed {table_name} Done")prepare_data(o, data_sets, "_maxframe_demo", True)
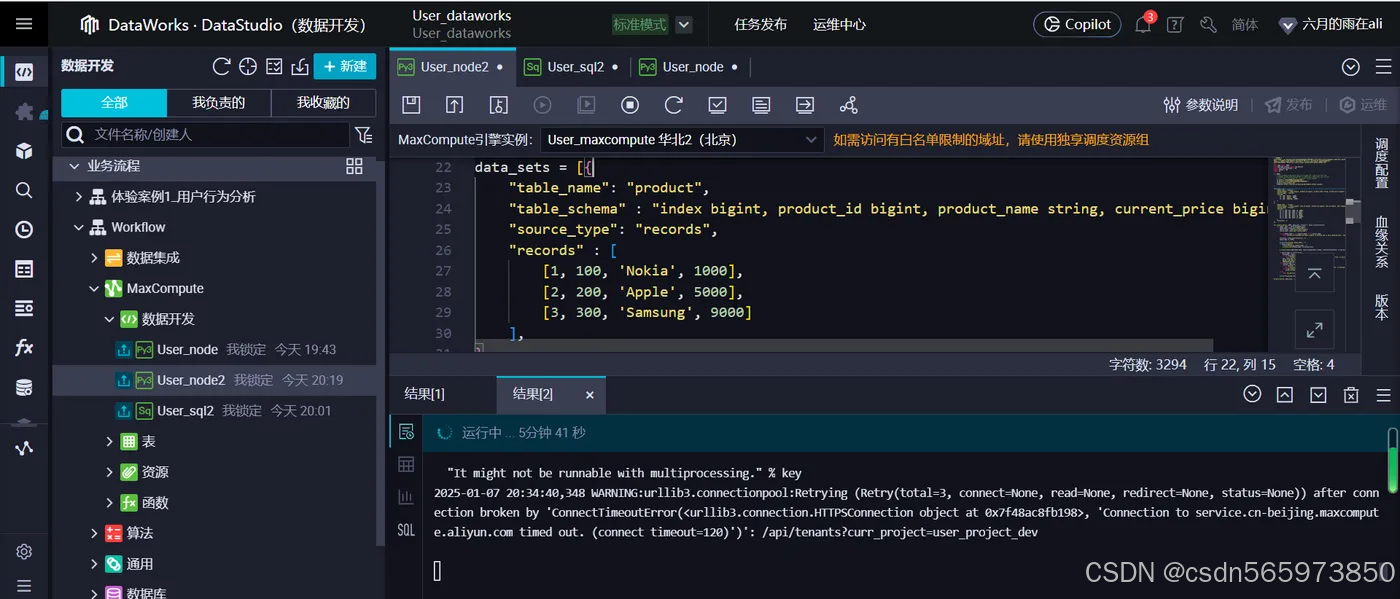
这里我们新建 PyODPS 3节点 User_node2 来执行替换了密钥信息后的上述示例代码,等待运行成功
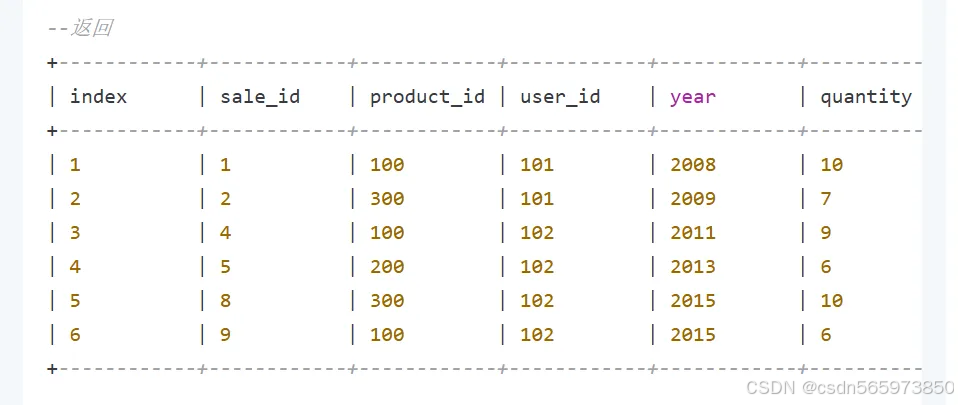
查询sales_maxframe_demo表和product_maxframe_demo表的数据,SQL命令如下
--查询sales_maxframe_demo表
SELECT * FROM sales_maxframe_demo;
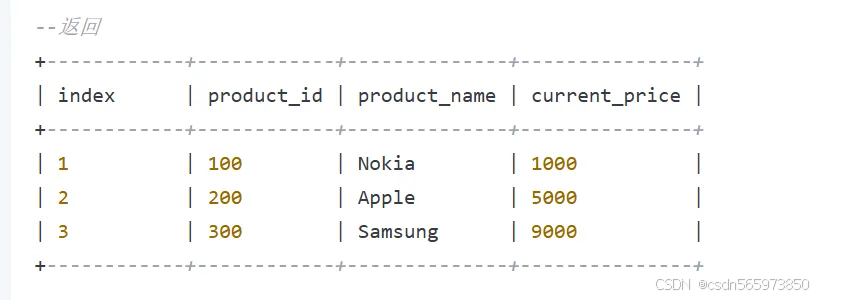
--查询product_maxframe_demo表数据
SELECT * FROM product_maxframe_demo;
这里需要说明一下,我没有执行结束,在执行的过程中,一直执行超时,不知道什么原因
Executing user script with PyODPS 0.12.1 (wrapper version: 0.12.1spawn)Processing product_maxframe_demo...
Deleting product_maxframe_demo.../opt/taobao/tbdpapp/pyodps/pyodpswrapper.py:1191: UserWarning: Global variable __doc__ you are about to set conflicts with pyodpswrapper or builtin variables. It might not be runnable with multiprocessing."It might not be runnable with multiprocessing." % key
2025-01-07 20:34:40,348 WARNING:urllib3.connectionpool:Retrying (Retry(total=3, connect=None, read=None, redirect=None, status=None)) after connection broken by 'ConnectTimeoutError(<urllib3.connection.HTTPSConnection object at 0x7f48ac8fb198>, 'Connection to service.cn-beijing.maxcompute.aliyun.com timed out. (connect timeout=120)')': /api/tenants?curr_project=user_project_dev
总的来说
MaxFrame可以在分布式环境下使用与Pandas相同的API来分析数据,通过MaxFrame,您能够以高于开源Pandas数十倍的性能在MaxCompute上快速完成数据分析和计算工作。MaxFrame兼容Pandas接口且自动进行分布式处理,在保证强大数据处理能力的同时,可以大幅度提高数据处理规模及计算效率。